 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomating Augmentation Through Random Unidimensional Search
Jun 16, 2021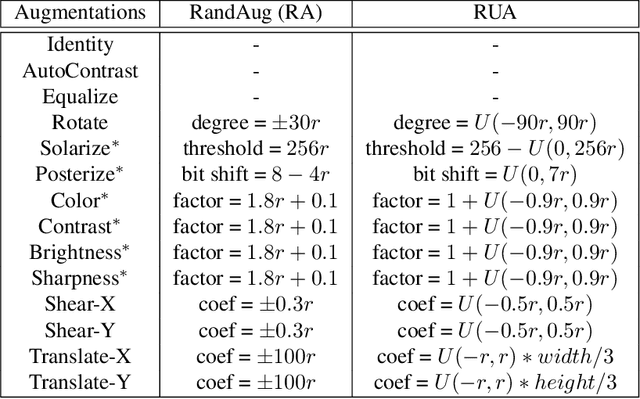
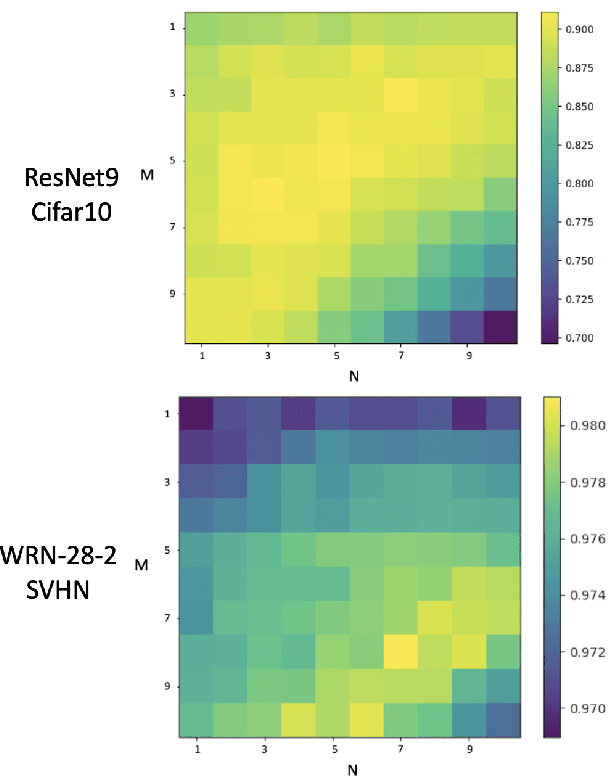
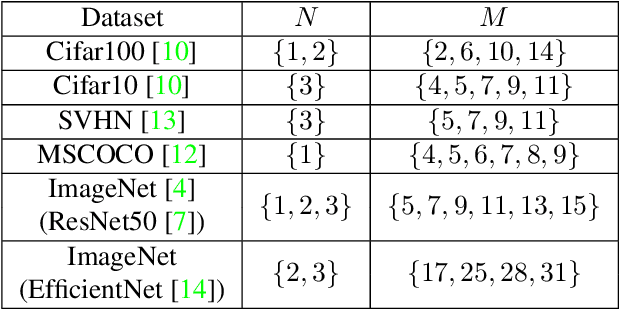
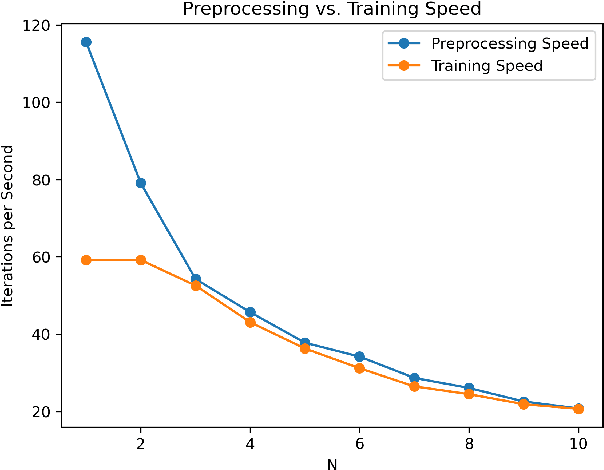
It is no secret amongst deep learning researchers that finding the right data augmentation strategy during training can mean the difference between a state-of-the-art result and a run-of-the-mill ranking. To that end, the community has seen many efforts to automate the process of finding the perfect augmentation procedure for any task at hand. Unfortunately, even recent cutting-edge methods bring massive computational overhead, requiring as many as 100 full model trainings to settle on an ideal configuration. We show how to achieve even better performance in just 7: with Random Unidimensional Augmentation. Source code is available at https://github.com/fastestimator/RUA
Learning Feature Weights using Reward Modeling for Denoising Parallel Corpora
Mar 11, 2021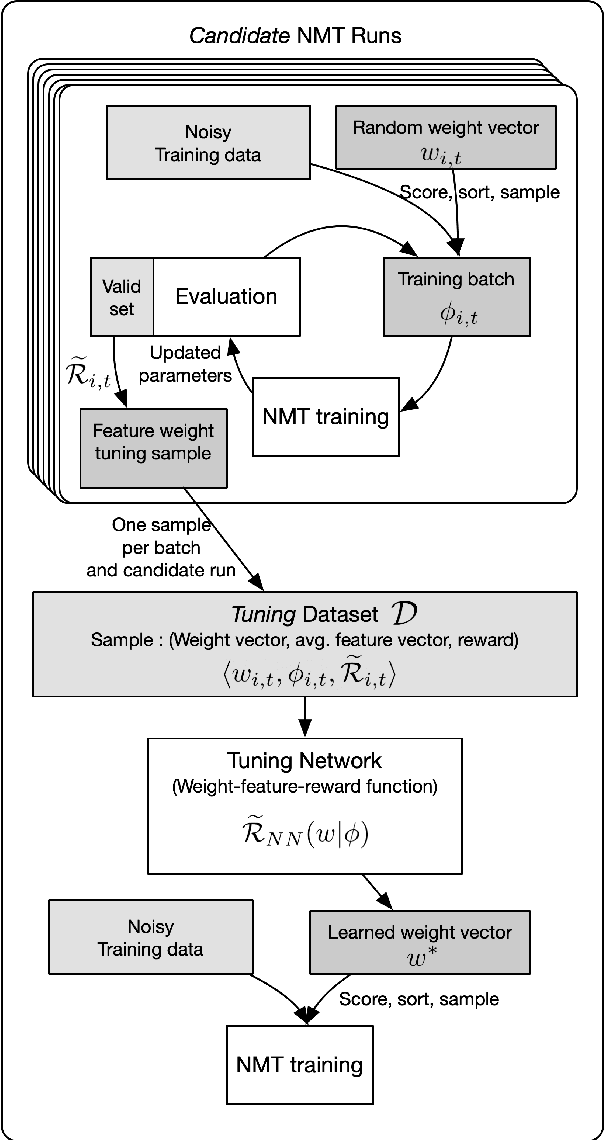
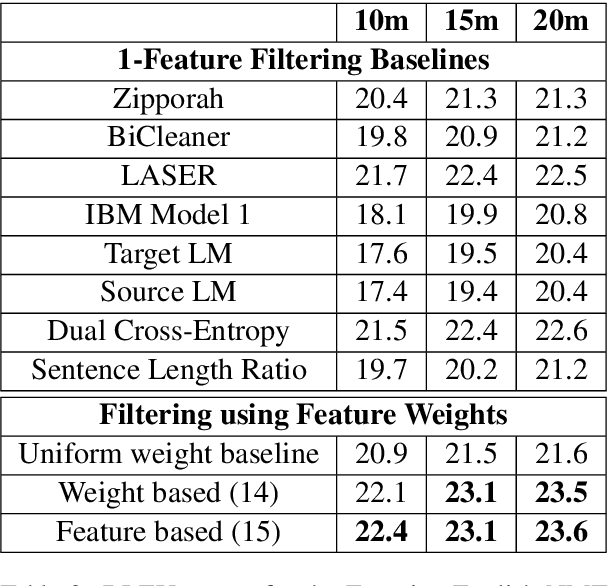
