 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStochastic Matching via Local Sparsification
May 13, 2026The classic online stochastic matching problem typically requires immediate and irrevocable matching decisions. However, in many modern decentralized systems such as real-time ride-hailing and distributed cloud computing, the primary bottleneck is often local communication bandwidth rather than the timing of the match itself. We formalize this challenge by introducing a two-stage local sparsification framework. In this setting, arriving requests must prune their realized compatibility sets to a strict budget of $k$ edges before a central coordinator optimizes the global matching. This creates a "middle ground" between local information constraints and global optimization utility. We propose a local selection strategy, parametrized by a fractional solution of the expected instance. Theoretically, we quantify the approximation ratio as a function of the solution's {\em spread}. We prove that under sufficient spread, our sparsifier globally preserves the expected size of the maximum matching. Empirically, we demonstrate the robustness of our approach using the New York City ride-hailing datasets and adversarial synthetic benchmarks. Our results show that near-optimal global matching is achievable even with highly constrained local budgets, significantly outperforming standard online baselines.
Diversify and Conquer: Diversity-Centric Data Selection with Iterative Refinement
Sep 17, 2024Finetuning large language models on instruction data is crucial for enhancing pre-trained knowledge and improving instruction-following capabilities. As instruction datasets proliferate, selecting optimal data for effective training becomes increasingly important. This work addresses the question: How can we determine the optimal subset of data for effective training? While existing research often emphasizes local criteria like instance quality for subset selection, we argue that a global approach focused on data diversity is more critical. Our method employs k-means clustering to ensure the selected subset effectively represents the full dataset. We propose an iterative refinement method inspired by active learning techniques to resample instances from clusters, reassessing each cluster's importance and sampling weight in every training iteration. This approach reduces the effect of outliers and automatically filters out clusters containing low-quality data. Through extensive evaluation across natural language reasoning, general world knowledge, code and math reasoning tasks, and by fine-tuning models from various families, we observe consistent improvements, achieving a 7% increase over random selection and a 3.8% improvement over state-of-the-art sampling methods. Our work highlights the significance of diversity-first sampling when finetuning LLMs to enhance performance across a broad array of evaluation tasks. Our code is available at https://github.com/for-ai/iterative-data-selection.
GIST: Greedy Independent Set Thresholding for Diverse Data Summarization
May 29, 2024

We propose a novel subset selection task called min-distance diverse data summarization ($\textsf{MDDS}$), which has a wide variety of applications in machine learning, e.g., data sampling and feature selection. Given a set of points in a metric space, the goal is to maximize an objective that combines the total utility of the points and a diversity term that captures the minimum distance between any pair of selected points, subject to the constraint $|S| \le k$. For example, the points may correspond to training examples in a data sampling problem, e.g., learned embeddings of images extracted from a deep neural network. This work presents the $\texttt{GIST}$ algorithm, which achieves a $\frac{2}{3}$-approximation guarantee for $\textsf{MDDS}$ by approximating a series of maximum independent set problems with a bicriteria greedy algorithm. We also prove a complementary $(\frac{2}{3}+\varepsilon)$-hardness of approximation, for any $\varepsilon > 0$. Finally, we provide an empirical study that demonstrates $\texttt{GIST}$ outperforms existing methods for $\textsf{MDDS}$ on synthetic data, and also for a real-world image classification experiment the studies single-shot subset selection for ImageNet.
Fair Active Ranking from Pairwise Preferences
Feb 05, 2024We investigate the problem of probably approximately correct and fair (PACF) ranking of items by adaptively evoking pairwise comparisons. Given a set of $n$ items that belong to disjoint groups, our goal is to find an $(\epsilon, \delta)$-PACF-Ranking according to a fair objective function that we propose. We assume access to an oracle, wherein, for each query, the learner can choose a pair of items and receive stochastic winner feedback from the oracle. Our proposed objective function asks to minimize the $\ell_q$ norm of the error of the groups, where the error of a group is the $\ell_p$ norm of the error of all the items within that group, for $p, q \geq 1$. This generalizes the objective function of $\epsilon$-Best-Ranking, proposed by Saha & Gopalan (2019). By adopting our objective function, we gain the flexibility to explore fundamental fairness concepts like equal or proportionate errors within a unified framework. Adjusting parameters $p$ and $q$ allows tailoring to specific fairness preferences. We present both group-blind and group-aware algorithms and analyze their sample complexity. We provide matching lower bounds up to certain logarithmic factors for group-blind algorithms. For a restricted class of group-aware algorithms, we show that we can get reasonable lower bounds. We conduct comprehensive experiments on both real-world and synthetic datasets to complement our theoretical findings.
