 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust and Real-time Deep Tracking Via Multi-Scale Domain Adaptation
Jan 03, 2017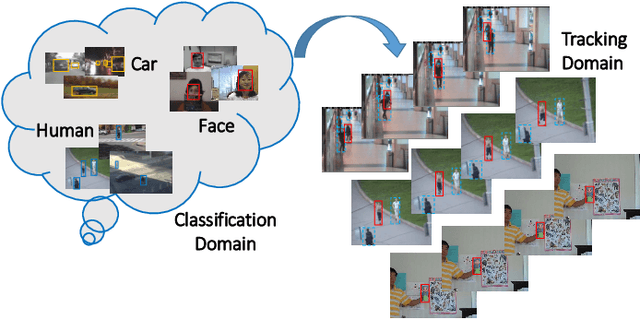

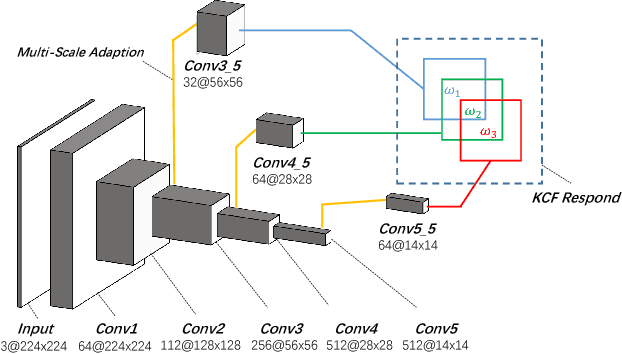
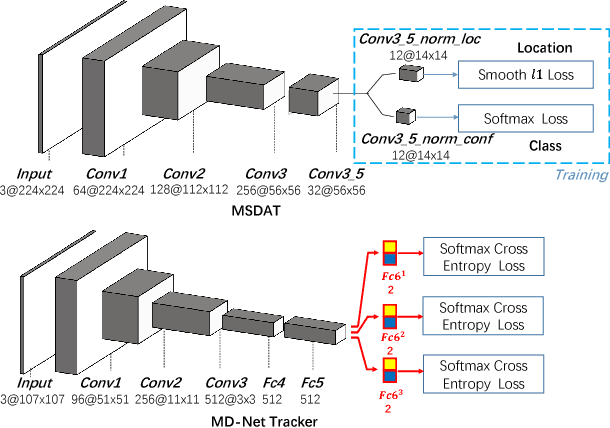
Visual tracking is a fundamental problem in computer vision. Recently, some deep-learning-based tracking algorithms have been achieving record-breaking performances. However, due to the high complexity of deep learning, most deep trackers suffer from low tracking speed, and thus are impractical in many real-world applications. Some new deep trackers with smaller network structure achieve high efficiency while at the cost of significant decrease on precision. In this paper, we propose to transfer the feature for image classification to the visual tracking domain via convolutional channel reductions. The channel reduction could be simply viewed as an additional convolutional layer with the specific task. It not only extracts useful information for object tracking but also significantly increases the tracking speed. To better accommodate the useful feature of the target in different scales, the adaptation filters are designed with different sizes. The yielded visual tracker is real-time and also illustrates the state-of-the-art accuracies in the experiment involving two well-adopted benchmarks with more than 100 test videos.
