 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBehavior Regularized Offline Reinforcement Learning
Nov 26, 2019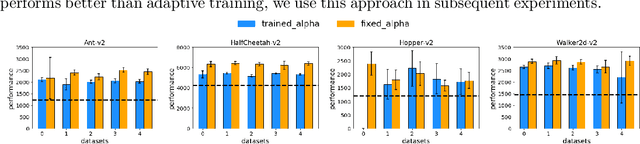
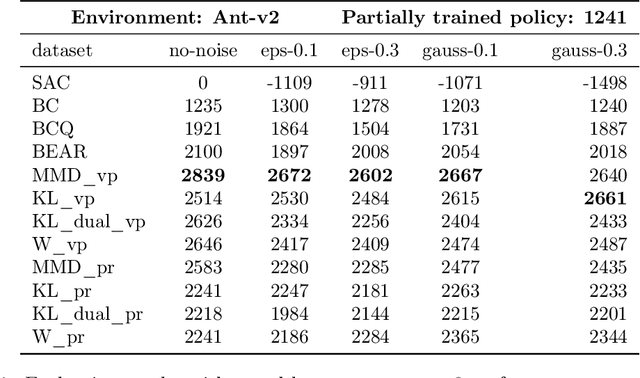
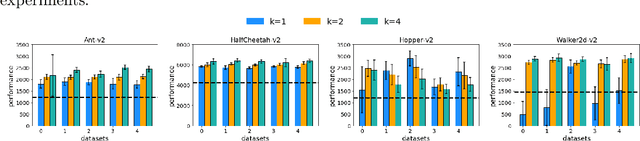
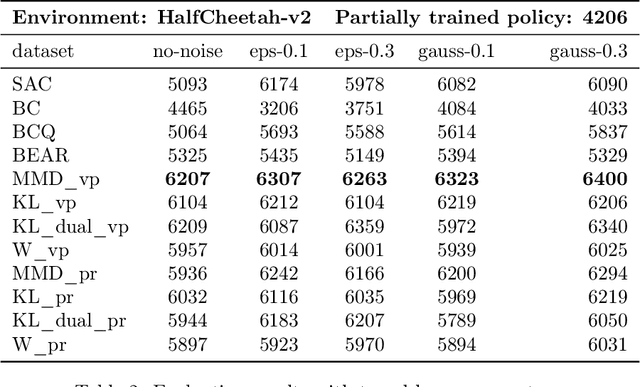
In reinforcement learning (RL) research, it is common to assume access to direct online interactions with the environment. However in many real-world applications, access to the environment is limited to a fixed offline dataset of logged experience. In such settings, standard RL algorithms have been shown to diverge or otherwise yield poor performance. Accordingly, recent work has suggested a number of remedies to these issues. In this work, we introduce a general framework, behavior regularized actor critic (BRAC), to empirically evaluate recently proposed methods as well as a number of simple baselines across a variety of offline continuous control tasks. Surprisingly, we find that many of the technical complexities introduced in recent methods are unnecessary to achieve strong performance. Additional ablations provide insights into which design choices matter most in the offline RL setting.