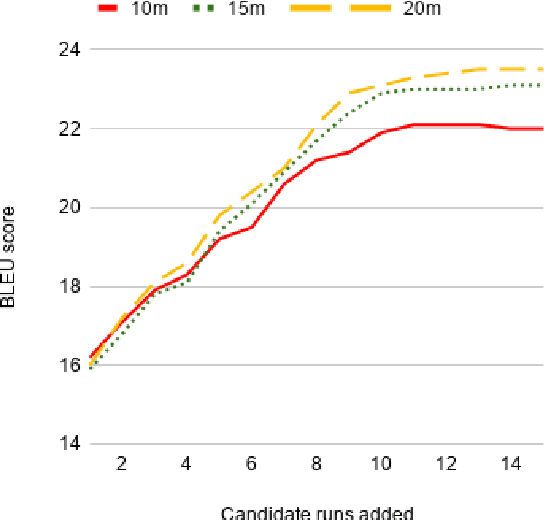
Large web-crawled corpora represent an excellent resource for improving the performance of Neural Machine Translation (NMT) systems across several language pairs. However, since these corpora are typically extremely noisy, their use is fairly limited. Current approaches to dealing with this problem mainly focus on filtering using heuristics or single features such as language model scores or bi-lingual similarity. This work presents an alternative approach which learns weights for multiple sentence-level features. These feature weights which are optimized directly for the task of improving translation performance, are used to score and filter sentences in the noisy corpora more effectively. We provide results of applying this technique to building NMT systems using the Paracrawl corpus for Estonian-English and show that it beats strong single feature baselines and hand designed combinations. Additionally, we analyze the sensitivity of this method to different types of noise and explore if the learned weights generalize to other language pairs using the Maltese-English Paracrawl corpus.