Recurrent Image Captioner: Describing Images with Spatial-Invariant Transformation and Attention Filtering
Dec 15, 2016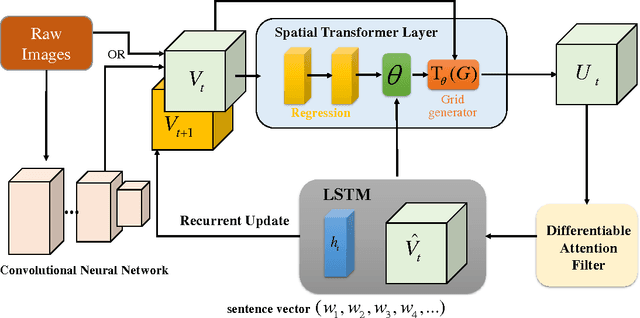
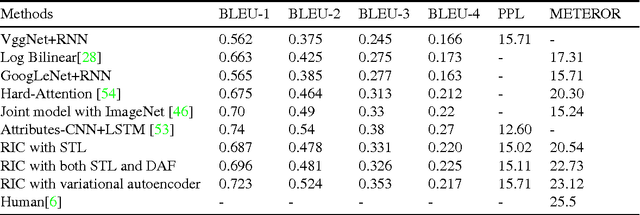
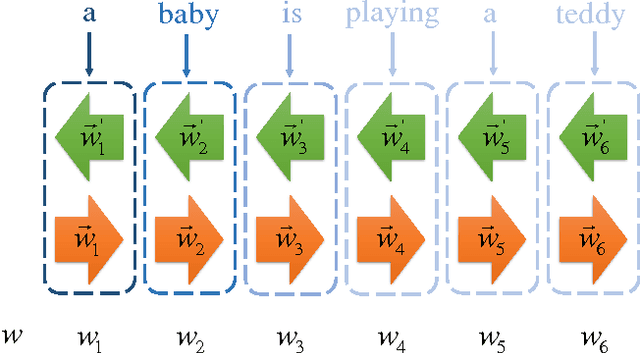
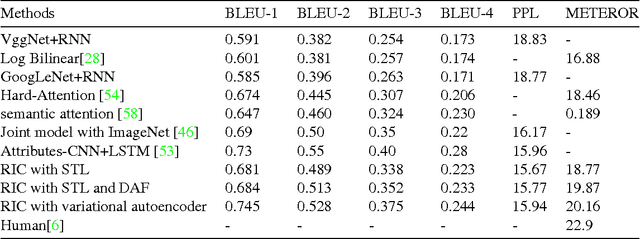
Along with the prosperity of recurrent neural network in modelling sequential data and the power of attention mechanism in automatically identify salient information, image captioning, a.k.a., image description, has been remarkably advanced in recent years. Nonetheless, most existing paradigms may suffer from the deficiency of invariance to images with different scaling, rotation, etc.; and effective integration of standalone attention to form a holistic end-to-end system. In this paper, we propose a novel image captioning architecture, termed Recurrent Image Captioner (\textbf{RIC}), which allows visual encoder and language decoder to coherently cooperate in a recurrent manner. Specifically, we first equip CNN-based visual encoder with a differentiable layer to enable spatially invariant transformation of visual signals. Moreover, we deploy an attention filter module (differentiable) between encoder and decoder to dynamically determine salient visual parts. We also employ bidirectional LSTM to preprocess sentences for generating better textual representations. Besides, we propose to exploit variational inference to optimize the whole architecture. Extensive experimental results on three benchmark datasets (i.e., Flickr8k, Flickr30k and MS COCO) demonstrate the superiority of our proposed architecture as compared to most of the state-of-the-art methods.
