 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGuided Policy Search for Parameterized Skills using Adverbs
Oct 23, 2021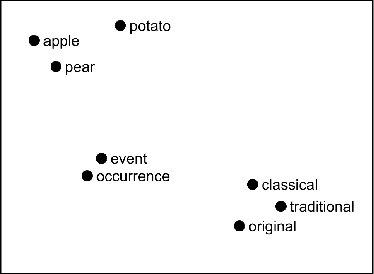
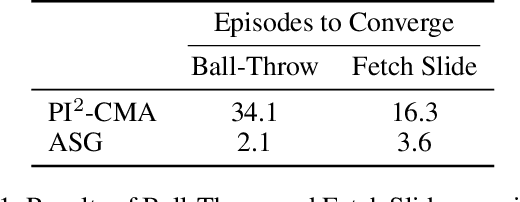
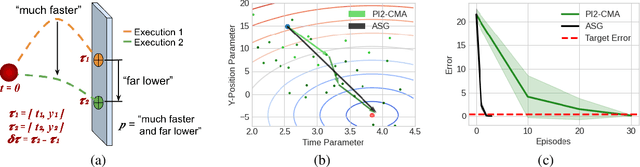
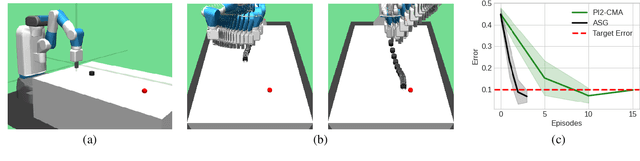
We present a method for using adverb phrases to adjust skill parameters via learned adverb-skill groundings. These groundings allow an agent to use adverb feedback provided by a human to directly update a skill policy, in a manner similar to traditional local policy search methods. We show that our method can be used as a drop-in replacement for these policy search methods when dense reward from the environment is not available but human language feedback is. We demonstrate improved sample efficiency over modern policy search methods in two experiments.
Coarse-Grained Smoothness for RL in Metric Spaces
Oct 23, 2021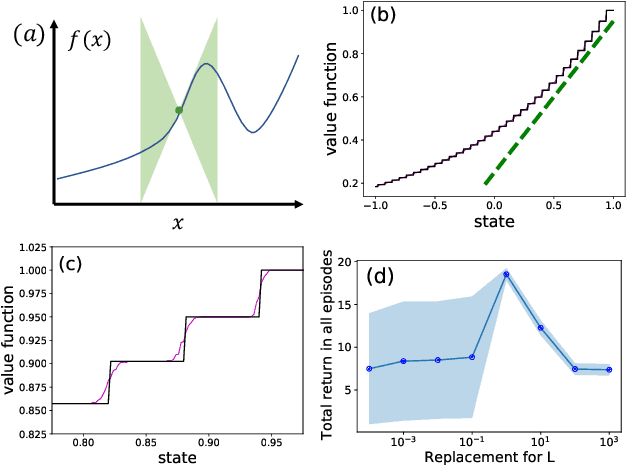
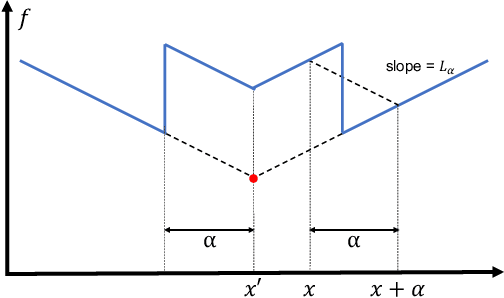
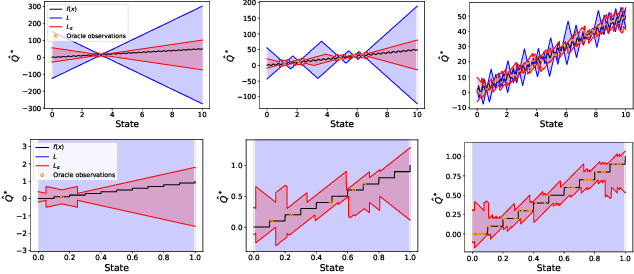
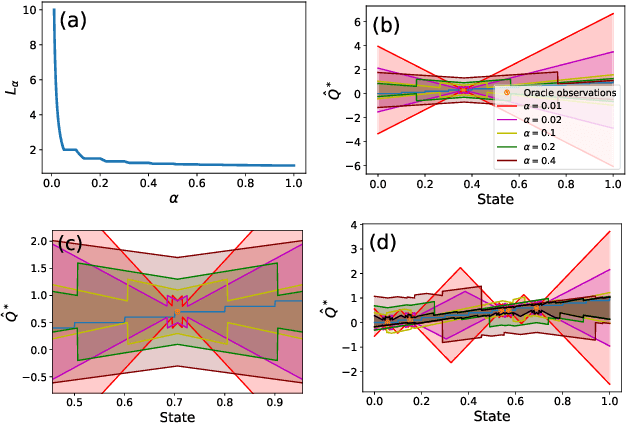
Principled decision-making in continuous state--action spaces is impossible without some assumptions. A common approach is to assume Lipschitz continuity of the Q-function. We show that, unfortunately, this property fails to hold in many typical domains. We propose a new coarse-grained smoothness definition that generalizes the notion of Lipschitz continuity, is more widely applicable, and allows us to compute significantly tighter bounds on Q-functions, leading to improved learning. We provide a theoretical analysis of our new smoothness definition, and discuss its implications and impact on control and exploration in continuous domains.
