 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDissecting adaptive methods in GANs
Oct 09, 2022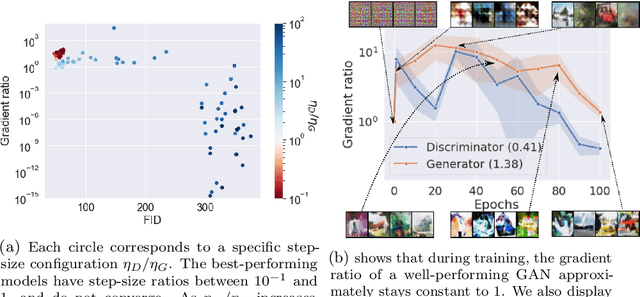
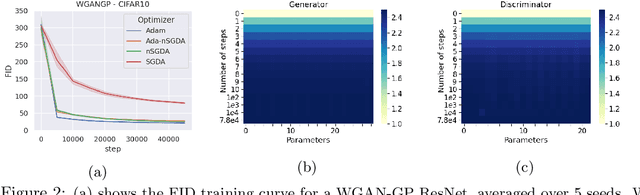
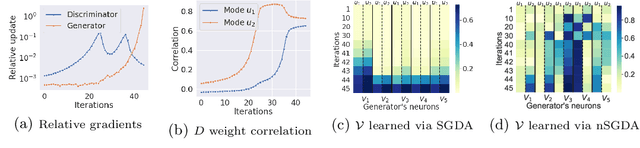
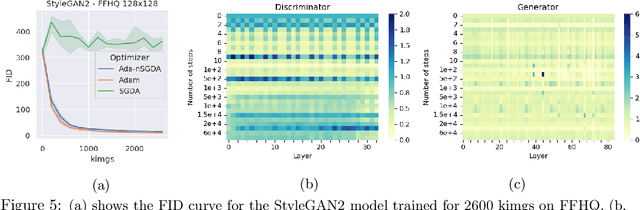
Adaptive methods are a crucial component widely used for training generative adversarial networks (GANs). While there has been some work to pinpoint the "marginal value of adaptive methods" in standard tasks, it remains unclear why they are still critical for GAN training. In this paper, we formally study how adaptive methods help train GANs; inspired by the grafting method proposed in arXiv:2002.11803 [cs.LG], we separate the magnitude and direction components of the Adam updates, and graft them to the direction and magnitude of SGDA updates respectively. By considering an update rule with the magnitude of the Adam update and the normalized direction of SGD, we empirically show that the adaptive magnitude of Adam is key for GAN training. This motivates us to have a closer look at the class of normalized stochastic gradient descent ascent (nSGDA) methods in the context of GAN training. We propose a synthetic theoretical framework to compare the performance of nSGDA and SGDA for GAN training with neural networks. We prove that in that setting, GANs trained with nSGDA recover all the modes of the true distribution, whereas the same networks trained with SGDA (and any learning rate configuration) suffer from mode collapse. The critical insight in our analysis is that normalizing the gradients forces the discriminator and generator to be updated at the same pace. We also experimentally show that for several datasets, Adam's performance can be recovered with nSGDA methods.
