 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA General Framework for Dynamic Consistent Submodular Maximization
Jun 03, 2026Consistency is an important property in dynamic submodular maximization and entails maintaining a near-optimal solution at all times, making only a small number of adjustments to the solution in each step. Prior work has explored this question for the insertion-only case, where the algorithm faces a stream of $n$ insertions, and has established lower and upper bounds for the cardinality-constrained version of the problem. We consider this question in the fully dynamic setting, where the stream of operations may contain both insertions and deletions. We develop a general framework for designing algorithms for this setting, and instantiate it to obtain the first constant-factor approximations with sublinear consistency. For cardinality constraints, we propose a $\frac 12 - O(\varepsilon)$ approximation that is $O\left(\frac{1}{\varepsilon^2}\right)$ consistent. For rank-$k$ matroid constraints, we construct a $\frac 14 - O(\varepsilon)$ approximation to the dynamic optimum that is $O\left(\frac{\log k}{\varepsilon^2}\right)$ consistent.
Accelerating Scientific Research with Gemini: Case Studies and Common Techniques
Feb 03, 2026Recent advances in large language models (LLMs) have opened new avenues for accelerating scientific research. While models are increasingly capable of assisting with routine tasks, their ability to contribute to novel, expert-level mathematical discovery is less understood. We present a collection of case studies demonstrating how researchers have successfully collaborated with advanced AI models, specifically Google's Gemini-based models (in particular Gemini Deep Think and its advanced variants), to solve open problems, refute conjectures, and generate new proofs across diverse areas in theoretical computer science, as well as other areas such as economics, optimization, and physics. Based on these experiences, we extract common techniques for effective human-AI collaboration in theoretical research, such as iterative refinement, problem decomposition, and cross-disciplinary knowledge transfer. While the majority of our results stem from this interactive, conversational methodology, we also highlight specific instances that push beyond standard chat interfaces. These include deploying the model as a rigorous adversarial reviewer to detect subtle flaws in existing proofs, and embedding it within a "neuro-symbolic" loop that autonomously writes and executes code to verify complex derivations. Together, these examples highlight the potential of AI not just as a tool for automation, but as a versatile, genuine partner in the creative process of scientific discovery.
The Cost of Consistency: Submodular Maximization with Constant Recourse
Dec 03, 2024



In this work, we study online submodular maximization, and how the requirement of maintaining a stable solution impacts the approximation. In particular, we seek bounds on the best-possible approximation ratio that is attainable when the algorithm is allowed to make at most a constant number of updates per step. We show a tight information-theoretic bound of $\tfrac{2}{3}$ for general monotone submodular functions, and an improved (also tight) bound of $\tfrac{3}{4}$ for coverage functions. Since both these bounds are attained by non poly-time algorithms, we also give a poly-time randomized algorithm that achieves a $0.51$-approximation. Combined with an information-theoretic hardness of $\tfrac{1}{2}$ for deterministic algorithms from prior work, our work thus shows a separation between deterministic and randomized algorithms, both information theoretically and for poly-time algorithms.
Consistent Submodular Maximization
May 30, 2024


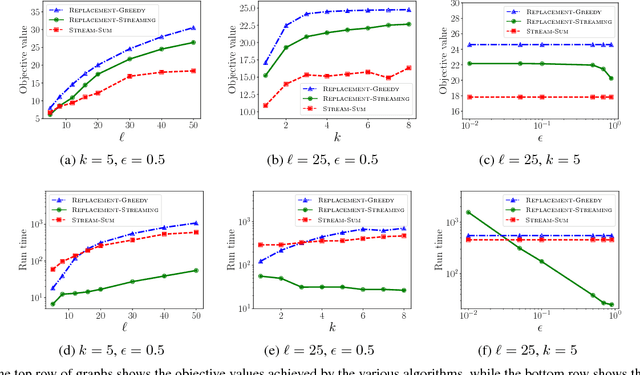
Maximizing monotone submodular functions under cardinality constraints is a classic optimization task with several applications in data mining and machine learning. In this paper we study this problem in a dynamic environment with consistency constraints: elements arrive in a streaming fashion and the goal is maintaining a constant approximation to the optimal solution while having a stable solution (i.e., the number of changes between two consecutive solutions is bounded). We provide algorithms in this setting with different trade-offs between consistency and approximation quality. We also complement our theoretical results with an experimental analysis showing the effectiveness of our algorithms in real-world instances.