Improved Approximation for Fair Correlation Clustering
Jun 09, 2022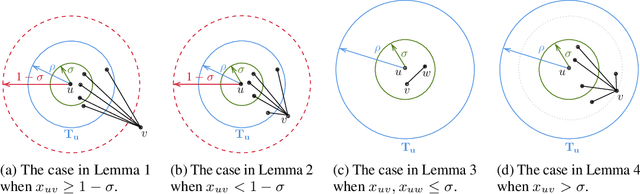
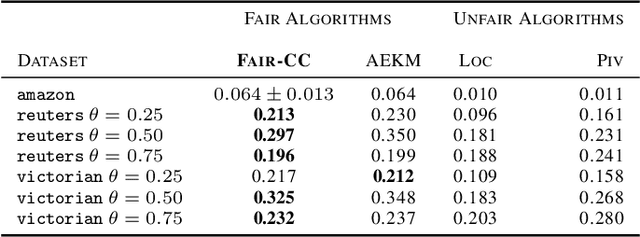
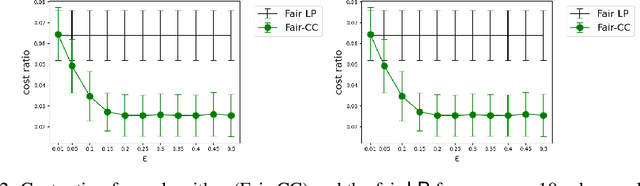
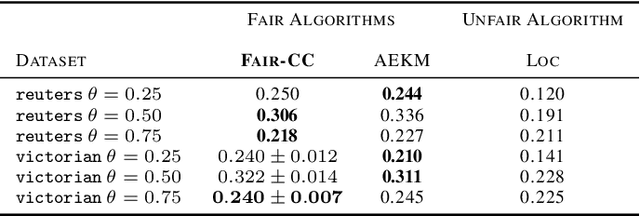
Correlation clustering is a ubiquitous paradigm in unsupervised machine learning where addressing unfairness is a major challenge. Motivated by this, we study Fair Correlation Clustering where the data points may belong to different protected groups and the goal is to ensure fair representation of all groups across clusters. Our paper significantly generalizes and improves on the quality guarantees of previous work of Ahmadi et al. and Ahmadian et al. as follows. - We allow the user to specify an arbitrary upper bound on the representation of each group in a cluster. - Our algorithm allows individuals to have multiple protected features and ensure fairness simultaneously across them all. - We prove guarantees for clustering quality and fairness in this general setting. Furthermore, this improves on the results for the special cases studied in previous work. Our experiments on real-world data demonstrate that our clustering quality compared to the optimal solution is much better than what our theoretical result suggests.
Fair Hierarchical Clustering
Jun 19, 2020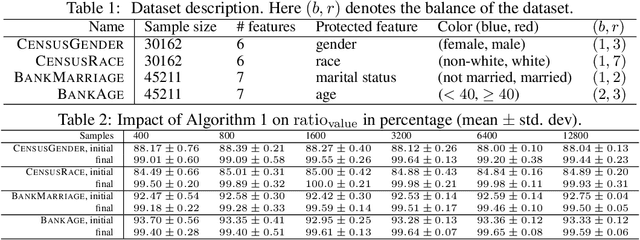
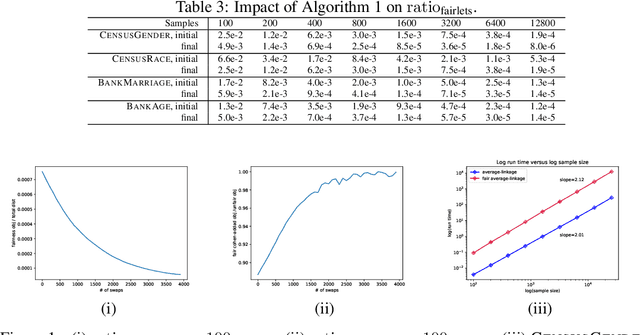
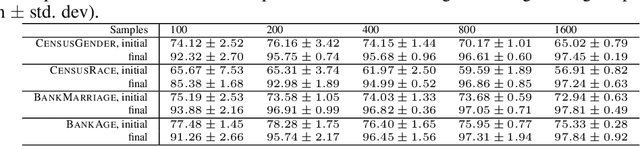

As machine learning has become more prevalent, researchers have begun to recognize the necessity of ensuring machine learning systems are fair. Recently, there has been an interest in defining a notion of fairness that mitigates over-representation in traditional clustering. In this paper we extend this notion to hierarchical clustering, where the goal is to recursively partition the data to optimize a specific objective. For various natural objectives, we obtain simple, efficient algorithms to find a provably good fair hierarchical clustering. Empirically, we show that our algorithms can find a fair hierarchical clustering, with only a negligible loss in the objective.