Binary Subspace Coding for Query-by-Image Video Retrieval
Dec 06, 2016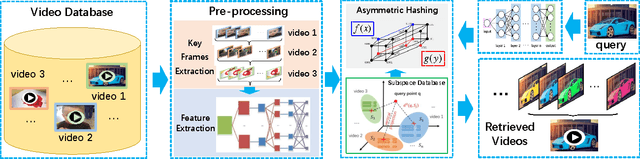
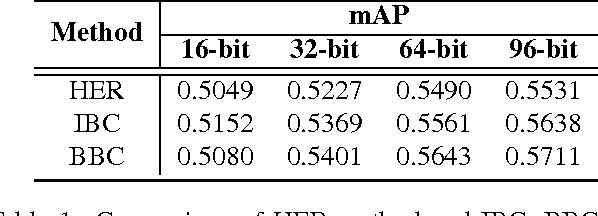


The query-by-image video retrieval (QBIVR) task has been attracting considerable research attention recently. However, most existing methods represent a video by either aggregating or projecting all its frames into a single datum point, which may easily cause severe information loss. In this paper, we propose an efficient QBIVR framework to enable an effective and efficient video search with image query. We first define a similarity-preserving distance metric between an image and its orthogonal projection in the subspace of the video, which can be equivalently transformed to a Maximum Inner Product Search (MIPS) problem. Besides, to boost the efficiency of solving the MIPS problem, we propose two asymmetric hashing schemes, which bridge the domain gap of images and videos. The first approach, termed Inner-product Binary Coding (IBC), preserves the inner relationships of images and videos in a common Hamming space. To further improve the retrieval efficiency, we devise a Bilinear Binary Coding (BBC) approach, which employs compact bilinear projections instead of a single large projection matrix. Extensive experiments have been conducted on four real-world video datasets to verify the effectiveness of our proposed approaches as compared to the state-of-the-arts.
Zero-Shot Hashing via Transferring Supervised Knowledge
Jun 16, 2016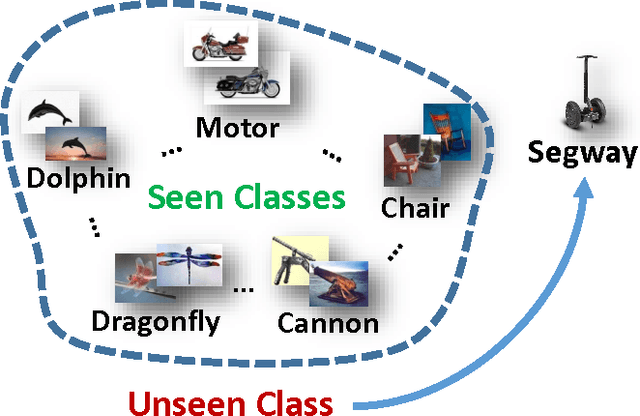
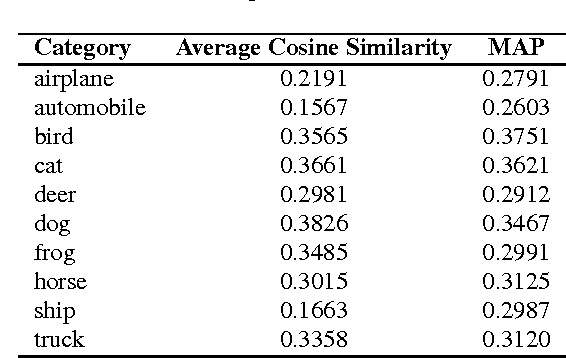
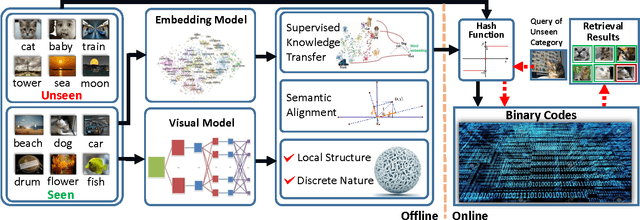
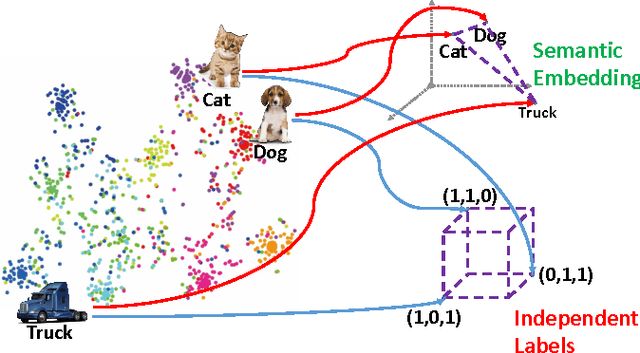
Hashing has shown its efficiency and effectiveness in facilitating large-scale multimedia applications. Supervised knowledge e.g. semantic labels or pair-wise relationship) associated to data is capable of significantly improving the quality of hash codes and hash functions. However, confronted with the rapid growth of newly-emerging concepts and multimedia data on the Web, existing supervised hashing approaches may easily suffer from the scarcity and validity of supervised information due to the expensive cost of manual labelling. In this paper, we propose a novel hashing scheme, termed \emph{zero-shot hashing} (ZSH), which compresses images of "unseen" categories to binary codes with hash functions learned