The Curse of Unrolling: Rate of Differentiating Through Optimization
Sep 27, 2022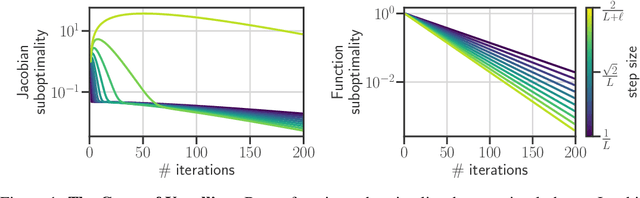
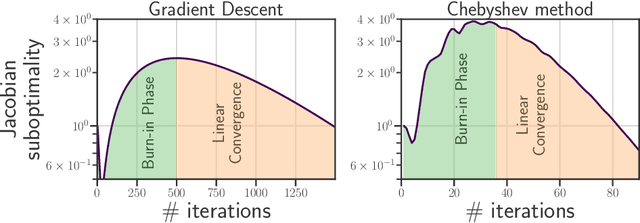
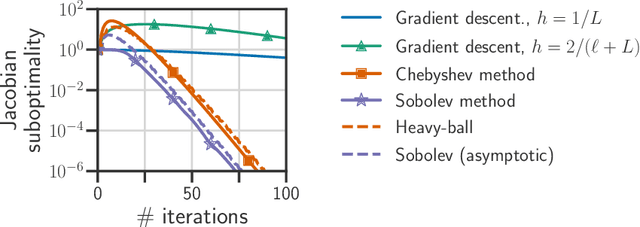
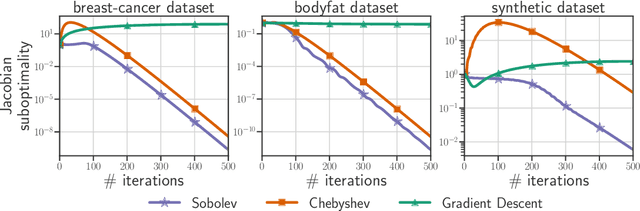
Computing the Jacobian of the solution of an optimization problem is a central problem in machine learning, with applications in hyperparameter optimization, meta-learning, optimization as a layer, and dataset distillation, to name a few. Unrolled differentiation is a popular heuristic that approximates the solution using an iterative solver and differentiates it through the computational path. This work provides a non-asymptotic convergence-rate analysis of this approach on quadratic objectives for gradient descent and the Chebyshev method. We show that to ensure convergence of the Jacobian, we can either 1) choose a large learning rate leading to a fast asymptotic convergence but accept that the algorithm may have an arbitrarily long burn-in phase or 2) choose a smaller learning rate leading to an immediate but slower convergence. We refer to this phenomenon as the curse of unrolling. Finally, we discuss open problems relative to this approach, such as deriving a practical update rule for the optimal unrolling strategy and making novel connections with the field of Sobolev orthogonal polynomials.
Proceedings of the ICML 2022 Expressive Vocalizations Workshop and Competition: Recognizing, Generating, and Personalizing Vocal Bursts
Jul 14, 2022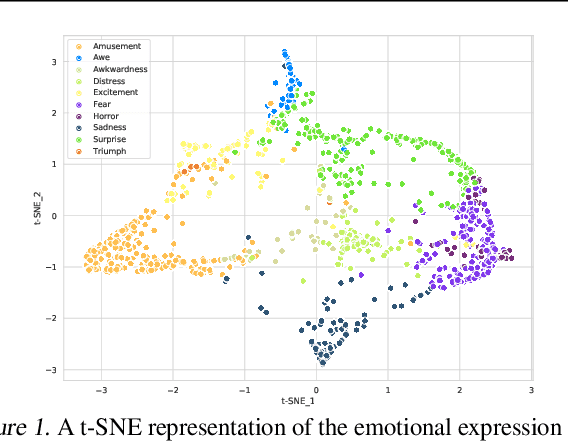
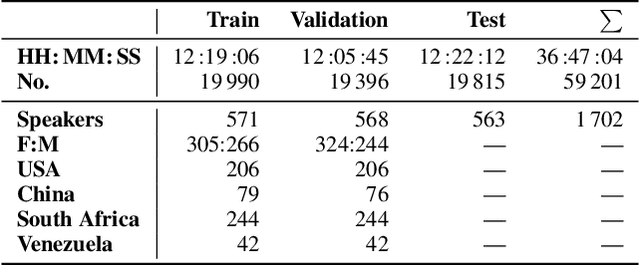
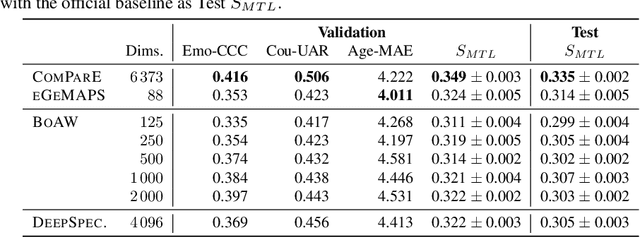
This is the Proceedings of the ICML Expressive Vocalization (ExVo) Competition. The ExVo competition focuses on understanding and generating vocal bursts: laughs, gasps, cries, and other non-verbal vocalizations that are central to emotional expression and communication. ExVo 2022, included three competition tracks using a large-scale dataset of 59,201 vocalizations from 1,702 speakers. The first, ExVo-MultiTask, requires participants to train a multi-task model to recognize expressed emotions and demographic traits from vocal bursts. The second, ExVo-Generate, requires participants to train a generative model that produces vocal bursts conveying ten different emotions. The third, ExVo-FewShot, requires participants to leverage few-shot learning incorporating speaker identity to train a model for the recognition of 10 emotions conveyed by vocal bursts.