Don't Blame the ELBO! A Linear VAE Perspective on Posterior Collapse
Nov 06, 2019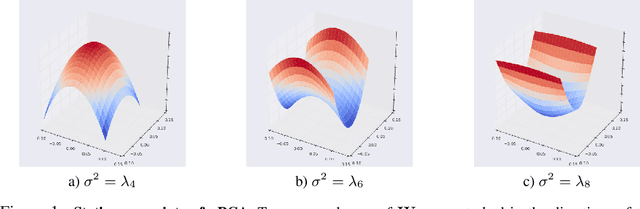
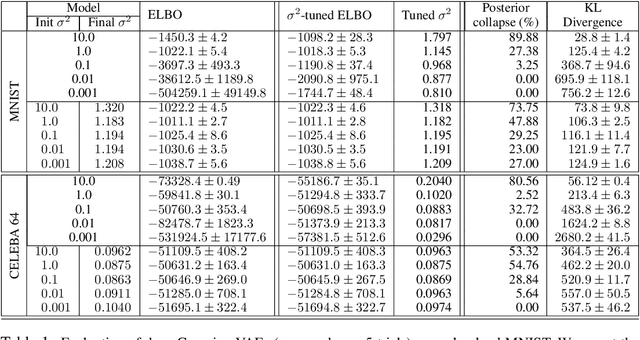
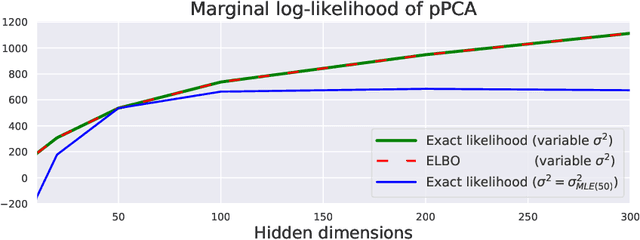
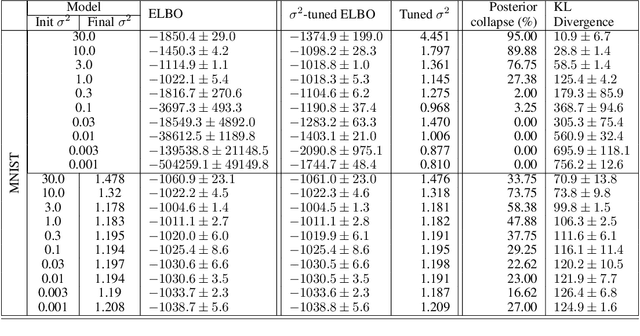
Posterior collapse in Variational Autoencoders (VAEs) arises when the variational posterior distribution closely matches the prior for a subset of latent variables. This paper presents a simple and intuitive explanation for posterior collapse through the analysis of linear VAEs and their direct correspondence with Probabilistic PCA (pPCA). We explain how posterior collapse may occur in pPCA due to local maxima in the log marginal likelihood. Unexpectedly, we prove that the ELBO objective for the linear VAE does not introduce additional spurious local maxima relative to log marginal likelihood. We show further that training a linear VAE with exact variational inference recovers an identifiable global maximum corresponding to the principal component directions. Empirically, we find that our linear analysis is predictive even for high-capacity, non-linear VAEs and helps explain the relationship between the observation noise, local maxima, and posterior collapse in deep Gaussian VAEs.
Energy-Inspired Models: Learning with Sampler-Induced Distributions
Oct 31, 2019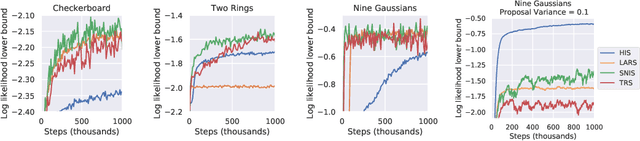
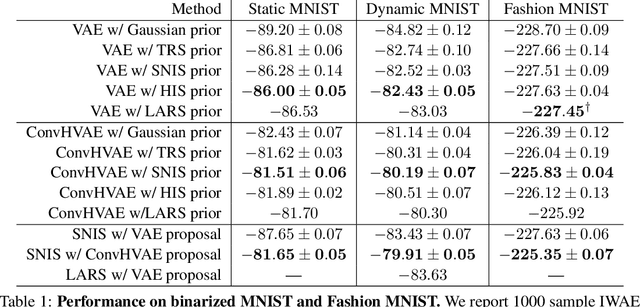
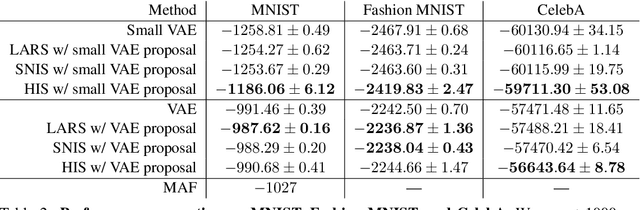
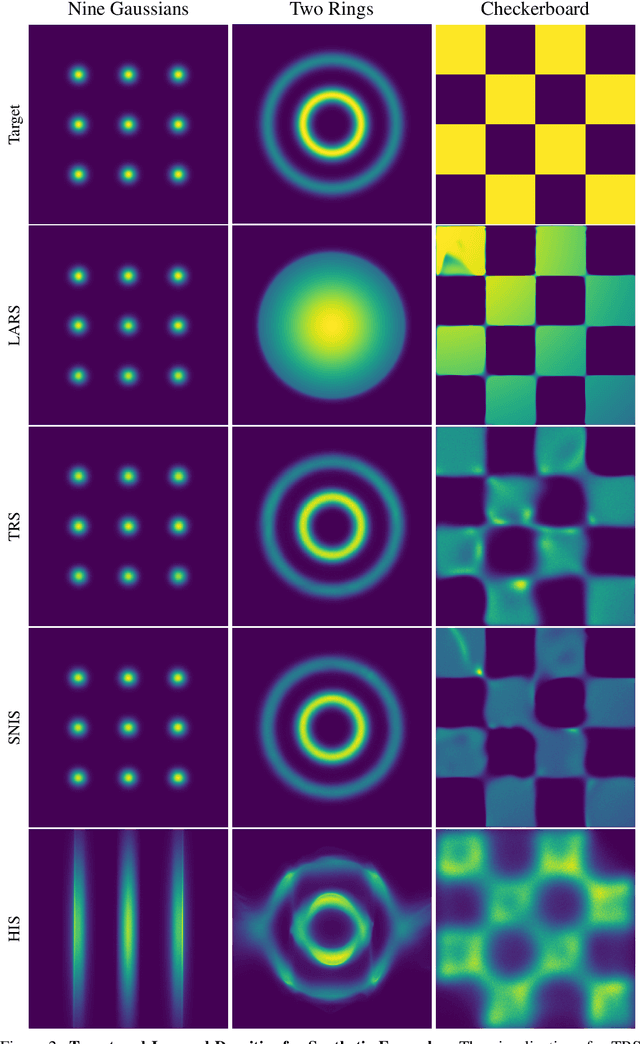
Energy-based models (EBMs) are powerful probabilistic models, but suffer from intractable sampling and density evaluation due to the partition function. As a result, inference in EBMs relies on approximate sampling algorithms, leading to a mismatch between the model and inference. Motivated by this, we consider the sampler-induced distribution as the model of interest and maximize the likelihood of this model. This yields a class of energy-inspired models (EIMs) that incorporate