from limited training data of "seen" categories. Specifically, we project independent data labels i.e. 0/1-form label vectors) into semantic embedding space, where semantic relationships among all the labels can be precisely characterized and thus seen supervised knowledge can be transferred to unseen classes. Moreover, in order to cope with the semantic shift problem, we rotate the embedded space to more suitably align the embedded semantics with the low-level visual feature space, thereby alleviating the influence of semantic gap. In the meantime, to exert positive effects on learning high-quality hash functions, we further propose to preserve local structural property and discrete nature in binary codes. Besides, we develop an efficient alternating algorithm to solve the ZSH model. Extensive experiments conducted on various real-life datasets show the superior zero-shot image retrieval performance of ZSH as compared to several state-of-the-art hashing methods.
Bidirectional Long-Short Term Memory for Video Description
Jun 15, 2016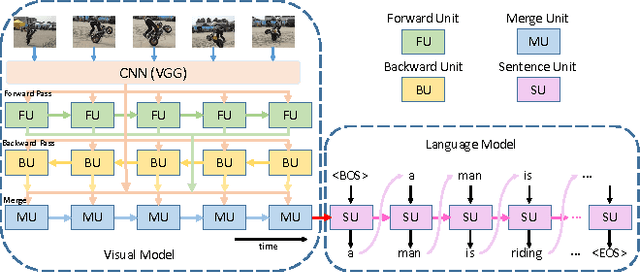


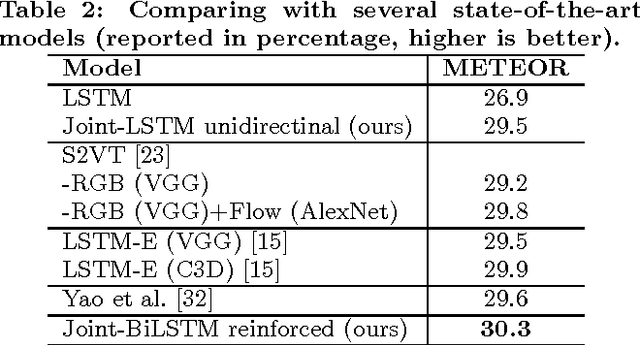
Video captioning has been attracting broad research attention in multimedia community. However, most existing approaches either ignore temporal information among video frames or just employ local contextual temporal knowledge. In this work, we propose a novel video captioning framework, termed as \emph{Bidirectional Long-Short Term Memory} (BiLSTM), which deeply captures bidirectional global temporal structure in video. Specifically, we first devise a joint visual modelling approach to encode video data by combining a forward LSTM pass, a backward LSTM pass, together with visual features from Convolutional Neural Networks (CNNs). Then, we inject the derived video representation into the subsequent language model for initialization. The benefits are in two folds: 1) comprehensively preserving sequential and visual information; and 2) adaptively learning dense visual features and sparse semantic representations for videos and sentences, respectively. We verify the effectiveness of our proposed video captioning framework on a commonly-used benchmark, i.e., Microsoft Video Description (MSVD) corpus, and the experimental results demonstrate that the superiority of the proposed approach as compared to several state-of-the-art methods.
