 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRHOBIN Challenge: Reconstruction of Human Object Interaction
Jan 07, 2024Modeling the interaction between humans and objects has been an emerging research direction in recent years. Capturing human-object interaction is however a very challenging task due to heavy occlusion and complex dynamics, which requires understanding not only 3D human pose, and object pose but also the interaction between them. Reconstruction of 3D humans and objects has been two separate research fields in computer vision for a long time. We hence proposed the first RHOBIN challenge: reconstruction of human-object interactions in conjunction with the RHOBIN workshop. It was aimed at bringing the research communities of human and object reconstruction as well as interaction modeling together to discuss techniques and exchange ideas. Our challenge consists of three tracks of 3D reconstruction from monocular RGB images with a focus on dealing with challenging interaction scenarios. Our challenge attracted more than 100 participants with more than 300 submissions, indicating the broad interest in the research communities. This paper describes the settings of our challenge and discusses the winning methods of each track in more detail. We observe that the human reconstruction task is becoming mature even under heavy occlusion settings while object pose estimation and joint reconstruction remain challenging tasks. With the growing interest in interaction modeling, we hope this report can provide useful insights and foster future research in this direction. Our workshop website can be found at \href{https://rhobin-challenge.github.io/}{https://rhobin-challenge.github.io/}.
Geometric Awareness in Neural Fields for 3D Human Registration
Dec 21, 2023Aligning a template to 3D human point clouds is a long-standing problem crucial for tasks like animation, reconstruction, and enabling supervised learning pipelines. Recent data-driven methods leverage predicted surface correspondences; however, they are not robust to varied poses or distributions. In contrast, industrial solutions often rely on expensive manual annotations or multi-view capturing systems. Recently, neural fields have shown promising results, but their purely data-driven nature lacks geometric awareness, often resulting in a trivial misalignment of the template registration. In this work, we propose two solutions: LoVD, a novel neural field model that predicts the direction towards the localized SMPL vertices on the target surface; and INT, the first self-supervised task dedicated to neural fields that, at test time, refines the backbone, exploiting the target geometry. We combine them into INLoVD, a robust 3D Human body registration pipeline trained on a large MoCap dataset. INLoVD is efficient (takes less than a minute), solidly achieves the state of the art over public benchmarks, and provides unprecedented generalization on out-of-distribution data. We will release code and checkpoints in \url{url}.
Paint-it: Text-to-Texture Synthesis via Deep Convolutional Texture Map Optimization and Physically-Based Rendering
Dec 18, 2023



We present Paint-it, a text-driven high-fidelity texture map synthesis method for 3D meshes via neural re-parameterized texture optimization. Paint-it synthesizes texture maps from a text description by synthesis-through-optimization, exploiting the Score-Distillation Sampling (SDS). We observe that directly applying SDS yields undesirable texture quality due to its noisy gradients. We reveal the importance of texture parameterization when using SDS. Specifically, we propose Deep Convolutional Physically-Based Rendering (DC-PBR) parameterization, which re-parameterizes the physically-based rendering (PBR) texture maps with randomly initialized convolution-based neural kernels, instead of a standard pixel-based parameterization. We show that DC-PBR inherently schedules the optimization curriculum according to texture frequency and naturally filters out the noisy signals from SDS. In experiments, Paint-it obtains remarkable quality PBR texture maps within 15 min., given only a text description. We demonstrate the generalizability and practicality of Paint-it by synthesizing high-quality texture maps for large-scale mesh datasets and showing test-time applications such as relighting and material control using a popular graphics engine. Project page: https://kim-youwang.github.io/paint-it
Template Free Reconstruction of Human-object Interaction with Procedural Interaction Generation
Dec 12, 2023Reconstructing human-object interaction in 3D from a single RGB image is a challenging task and existing data driven methods do not generalize beyond the objects present in the carefully curated 3D interaction datasets. Capturing large-scale real data to learn strong interaction and 3D shape priors is very expensive due to the combinatorial nature of human-object interactions. In this paper, we propose ProciGen (Procedural interaction Generation), a method to procedurally generate datasets with both, plausible interaction and diverse object variation. We generate 1M+ human-object interaction pairs in 3D and leverage this large-scale data to train our HDM (Hierarchical Diffusion Model), a novel method to reconstruct interacting human and unseen objects, without any templates. Our HDM is an image-conditioned diffusion model that learns both realistic interaction and highly accurate human and object shapes. Experiments show that our HDM trained with ProciGen significantly outperforms prior methods that requires template meshes and that our dataset allows training methods with strong generalization ability to unseen object instances. Our code and data will be publicly released at: https://virtualhumans.mpi-inf.mpg.de/procigen-hdm.