learned energy functions while still providing exact samples and tractable log-likelihood lower bounds. We describe and evaluate three instantiations of such models based on truncated rejection sampling, self-normalized importance sampling, and Hamiltonian importance sampling. These models outperform or perform comparably to the recently proposed Learned Accept/Reject Sampling algorithm and provide new insights on ranking Noise Contrastive Estimation and Contrastive Predictive Coding. Moreover, EIMs allow us to generalize a recent connection between multi-sample variational lower bounds and auxiliary variable variational inference. We show how recent variational bounds can be unified with EIMs as the variational family.
Reinforcement Learning Driven Heuristic Optimization
Jun 16, 2019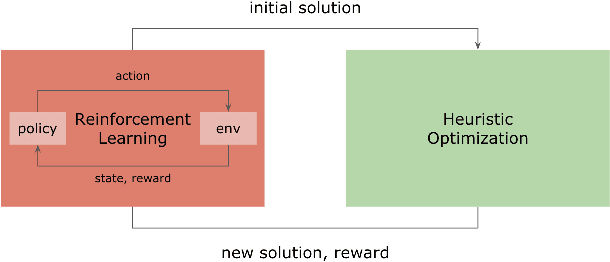


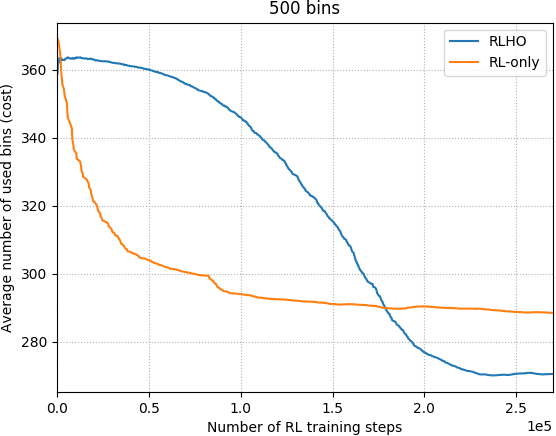
Heuristic algorithms such as simulated annealing, Concorde, and METIS are effective and widely used approaches to find solutions to combinatorial optimization problems. However, they are limited by the high sample complexity required to reach a reasonable solution from a cold-start. In this paper, we introduce a novel framework to generate better initial solutions for heuristic algorithms using reinforcement learning (RL), named RLHO. We augment the ability of heuristic algorithms to greedily improve upon an existing initial solution generated by RL, and demonstrate novel results where RL is able to leverage the performance of heuristics as a learning signal to generate better initialization. We apply this framework to Proximal Policy Optimization (PPO) and Simulated Annealing (SA). We conduct a series of experiments on the well-known NP-complete bin packing problem, and show that the RLHO method outperforms our baselines. We show that on the bin packing problem, RL can learn to help heuristics perform even better, allowing us to combine the best parts of both approaches.