Learning Binary Codes and Binary Weights for Efficient Classification
Mar 14, 2016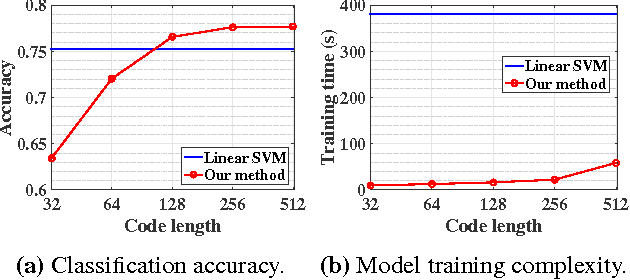
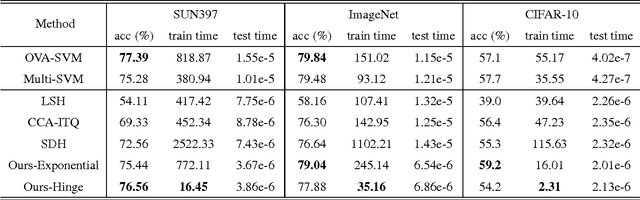
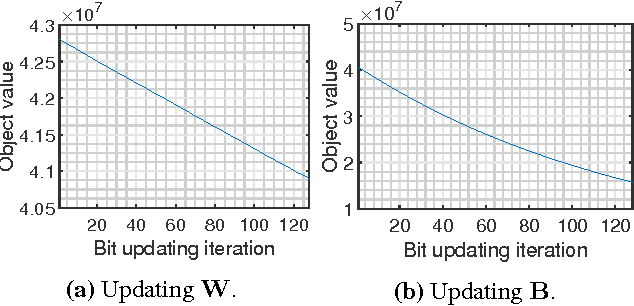
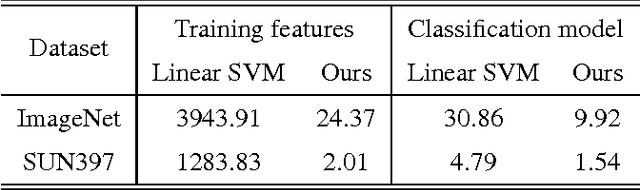
This paper proposes a generic formulation that significantly expedites the training and deployment of image classification models, particularly under the scenarios of many image categories and high feature dimensions. As a defining property, our method represents both the images and learned classifiers using binary hash codes, which are simultaneously learned from the training data. Classifying an image thereby reduces to computing the Hamming distance between the binary codes of the image and classifiers and selecting the class with minimal Hamming distance. Conventionally, compact hash codes are primarily used for accelerating image search. Our work is first of its kind to represent classifiers using binary codes. Specifically, we formulate multi-class image classification as an optimization problem over binary variables. The optimization alternatively proceeds over the binary classifiers and image hash codes. Profiting from the special property of binary codes, we show that the sub-problems can be efficiently solved through either a binary quadratic program (BQP) or linear program. In particular, for attacking the BQP problem, we propose a novel bit-flipping procedure which enjoys high efficacy and local optimality guarantee. Our formulation supports a large family of empirical loss functions and is here instantiated by exponential / hinge losses. Comprehensive evaluations are conducted on several representative image benchmarks. The experiments consistently observe reduced complexities of model training and deployment, without sacrifice of accuracies.