Generating Diverse Vocal Bursts with StyleGAN2 and MEL-Spectrograms
Jun 25, 2022
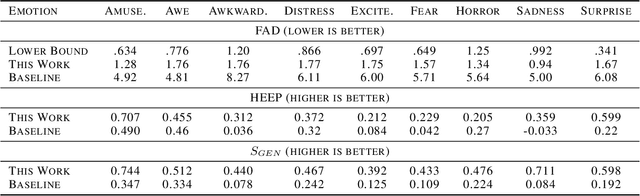

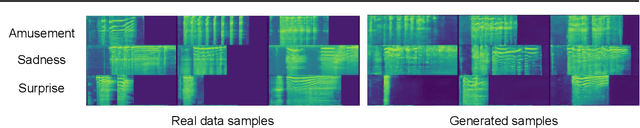
We describe our approach for the generative emotional vocal burst task (ExVo Generate) of the ICML Expressive Vocalizations Competition. We train a conditional StyleGAN2 architecture on mel-spectrograms of preprocessed versions of the audio samples. The mel-spectrograms generated by the model are then inverted back to the audio domain. As a result, our generated samples substantially improve upon the baseline provided by the competition from a qualitative and quantitative perspective for all emotions. More precisely, even for our worst-performing emotion (awe), we obtain an FAD of 1.76 compared to the baseline of 4.81 (as a reference, the FAD between the train/validation sets for awe is 0.776).
Only Tails Matter: Average-Case Universality and Robustness in the Convex Regime
Jun 22, 2022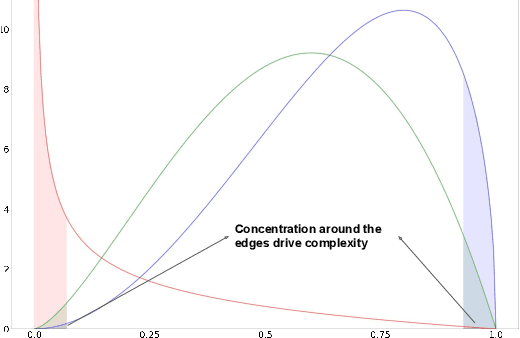

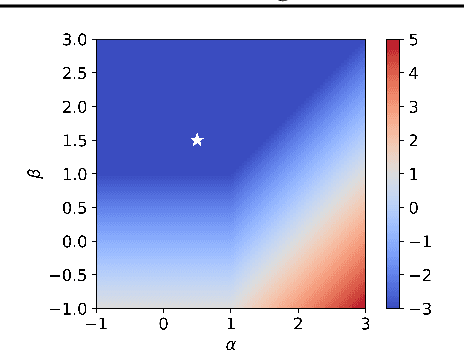

The recently developed average-case analysis of optimization methods allows a more fine-grained and representative convergence analysis than usual worst-case results. In exchange, this analysis requires a more precise hypothesis over the data generating process, namely assuming knowledge of the expected spectral distribution (ESD) of the random matrix associated with the problem. This work shows that the concentration of eigenvalues near the edges of the ESD determines a problem's asymptotic average complexity. This a priori information on this concentration is a more grounded assumption than complete knowledge of the ESD. This approximate concentration is effectively a middle ground between the coarseness of the worst-case scenario convergence and the restrictive previous average-case analysis. We also introduce the Generalized Chebyshev method, asymptotically optimal under a hypothesis on this concentration and globally optimal when the ESD follows a Beta distribution. We compare its performance to classical optimization algorithms, such as gradient descent or Nesterov's scheme, and we show that, in the average-case context, Nesterov's method is universally nearly optimal asymptotically.
