 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Logical Neural Network Structure With More Direct Mapping From Logical Relations
Jun 22, 2021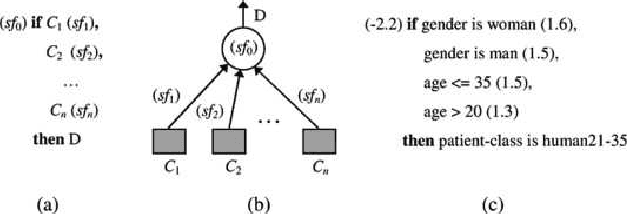
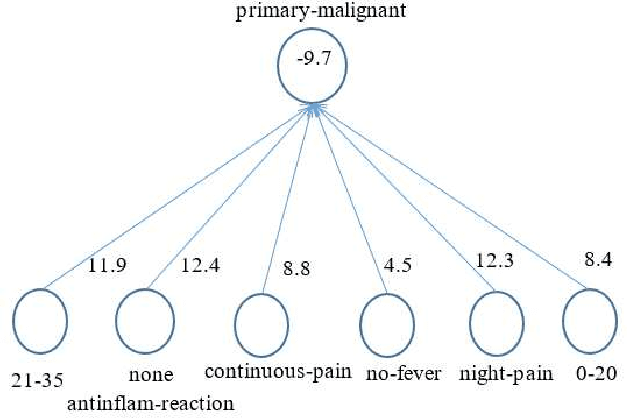
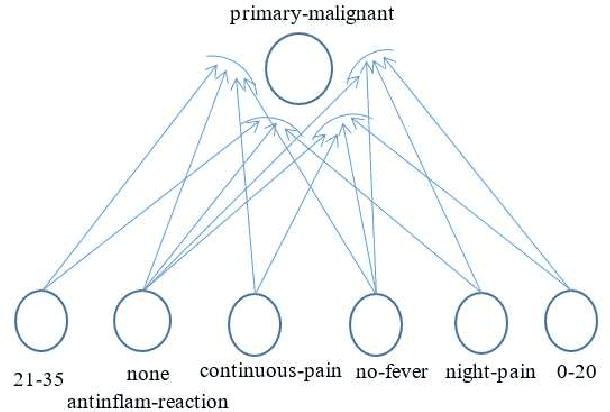
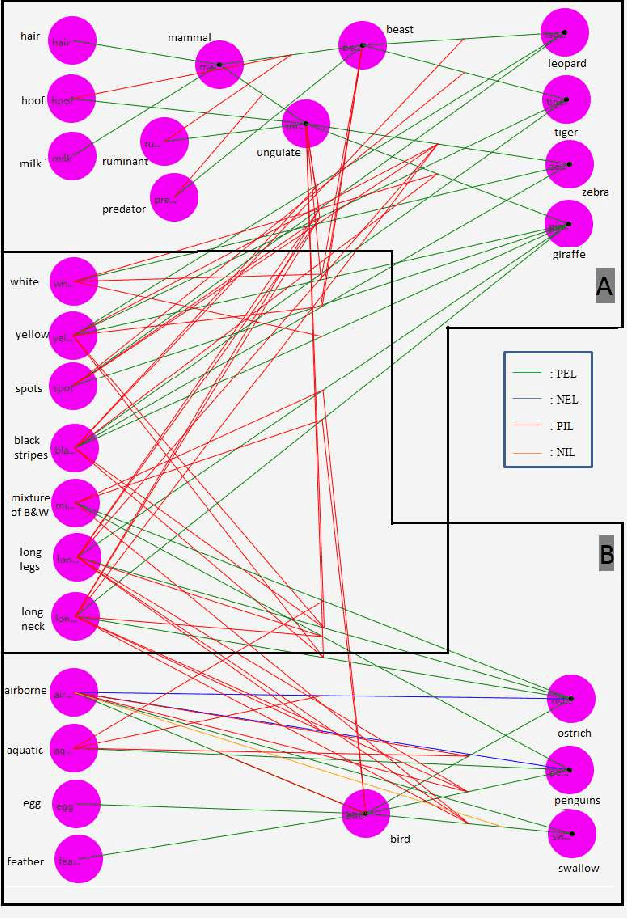
Logical relations widely exist in human activities. Human use them for making judgement and decision according to various conditions, which are embodied in the form of \emph{if-then} rules. As an important kind of cognitive intelligence, it is prerequisite of representing and storing logical relations rightly into computer systems so as to make automatic judgement and decision, especially for high-risk domains like medical diagnosis. However, current numeric ANN (Artificial Neural Network) models are good at perceptual intelligence such as image recognition while they are not good at cognitive intelligence such as logical representation, blocking the further application of ANN. To solve it, researchers have tried to design logical ANN models to represent and store logical relations. Although there are some advances in this research area, recent works still have disadvantages because the structures of these logical ANN models still don't map more directly with logical relations which will cause the corresponding logical relations cannot be read out from their network structures. Therefore, in order to represent logical relations more clearly by the neural network structure and to read out logical relations from it, this paper proposes a novel logical ANN model by designing the new logical neurons and links in demand of logical representation. Compared with the recent works on logical ANN models, this logical ANN model has more clear corresponding with logical relations using the more direct mapping method herein, thus logical relations can be read out following the connection patterns of the network structure. Additionally, less neurons are used.