Supervised Discrete Hashing
Apr 19, 2015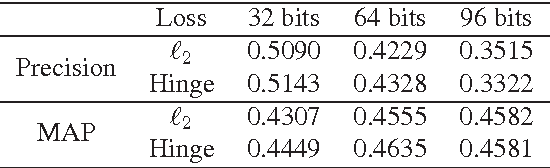
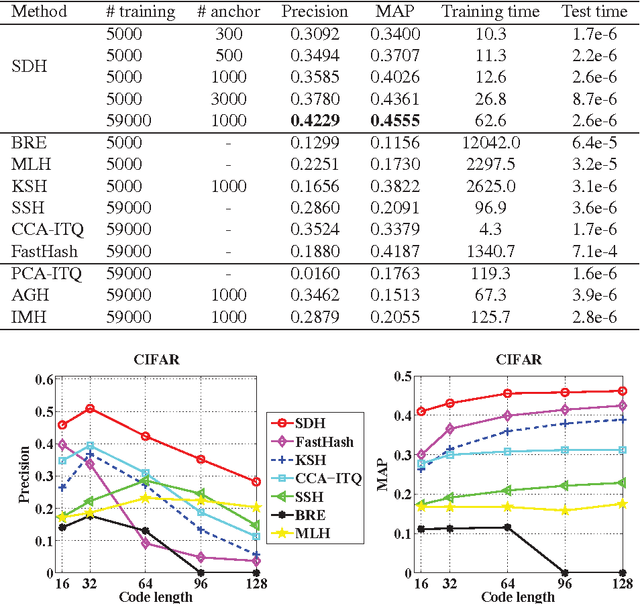
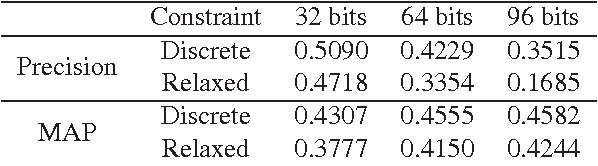
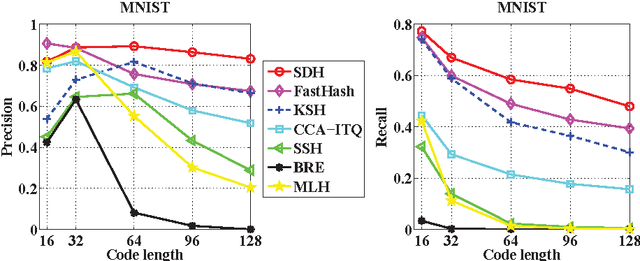
This paper has been withdrawn by the authour.
Hashing on Nonlinear Manifolds
Dec 02, 2014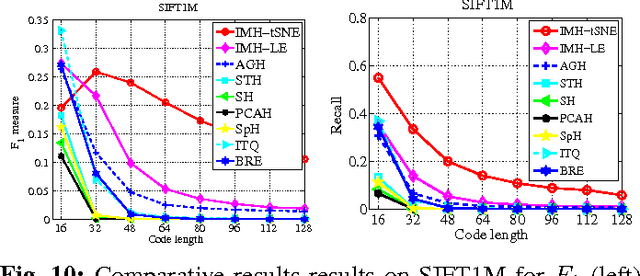

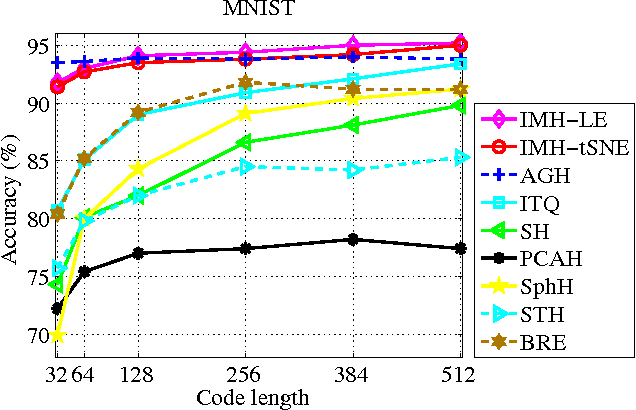
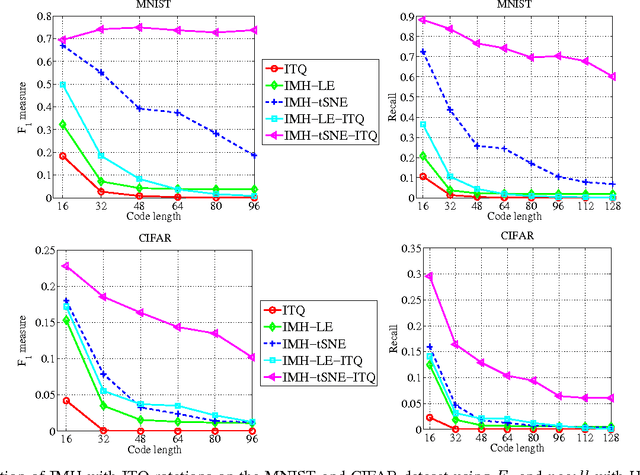
Learning based hashing methods have attracted considerable attention due to their ability to greatly increase the scale at which existing algorithms may operate. Most of these methods are designed to generate binary codes preserving the Euclidean similarity in the original space. Manifold learning techniques, in contrast, are better able to model the intrinsic structure embedded in the original high-dimensional data. The complexities of these models, and the problems with out-of-sample data, have previously rendered them unsuitable for application to large-scale embedding, however. In this work, how to learn compact binary embeddings on their intrinsic manifolds is considered. In order to address the above-mentioned difficulties, an efficient, inductive solution to the out-of-sample data problem, and a process by which non-parametric manifold learning may be used as the basis of a hashing method is proposed. The proposed approach thus allows the development of a range of new hashing techniques exploiting the flexibility of the wide variety of manifold learning approaches available. It is particularly shown that hashing on the basis of t-SNE outperforms state-of-the-art hashing methods on large-scale benchmark datasets, and is very effective for image classification with very short code lengths. The proposed