Learning Policies for Multilingual Training of Neural Machine Translation Systems
Mar 11, 2021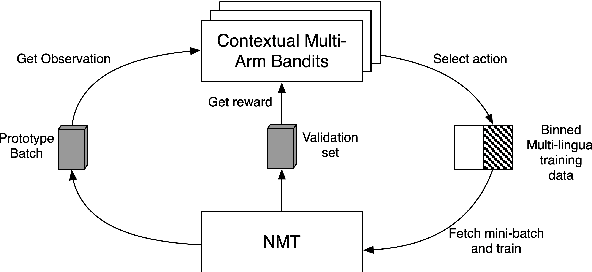
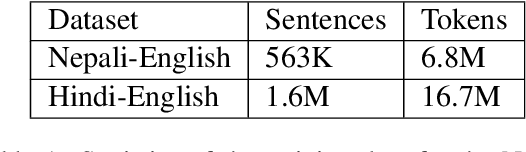
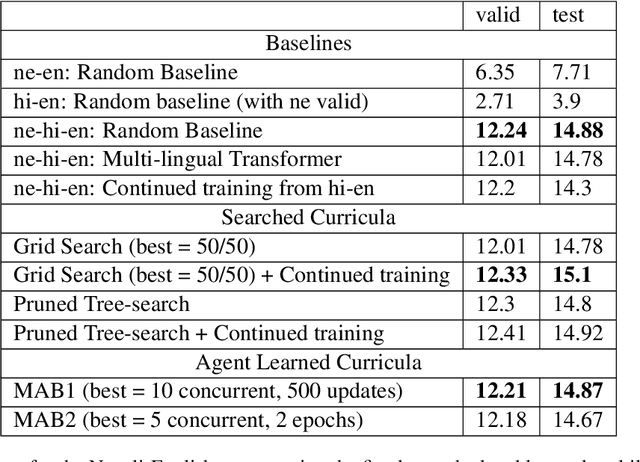
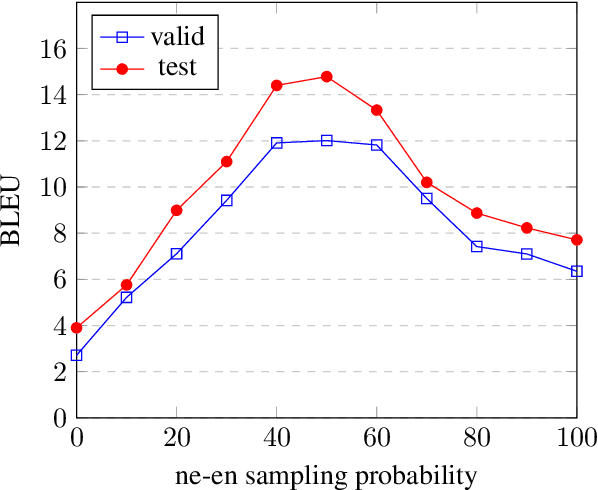
Low-resource Multilingual Neural Machine Translation (MNMT) is typically tasked with improving the translation performance on one or more language pairs with the aid of high-resource language pairs. In this paper, we propose two simple search based curricula -- orderings of the multilingual training data -- which help improve translation performance in conjunction with existing techniques such as fine-tuning. Additionally, we attempt to learn a curriculum for MNMT from scratch jointly with the training of the translation system with the aid of contextual multi-arm bandits. We show on the FLORES low-resource translation dataset that these learned curricula can provide better starting points for fine tuning and improve overall performance of the translation system.
