 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Role of Target Update Frequencies in Q-Learning
Feb 03, 2026The target network update frequency (TUF) is a central stabilization mechanism in (deep) Q-learning. However, their selection remains poorly understood and is often treated merely as another tunable hyperparameter rather than as a principled design decision. This work provides a theoretical analysis of target fixing in tabular Q-learning through the lens of approximate dynamic programming. We formulate periodic target updates as a nested optimization scheme in which each outer iteration applies an inexact Bellman optimality operator, approximated by a generic inner loop optimizer. Rigorous theory yields a finite-time convergence analysis for the asynchronous sampling setting, specializing to stochastic gradient descent in the inner loop. Our results deliver an explicit characterization of the bias-variance trade-off induced by the target update period, showing how to optimally set this critical hyperparameter. We prove that constant target update schedules are suboptimal, incurring a logarithmic overhead in sample complexity that is entirely avoidable with adaptive schedules. Our analysis shows that the optimal target update frequency increases geometrically over the course of the learning process.
An Approximate Ascent Approach To Prove Convergence of PPO
Feb 03, 2026Proximal Policy Optimization (PPO) is among the most widely used deep reinforcement learning algorithms, yet its theoretical foundations remain incomplete. Most importantly, convergence and understanding of fundamental PPO advantages remain widely open. Under standard theory assumptions we show how PPO's policy update scheme (performing multiple epochs of minibatch updates on multi-use rollouts with a surrogate gradient) can be interpreted as approximated policy gradient ascent. We show how to control the bias accumulated by the surrogate gradients and use techniques from random reshuffling to prove a convergence theorem for PPO that sheds light on PPO's success. Additionally, we identify a previously overlooked issue in truncated Generalized Advantage Estimation commonly used in PPO. The geometric weighting scheme induces infinite mass collapse onto the longest $k$-step advantage estimator at episode boundaries. Empirical evaluations show that a simple weight correction can yield substantial improvements in environments with strong terminal signal, such as Lunar Lander.
Adaptive Kernel Selection for Stein Variational Gradient Descent
Oct 02, 2025A central challenge in Bayesian inference is efficiently approximating posterior distributions. Stein Variational Gradient Descent (SVGD) is a popular variational inference method which transports a set of particles to approximate a target distribution. The SVGD dynamics are governed by a reproducing kernel Hilbert space (RKHS) and are highly sensitive to the choice of the kernel function, which directly influences both convergence and approximation quality. The commonly used median heuristic offers a simple approach for setting kernel bandwidths but lacks flexibility and often performs poorly, particularly in high-dimensional settings. In this work, we propose an alternative strategy for adaptively choosing kernel parameters over an abstract family of kernels. Recent convergence analyses based on the kernelized Stein discrepancy (KSD) suggest that optimizing the kernel parameters by maximizing the KSD can improve performance. Building on this insight, we introduce Adaptive SVGD (Ad-SVGD), a method that alternates between updating the particles via SVGD and adaptively tuning kernel bandwidths through gradient ascent on the KSD. We provide a simplified theoretical analysis that extends existing results on minimizing the KSD for fixed kernels to our adaptive setting, showing convergence properties for the maximal KSD over our kernel class. Our empirical results further support this intuition: Ad-SVGD consistently outperforms standard heuristics in a variety of tasks.
Controlling the Flow: Stability and Convergence for Stochastic Gradient Descent with Decaying Regularization
May 16, 2025The present article studies the minimization of convex, L-smooth functions defined on a separable real Hilbert space. We analyze regularized stochastic gradient descent (reg-SGD), a variant of stochastic gradient descent that uses a Tikhonov regularization with time-dependent, vanishing regularization parameter. We prove strong convergence of reg-SGD to the minimum-norm solution of the original problem without additional boundedness assumptions. Moreover, we quantify the rate of convergence and optimize the interplay between step-sizes and regularization decay. Our analysis reveals how vanishing Tikhonov regularization controls the flow of SGD and yields stable learning dynamics, offering new insights into the design of iterative algorithms for convex problems, including those that arise in ill-posed inverse problems. We validate our theoretical findings through numerical experiments on image reconstruction and ODE-based inverse problems.
Clustered KL-barycenter design for policy evaluation
Mar 04, 2025In the context of stochastic bandit models, this article examines how to design sample-efficient behavior policies for the importance sampling evaluation of multiple target policies. From importance sampling theory, it is well established that sample efficiency is highly sensitive to the KL divergence between the target and importance sampling distributions. We first analyze a single behavior policy defined as the KL-barycenter of the target policies. Then, we refine this approach by clustering the target policies into groups with small KL divergences and assigning each cluster its own KL-barycenter as a behavior policy. This clustered KL-based policy evaluation (CKL-PE) algorithm provides a novel perspective on optimal policy selection. We prove upper bounds on the sample complexity of our method and demonstrate its effectiveness with numerical validation.