hashing framework is shown to be easily improved, for example, by minimizing the quantization error with learned orthogonal rotations. In addition, a supervised inductive manifold hashing framework is developed by incorporating the label information, which is shown to greatly advance the semantic retrieval performance.
Face Identification with Second-Order Pooling
Sep 17, 2014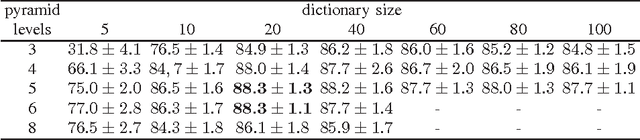

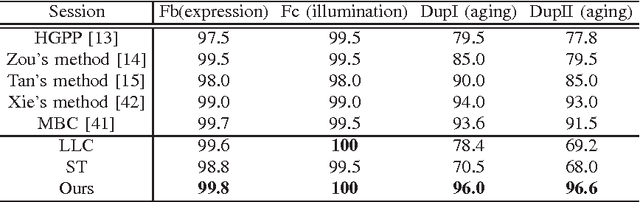
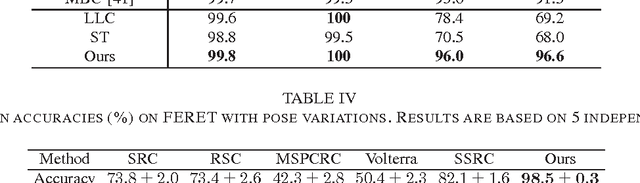
Automatic face recognition has received significant performance improvement by developing specialised facial image representations. On the other hand, generic object recognition has rarely been applied to the face recognition. Spatial pyramid pooling of features encoded by an over-complete dictionary has been the key component of many state-of-the-art image classification systems. Inspired by its success, in this work we develop a new face image representation method inspired by the second-order pooling in Carreira et al. [1], which was originally proposed for image segmentation. The proposed method differs from the previous methods in that, we encode the densely extracted local patches by a small-size dictionary; and the facial image signatures are obtained by pooling the second-order statistics of the encoded features. We show the importance of pooling on encoded features, which is bypassed by the original second-order pooling method to avoid the high computational cost. Equipped with a simple linear classifier, the proposed method outperforms the state-of-the-art face identification performance by large margins. For example, on the LFW databases, the proposed method performs better than the previous best by around 13% accuracy.