Solving Physics Puzzles by Reasoning about Paths
Nov 14, 2020

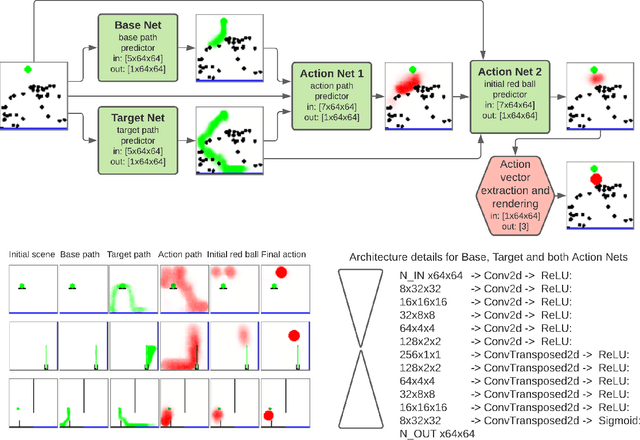
We propose a new deep learning model for goal-driven tasks that require intuitive physical reasoning and intervention in the scene to achieve a desired end goal. Its modular structure is motivated by hypothesizing a sequence of intuitive steps that humans apply when trying to solve such a task. The model first predicts the path the target object would follow without intervention and the path the target object should follow in order to solve the task. Next, it predicts the desired path of the action object and generates the placement of the action object. All components of the model are trained jointly in a supervised way; each component receives its own learning signal but learning signals are also backpropagated through the entire architecture. To evaluate the model we use PHYRE - a benchmark test for goal-driven physical reasoning in 2D mechanics puzzles.
AMUSED: A Multi-Stream Vector Representation Method for Use in Natural Dialogue
Dec 04, 2019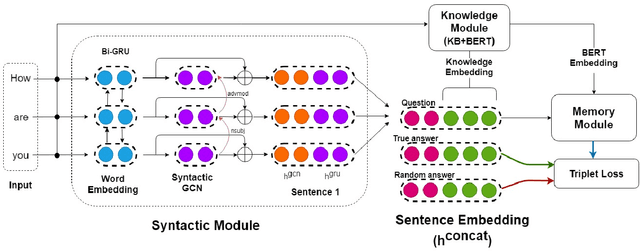

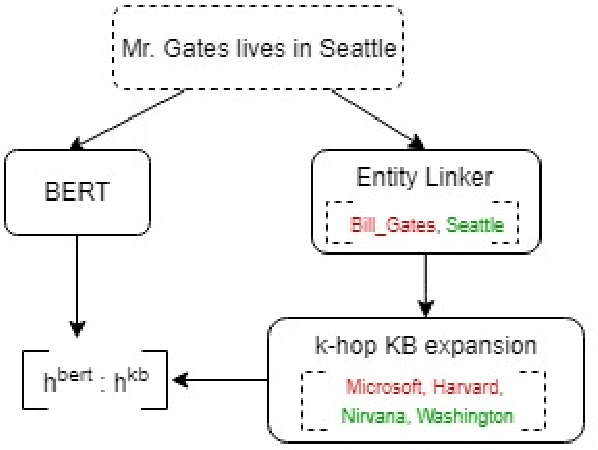
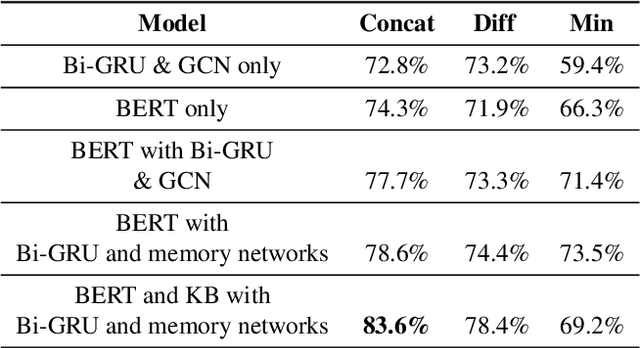
The problem of building a coherent and non-monotonous conversational agent with proper discourse and coverage is still an area of open research. Current architectures only take care of semantic and contextual information for a given query and fail to completely account for syntactic and external knowledge which are crucial for generating responses in a chit-chat system. To overcome this problem, we propose an end to end multi-stream deep learning architecture which learns unified embeddings for query-response pairs by leveraging contextual information from memory networks and syntactic information by incorporating Graph Convolution Networks (GCN) over their dependency parse. A stream of this network also utilizes transfer learning by pre-training a bidirectional transformer to extract semantic representation for each input sentence and incorporates external knowledge through the the neighborhood of the entities from a Knowledge Base (KB). We benchmark these embeddings on next sentence prediction task and significantly improve upon the existing techniques. Furthermore, we use AMUSED to represent query and responses along with its context to develop a retrieval based conversational agent which has been validated by expert linguists to have comprehensive engagement with humans.