On the Limitations of Elo: Real-World Games, are Transitive, not Additive
Jun 21, 2022
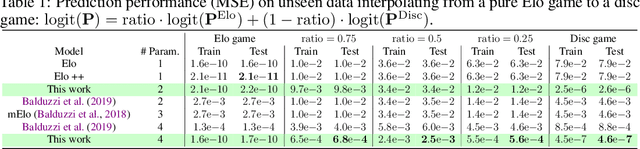
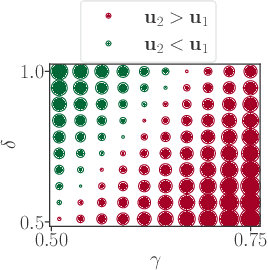
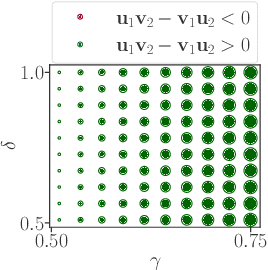
Real-world competitive games, such as chess, go, or StarCraft II, rely on Elo models to measure the strength of their players. Since these games are not fully transitive, using Elo implicitly assumes they have a strong transitive component that can correctly be identified and extracted. In this study, we investigate the challenge of identifying the strength of the transitive component in games. First, we show that Elo models can fail to extract this transitive component, even in elementary transitive games. Then, based on this observation, we propose an extension of the Elo score: we end up with a disc ranking system that assigns each player two scores, which we refer to as skill and consistency. Finally, we propose an empirical validation on payoff matrices coming from real-world games played by bots and humans.
Optimal Extragradient-Based Bilinearly-Coupled Saddle-Point Optimization
Jun 17, 2022
We consider the smooth convex-concave bilinearly-coupled saddle-point problem, $\min_{\mathbf{x}}\max_{\mathbf{y}}~F(\mathbf{x}) + H(\mathbf{x},\mathbf{y}) - G(\mathbf{y})$, where one has access to stochastic first-order oracles for $F$, $G$ as well as the bilinear coupling function $H$. Building upon standard stochastic extragradient analysis for variational inequalities, we present a stochastic \emph{accelerated gradient-extragradient (AG-EG)} descent-ascent algorithm that combines extragradient and Nesterov's acceleration in general stochastic settings. This algorithm leverages scheduled restarting to admit a fine-grained nonasymptotic convergence rate that matches known lower bounds by both \citet{ibrahim2020linear} and \citet{zhang2021lower} in their corresponding settings, plus an additional statistical error term for bounded stochastic noise that is optimal up to a constant prefactor. This is the first result that achieves such a relatively mature characterization of optimality in saddle-point optimization.
A General Framework For Proving The Equivariant Strong Lottery Ticket Hypothesis
Jun 09, 2022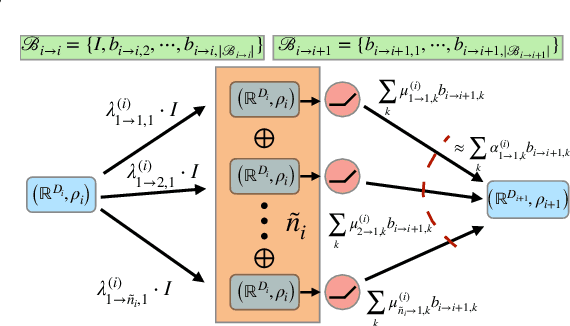


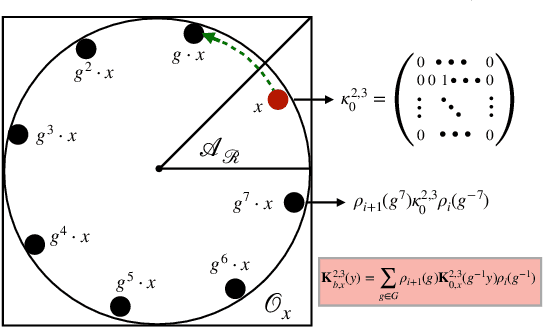
The Strong Lottery Ticket Hypothesis (SLTH) stipulates the existence of a subnetwork within a sufficiently overparameterized (dense) neural network that -- when initialized randomly and without any training -- achieves the accuracy of a fully trained target network. Recent work by \citet{da2022proving} demonstrates that the SLTH can also be extended to translation equivariant networks -- i.e. CNNs -- with the same level of overparametrization as needed for SLTs in dense networks. However, modern neural networks are capable of incorporating more than just translation symmetry, and developing general equivariant architectures such as rotation and permutation has been a powerful design principle. In this paper, we generalize the SLTH to functions that preserve the action of the group $G$ -- i.e. $G$-equivariant network -- and prove, with high probability, that one can prune a randomly initialized overparametrized $G$-equivariant network to a $G$-equivariant subnetwork that approximates another fully trained $G$-equivariant network of fixed width and depth. We further prove that our prescribed overparametrization scheme is also optimal as a function of the error tolerance. We develop our theory for a large range of groups, including important ones such as subgroups of the Euclidean group $\text{E}(n)$ and subgroups of the symmetric group $G \leq \mathcal{S}_n$ -- allowing us to find SLTs for MLPs, CNNs, $\text{E}(2)$-steerable CNNs, and permutation equivariant networks as specific instantiations of our unified framework which completely extends prior work. Empirically, we verify our theory by pruning overparametrized $\text{E}(2)$-steerable CNNs and message passing GNNs to match the performance of trained target networks within a given error tolerance.