Towards Optimal Correlational Object Search
Oct 19, 2021
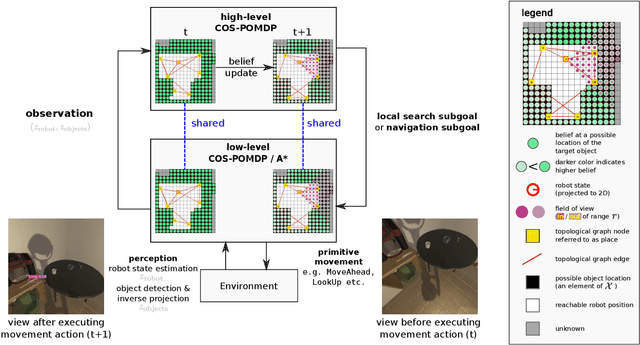


In realistic applications of object search, robots will need to locate target objects in complex environments while coping with unreliable sensors, especially for small or hard-to-detect objects. In such settings, correlational information can be valuable for planning efficiently: when looking for a fork, the robot could start by locating the easier-to-detect refrigerator, since forks would probably be found nearby. Previous approaches to object search with correlational information typically resort to ad-hoc or greedy search strategies. In this paper, we propose the Correlational Object Search POMDP (COS-POMDP), which can be solved to produce search strategies that use correlational information. COS-POMDPs contain a correlation-based observation model that allows us to avoid the exponential blow-up of maintaining a joint belief about all objects, while preserving the optimal solution to this naive, exponential POMDP formulation. We propose a hierarchical planning algorithm to scale up COS-POMDP for practical domains. We conduct experiments using AI2-THOR, a realistic simulator of household environments, as well as YOLOv5, a widely-used object detector. Our results show that, particularly for hard-to-detect objects, such as scrub brush and remote control, our method offers the most robust performance compared to baselines that ignore correlations as well as a greedy, next-best view approach.
Learning to Infer Kinematic Hierarchies for Novel Object Instances
Oct 15, 2021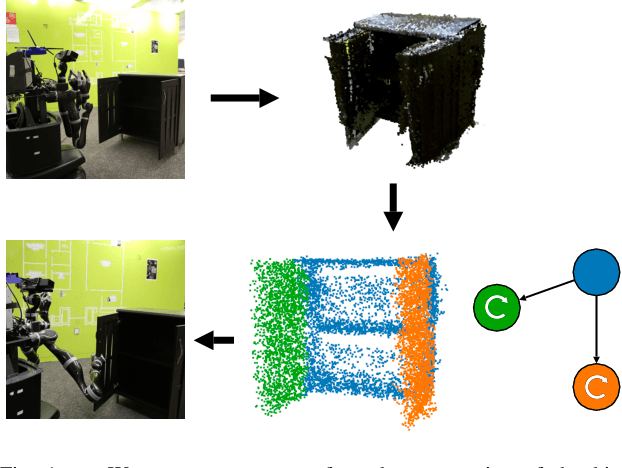
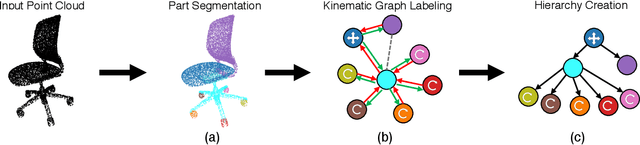
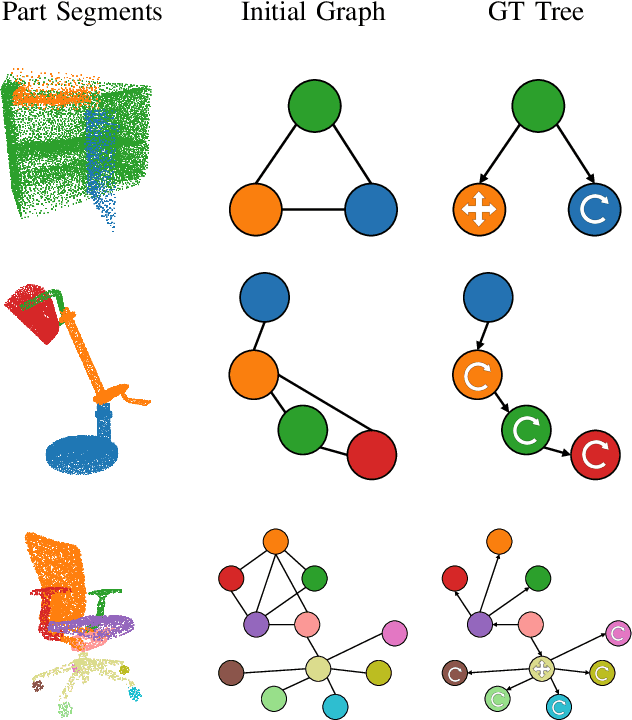
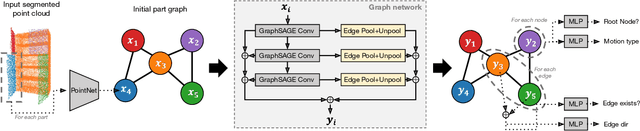