Face Image Classification by Pooling Raw Features
Sep 17, 2014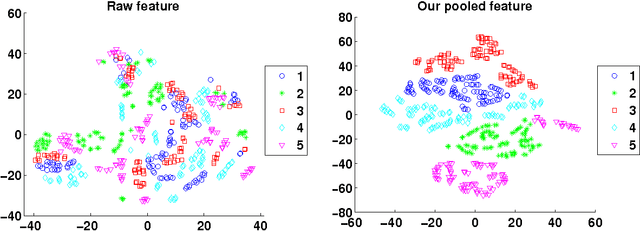
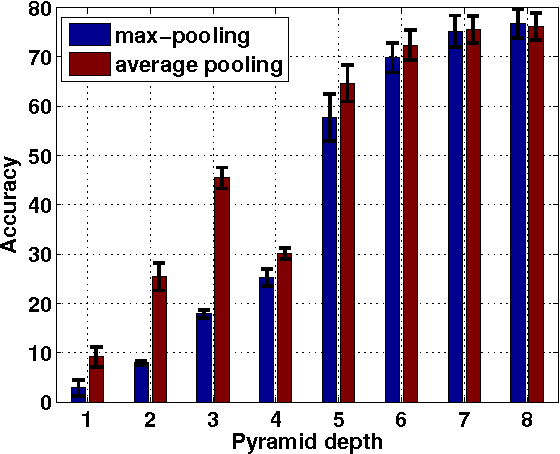
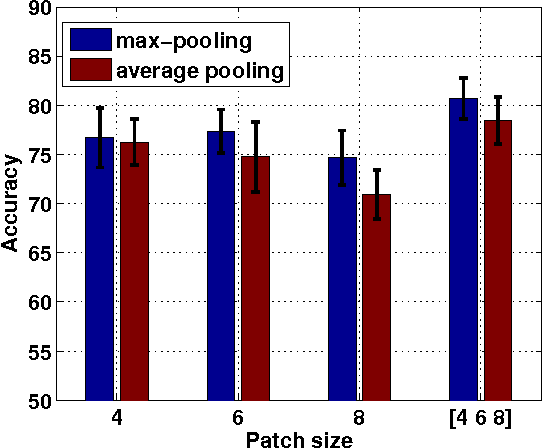
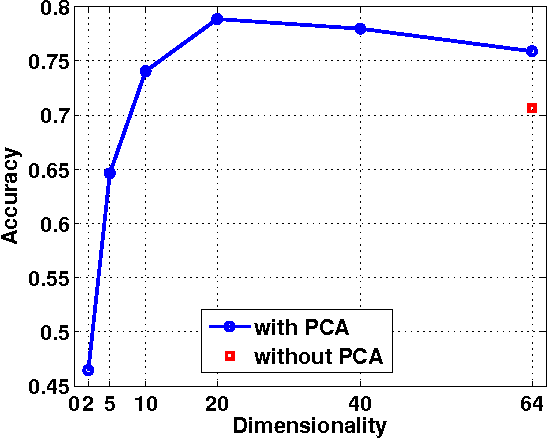
We propose a very simple, efficient yet surprisingly effective feature extraction method for face recognition (about 20 lines of Matlab code), which is mainly inspired by spatial pyramid pooling in generic image classification. We show that features formed by simply pooling local patches over a multi-level pyramid, coupled with a linear classifier, can significantly outperform most recent face recognition methods. The simplicity of our feature extraction procedure is demonstrated by the fact that no learning is involved (except PCA whitening). We show that, multi-level spatial pooling and dense extraction of multi-scale patches play critical roles in face image classification. The extracted facial features can capture strong structural information of individual faces with no label information being used. We also find that, pre-processing on local image patches such as contrast normalization can have an important impact on the classification accuracy. In particular, on the challenging face recognition datasets of FERET and LFW-a, our method improves previous best results by more than 10% and 20%, respectively.