SSMD: Semi-Supervised Medical Image Detection with Adaptive Consistency and Heterogeneous Perturbation
Jun 03, 2021Semi-Supervised classification and segmentation methods have been widely investigated in medical image analysis. Both approaches can improve the performance of fully-supervised methods with additional unlabeled data. However, as a fundamental task, semi-supervised object detection has not gained enough attention in the field of medical image analysis. In this paper, we propose a novel Semi-Supervised Medical image Detector (SSMD). The motivation behind SSMD is to provide free yet effective supervision for unlabeled data, by regularizing the predictions at each position to be consistent. To achieve the above idea, we develop a novel adaptive consistency cost function to regularize different components in the predictions. Moreover, we introduce heterogeneous perturbation strategies that work in both feature space and image space, so that the proposed detector is promising to produce powerful image representations and robust predictions. Extensive experimental results show that the proposed SSMD achieves the state-of-the-art performance at a wide range of settings. We also demonstrate the strength of each proposed module with comprehensive ablation studies.
Thermal Infrared Image Colorization for Nighttime Driving Scenes with Top-Down Guided Attention
Apr 29, 2021


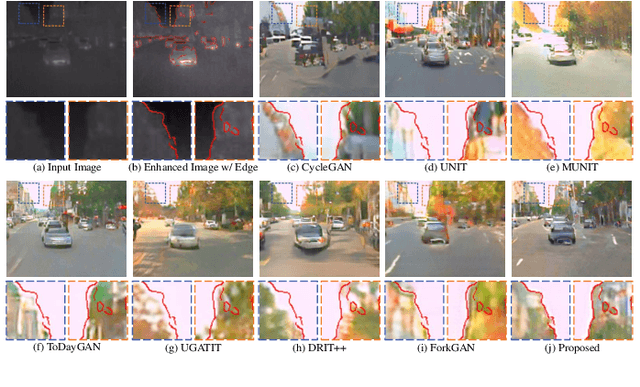
Benefitting from insensitivity to light and high penetration of foggy environments, infrared cameras are widely used for sensing in nighttime traffic scenes. However, the low contrast and lack of chromaticity of thermal infrared (TIR) images hinder the human interpretation and portability of high-level computer vision algorithms. Colorization to translate a nighttime TIR image into a daytime color (NTIR2DC) image may be a promising way to facilitate nighttime scene perception. Despite recent impressive advances in image translation, semantic encoding entanglement and geometric distortion in the NTIR2DC task remain under-addressed. Hence, we propose a toP-down attEntion And gRadient aLignment based GAN, referred to as PearlGAN. A top-down guided attention module and an elaborate attentional loss are first designed to reduce the semantic encoding ambiguity during translation. Then, a structured gradient alignment loss is introduced to encourage edge consistency between the translated and input images. In addition, pixel-level annotation is carried out on a subset of FLIR and KAIST datasets to evaluate the semantic preservation performance of multiple translation methods. Furthermore, a new metric is devised to evaluate the geometric consistency in the translation process. Extensive experiments demonstrate the superiority of the proposed PearlGAN over other image translation methods for the NTIR2DC task. The source code and labeled segmentation masks will be available at \url{https://github.com/FuyaLuo/PearlGAN/}.
