 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Sampling: Algorithmic vs. Human Waypoint Selection
Apr 24, 2021
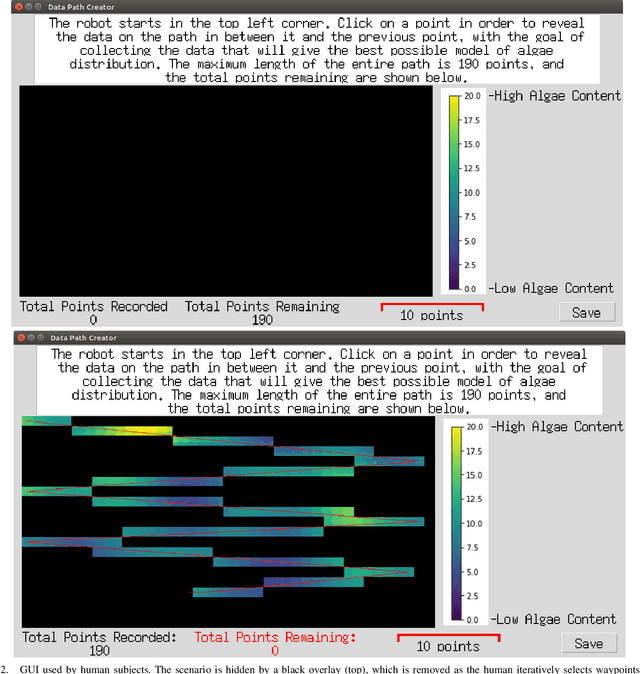
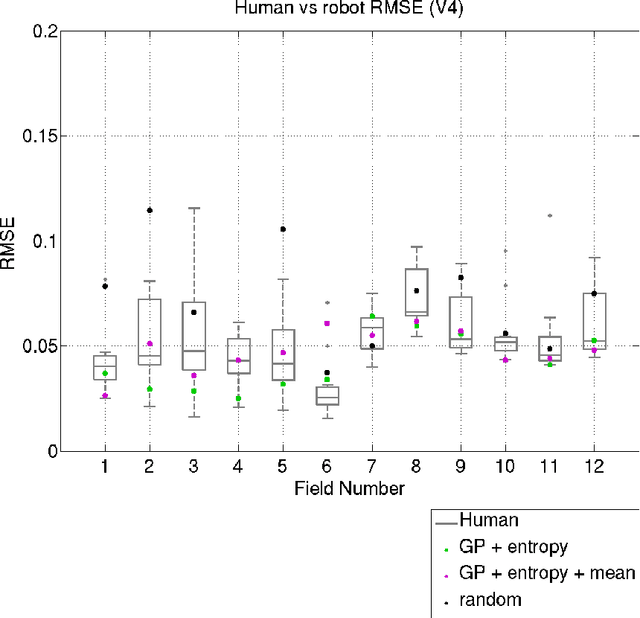
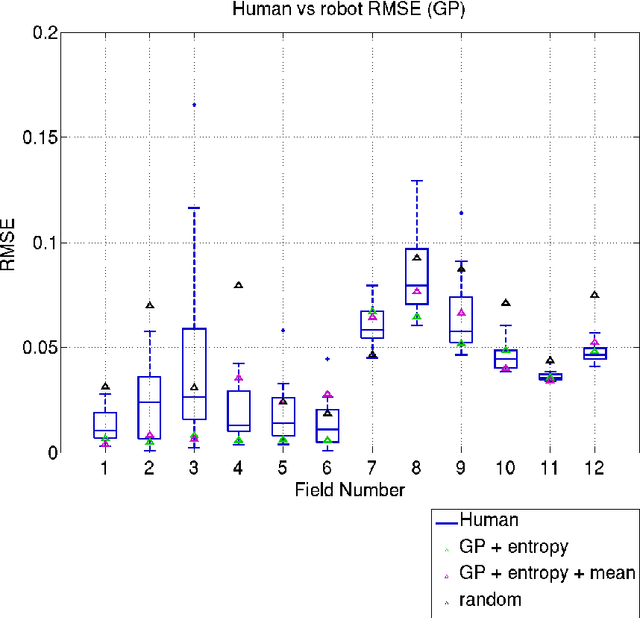
Robots are used for collecting samples from natural environments to create models of, for example, temperature or algae fields in the ocean. Adaptive informative sampling is a proven technique for this kind of spatial field modeling. This paper compares the performance of humans versus adaptive informative sampling algorithms for selecting informative waypoints. The humans and simulated robot are given the same information for selecting waypoints, and both are evaluated on the accuracy of the resulting model. We developed a graphical user interface for selecting waypoints and visualizing samples. Eleven participants iteratively picked waypoints for twelve scenarios. Our simulated robot used Gaussian Process regression with two entropy-based optimization criteria to iteratively choose waypoints. Our results show that the robot can on average perform better than the average human, and approximately as good as the best human, when the model assumptions correspond to the actual field. However, when the model assumptions do not correspond as well to the characteristics of the field, both human and robot performance are no better than random sampling.