Structure Matters: Dynamic Policy Gradient
Nov 07, 2024



In this work, we study $\gamma$-discounted infinite-horizon tabular Markov decision processes (MDPs) and introduce a framework called dynamic policy gradient (DynPG). The framework directly integrates dynamic programming with (any) policy gradient method, explicitly leveraging the Markovian property of the environment. DynPG dynamically adjusts the problem horizon during training, decomposing the original infinite-horizon MDP into a sequence of contextual bandit problems. By iteratively solving these contextual bandits, DynPG converges to the stationary optimal policy of the infinite-horizon MDP. To demonstrate the power of DynPG, we establish its non-asymptotic global convergence rate under the tabular softmax parametrization, focusing on the dependencies on salient but essential parameters of the MDP. By combining classical arguments from dynamic programming with more recent convergence arguments of policy gradient schemes, we prove that softmax DynPG scales polynomially in the effective horizon $(1-\gamma)^{-1}$. Our findings contrast recent exponential lower bound examples for vanilla policy gradient.
Polyak's Heavy Ball Method Achieves Accelerated Local Rate of Convergence under Polyak-Lojasiewicz Inequality
Oct 22, 2024In this work, we consider the convergence of Polyak's heavy ball method, both in continuous and discrete time, on a non-convex objective function. We recover the convergence rates derived in [Polyak, U.S.S.R. Comput. Math. and Math. Phys., 1964] for strongly convex objective functions, assuming only validity of the Polyak-Lojasiewicz inequality. In continuous time our result holds for all initializations, whereas in the discrete time setting we conduct a local analysis around the global minima. Our results demonstrate that the heavy ball method does, in fact, accelerate on the class of objective functions satisfying the Polyak-Lojasiewicz inequality. This holds even in the discrete time setting, provided the method reaches a neighborhood of the global minima. Instead of the usually employed Lyapunov-type arguments, our approach leverages a new differential geometric perspective of the Polyak-Lojasiewicz inequality proposed in [Rebjock and Boumal, Math. Program., 2024].
Beyond Stationarity: Convergence Analysis of Stochastic Softmax Policy Gradient Methods
Oct 04, 2023Markov Decision Processes (MDPs) are a formal framework for modeling and solving sequential decision-making problems. In finite-time horizons such problems are relevant for instance for optimal stopping or specific supply chain problems, but also in the training of large language models. In contrast to infinite horizon MDPs optimal policies are not stationary, policies must be learned for every single epoch. In practice all parameters are often trained simultaneously, ignoring the inherent structure suggested by dynamic programming. This paper introduces a combination of dynamic programming and policy gradient called dynamic policy gradient, where the parameters are trained backwards in time. For the tabular softmax parametrisation we carry out the convergence analysis for simultaneous and dynamic policy gradient towards global optima, both in the exact and sampled gradient settings without regularisation. It turns out that the use of dynamic policy gradient training much better exploits the structure of finite-time problems which is reflected in improved convergence bounds.
Consistency analysis of bilevel data-driven learning in inverse problems
Jul 06, 2020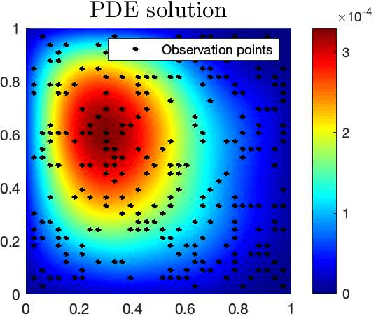

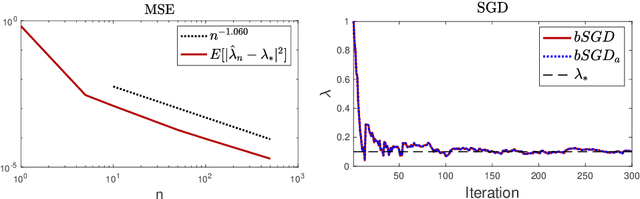
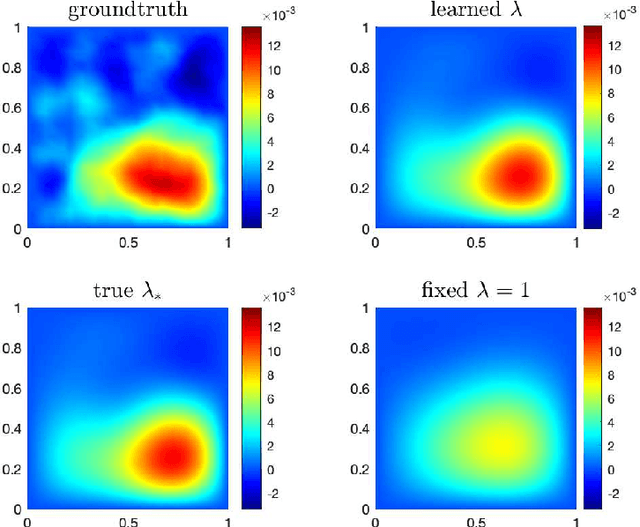
One fundamental problem when solving inverse problems is how to find regularization parameters. This article considers solving this problem using data-driven bilevel optimization, i.e. we consider the adaptive learning of the regularization parameter from data by means of optimization. This approach can be interpreted as solving an empirical risk minimization problem, and we analyze its performance in the large data sample size limit for general nonlinear problems. To reduce the associated computational cost, online numerical schemes are derived using the stochastic gradient method. We prove convergence of these numerical schemes under suitable assumptions on the forward problem. Numerical experiments are presented illustrating the theoretical results and demonstrating the applicability and efficiency of the proposed approaches for various linear and nonlinear inverse problems, including Darcy flow, the eikonal equation, and an image denoising example.