 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActive Flow Expansion for Out-of-Distribution Discovery: from Theory to Molecules
Jun 07, 2026Standard flow and diffusion pre-training matches the distribution of available data (e.g., molecules), which often covers only a small fraction of the valid design space. In generative discovery, however, one aims to sample valid new-to-nature designs, assigned negligible probability under, and thus inaccessible to, standard models fitted to the observed data. To overcome this limitation, we depart from data distribution matching and view a generative model through its generable set: the region it covers with non-negligible probability. This allows to introduce a new learning principle for out-of-distribution flow modeling: enlarging a model's generable set to increase coverage of the valid design space. We propose Active Flow Expansion (ActFlow), a continued pre-training method that employs verifier feedback to expand a pre-trained model over new valid regions by iteratively adapting to synthetic data generated through active exploration in the learned flow representation. Theoretically, we establish to our knowledge first-of-their-kind statistical learning guarantees for out-of-distribution flow modeling, analyzing generable set expansion as a local-to-global reachability process over a learned representation. Empirically, we assess ActFlow with suitable out-of-distribution generative modeling metrics across small organic molecules, mid-sized drug-like molecules, therapeutic peptides, and protein sequence design tasks. Results show that ActFlow expands valid coverage far beyond the region modeled by the initial pre-trained model, significantly outperforming widely adopted synthetic flow pre-training methods.
Constrained Flow Optimization via Sequential Fine Tuning for Molecular Design
May 28, 2026Adapting generative foundation models, in particular diffusion and flow models, to optimize given reward functions (e.g., binding affinity) while satisfying constraints (e.g., molecular synthesizability) is fundamental for their adoption in real-world scientific discovery applications such as molecular design or protein engineering. While recent works have introduced scalable methods for reward-guided fine-tuning of such models via reinforcement learning and control schemes, it remains an open problem how to algorithmically trade-off reward maximization and constraint satisfaction in a reliable and predictable manner. Motivated by this challenge, we first present a rigorous framework for Constrained Generative Optimization, which brings an optimization viewpoint to the introduced adaptation problem and retrieves the relevant task of constrained generation as a sub-case. Then, we introduce Constrained Flow Optimization (CFO), an algorithm that automatically and provably balances reward maximization and constraint satisfaction by reducing the original problem to sequential fine-tuning via established, scalable methods. We provide convergence guarantees for constrained generative optimization and constrained generation via CFO. Ultimately, we present an experimental evaluation of CFO on both synthetic, yet illustrative, settings, and a molecular design task. Across these evaluations, CFO achieves consistent increases in reward while ensuring high constraint satisfaction, showcasing its practical utility for constrained generative optimization.
Efficient Tail-Aware Generative Optimization via Flow Model Fine-Tuning
Feb 18, 2026Fine-tuning pre-trained diffusion and flow models to optimize downstream utilities is central to real-world deployment. Existing entropy-regularized methods primarily maximize expected reward, providing no mechanism to shape tail behavior. However, tail control is often essential: the lower tail determines reliability by limiting low-reward failures, while the upper tail enables discovery by prioritizing rare, high-reward outcomes. In this work, we present Tail-aware Flow Fine-Tuning (TFFT), a principled and efficient distributional fine-tuning algorithm based on the Conditional Value-at-Risk (CVaR). We address two distinct tail-shaping goals: right-CVaR for seeking novel samples in the high-reward tail and left-CVaR for controlling worst-case samples in the low-reward tail. Unlike prior approaches that rely on non-linear optimization, we leverage the variational dual formulation of CVaR to decompose it into a decoupled two-stage procedure: a lightweight one-dimensional threshold optimization step, and a single entropy-regularized fine-tuning process via a specific pseudo-reward. This decomposition achieves CVaR fine-tuning efficiently with computational cost comparable to standard expected fine-tuning methods. We demonstrate the effectiveness of TFFT across illustrative experiments, high-dimensional text-to-image generation, and molecular design.