NeuralSim: Augmenting Differentiable Simulators with Neural Networks
Nov 09, 2020
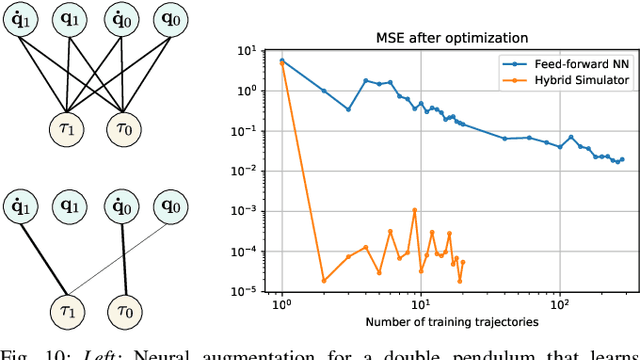
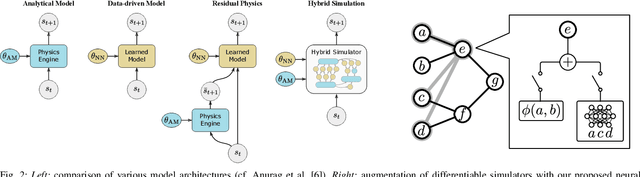
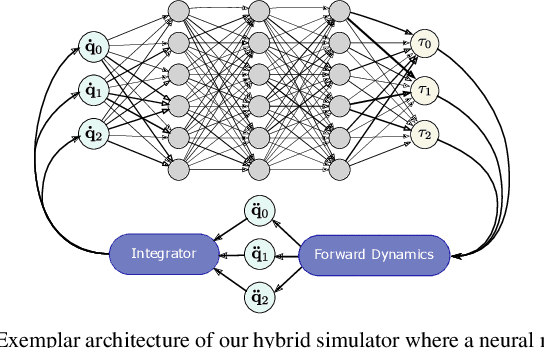
Differentiable simulators provide an avenue for closing the sim-to-real gap by enabling the use of efficient, gradient-based optimization algorithms to find the simulation parameters that best fit the observed sensor readings. Nonetheless, these analytical models can only predict the dynamical behavior of systems for which they have been designed. In this work, we study the augmentation of a novel differentiable rigid-body physics engine via neural networks that is able to learn nonlinear relationships between dynamic quantities and can thus learn effects not accounted for in traditional simulators.Such augmentations require less data to train and generalize better compared to entirely data-driven models. Through extensive experiments, we demonstrate the ability of our hybrid simulator to learn complex dynamics involving frictional contacts from real data, as well as match known models of viscous friction, and present an approach for automatically discovering useful augmentations. We show that, besides benefiting dynamics modeling, inserting neural networks can accelerate model-based control architectures. We observe a ten-fold speed-up when replacing the QP solver inside a model-predictive gait controller for quadruped robots with a neural network, allowing us to significantly improve control delays as we demonstrate in real-hardware experiments. We publish code, additional results and videos from our experiments on our project webpage at https://sites.google.com/usc.edu/neuralsim.