GAN-Avatar: Controllable Personalized GAN-based Human Head Avatar
Nov 22, 2023



Digital humans and, especially, 3D facial avatars have raised a lot of attention in the past years, as they are the backbone of several applications like immersive telepresence in AR or VR. Despite the progress, facial avatars reconstructed from commodity hardware are incomplete and miss out on parts of the side and back of the head, severely limiting the usability of the avatar. This limitation in prior work stems from their requirement of face tracking, which fails for profile and back views. To address this issue, we propose to learn person-specific animatable avatars from images without assuming to have access to precise facial expression tracking. At the core of our method, we leverage a 3D-aware generative model that is trained to reproduce the distribution of facial expressions from the training data. To train this appearance model, we only assume to have a collection of 2D images with the corresponding camera parameters. For controlling the model, we learn a mapping from 3DMM facial expression parameters to the latent space of the generative model. This mapping can be learned by sampling the latent space of the appearance model and reconstructing the facial parameters from a normalized frontal view, where facial expression estimation performs well. With this scheme, we decouple 3D appearance reconstruction and animation control to achieve high fidelity in image synthesis. In a series of experiments, we compare our proposed technique to state-of-the-art monocular methods and show superior quality while not requiring expression tracking of the training data.
NSF: Neural Surface Fields for Human Modeling from Monocular Depth
Aug 30, 2023Obtaining personalized 3D animatable avatars from a monocular camera has several real world applications in gaming, virtual try-on, animation, and VR/XR, etc. However, it is very challenging to model dynamic and fine-grained clothing deformations from such sparse data. Existing methods for modeling 3D humans from depth data have limitations in terms of computational efficiency, mesh coherency, and flexibility in resolution and topology. For instance, reconstructing shapes using implicit functions and extracting explicit meshes per frame is computationally expensive and cannot ensure coherent meshes across frames. Moreover, predicting per-vertex deformations on a pre-designed human template with a discrete surface lacks flexibility in resolution and topology. To overcome these limitations, we propose a novel method `\keyfeature: Neural Surface Fields' for modeling 3D clothed humans from monocular depth. NSF defines a neural field solely on the base surface which models a continuous and flexible displacement field. NSF can be adapted to the base surface with different resolution and topology without retraining at inference time. Compared to existing approaches, our method eliminates the expensive per-frame surface extraction while maintaining mesh coherency, and is capable of reconstructing meshes with arbitrary resolution without retraining. To foster research in this direction, we release our code in project page at: https://yuxuan-xue.com/nsf.
Object pop-up: Can we infer 3D objects and their poses from human interactions alone?
Jun 01, 2023The intimate entanglement between objects affordances and human poses is of large interest, among others, for behavioural sciences, cognitive psychology, and Computer Vision communities. In recent years, the latter has developed several object-centric approaches: starting from items, learning pipelines synthesizing human poses and dynamics in a realistic way, satisfying both geometrical and functional expectations. However, the inverse perspective is significantly less explored: Can we infer 3D objects and their poses from human interactions alone? Our investigation follows this direction, showing that a generic 3D human point cloud is enough to pop up an unobserved object, even when the user is just imitating a functionality (e.g., looking through a binocular) without involving a tangible counterpart. We validate our method qualitatively and quantitatively, with synthetic data and sequences acquired for the task, showing applicability for XR/VR. The code is available at https://github.com/ptrvilya/object-popup.