FastEstimator: A Deep Learning Library for Fast Prototyping and Productization
Nov 18, 2019
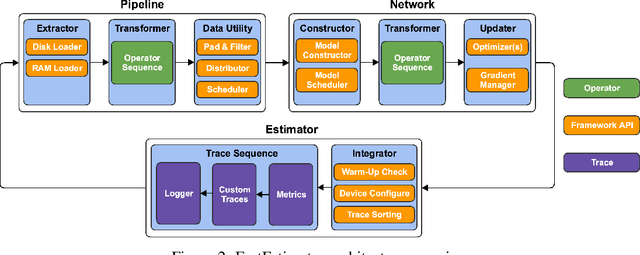

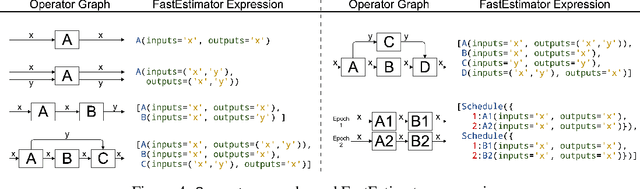
As the complexity of state-of-the-art deep learning models increases by the month, implementation, interpretation, and traceability become ever-more-burdensome challenges for AI practitioners around the world. Several AI frameworks have risen in an effort to stem this tide, but the steady advance of the field has begun to test the bounds of their flexibility, expressiveness, and ease of use. To address these concerns, we introduce a radically flexible high-level open source deep learning framework for both research and industry. We introduce FastEstimator.
Curriculum Learning for Domain Adaptation in Neural Machine Translation
May 14, 2019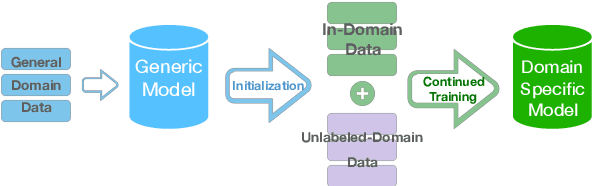
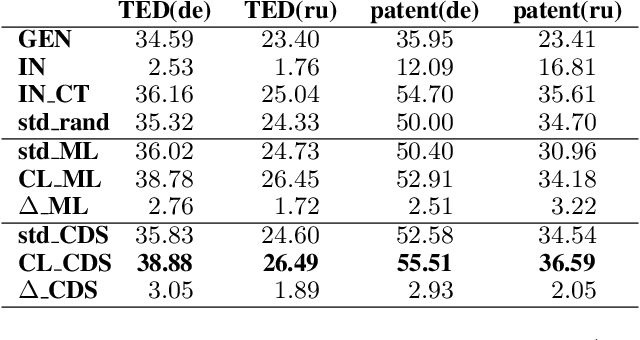
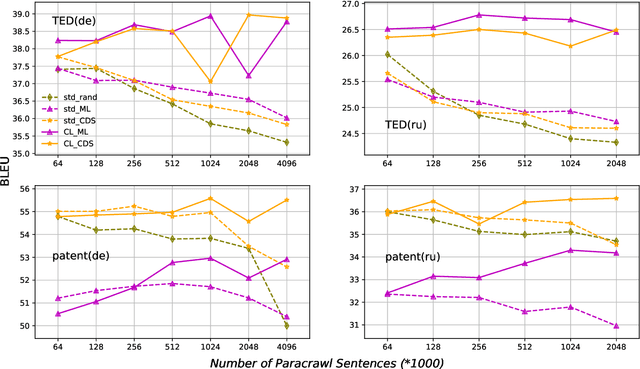
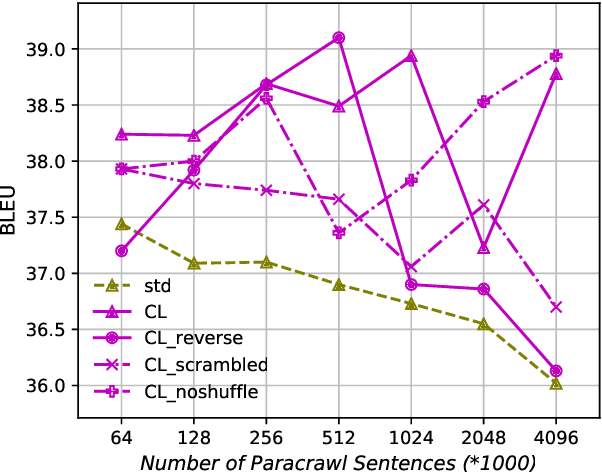
We introduce a curriculum learning approach to adapt generic neural machine translation models to a specific domain. Samples are grouped by their similarities to the domain of interest and each group is fed to the training algorithm with a particular schedule. This approach is simple to implement on top of any neural framework or architecture, and consistently outperforms both unadapted and adapted baselines in experiments with two distinct domains and two language pairs.