Motion Planner Augmented Reinforcement Learning for Robot Manipulation in Obstructed Environments
Oct 22, 2020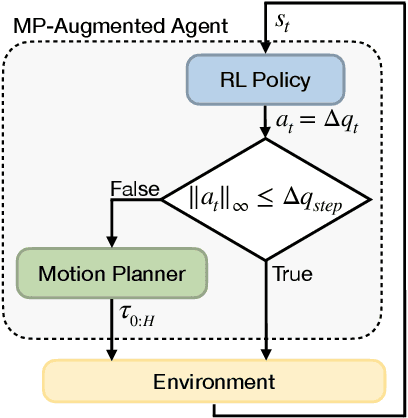

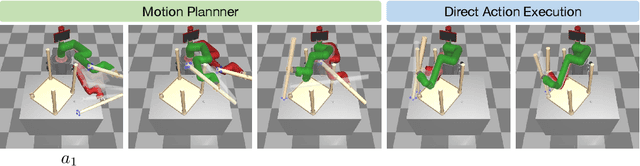

Deep reinforcement learning (RL) agents are able to learn contact-rich manipulation tasks by maximizing a reward signal, but require large amounts of experience, especially in environments with many obstacles that complicate exploration. In contrast, motion planners use explicit models of the agent and environment to plan collision-free paths to faraway goals, but suffer from inaccurate models in tasks that require contacts with the environment. To combine the benefits of both approaches, we propose motion planner augmented RL (MoPA-RL) which augments the action space of an RL agent with the long-horizon planning capabilities of motion planners. Based on the magnitude of the action, our approach smoothly transitions between directly executing the action and invoking a motion planner. We evaluate our approach on various simulated manipulation tasks and compare it to alternative action spaces in terms of learning efficiency and safety. The experiments demonstrate that MoPA-RL increases learning efficiency, leads to a faster exploration, and results in safer policies that avoid collisions with the environment. Videos and code are available at https://clvrai.com/mopa-rl .
Learning Equality Constraints for Motion Planning on Manifolds
Sep 24, 2020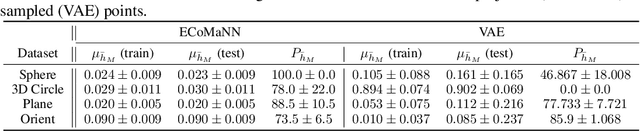
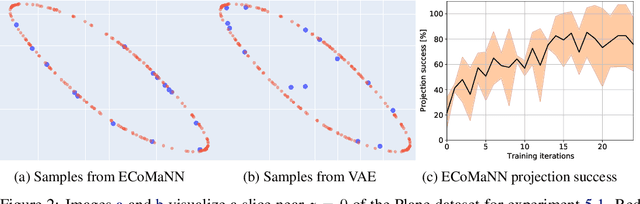

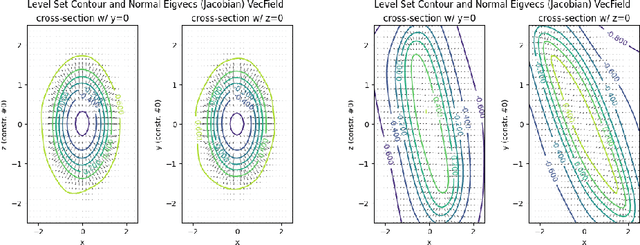
Constrained robot motion planning is a widely used technique to solve complex robot tasks. We consider the problem of learning representations of constraints from demonstrations with a deep neural network, which we call Equality Constraint Manifold Neural Network (ECoMaNN). The key idea is to learn a level-set function of the constraint suitable for integration into a constrained sampling-based motion planner. Learning proceeds by aligning subspaces in the network with subspaces of the data. We combine both learned constraints and analytically described constraints into the planner and use a projection-based strategy to find valid points. We evaluate ECoMaNN on its representation capabilities of constraint manifolds, the impact of its individual loss terms, and the motions produced when incorporated into a planner.