Verifier-Constrained Flow Expansion for Discovery Beyond the Data
Feb 17, 2026Flow and diffusion models are typically pre-trained on limited available data (e.g., molecular samples), covering only a fraction of the valid design space (e.g., the full molecular space). As a consequence, they tend to generate samples from only a narrow portion of the feasible domain. This is a fundamental limitation for scientific discovery applications, where one typically aims to sample valid designs beyond the available data distribution. To this end, we address the challenge of leveraging access to a verifier (e.g., an atomic bonds checker), to adapt a pre-trained flow model so that its induced density expands beyond regions of high data availability, while preserving samples validity. We introduce formal notions of strong and weak verifiers and propose algorithmic frameworks for global and local flow expansion via probability-space optimization. Then, we present Flow Expander (FE), a scalable mirror descent scheme that provably tackles both problems by verifier-constrained entropy maximization over the flow process noised state space. Next, we provide a thorough theoretical analysis of the proposed method, and state convergence guarantees under both idealized and general assumptions. Ultimately, we empirically evaluate our method on both illustrative, yet visually interpretable settings, and on a molecular design task showcasing the ability of FE to expand a pre-trained flow model increasing conformer diversity while preserving validity.
A Unified Density Operator View of Flow Control and Merging
Feb 08, 2026Recent progress in large-scale flow and diffusion models raised two fundamental algorithmic challenges: (i) control-based reward adaptation of pre-trained flows, and (ii) integration of multiple models, i.e., flow merging. While current approaches address them separately, we introduce a unifying probability-space framework that subsumes both as limit cases, and enables reward-guided flow merging, allowing principled, task-aware combination of multiple pre-trained flows (e.g., merging priors while maximizing drug-discovery utilities). Our formulation renders possible to express a rich family of operators over generative models densities, including intersection (e.g., to enforce safety), union (e.g., to compose diverse models), interpolation (e.g., for discovery), their reward-guided counterparts, as well as complex logical expressions via generative circuits. Next, we introduce Reward-Guided Flow Merging (RFM), a mirror-descent scheme that reduces reward-guided flow merging to a sequence of standard fine-tuning problems. Then, we provide first-of-their-kind theoretical guarantees for reward-guided and pure flow merging via RFM. Ultimately, we showcase the capabilities of the proposed method on illustrative settings providing visually interpretable insights, and apply our method to high-dimensional de-novo molecular design and low-energy conformer generation.
Efficient Personalization of Generative Models via Optimal Experimental Design
Dec 22, 2025Preference learning from human feedback has the ability to align generative models with the needs of end-users. Human feedback is costly and time-consuming to obtain, which creates demand for data-efficient query selection methods. This work presents a novel approach that leverages optimal experimental design to ask humans the most informative preference queries, from which we can elucidate the latent reward function modeling user preferences efficiently. We formulate the problem of preference query selection as the one that maximizes the information about the underlying latent preference model. We show that this problem has a convex optimization formulation, and introduce a statistically and computationally efficient algorithm ED-PBRL that is supported by theoretical guarantees and can efficiently construct structured queries such as images or text. We empirically present the proposed framework by personalizing a text-to-image generative model to user-specific styles, showing that it requires less preference queries compared to random query selection.
Provable Maximum Entropy Manifold Exploration via Diffusion Models
Jun 18, 2025

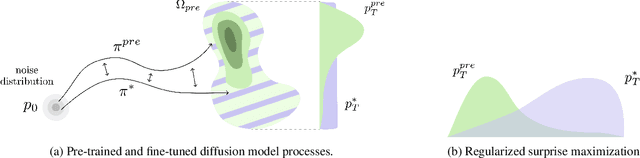

Exploration is critical for solving real-world decision-making problems such as scientific discovery, where the objective is to generate truly novel designs rather than mimic existing data distributions. In this work, we address the challenge of leveraging the representational power of generative models for exploration without relying on explicit uncertainty quantification. We introduce a novel framework that casts exploration as entropy maximization over the approximate data manifold implicitly defined by a pre-trained diffusion model. Then, we present a novel principle for exploration based on density estimation, a problem well-known to be challenging in practice. To overcome this issue and render this method truly scalable, we leverage a fundamental connection between the entropy of the density induced by a diffusion model and its score function. Building on this, we develop an algorithm based on mirror descent that solves the exploration problem as sequential fine-tuning of a pre-trained diffusion model. We prove its convergence to the optimal exploratory diffusion model under realistic assumptions by leveraging recent understanding of mirror flows. Finally, we empirically evaluate our approach on both synthetic and high-dimensional text-to-image diffusion, demonstrating promising results.