Complexity-Weighted Loss and Diverse Reranking for Sentence Simplification
Apr 04, 2019
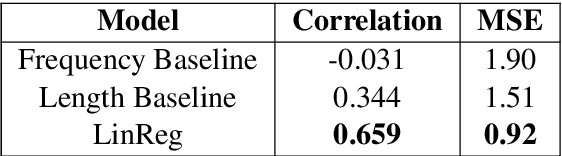
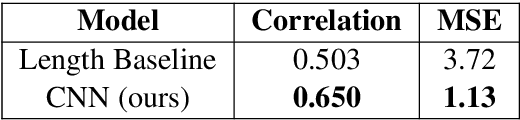
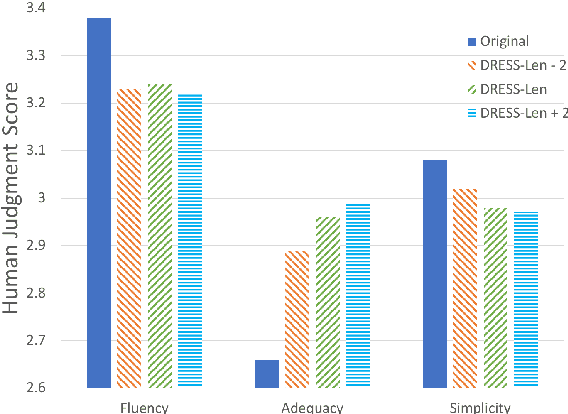
Sentence simplification is the task of rewriting texts so they are easier to understand. Recent research has applied sequence-to-sequence (Seq2Seq) models to this task, focusing largely on training-time improvements via reinforcement learning and memory augmentation. One of the main problems with applying generic Seq2Seq models for simplification is that these models tend to copy directly from the original sentence, resulting in outputs that are relatively long and complex. We aim to alleviate this issue through the use of two main techniques. First, we incorporate content word complexities, as predicted with a leveled word complexity model, into our loss function during training. Second, we generate a large set of diverse candidate simplifications at test time, and rerank these to promote fluency, adequacy, and simplicity. Here, we measure simplicity through a novel sentence complexity model. These extensions allow our models to perform competitively with state-of-the-art systems while generating simpler sentences. We report standard automatic and human evaluation metrics.