Fair Correlation Clustering
Mar 02, 2020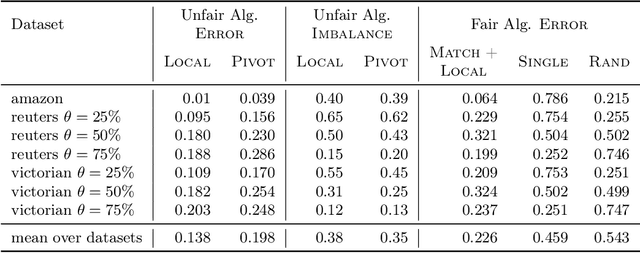
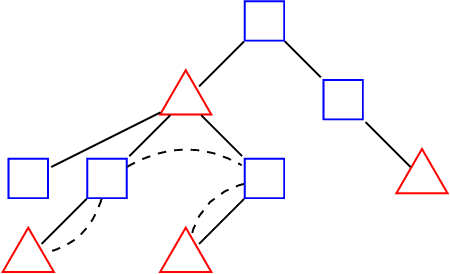
In this paper, we study correlation clustering under fairness constraints. Fair variants of $k$-median and $k$-center clustering have been studied recently, and approximation algorithms using a notion called fairlet decomposition have been proposed. We obtain approximation algorithms for fair correlation clustering under several important types of fairness constraints. Our results hinge on obtaining a fairlet decomposition for correlation clustering by introducing a novel combinatorial optimization problem. We define a fairlet decomposition with cost similar to the $k$-median cost and this allows us to obtain approximation algorithms for a wide range of fairness constraints. We complement our theoretical results with an in-depth analysis of our algorithms on real graphs where we show that fair solutions to correlation clustering can be obtained with limited increase in cost compared to the state-of-the-art (unfair) algorithms.
Clustering without Over-Representation
May 29, 2019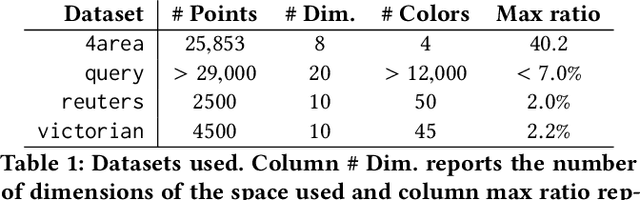
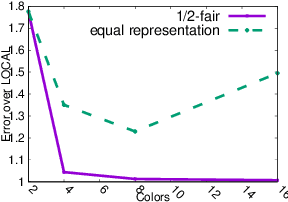
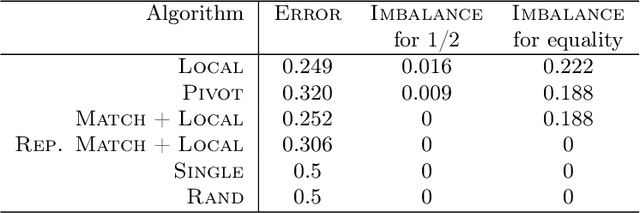
In this paper we consider clustering problems in which each point is endowed with a color. The goal is to cluster the points to minimize the classical clustering cost but with the additional constraint that no color is over-represented in any cluster. This problem is motivated by practical clustering settings, e.g., in clustering news articles where the color of an article is its source, it is preferable that no single news source dominates any cluster. For the most general version of this problem, we obtain an algorithm that has provable guarantees of performance; our algorithm is based on finding a fractional solution using a linear program and rounding the solution subsequently. For the special case of the problem where no color has an absolute majority in any cluster, we obtain a simpler combinatorial algorithm also with provable guarantees. Experiments on real-world data shows that our algorithms are effective in finding good clustering without over-representation.
* 10 pages, 6 figures, in KDD 2019