Clipped Stochastic Methods for Variational Inequalities with Heavy-Tailed Noise
Jun 02, 2022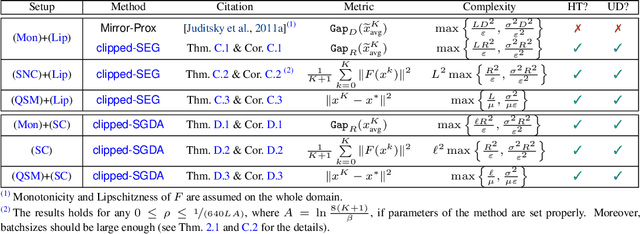
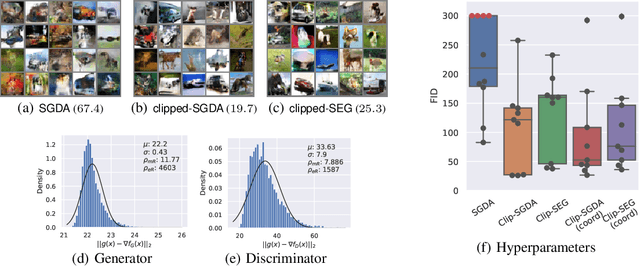
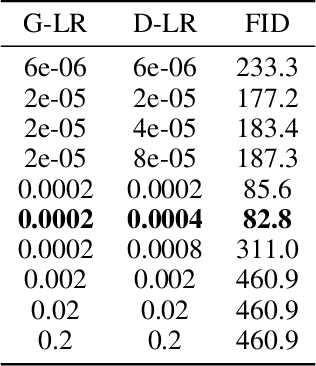
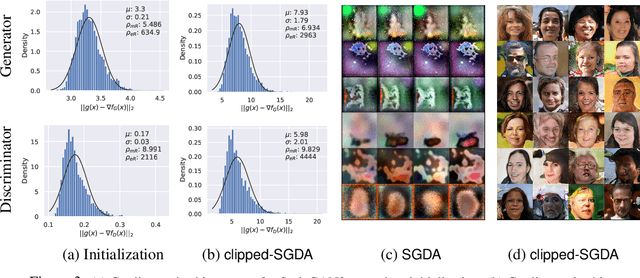
Stochastic first-order methods such as Stochastic Extragradient (SEG) or Stochastic Gradient Descent-Ascent (SGDA) for solving smooth minimax problems and, more generally, variational inequality problems (VIP) have been gaining a lot of attention in recent years due to the growing popularity of adversarial formulations in machine learning. However, while high-probability convergence bounds are known to reflect the actual behavior of stochastic methods more accurately, most convergence results are provided in expectation. Moreover, the only known high-probability complexity results have been derived under restrictive sub-Gaussian (light-tailed) noise and bounded domain Assump. [Juditsky et al., 2011]. In this work, we prove the first high-probability complexity results with logarithmic dependence on the confidence level for stochastic methods for solving monotone and structured non-monotone VIPs with non-sub-Gaussian (heavy-tailed) noise and unbounded domains. In the monotone case, our results match the best-known ones in the light-tails case [Juditsky et al., 2011], and are novel for structured non-monotone problems such as negative comonotone, quasi-strongly monotone, and/or star-cocoercive ones. We achieve these results by studying SEG and SGDA with clipping. In addition, we numerically validate that the gradient noise of many practical GAN formulations is heavy-tailed and show that clipping improves the performance of SEG/SGDA.
