 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrank Wood
Safer End-to-End Autonomous Driving via Conditional Imitation Learning and Command Augmentation
Sep 20, 2019
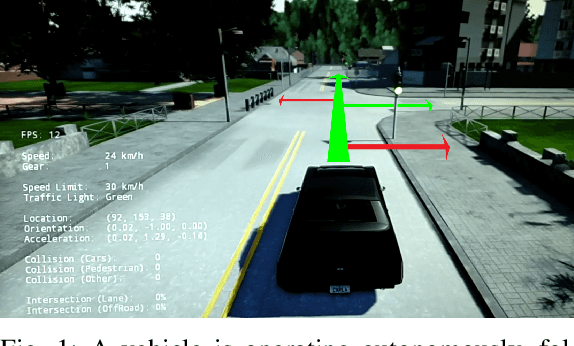
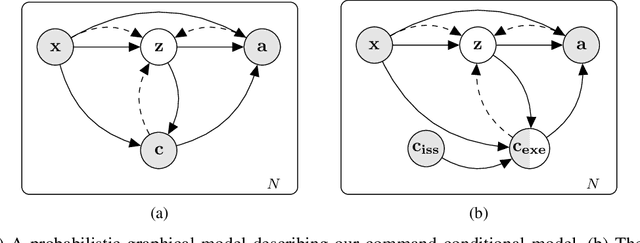
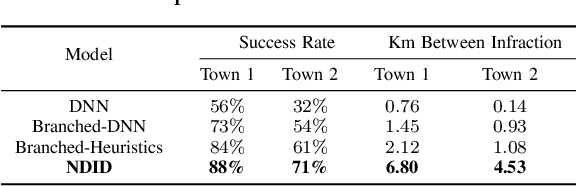

Imitation learning is a promising approach to end-to-end training of autonomous vehicle controllers. Typically the driving process with such approaches is entirely automatic and black-box, although in practice it is desirable to control the vehicle through high-level commands, such as telling it which way to go at an intersection. In existing work this has been accomplished by the application of a branched neural architecture, since directly providing the command as an additional input to the controller often results in the command being ignored. In this work we overcome this limitation by learning a disentangled probabilistic latent variable model that generates the steering commands. We achieve faithful command-conditional generation without using a branched architecture and demonstrate improved stability of the controller, applying only a variational objective without any domain-specific adjustments. On top of that, we extend our model with an additional latent variable and augment the dataset to train a controller that is robust to unsafe commands, such as asking it to turn into a wall. The main contribution of this work is a recipe for building controllable imitation driving agents that improves upon multiple aspects of the current state of the art relating to robustness and interpretability.