Resilient Monitoring in Heterogeneous Multi-robot Systems through Network Reconfiguration
Aug 04, 2020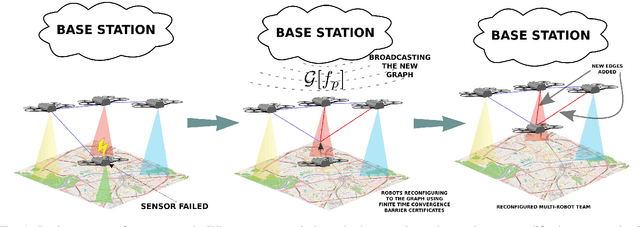

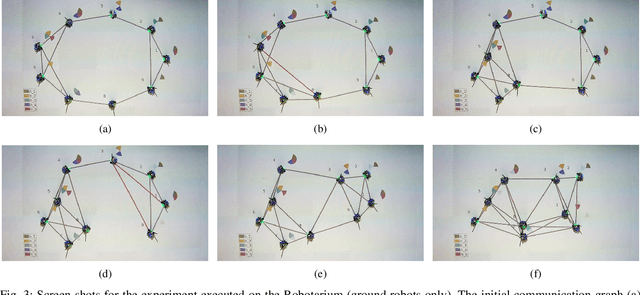
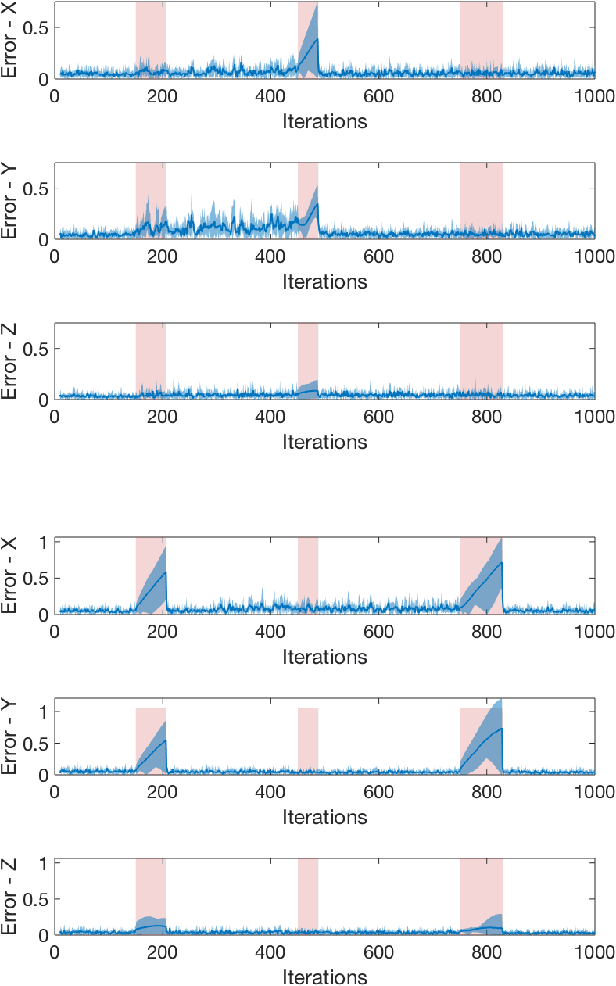
We propose a framework for resilience in a networked heterogeneous multi-robot team subject to resource failures. Each robot in the team is equipped with resources that it shares with its neighbors. Additionally, each robot in the team executes a task, whose performance depends on the resources to which it has access. When a resource on a particular robot becomes unavailable (\eg a camera ceases to function), the team optimally reconfigures its communication network so that the robots affected by the failure can continue their tasks. We focus on a monitoring task, where robots individually estimate the state of an exogenous process. We encode the end-to-end effect of a robot's resource loss on the monitoring performance of the team by defining a new stronger notion of observability -- \textit{one-hop observability}. By abstracting the impact that {low-level} individual resources have on the task performance through the notion of one-hop observability, our framework leads to the principled reconfiguration of information flow in the team to effectively replace the lost resource on one robot with information from another, as long as certain conditions are met. Network reconfiguration is converted to the problem of selecting edges to be modified in the system's communication graph after a resource failure has occurred. A controller based on finite-time convergence control barrier functions drives each robot to a spatial location that enables the communication links of the modified graph. We validate the effectiveness of our framework by deploying it on a team of differential-drive robots estimating the position of a group of quadrotors.