Variance Reduction is an Antidote to Byzantines: Better Rates, Weaker Assumptions and Communication Compression as a Cherry on the Top
Jun 01, 2022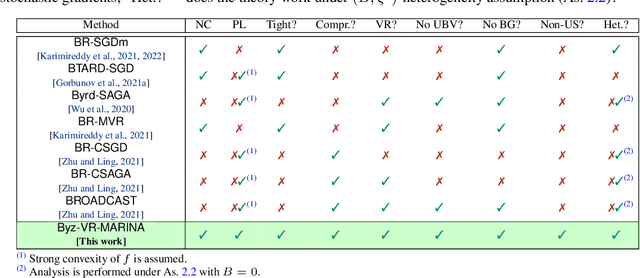
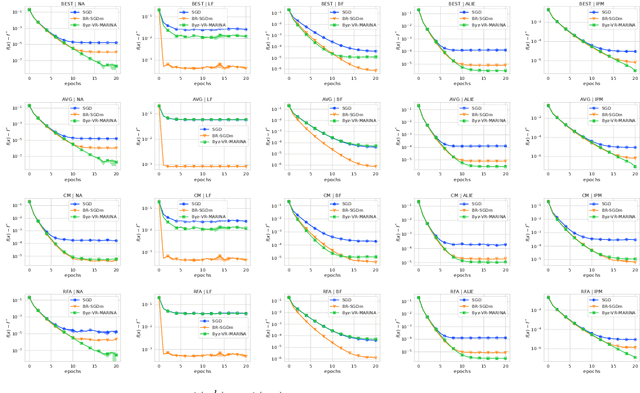
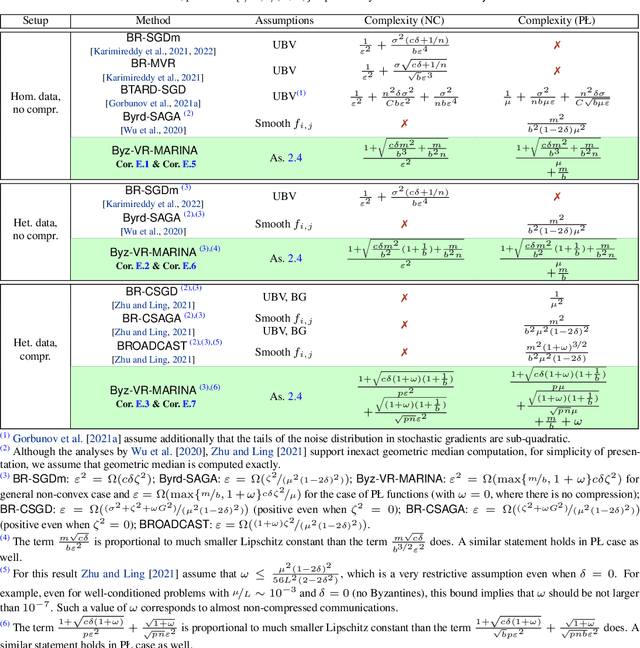
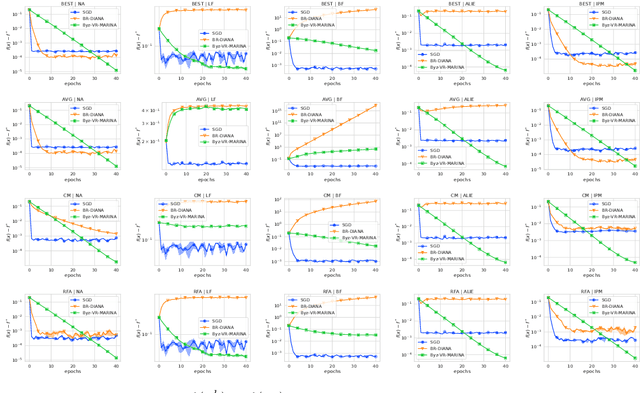
Byzantine-robustness has been gaining a lot of attention due to the growth of the interest in collaborative and federated learning. However, many fruitful directions, such as the usage of variance reduction for achieving robustness and communication compression for reducing communication costs, remain weakly explored in the field. This work addresses this gap and proposes Byz-VR-MARINA - a new Byzantine-tolerant method with variance reduction and compression. A key message of our paper is that variance reduction is key to fighting Byzantine workers more effectively. At the same time, communication compression is a bonus that makes the process more communication efficient. We derive theoretical convergence guarantees for Byz-VR-MARINA outperforming previous state-of-the-art for general non-convex and Polyak-Lojasiewicz loss functions. Unlike the concurrent Byzantine-robust methods with variance reduction and/or compression, our complexity results are tight and do not rely on restrictive assumptions such as boundedness of the gradients or limited compression. Moreover, we provide the first analysis of a Byzantine-tolerant method supporting non-uniform sampling of stochastic gradients. Numerical experiments corroborate our theoretical findings.