GIST: Greedy Independent Set Thresholding for Diverse Data Summarization
May 29, 2024

We propose a novel subset selection task called min-distance diverse data summarization ($\textsf{MDDS}$), which has a wide variety of applications in machine learning, e.g., data sampling and feature selection. Given a set of points in a metric space, the goal is to maximize an objective that combines the total utility of the points and a diversity term that captures the minimum distance between any pair of selected points, subject to the constraint $|S| \le k$. For example, the points may correspond to training examples in a data sampling problem, e.g., learned embeddings of images extracted from a deep neural network. This work presents the $\texttt{GIST}$ algorithm, which achieves a $\frac{2}{3}$-approximation guarantee for $\textsf{MDDS}$ by approximating a series of maximum independent set problems with a bicriteria greedy algorithm. We also prove a complementary $(\frac{2}{3}+\varepsilon)$-hardness of approximation, for any $\varepsilon > 0$. Finally, we provide an empirical study that demonstrates $\texttt{GIST}$ outperforms existing methods for $\textsf{MDDS}$ on synthetic data, and also for a real-world image classification experiment the studies single-shot subset selection for ImageNet.
Fully Dynamic Submodular Maximization over Matroids
May 31, 2023Maximizing monotone submodular functions under a matroid constraint is a classic algorithmic problem with multiple applications in data mining and machine learning. We study this classic problem in the fully dynamic setting, where elements can be both inserted and deleted in real-time. Our main result is a randomized algorithm that maintains an efficient data structure with an $\tilde{O}(k^2)$ amortized update time (in the number of additions and deletions) and yields a $4$-approximate solution, where $k$ is the rank of the matroid.
Deletion Robust Non-Monotone Submodular Maximization over Matroids
Aug 16, 2022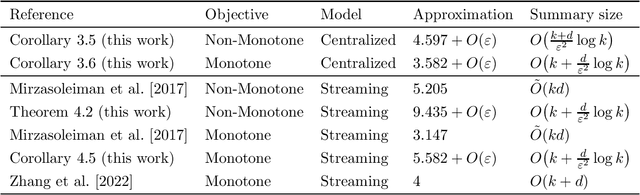
Maximizing a submodular function is a fundamental task in machine learning and in this paper we study the deletion robust version of the problem under the classic matroids constraint. Here the goal is to extract a small size summary of the dataset that contains a high value independent set even after an adversary deleted some elements. We present constant-factor approximation algorithms, whose space complexity depends on the rank $k$ of the matroid and the number $d$ of deleted elements. In the centralized setting we present a $(4.597+O(\varepsilon))$-approximation algorithm with summary size $O( \frac{k+d}{\varepsilon^2}\log \frac{k}{\varepsilon})$ that is improved to a $(3.582+O(\varepsilon))$-approximation with $O(k + \frac{d}{\varepsilon^2}\log \frac{k}{\varepsilon})$ summary size when the objective is monotone. In the streaming setting we provide a $(9.435 + O(\varepsilon))$-approximation algorithm with summary size and memory $O(k + \frac{d}{\varepsilon^2}\log \frac{k}{\varepsilon})$; the approximation factor is then improved to $(5.582+O(\varepsilon))$ in the monotone case.