Augmenting Differentiable Simulators with Neural Networks to Close the Sim2Real Gap
Jul 12, 2020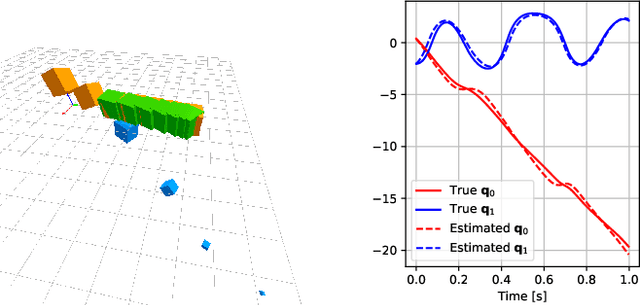
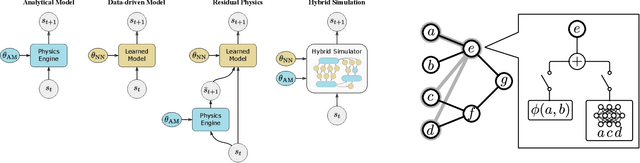

We present a differentiable simulation architecture for articulated rigid-body dynamics that enables the augmentation of analytical models with neural networks at any point of the computation. Through gradient-based optimization, identification of the simulation parameters and network weights is performed efficiently in preliminary experiments on a real-world dataset and in sim2sim transfer applications, while poor local optima are overcome through a random search approach.
Learning Manifolds for Sequential Motion Planning
Jul 04, 2020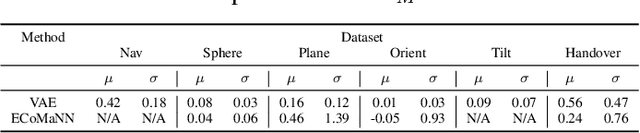

Motion planning with constraints is an important part of many real-world robotic systems. In this work, we study manifold learning methods to learn such constraints from data. We explore two methods for learning implicit constraint manifolds from data: Variational Autoencoders (VAE), and a new method, Equality Constraint Manifold Neural Network (ECoMaNN). With the aim of incorporating learned constraints into a sampling-based motion planning framework, we evaluate the approaches on their ability to learn representations of constraints from various datasets and on the quality of paths produced during planning.
Supervised Learning and Reinforcement Learning of Feedback Models for Reactive Behaviors: Tactile Feedback Testbed
Jun 29, 2020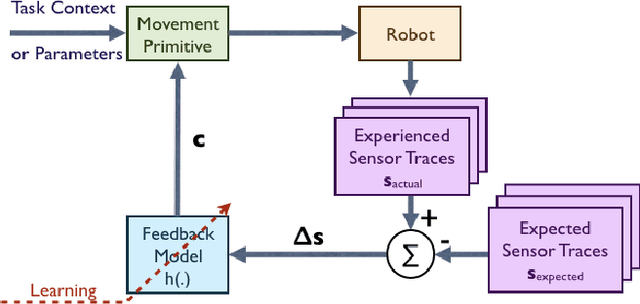

Robots need to be able to adapt to unexpected changes in the environment such that they can autonomously succeed in their tasks. However, hand-designing feedback models for adaptation is tedious, if at all possible, making data-driven methods a promising alternative. In this paper we introduce a full framework for learning feedback models for reactive motion planning. Our pipeline starts by segmenting demonstrations of a complete task into motion primitives via a semi-automated segmentation algorithm. Then, given additional demonstrations of successful adaptation behaviors, we learn initial feedback models through learning from demonstrations. In the final phase, a sample-efficient reinforcement learning algorithm fine-tunes these feedback models for novel task settings through few real system interactions. We evaluate our approach on a real anthropomorphic robot in learning a tactile feedback task.
Confidence-rich grid mapping
Jun 29, 2020

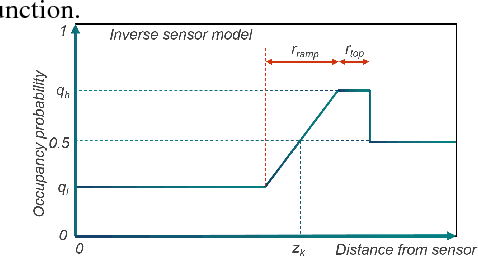
Representing the environment is a fundamental task in enabling robots to act autonomously in unknown environments. In this work, we present confidence-rich mapping (CRM), a new algorithm for spatial grid-based mapping of the 3D environment. CRM augments the occupancy level at each voxel by its confidence value. By explicitly storing and evolving confidence values using the CRM filter, CRM extends traditional grid mapping in three ways: first, it partially maintains the probabilistic dependence among voxels. Second, it relaxes the need for hand-engineering an inverse sensor model and proposes the concept of sensor cause model that can be derived in a principled manner from the forward sensor model. Third, and most importantly, it provides consistent confidence values over the occupancy estimation that can be reliably used in collision risk evaluation and motion planning. CRM runs online and enables mapping environments where voxels might be partially occupied. We demonstrate the performance of the method on various datasets and environments in simulation and on physical systems. We show in real-world experiments that, in addition to achieving maps that are more accurate than traditional methods, the proposed filtering scheme demonstrates a much higher level of consistency between its error and the reported confidence, hence, enabling a more reliable collision risk evaluation for motion planning.