SceneRec: Scene-Based Graph Neural Networks for Recommender Systems
Feb 12, 2021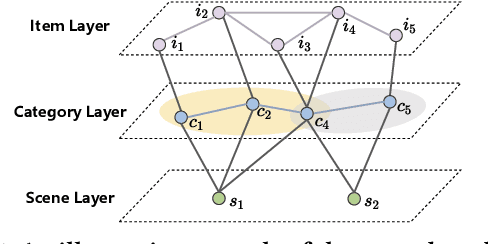
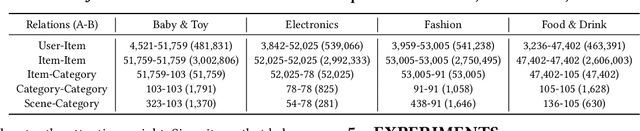
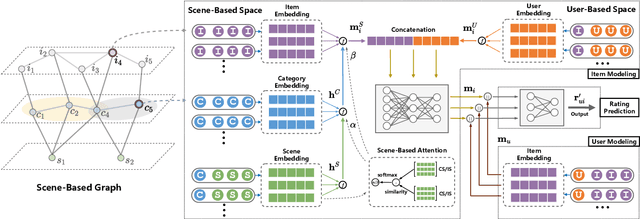
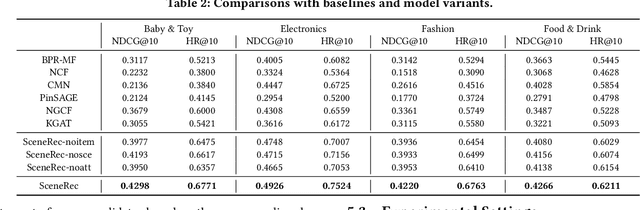
Collaborative filtering has been largely used to advance modern recommender systems to predict user preference. A key component in collaborative filtering is representation learning, which aims to project users and items into a low dimensional space to capture collaborative signals. However, the scene information, which has effectively guided many recommendation tasks, is rarely considered in existing collaborative filtering methods. To bridge this gap, we focus on scene-based collaborative recommendation and propose a novel representation model SceneRec. SceneRec formally defines a scene as a set of pre-defined item categories that occur simultaneously in real-life situations and creatively designs an item-category-scene hierarchical structure to build a scene-based graph. In the scene-based graph, we adopt graph neural networks to learn scene-specific representation on each item node, which is further aggregated with latent representation learned from collaborative interactions to make recommendations. We perform extensive experiments on real-world E-commerce datasets and the results demonstrate the effectiveness of the proposed method.
Human Action Recognition from Various Data Modalities: A Review
Jan 29, 2021
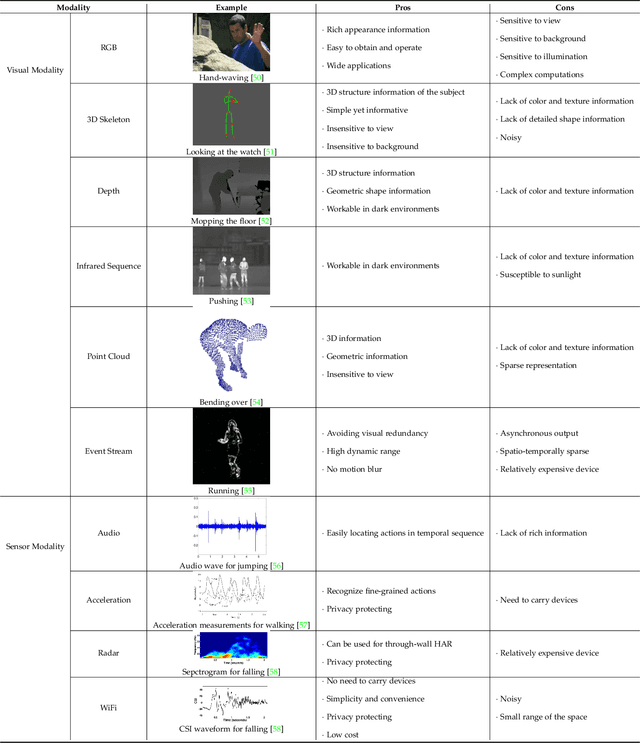

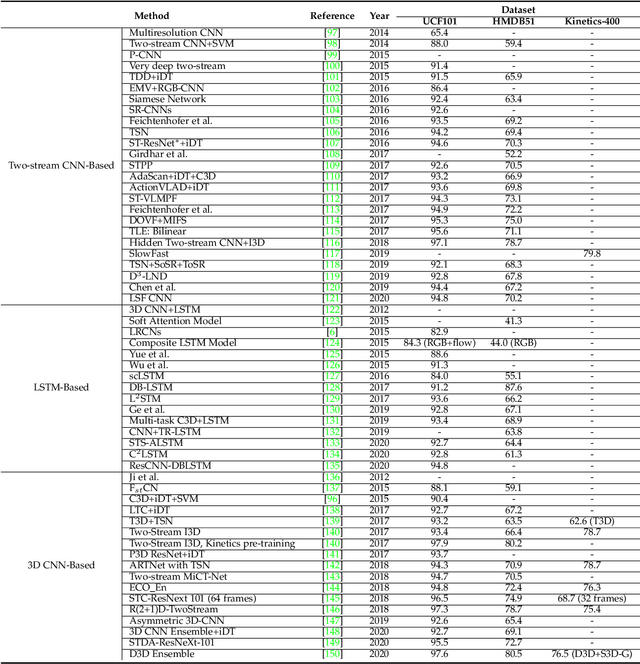
Human Action Recognition (HAR) aims to understand human behavior and assign a label to each action. It has a wide range of applications, and therefore has been attracting increasing attention in the field of computer vision. Human actions can be represented using various data modalities, such as RGB, skeleton, depth, infrared, point cloud, event stream, audio, acceleration, radar, and WiFi signal, which encode different