 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaLoGN: Adaptive Logic Graph Network for Reasoning-Based Machine Reading Comprehension
Mar 16, 2022

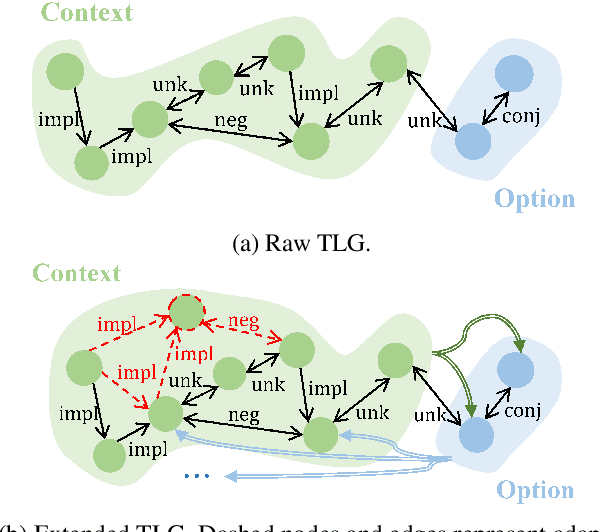
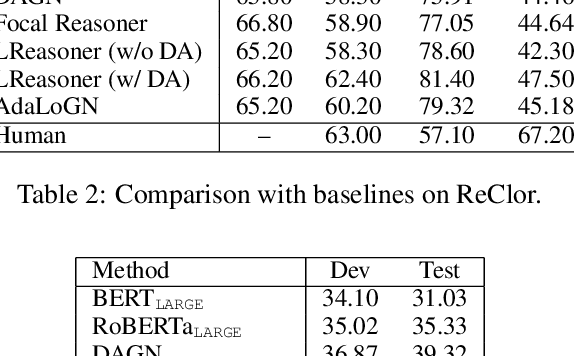
Recent machine reading comprehension datasets such as ReClor and LogiQA require performing logical reasoning over text. Conventional neural models are insufficient for logical reasoning, while symbolic reasoners cannot directly apply to text. To meet the challenge, we present a neural-symbolic approach which, to predict an answer, passes messages over a graph representing logical relations between text units. It incorporates an adaptive logic graph network (AdaLoGN) which adaptively infers logical relations to extend the graph and, essentially, realizes mutual and iterative reinforcement between neural and symbolic reasoning. We also implement a novel subgraph-to-node message passing mechanism to enhance context-option interaction for answering multiple-choice questions. Our approach shows promising results on ReClor and LogiQA.
TSQA: Tabular Scenario Based Question Answering
Jan 14, 2021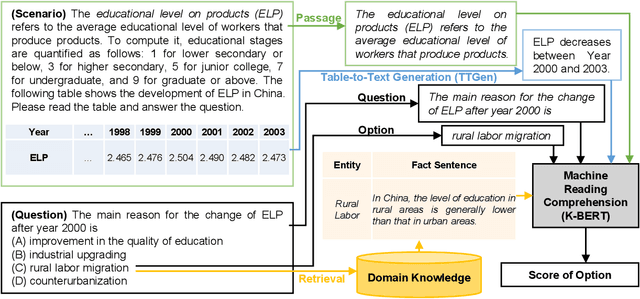

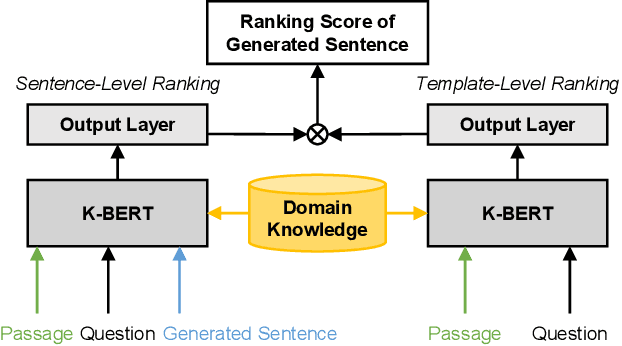
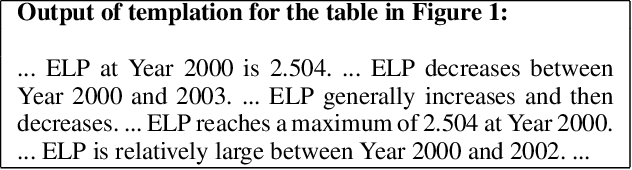
Scenario-based question answering (SQA) has attracted an increasing research interest. Compared with the well-studied machine reading comprehension (MRC), SQA is a more challenging task: a scenario may contain not only a textual passage to read but also structured data like tables, i.e., tabular scenario based question answering (TSQA). AI applications of TSQA such as answering multiple-choice questions in high-school exams require synthesizing data in multiple cells and combining tables with texts and domain knowledge to infer answers. To support the study of this task, we construct GeoTSQA. This dataset contains 1k real questions contextualized by tabular scenarios in the geography domain. To solve the task, we extend state-of-the-art MRC methods with TTGen, a novel table-to-text generator. It generates sentences from variously synthesized tabular data and feeds the downstream MRC method with the most useful sentences. Its sentence ranking model fuses the information in the scenario, question, and domain knowledge. Our approach outperforms a variety of strong baseline methods on GeoTSQA.
SPARQA: Skeleton-based Semantic Parsing for Complex Questions over Knowledge Bases
Mar 31, 2020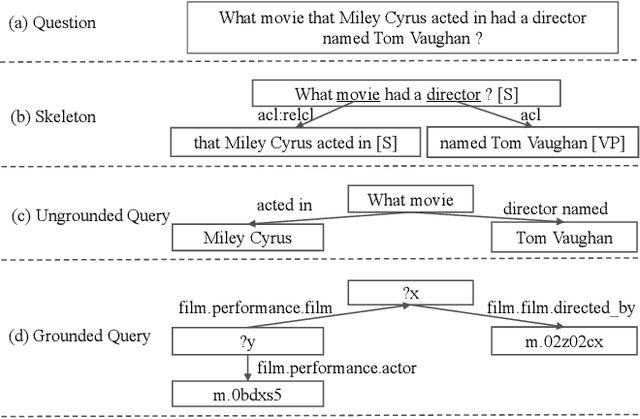
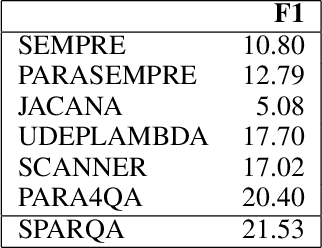