Manipulating an articulated object requires perceiving itskinematic hierarchy: its parts, how each can move, and howthose motions are coupled. Previous work has explored per-ception for kinematics, but none infers a complete kinematichierarchy on never-before-seen object instances, without relyingon a schema or template. We present a novel perception systemthat achieves this goal. Our system infers the moving parts ofan object and the kinematic couplings that relate them. Toinfer parts, it uses a point cloud instance segmentation neuralnetwork and to infer kinematic hierarchies, it uses a graphneural network to predict the existence, direction, and typeof edges (i.e. joints) that relate the inferred parts. We trainthese networks using simulated scans of synthetic 3D models.We evaluate our system on simulated scans of 3D objects, andwe demonstrate a proof-of-concept use of our system to drivereal-world robotic manipulation.
Generalizing to New Domains by Mapping Natural Language to Lifted LTL
Oct 11, 2021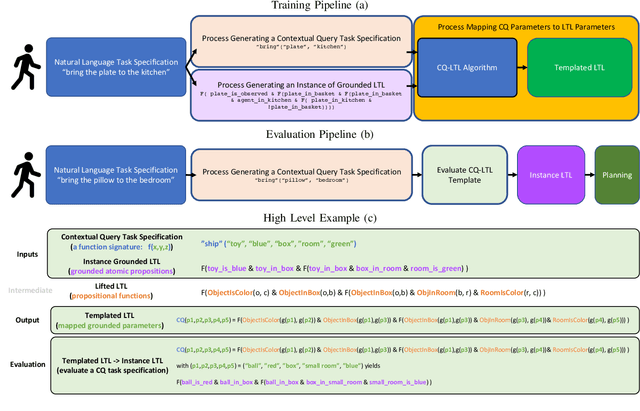

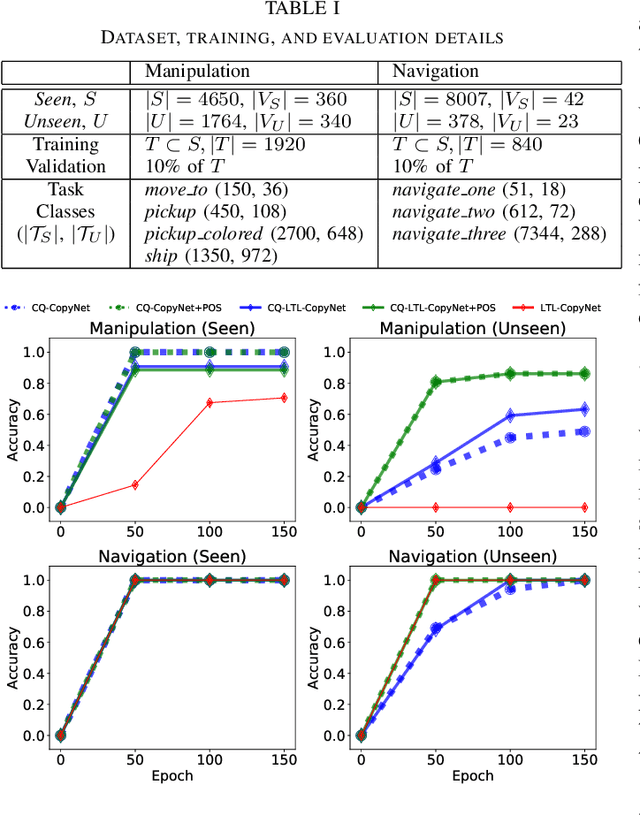
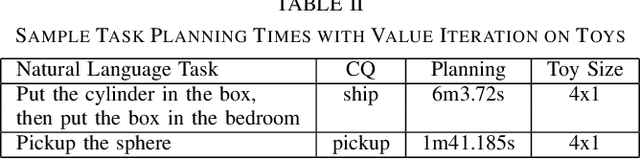
Recent work on using natural language to specify commands to robots has grounded that language to LTL. However, mapping natural language task specifications to LTL task specifications using language models require probability distributions over finite vocabulary. Existing state-of-the-art methods have extended this finite vocabulary to include unseen terms from the input sequence to improve output generalization. However, novel out-of-vocabulary atomic propositions cannot be generated using these methods. To overcome this, we introduce an intermediate contextual query representation which can be learned from single positive task specification examples, associating a contextual