Generating Continual Human Motion in Diverse 3D Scenes
Apr 11, 2023We introduce a method to synthesize animator guided human motion across 3D scenes. Given a set of sparse (3 or 4) joint locations (such as the location of a person's hand and two feet) and a seed motion sequence in a 3D scene, our method generates a plausible motion sequence starting from the seed motion while satisfying the constraints imposed by the provided keypoints. We decompose the continual motion synthesis problem into walking along paths and transitioning in and out of the actions specified by the keypoints, which enables long generation of motions that satisfy scene constraints without explicitly incorporating scene information. Our method is trained only using scene agnostic mocap data. As a result, our approach is deployable across 3D scenes with various geometries. For achieving plausible continual motion synthesis without drift, our key contribution is to generate motion in a goal-centric canonical coordinate frame where the next immediate target is situated at the origin. Our model can generate long sequences of diverse actions such as grabbing, sitting and leaning chained together in arbitrary order, demonstrated on scenes of varying geometry: HPS, Replica, Matterport, ScanNet and scenes represented using NeRFs. Several experiments demonstrate that our method outperforms existing methods that navigate paths in 3D scenes.
Visibility Aware Human-Object Interaction Tracking from Single RGB Camera
Mar 29, 2023Capturing the interactions between humans and their environment in 3D is important for many applications in robotics, graphics, and vision. Recent works to reconstruct the 3D human and object from a single RGB image do not have consistent relative translation across frames because they assume a fixed depth. Moreover, their performance drops significantly when the object is occluded. In this work, we propose a novel method to track the 3D human, object, contacts between them, and their relative translation across frames from a single RGB camera, while being robust to heavy occlusions. Our method is built on two key insights. First, we condition our neural field reconstructions for human and object on per-frame SMPL model estimates obtained by pre-fitting SMPL to a video sequence. This improves neural reconstruction accuracy and produces coherent relative translation across frames. Second, human and object motion from visible frames provides valuable information to infer the occluded object. We propose a novel transformer-based neural network that explicitly uses object visibility and human motion to leverage neighbouring frames to make predictions for the occluded frames. Building on these insights, our method is able to track both human and object robustly even under occlusions. Experiments on two datasets show that our method significantly improves over the state-of-the-art methods. Our code and pretrained models are available at: https://virtualhumans.mpi-inf.mpg.de/VisTracker
Skeleton-free Pose Transfer for Stylized 3D Characters
Jul 28, 2022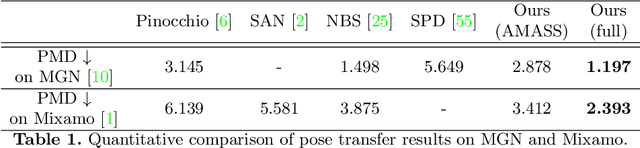
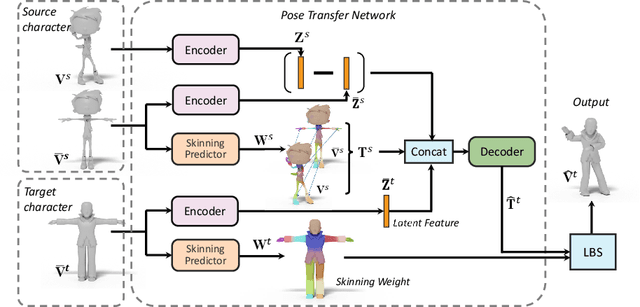
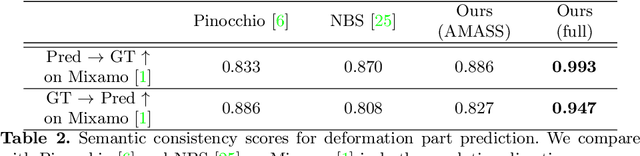

We present the first method that automatically transfers poses between stylized 3D characters without skeletal rigging. In contrast to previous attempts to learn pose transformations on fixed or topology-equivalent skeleton templates, our method focuses on a novel scenario to handle skeleton-free characters with diverse shapes, topologies, and mesh connectivities. The key idea of our method is to represent the characters in a unified articulation model so that the pose can be transferred through the correspondent parts. To achieve this, we propose a novel pose transfer network that predicts the character skinning weights and deformation transformations jointly to articulate the target character to match the desired pose. Our method is trained in a semi-supervised manner absorbing all existing character data with paired/unpaired poses and stylized shapes. It generalizes well to unseen stylized characters and inanimate objects. We conduct extensive experiments and demonstrate the effectiveness of our method on this novel task.