* Published at International Journal of Robotics Research (IJRR) 2019 (https://journals.sagepub.com/doi/10.1177/0278364919839762)
Sampling-Based Motion Planning on Manifold Sequences
Jun 03, 2020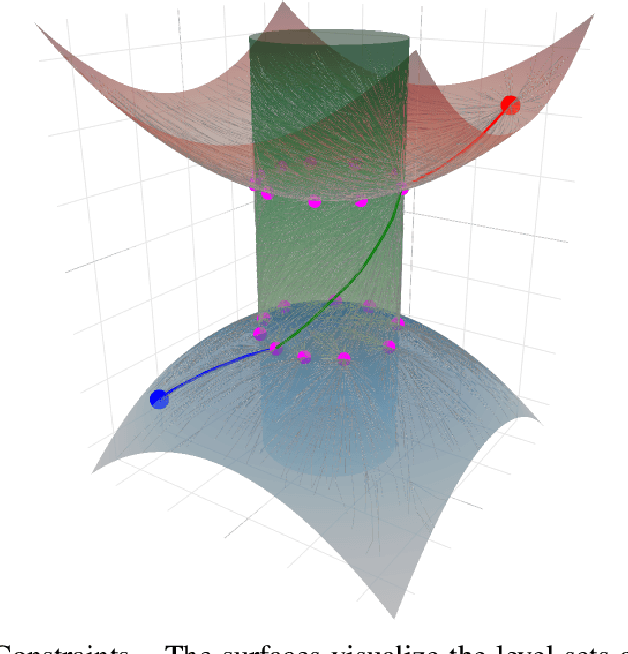
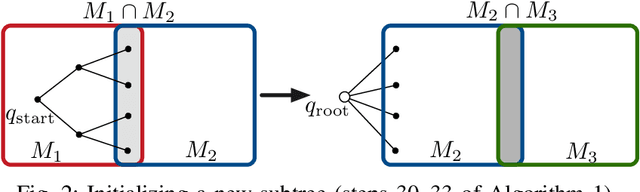
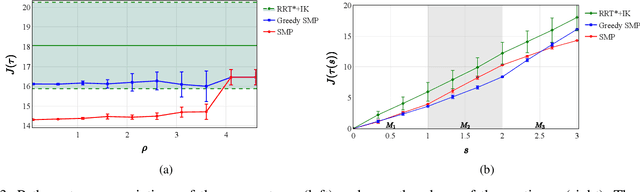
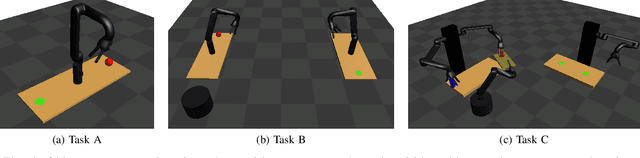
We address the problem of planning robot motions in constrained configuration spaces where the constraints change throughout the motion. A novel problem formulation is introduced that describes a task as a sequence of intersecting manifolds, which the robot needs to traverse in order to solve the task. We specify a class of sequential motion planning problems that fulfill a particular property of the change in the free configuration space when transitioning between manifolds. For this problem class, a sequential motion planning algorithm SMP is developed that searches for optimal intersection points between manifolds by using RRT* in an inner loop with a novel steering strategy. We provide a theoretical analysis regarding its probabilistic completeness and demonstrate its performance on kinematic planning problems where the constraints are represented as geometric primitives. Further, we show its capabilities on solving multi-robot object transportation tasks.