Deletion Robust Submodular Maximization over Matroids
Jan 31, 2022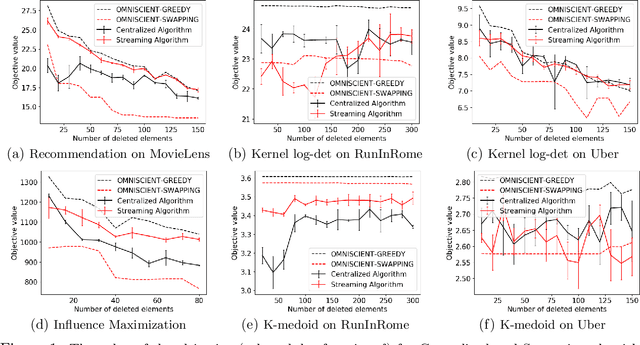
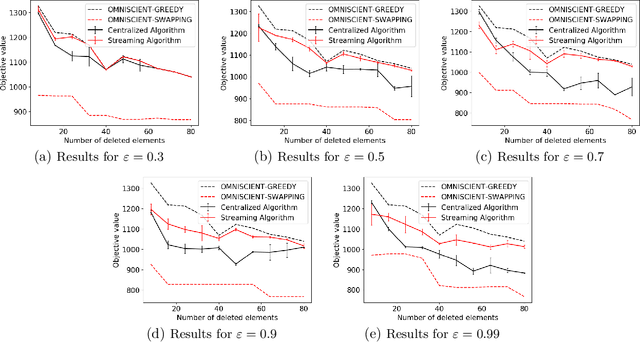
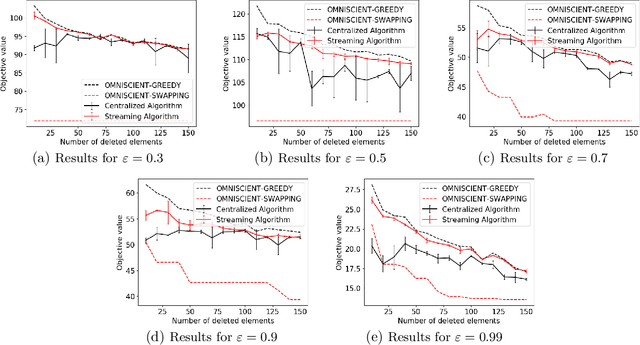
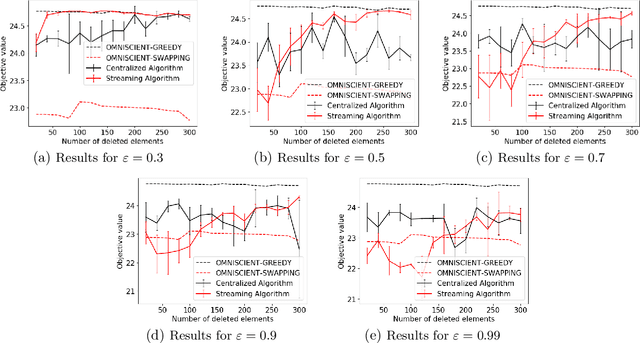
Maximizing a monotone submodular function is a fundamental task in machine learning. In this paper, we study the deletion robust version of the problem under the classic matroids constraint. Here the goal is to extract a small size summary of the dataset that contains a high value independent set even after an adversary deleted some elements. We present constant-factor approximation algorithms, whose space complexity depends on the rank $k$ of the matroid and the number $d$ of deleted elements. In the centralized setting we present a $(3.582+O(\varepsilon))$-approximation algorithm with summary size $O(k + \frac{d \log k}{\varepsilon^2})$. In the streaming setting we provide a $(5.582+O(\varepsilon))$-approximation algorithm with summary size and memory $O(k + \frac{d \log k}{\varepsilon^2})$. We complement our theoretical results with an in-depth experimental analysis showing the effectiveness of our algorithms on real-world datasets.