Semantic parsing transforms a natural language question into a formal query over a knowledge base. Many existing methods rely on syntactic parsing like dependencies. However, the accuracy of producing such expressive formalisms is not satisfying on long complex questions. In this paper, we propose a novel skeleton grammar to represent the high-level structure of a complex question. This dedicated coarse-grained formalism with a BERT-based parsing algorithm helps to improve the accuracy of the downstream fine-grained semantic parsing. Besides, to align the structure of a question with the structure of a knowledge base, our multi-strategy method combines sentence-level and word-level semantics. Our approach shows promising performance on several datasets.
Learning to Select Bi-Aspect Information for Document-Scale Text Content Manipulation
Feb 24, 2020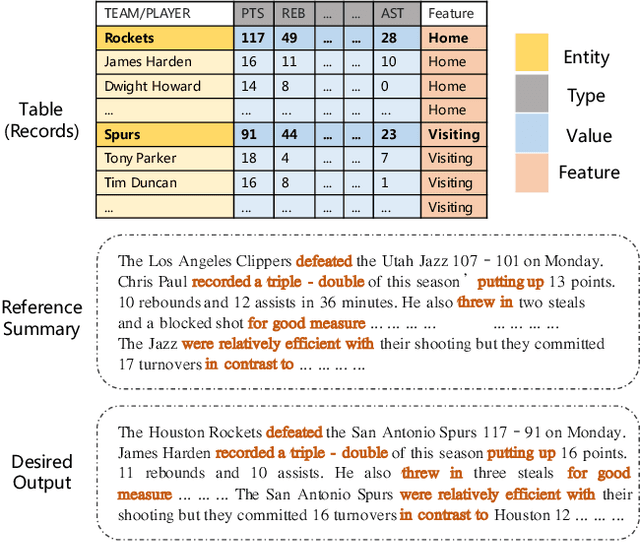
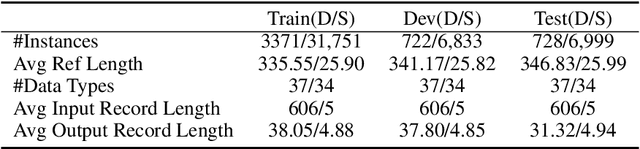
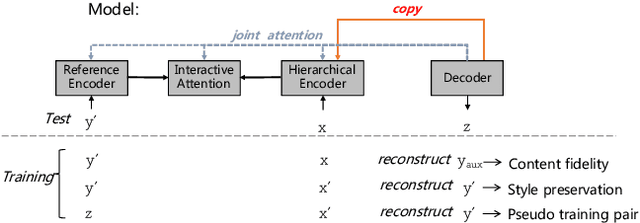
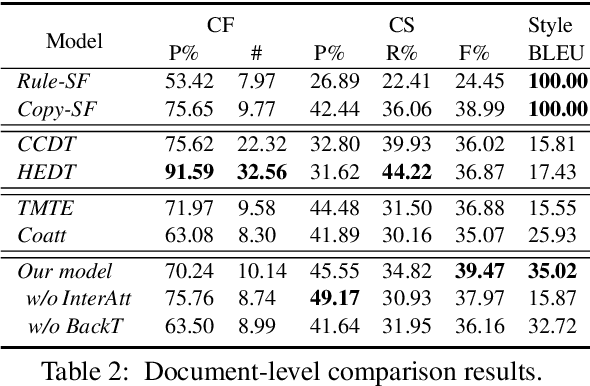
In this paper, we focus on a new practical task, document-scale text content manipulation, which is the opposite of text style transfer and aims to preserve text styles while altering the content. In detail, the input is a set of structured records and a reference text for describing another recordset. The output is a summary that accurately describes the partial content in the source recordset with the same writing style of the reference. The task is unsupervised due to lack of parallel data, and is challenging to select suitable records and style words from bi-aspect inputs respectively and generate a high-fidelity long document. To tackle those problems, we first build a dataset based on a basketball game report corpus as our testbed, and present an unsupervised neural model with interactive attention mechanism, which is used for learning the semantic relationship between records and reference texts to achieve better content transfer and better style preservation. In addition, we also explore the effectiveness of the back-translation in our task for constructing some pseudo-training pairs. Empirical results show superiority of our approaches over competitive methods, and the models also yield a new state-of-the-art result on a sentence-level dataset.