Stabilizing Off-Policy Q-Learning via Bootstrapping Error Reduction
Jun 03, 2019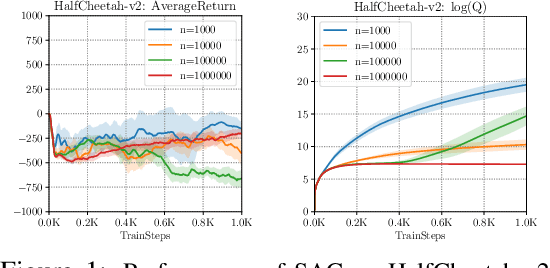
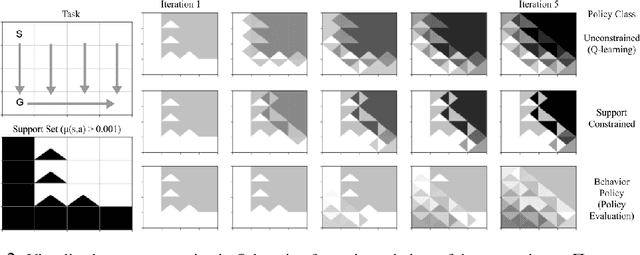
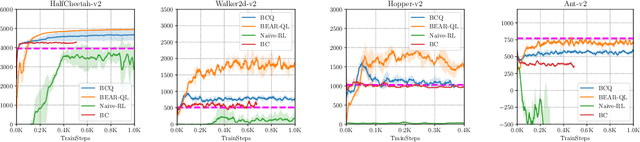
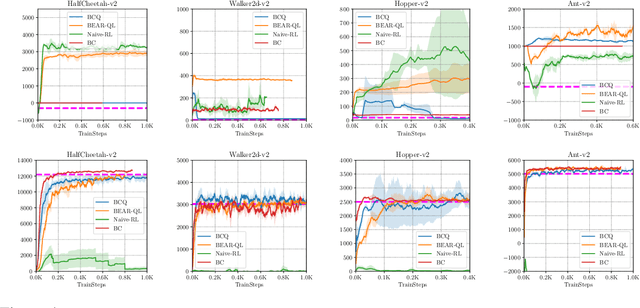
Off-policy reinforcement learning aims to leverage experience collected from prior policies for sample-efficient learning. However, in practice, commonly used off-policy approximate dynamic programming methods based on Q-learning and actor-critic methods are highly sensitive to the data distribution, and can make only limited progress without collecting additional on-policy data. As a step towards more robust off-policy algorithms, we study the setting where the off-policy experience is fixed and there is no further interaction with the environment. We identify bootstrapping error as a key source of instability in current methods. Bootstrapping error is due to bootstrapping from actions that lie outside of the training data distribution, and it accumulates via the Bellman backup operator. We theoretically analyze bootstrapping error, and demonstrate how carefully constraining action selection in the backup can mitigate it. Based on our analysis, we propose a practical algorithm, bootstrapping error accumulation reduction (BEAR). We demonstrate that BEAR is able to learn robustly from different off-policy distributions, including random and suboptimal demonstrations, on a range of continuous control tasks.
On Variational Bounds of Mutual Information
May 16, 2019



Estimating and optimizing Mutual Information (MI) is core to many problems in machine learning; however, bounding MI in high dimensions is challenging. To establish tractable and scalable objectives, recent work has turned to variational bounds parameterized by neural networks, but the relationships and tradeoffs between these bounds remains unclear. In this work, we unify these recent developments in a single framework. We find that the existing variational lower bounds degrade when the MI is large, exhibiting either high bias or high variance. To address this problem, we introduce a continuum of lower bounds that encompasses previous bounds and flexibly trades off bias and variance. On high-dimensional, controlled problems, we empirically characterize the bias and variance of the bounds and their gradients and demonstrate the effectiveness of our new bounds for estimation and representation learning.