query with an LTL template. We demonstrate that this intermediate representation allows for generalization over unseen object references, assuming accurate groundings are available. We compare our method of mapping natural language task specifications to intermediate contextual queries against state-of-the-art CopyNet models capable of translating natural language to LTL, by evaluating whether correct LTL for manipulation and navigation task specifications can be output, and show that our method outperforms the CopyNet model on unseen object references. We demonstrate that the grounded LTL our method outputs can be used for planning in a simulated OO-MDP environment. Finally, we discuss some common failure modes encountered when translating natural language task specifications to grounded LTL.
RMPs for Safe Impedance Control in Contact-Rich Manipulation
Sep 24, 2021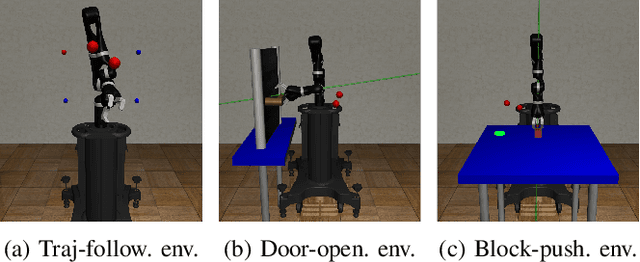
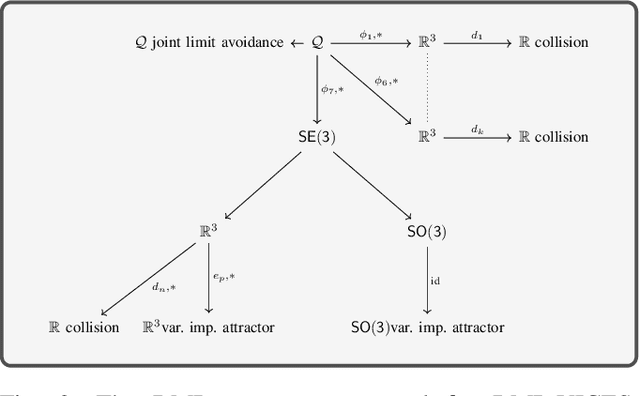

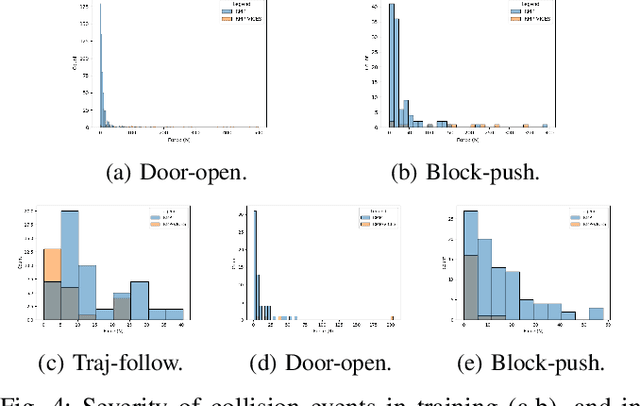
Variable impedance control in operation-space is a promising approach to learning contact-rich manipulation behaviors. One of the main challenges with this approach is producing a manipulation behavior that ensures the safety of the arm and the environment. Such behavior is typically implemented via a reward function that penalizes unsafe actions (e.g. obstacle collision, joint limit extension), but that approach is not always effective and does not result in behaviors that can be reused in slightly different environments. We show how to combine Riemannian Motion Policies, a class of policies that dynamically generate motion in the presence of safety and collision constraints, with variable impedance operation-space control to learn safer contact-rich manipulation behaviors.