Geometric Active Exploration in Markov Decision Processes: the Benefit of Abstraction
Jul 18, 2024

How can a scientist use a Reinforcement Learning (RL) algorithm to design experiments over a dynamical system's state space? In the case of finite and Markovian systems, an area called Active Exploration (AE) relaxes the optimization problem of experiments design into Convex RL, a generalization of RL admitting a wider notion of reward. Unfortunately, this framework is currently not scalable and the potential of AE is hindered by the vastness of experiment spaces typical of scientific discovery applications. However, these spaces are often endowed with natural geometries, e.g., permutation invariance in molecular design, that an agent could leverage to improve the statistical and computational efficiency of AE. To achieve this, we bridge AE and MDP homomorphisms, which offer a way to exploit known geometric structures via abstraction. Towards this goal, we make two fundamental contributions: we extend MDP homomorphisms formalism to Convex RL, and we present, to the best of our knowledge, the first analysis that formally captures the benefit of abstraction via homomorphisms on sample efficiency. Ultimately, we propose the Geometric Active Exploration (GAE) algorithm, which we analyse theoretically and experimentally in environments motivated by problems in scientific discovery.
Global Reinforcement Learning: Beyond Linear and Convex Rewards via Submodular Semi-gradient Methods
Jul 13, 2024In classic Reinforcement Learning (RL), the agent maximizes an additive objective of the visited states, e.g., a value function. Unfortunately, objectives of this type cannot model many real-world applications such as experiment design, exploration, imitation learning, and risk-averse RL to name a few. This is due to the fact that additive objectives disregard interactions between states that are crucial for certain tasks. To tackle this problem, we introduce Global RL (GRL), where rewards are globally defined over trajectories instead of locally over states. Global rewards can capture negative interactions among states, e.g., in exploration, via submodularity, positive interactions, e.g., synergetic effects, via supermodularity, while mixed interactions via combinations of them. By exploiting ideas from submodular optimization, we propose a novel algorithmic scheme that converts any GRL problem to a sequence of classic RL problems and solves it efficiently with curvature-dependent approximation guarantees. We also provide hardness of approximation results and empirically demonstrate the effectiveness of our method on several GRL instances.
Exploiting Causal Graph Priors with Posterior Sampling for Reinforcement Learning
Oct 11, 2023

Posterior sampling allows the exploitation of prior knowledge of the environment's transition dynamics to improve the sample efficiency of reinforcement learning. The prior is typically specified as a class of parametric distributions, a task that can be cumbersome in practice, often resulting in the choice of uninformative priors. In this work, we propose a novel posterior sampling approach in which the prior is given as a (partial) causal graph over the environment's variables. The latter is often more natural to design, such as listing known causal dependencies between biometric features in a medical treatment study. Specifically, we propose a hierarchical Bayesian procedure, called C-PSRL, simultaneously learning the full causal graph at the higher level and the parameters of the resulting factored dynamics at the lower level. For this procedure, we provide an analysis of its Bayesian regret, which explicitly connects the regret rate with the degree of prior knowledge. Our numerical evaluation conducted in illustrative domains confirms that C-PSRL strongly improves the efficiency of posterior sampling with an uninformative prior while performing close to posterior sampling with the full causal graph.