Reinforcement Learning based Curriculum Optimization for Neural Machine Translation
Feb 28, 2019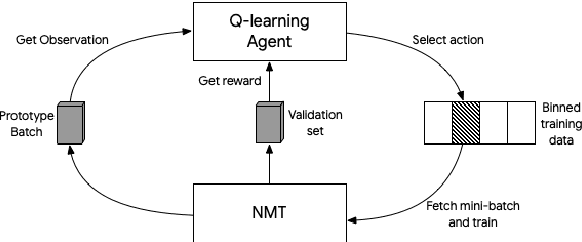
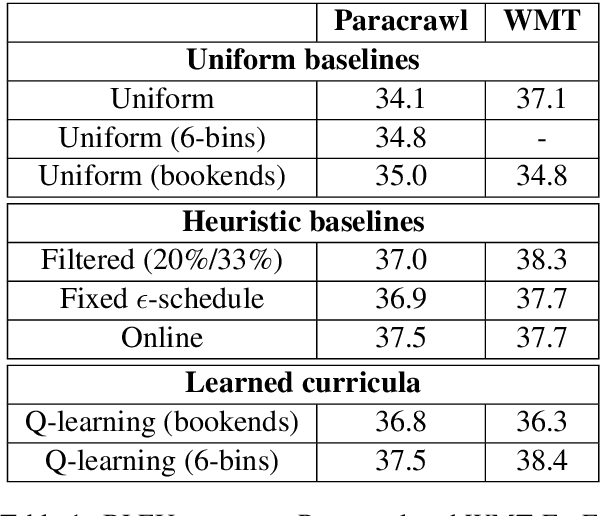
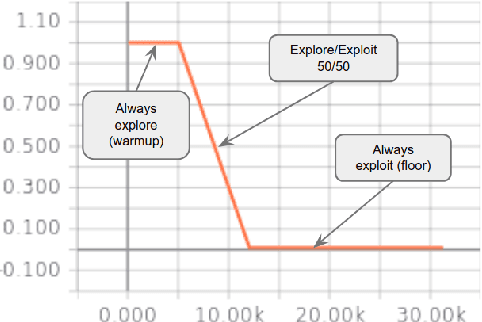
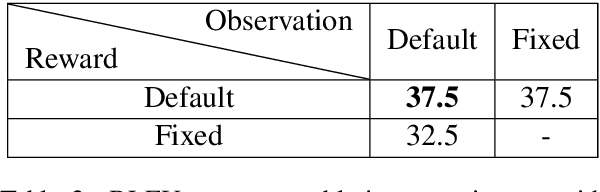
We consider the problem of making efficient use of heterogeneous training data in neural machine translation (NMT). Specifically, given a training dataset with a sentence-level feature such as noise, we seek an optimal curriculum, or order for presenting examples to the system during training. Our curriculum framework allows examples to appear an arbitrary number of times, and thus generalizes data weighting, filtering, and fine-tuning schemes. Rather than relying on prior knowledge to design a curriculum, we use reinforcement learning to learn one automatically, jointly with the NMT system, in the course of a single training run. We show that this approach can beat uniform and filtering baselines on Paracrawl and WMT English-to-French datasets by up to +3.4 BLEU, and match the performance of a hand-designed, state-of-the-art curriculum.
An Empirical Exploration of Curriculum Learning for Neural Machine Translation
Nov 02, 2018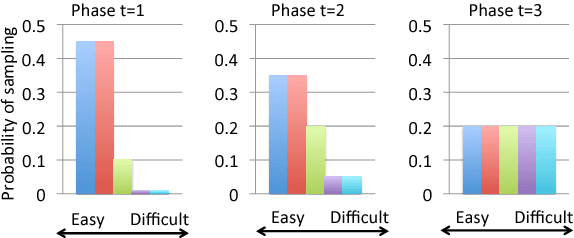
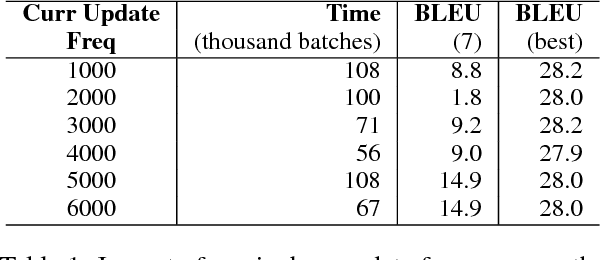

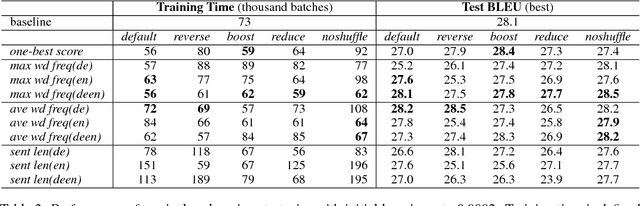
Machine translation systems based on deep neural networks are expensive to train. Curriculum learning aims to address this issue by choosing the order in which samples are presented during training to help train better models faster. We adopt a probabilistic view of curriculum learning, which lets us flexibly evaluate the impact of curricula design, and perform an extensive exploration on a German-English translation task. Results show that it is possible to improve convergence time at no loss in translation quality. However, results are highly sensitive to the choice of sample difficulty criteria, curriculum schedule and other hyperparameters.