sources of useful yet distinct information and have various advantages depending on the application scenarios. Consequently, lots of existing works have attempted to investigate different types of approaches for HAR using various modalities. In this paper, we present a comprehensive survey of recent progress in deep learning methods for HAR based on the type of input data modality. Specifically, we review the current mainstream deep learning methods for single data modalities and multiple data modalities, including the fusion-based and the co-learning-based frameworks. We also present comparative results on several benchmark datasets for HAR, together with insightful observations and inspiring future research directions.
Developing Univariate Neurodegeneration Biomarkers with Low-Rank and Sparse Subspace Decomposition
Oct 26, 2020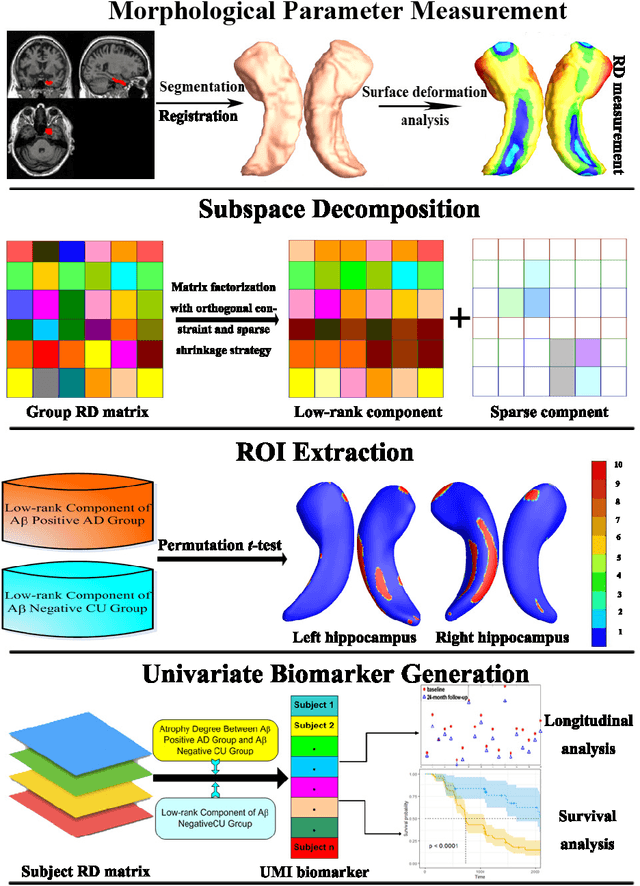

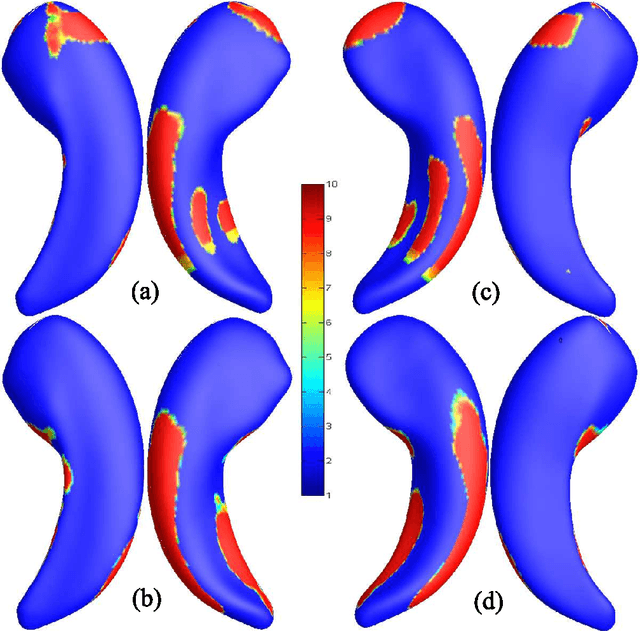

Cognitive decline due to Alzheimer's disease (AD) is closely associated with brain structure alterations captured by structural magnetic resonance imaging (sMRI). It supports the validity to develop sMRI-based univariate neurodegeneration biomarkers (UNB). However, existing UNB work either fails to model large group variances or does not capture AD dementia (ADD) induced changes. We propose a novel low-rank and sparse subspace decomposition method capable of stably quantifying the morphological changes induced by ADD. Specifically, we propose a numerically efficient rank minimization mechanism to extract group common structure and impose regularization constraints to encode the original 3D morphometry connectivity. Further, we generate regions-of-interest (ROI) with group difference study between common subspaces of $A\beta+$ AD and $A\beta-$ cognitively unimpaired (CU) groups. A univariate morphometry index (UMI) is constructed from these ROIs by summarizing individual morphological characteristics weighted by normalized difference between $A\beta+$ AD and $A\beta-$ CU groups. We use hippocampal surface radial distance feature to compute the UMIs and validate our work in the Alzheimer's Disease Neuroimaging Initiative (ADNI) cohort. With hippocampal UMIs, the estimated minimum sample sizes needed to detect a 25$\%$ reduction in the mean annual change with 80$\%$ power and two-tailed $P=0.05$ are 116, 279 and 387 for the longitudinal $A\beta+$ AD, $A\beta+$ mild cognitive impairment (MCI) and $A\beta+$ CU groups, respectively. Additionally, for MCI patients, UMIs well correlate with hazard ratio of conversion to AD ($4.3$, $95\%$ CI=$2.3-8.2$) within 18 months. Our experimental results outperform traditional hippocampal volume measures and suggest the application of UMI as a potential UNB.
A Traffic Light Dynamic Control Algorithm with Deep Reinforcement Learning Based on GNN Prediction
Sep 29, 2020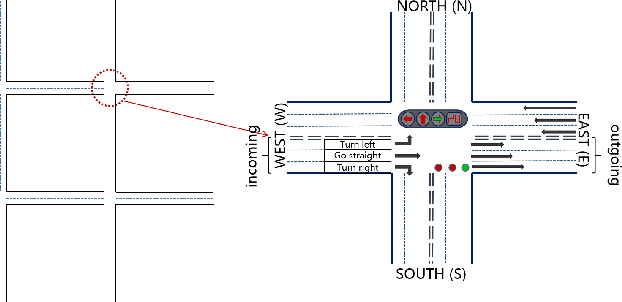
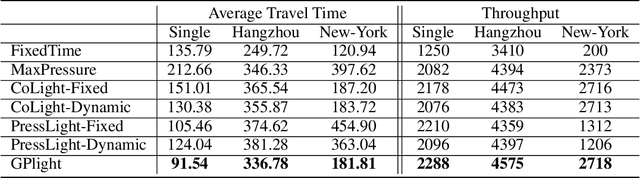
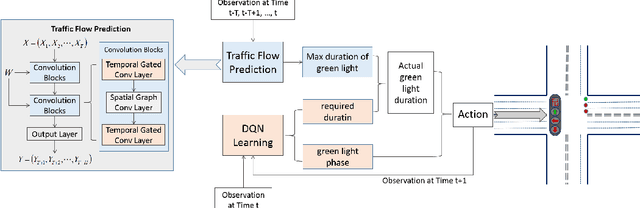
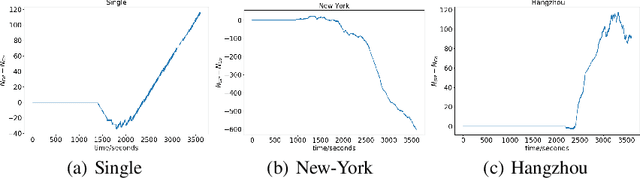
Today's intelligent traffic light control system is based on the current road traffic conditions for traffic regulation. However, these approaches cannot exploit the future traffic information in advance. In this paper, we propose GPlight, a deep reinforcement learning (DRL) algorithm integrated with graph neural network (GNN) , to relieve the traffic congestion for multi-intersection intelligent traffic control system. In GPlight, the graph neural network (GNN) is first used to predict the future short-term traffic flow at the intersections. Then, the results of traffic flow prediction are used in traffic light control, and the agent combines the predicted results with the observed current traffic conditions to dynamically control the phase and duration of the traffic lights at the intersection. Experiments on both synthetic and two real-world data-sets of Hangzhou and New-York verify the effectiveness and rationality of the GPlight algorithm.