HAC Explore: Accelerating Exploration with Hierarchical Reinforcement Learning
Aug 12, 2021
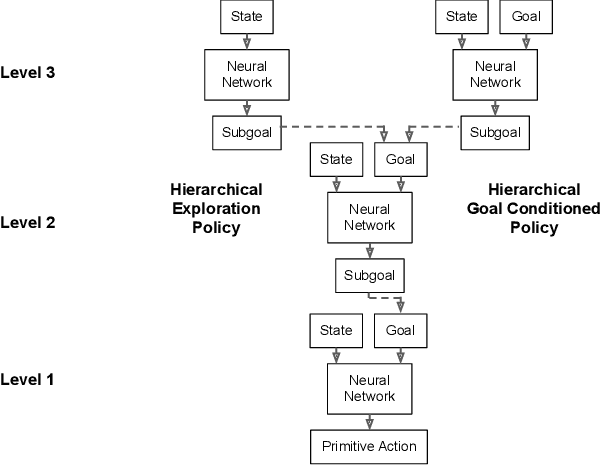
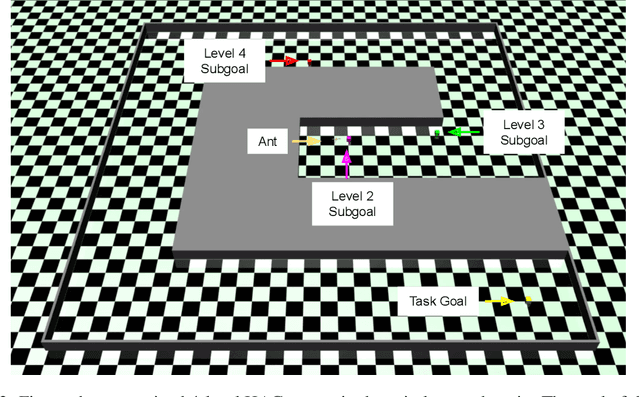
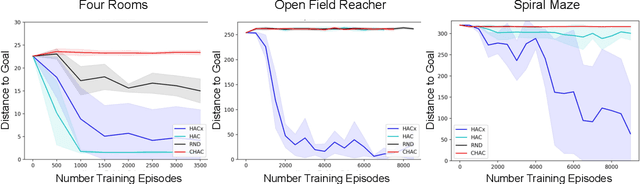
Sparse rewards and long time horizons remain challenging for reinforcement learning algorithms. Exploration bonuses can help in sparse reward settings by encouraging agents to explore the state space, while hierarchical approaches can assist with long-horizon tasks by decomposing lengthy tasks into shorter subtasks. We propose HAC Explore (HACx), a new method that combines these approaches by integrating the exploration bonus method Random Network Distillation (RND) into the hierarchical approach Hierarchical Actor-Critic (HAC). HACx outperforms either component method on its own, as well as an existing approach to combining hierarchy and exploration, in a set of difficult simulated robotics tasks. HACx is the first RL method to solve a sparse reward, continuous-control task that requires over 1,000 actions.