Learning to Walk via Deep Reinforcement Learning
Mar 25, 2019
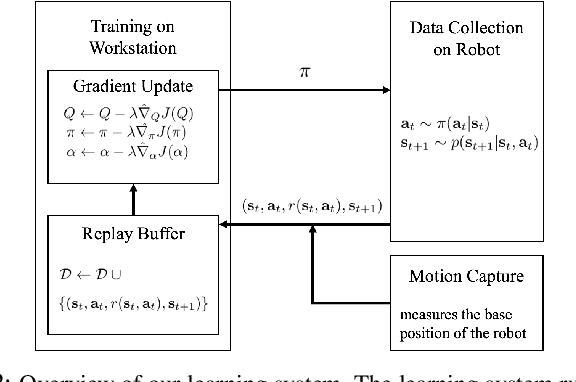
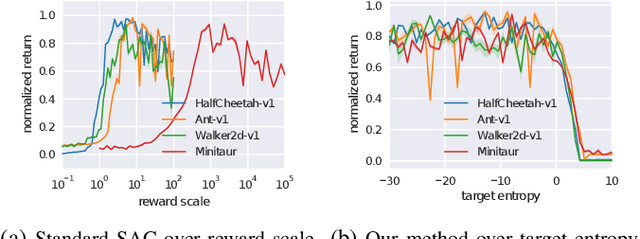
Deep reinforcement learning offers the promise of automatic acquisition of robotic control policies that directly map sensory inputs to low-level actions. In the domain of robotic locomotion, it could make it possible for locomotion skills to be learned with minimal engineering and without even needing to construct a model of the robot. However, applying deep reinforcement learning methods on real-world robots is exceptionally difficult, due both to the sample complexity and, just as importantly, the sensitivity of such methods to hyperparameters. While hyperparameter tuning can be performed in parallel in simulated domains, it is usually impractical to tune hyperparameters directly on real-world robotic platforms, especially legged platforms like quadrupedal robots that can be damaged through extensive trial-and-error learning. We develop a stable deep RL algorithm that extends soft actor-critic, requires minimal hyperparameter tuning, and requires only a modest number of trials to learn multilayer neural network policies. We then apply this method to learn walking gaits on a real-world Minitaur robot. Our method can learn to walk from scratch directly in the real world in two hours of training, without any model or simulation, and the resulting policy is robust to moderate variations in the environment. We further show that our algorithm achieves state-of-the-art performance on four standard simulated benchmarks.
Model-Based Reinforcement Learning for Atari
Mar 05, 2019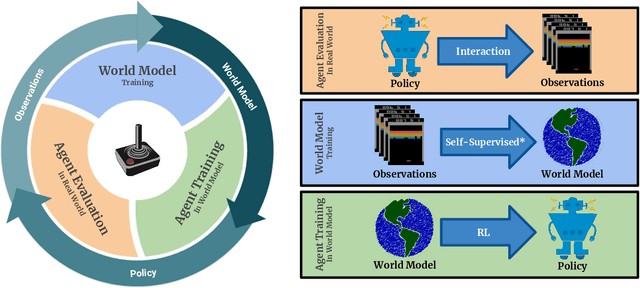
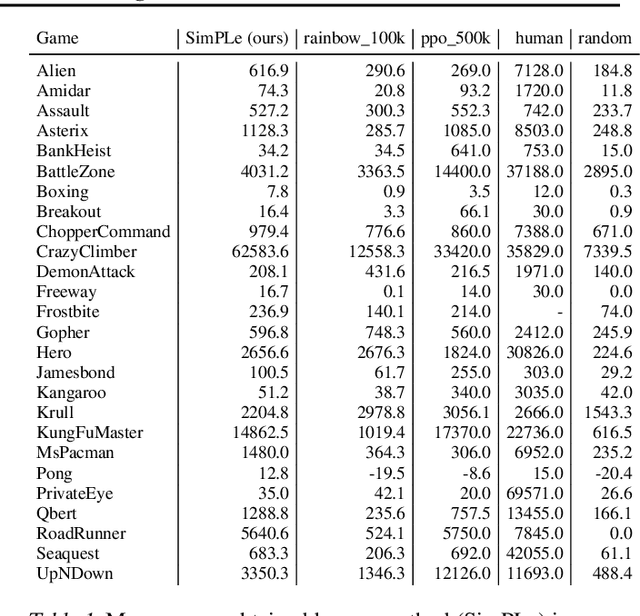
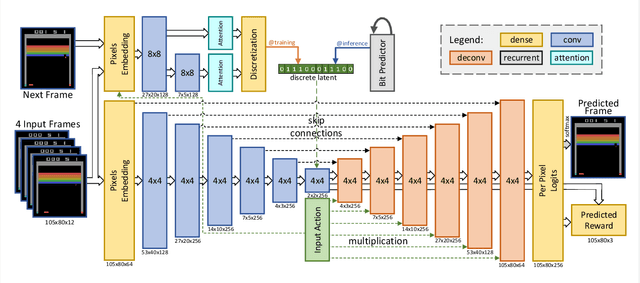
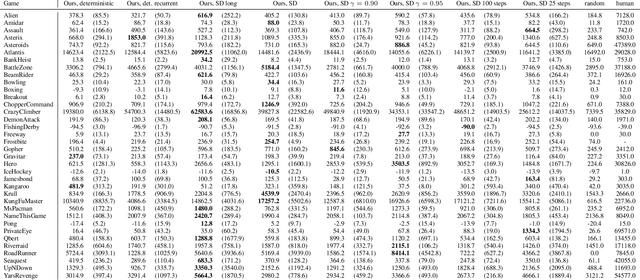