PDLight: A Deep Reinforcement Learning Traffic Light Control Algorithm with Pressure and Dynamic Light Duration
Sep 29, 2020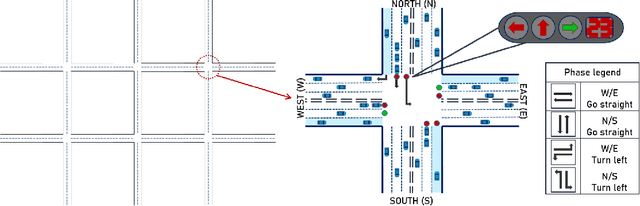

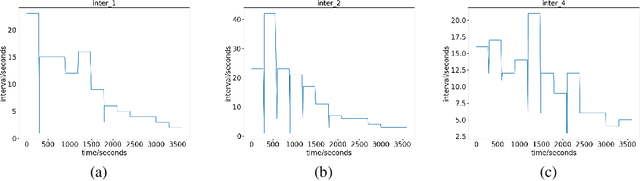

Existing ineffective and inflexible traffic light control at urban intersections can often lead to congestion in traffic flows and cause numerous problems, such as long delay and waste of energy. How to find the optimal signal timing strategy is a significant challenge in urban traffic management. In this paper, we propose PDlight, a deep reinforcement learning (DRL) traffic light control algorithm with a novel reward as PRCOL (Pressure with Remaining Capacity of Outgoing Lane). Serving as an improvement over the pressure used in traffic control algorithms, PRCOL considers not only the number of vehicles on the incoming lane but also the remaining capacity of the outgoing lane. Simulation results using both synthetic and real-world data-sets show that the proposed PDlight yields lower average travel time compared with several state-of-the-art algorithms, PressLight and Colight, under both fixed and dynamic green light duration.
Urban Sensing based on Mobile Phone Data: Approaches, Applications and Challenges
Aug 29, 2020
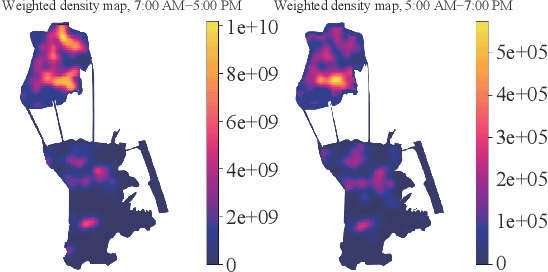
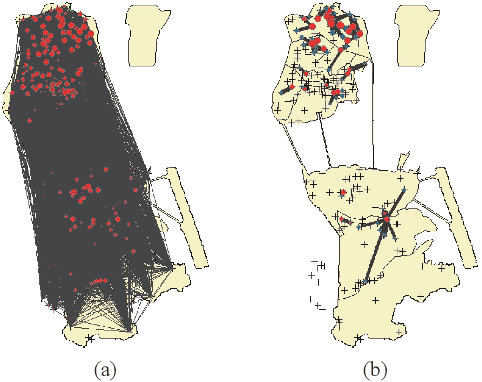
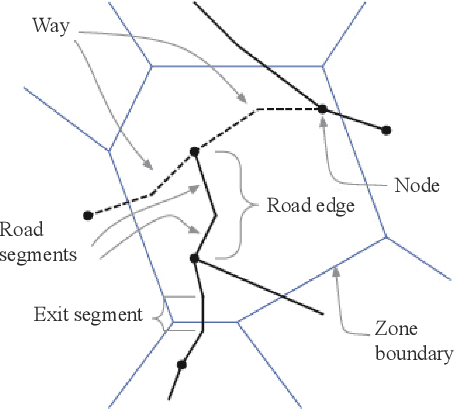
Data volume grows explosively with the proliferation of powerful smartphones and innovative mobile applications. The ability to accurately and extensively monitor and analyze these data is necessary. Much concern in mobile data analysis is related to human beings and their behaviours. Due to the potential value that lies behind these massive data, there have been different proposed approaches for understanding corresponding patterns. To that end, monitoring people's interactions, whether counting them at fixed locations or tracking them by generating origin-destination matrices is crucial. The former can be used to determine the utilization of assets like roads and city attractions. The latter is valuable when planning transport infrastructure. Such insights allow a government to predict the adoption of new roads, new public transport routes, modification of existing infrastructure, and detection of congestion zones, resulting in more efficient designs and improvement. Smartphone data exploration can help research in various fields, e.g., urban planning, transportation, health care, and business marketing. It can also help organizations in decision making, policy implementation, monitoring and evaluation at all levels. This work aims to review the methods and techniques that have been implemented to discover knowledge from mobile phone data. We classify these existing methods and present a taxonomy of the related work by discussing their pros and cons.