Submodular Streaming in All its Glory: Tight Approximation, Minimum Memory and Low Adaptive Complexity
May 13, 2019
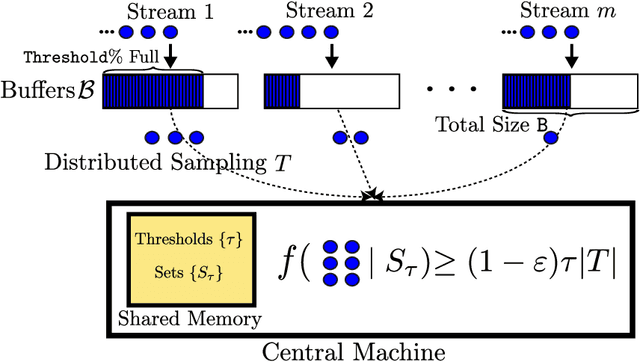
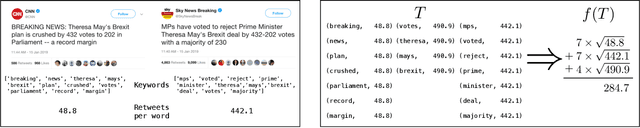

Streaming algorithms are generally judged by the quality of their solution, memory footprint, and computational complexity. In this paper, we study the problem of maximizing a monotone submodular function in the streaming setting with a cardinality constraint $k$. We first propose Sieve-Streaming++, which requires just one pass over the data, keeps only $O(k)$ elements and achieves the tight $(1/2)$-approximation guarantee. The best previously known streaming algorithms either achieve a suboptimal $(1/4)$-approximation with $\Theta(k)$ memory or the optimal $(1/2)$-approximation with $O(k\log k)$ memory. Next, we show that by buffering a small fraction of the stream and applying a careful filtering procedure, one can heavily reduce the number of adaptive computational rounds, thus substantially lowering the computational complexity of Sieve-Streaming++. We then generalize our results to the more challenging multi-source streaming setting. We show how one can achieve the tight $(1/2)$-approximation guarantee with $O(k)$ shared memory while minimizing not only the required rounds of computations but also the total number of communicated bits. Finally, we demonstrate the efficiency of our algorithms on real-world data summarization tasks for multi-source streams of tweets and of YouTube videos.
Data Summarization at Scale: A Two-Stage Submodular Approach
Jun 07, 2018
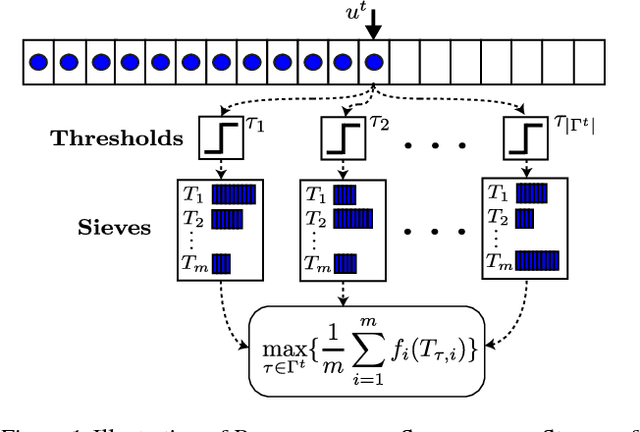

The sheer scale of modern datasets has resulted in a dire need for summarization techniques that identify representative elements in a dataset. Fortunately, the vast majority of data summarization tasks satisfy an intuitive diminishing returns condition known as submodularity, which allows us to find nearly-optimal solutions in linear time. We focus on a two-stage submodular framework where the goal is to use some given training functions to reduce the ground set so that optimizing new functions (drawn from the same distribution) over the reduced set provides almost as much value as optimizing them over the entire ground set. In this paper, we develop the first streaming and distributed solutions to this problem. In addition to providing strong theoretical guarantees, we demonstrate both the utility and efficiency of our algorithms on real-world tasks including image summarization and ride-share optimization.