Value-Based Reinforcement Learning for Continuous Control Robotic Manipulation in Multi-Task Sparse Reward Settings
Jul 28, 2021
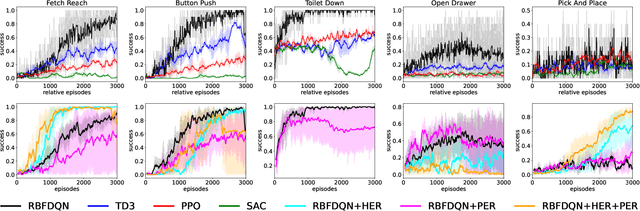
Learning continuous control in high-dimensional sparse reward settings, such as robotic manipulation, is a challenging problem due to the number of samples often required to obtain accurate optimal value and policy estimates. While many deep reinforcement learning methods have aimed at improving sample efficiency through replay or improved exploration techniques, state of the art actor-critic and policy gradient methods still suffer from the hard exploration problem in sparse reward settings. Motivated by recent successes of value-based methods for approximating state-action values, like RBF-DQN, we explore the potential of value-based reinforcement learning for learning continuous robotic manipulation tasks in multi-task sparse reward settings. On robotic manipulation tasks, we empirically show RBF-DQN converges faster than current state of the art algorithms such as TD3, SAC, and PPO. We also perform ablation studies with RBF-DQN and have shown that some enhancement techniques for vanilla Deep Q learning such as Hindsight Experience Replay (HER) and Prioritized Experience Replay (PER) can also be applied to RBF-DQN. Our experimental analysis suggests that value-based approaches may be more sensitive to data augmentation and replay buffer sample techniques than policy-gradient methods, and that the benefits of these methods for robot manipulation are heavily dependent on the transition dynamics of generated subgoal states.
Learning Markov State Abstractions for Deep Reinforcement Learning
Jun 08, 2021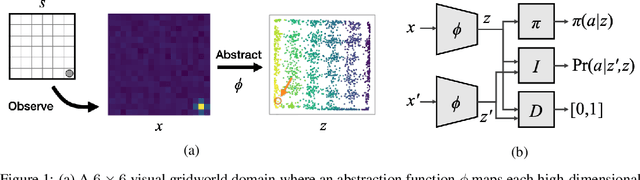

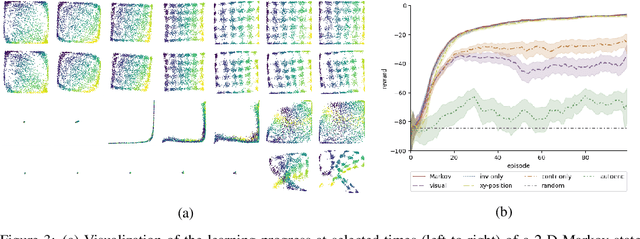
The fundamental assumption of reinforcement learning in Markov decision processes (MDPs) is that the relevant decision process is, in fact, Markov. However, when MDPs have rich observations, agents typically learn by way of an abstract state representation, and such representations are not guaranteed to preserve the Markov property. We introduce a novel set of conditions and prove that they are sufficient for learning a Markov abstract state representation. We then describe a practical training procedure that combines inverse model estimation and temporal contrastive learning to learn an abstraction that approximately satisfies these conditions. Our novel training objective is compatible with both online and offline training: it does not require a reward signal, but agents can capitalize on reward information when available. We empirically evaluate our approach on a visual gridworld domain and a set of continuous control benchmarks. Our approach learns representations that capture the underlying structure of the domain and lead to improved sample efficiency over state-of-the-art deep reinforcement learning with visual features -- often matching or exceeding the performance achieved with hand-designed compact state information.
Learning to Detect Multi-Modal Grasps for Dexterous Grasping in Dense Clutter
Jun 07, 2021



Grasping arbitrary objects in densely cluttered novel environments is a crucial skill for robots. Though many existing systems enable two-finger parallel-jaw grippers to pick items from clutter, these grippers cannot perform multiple types of grasps. However, multi-modal grasping with multi-finger grippers could much more effectively clear objects of varying sizes from cluttered scenes. We propose an approach to multi-model grasp detection that jointly predicts the probabilities that several types of grasps succeed at a given grasp pose. Given a partial point cloud of a scene, the algorithm proposes a set of feasible grasp candidates, then estimates the probabilities that a grasp of each type would succeed at each candidate pose. Predicting grasp success probabilities directly from point clouds makes our approach agnostic to the number and placement of depth sensors at execution time. We evaluate our system both in simulation and on a real robot with a Robotiq 3-Finger Adaptive Gripper. We compare our network against several baselines that perform fewer types of grasps. Our experiments show that a system that explicitly models grasp type achieves an object retrieval rate 8.5% higher in a complex cluttered environment than our highest-performing baseline.