Learning while Respecting Privacy and Robustness to Distributional Uncertainties and Adversarial Data
Jul 07, 2020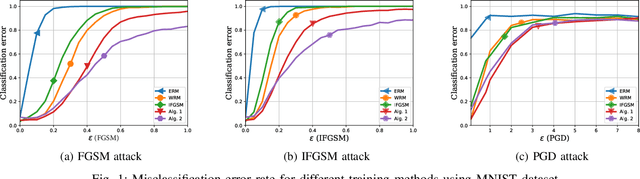
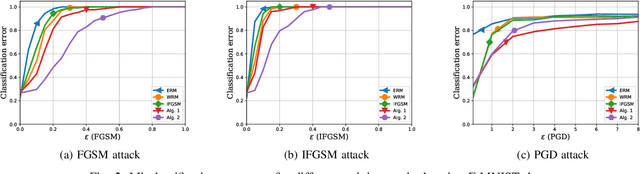
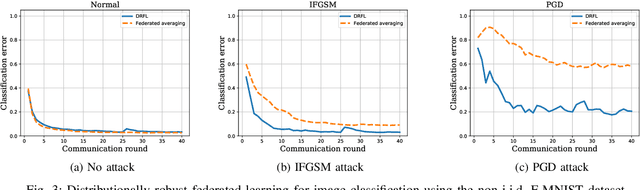
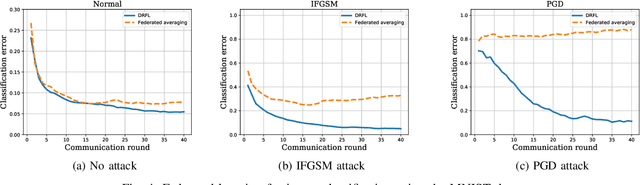
Data used to train machine learning models can be adversarial--maliciously constructed by adversaries to fool the model. Challenge also arises by privacy, confidentiality, or due to legal constraints when data are geographically gathered and stored across multiple learners, some of which may hold even an "anonymized" or unreliable dataset. In this context, the distributionally robust optimization framework is considered for training a parametric model, both in centralized and federated learning settings. The objective is to endow the trained model with robustness against adversarially manipulated input data, or, distributional uncertainties, such as mismatches between training and testing data distributions, or among datasets stored at different workers. To this aim, the data distribution is assumed unknown, and lies within a Wasserstein ball centered around the empirical data distribution. This robust learning task entails an infinite-dimensional optimization problem, which is challenging. Leveraging a strong duality result, a surrogate is obtained, for which three stochastic primal-dual algorithms are developed: i) stochastic proximal gradient descent with an $\epsilon$-accurate oracle, which invokes an oracle to solve the convex sub-problems; ii) stochastic proximal gradient descent-ascent, which approximates the solution of the convex sub-problems via a single gradient ascent step; and, iii) a distributionally robust federated learning algorithm, which solves the sub-problems locally at different workers where data are stored. Compared to the empirical risk minimization and federated learning methods, the proposed algorithms offer robustness with little computation overhead. Numerical tests using image datasets showcase the merits of the proposed algorithms under several existing adversarial attacks and distributional uncertainties.