Model-free reinforcement learning (RL) can be used to learn effective policies for complex tasks, such as Atari games, even from image observations. However, this typically requires very large amounts of interaction -- substantially more, in fact, than a human would need to learn the same games. How can people learn so quickly? Part of the answer may be that people can learn how the game works and predict which actions will lead to desirable outcomes. In this paper, we explore how video prediction models can similarly enable agents to solve Atari games with orders of magnitude fewer interactions than model-free methods. We describe Simulated Policy Learning (SimPLe), a complete model-based deep RL algorithm based on video prediction models and present a comparison of several model architectures, including a novel architecture that yields the best results in our setting. Our experiments evaluate SimPLe on a range of Atari games and achieve competitive results with only 100K interactions between the agent and the environment (400K frames), which corresponds to about two hours of real-time play.
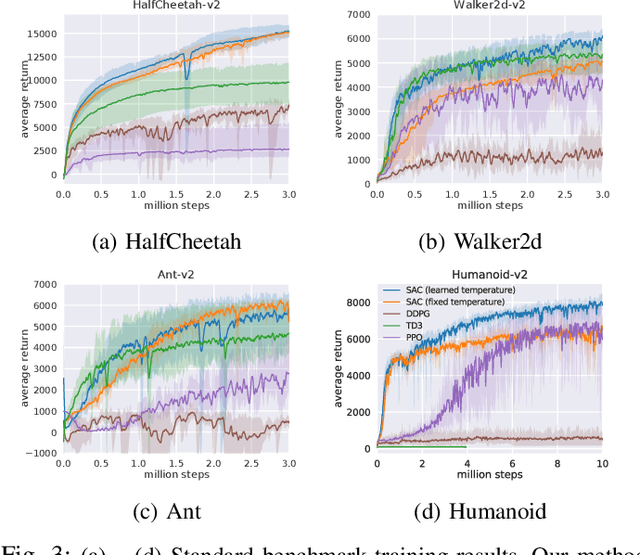
Soft Actor-Critic Algorithms and Applications
Jan 29, 2019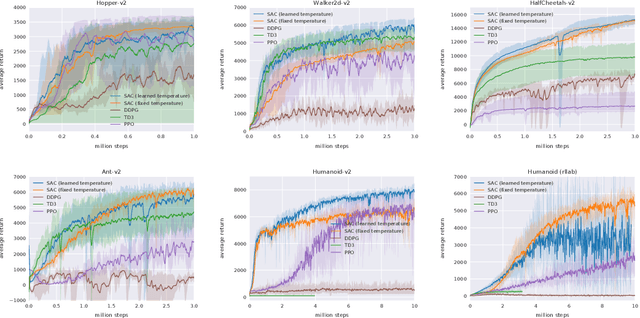



Model-free deep reinforcement learning (RL) algorithms have been successfully applied to a range of challenging sequential decision making and control tasks. However, these methods typically suffer from two major challenges: high sample complexity and brittleness to hyperparameters. Both of these challenges limit the applicability of such methods to real-world domains. In this paper, we describe Soft Actor-Critic (SAC), our recently introduced off-policy actor-critic algorithm based on the maximum entropy RL framework. In this framework, the actor aims to simultaneously maximize expected return and entropy. That is, to succeed at the task while acting as randomly as possible. We extend SAC to incorporate a number of modifications that accelerate training and improve stability with respect to the hyperparameters, including a constrained formulation that automatically tunes the temperature hyperparameter. We systematically evaluate SAC on a range of benchmark tasks, as well as real-world challenging tasks such as locomotion for a quadrupedal robot and robotic manipulation with a dexterous hand. With these improvements, SAC achieves state-of-the-art performance, outperforming prior on-policy and off-policy methods in sample-efficiency and asymptotic performance. Furthermore, we demonstrate that, in contrast to other off-policy algorithms, our approach is very stable, achieving similar performance across different random seeds. These results suggest that SAC is a promising candidate for learning in real-world robotics tasks.
The Laplacian in RL: Learning Representations with Efficient Approximations
Oct 10, 2018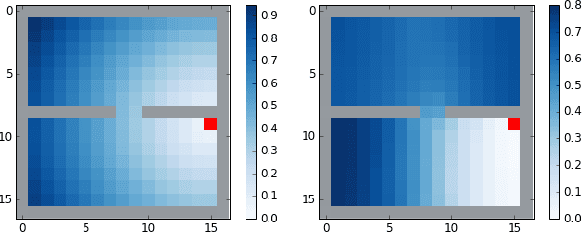
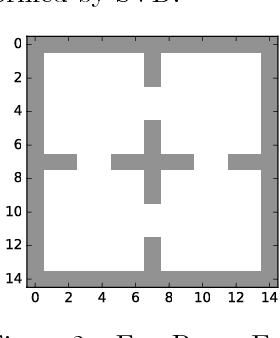
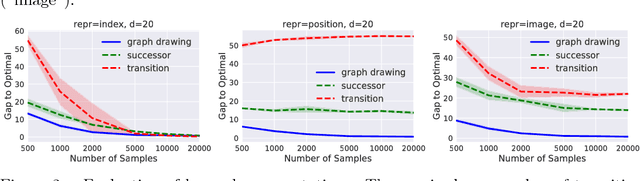
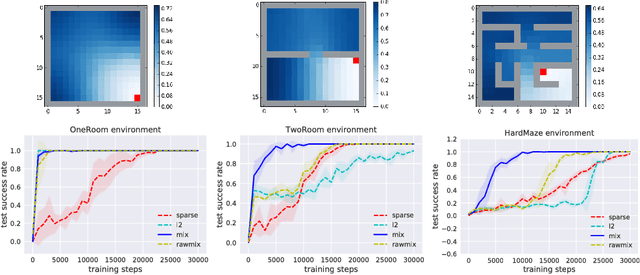
The smallest eigenvectors of the graph Laplacian are well-known to provide a succinct representation of the geometry of a weighted graph. In reinforcement learning (RL), where the weighted graph may be interpreted as the state transition process induced by a behavior policy acting on the environment, approximating the eigenvectors of the Laplacian provides a promising approach to state representation learning. However, existing methods for performing this approximation are ill-suited in general RL settings for two main reasons: First, they are computationally expensive, often requiring operations on large matrices. Second, these methods lack adequate justification beyond simple, tabular, finite-state settings. In this paper, we present a fully general and scalable method for approximating the eigenvectors of the Laplacian in a model-free RL context. We systematically evaluate our approach and empirically show that it generalizes beyond the tabular, finite-state setting. Even in tabular, finite-state settings, its ability to approximate the eigenvectors outperforms previous proposals. Finally, we show the potential benefits of using a Laplacian representation learned using our method in goal-achieving RL tasks, providing evidence that our technique can be used to significantly improve the performance of an RL agent.