The Virtual Patch Clamp: Imputing C. elegans Membrane Potentials from Calcium Imaging
Jul 24, 2019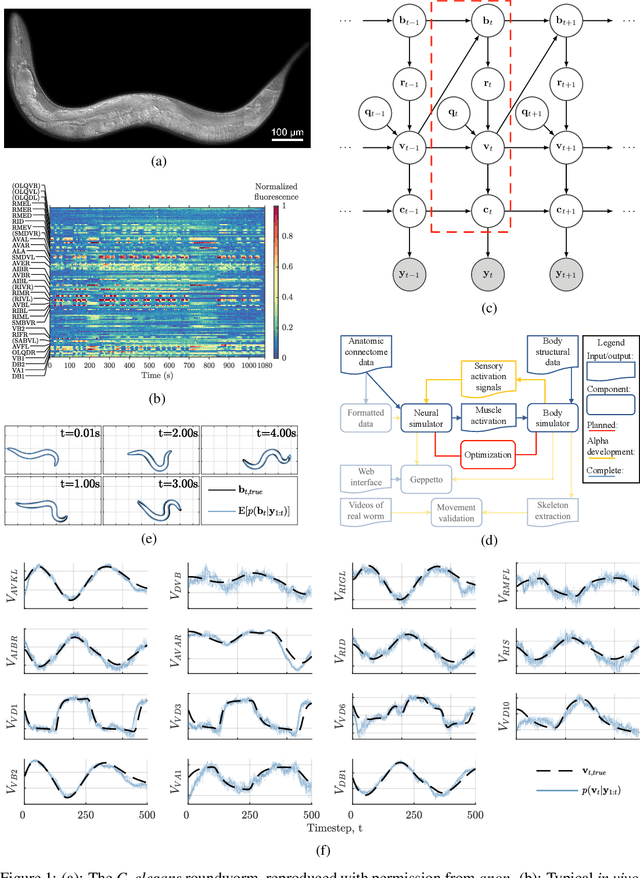
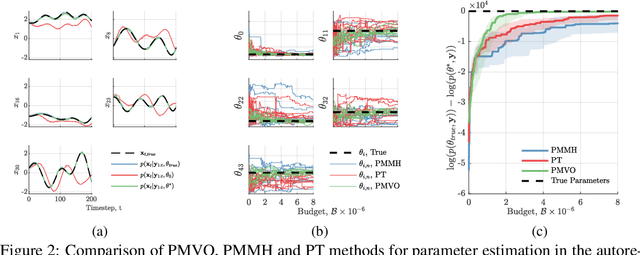
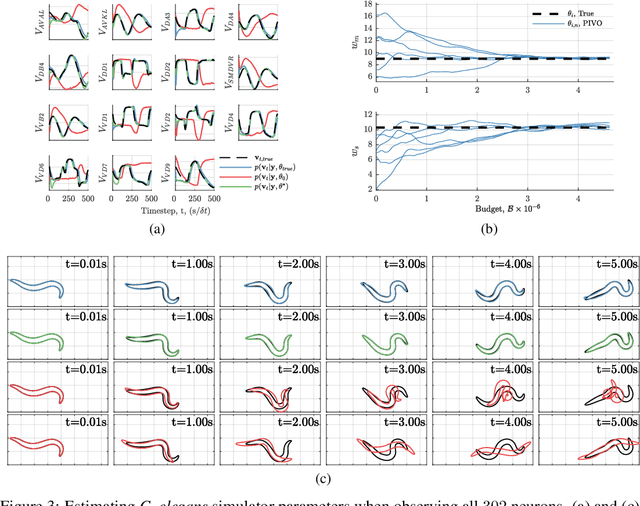
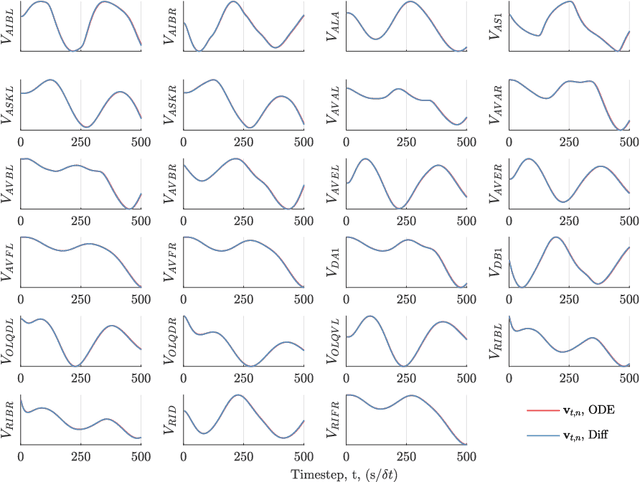
We develop a stochastic whole-brain and body simulator of the nematode roundworm Caenorhabditis elegans (C. elegans) and show that it is sufficiently regularizing to allow imputation of latent membrane potentials from partial calcium fluorescence imaging observations. This is the first attempt we know of to "complete the circle," where an anatomically grounded whole-connectome simulator is used to impute a time-varying "brain" state at single-cell fidelity from covariates that are measurable in practice. The sequential Monte Carlo (SMC) method we employ not only enables imputation of said latent states but also presents a strategy for learning simulator parameters via variational optimization of the noisy model evidence approximation provided by SMC. Our imputation and parameter estimation experiments were conducted on distributed systems using novel implementations of the aforementioned techniques applied to synthetic data of dimension and type representative of that which are measured in laboratories currently.
Amortized Monte Carlo Integration
Jul 18, 2019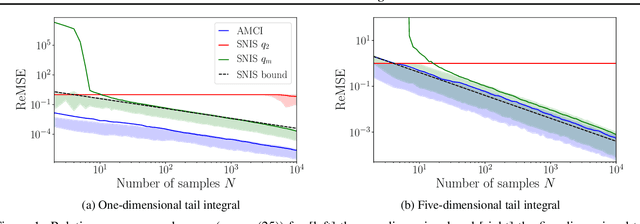
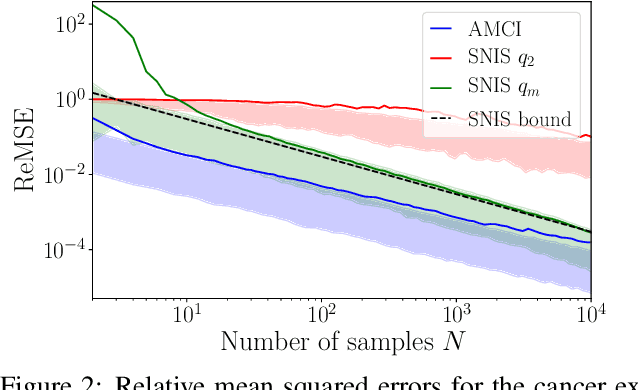
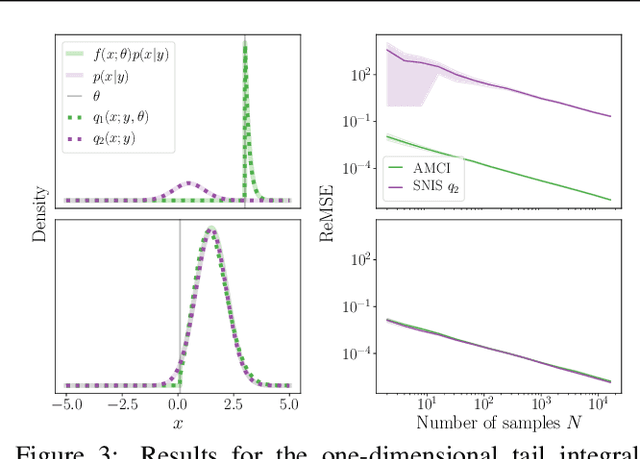
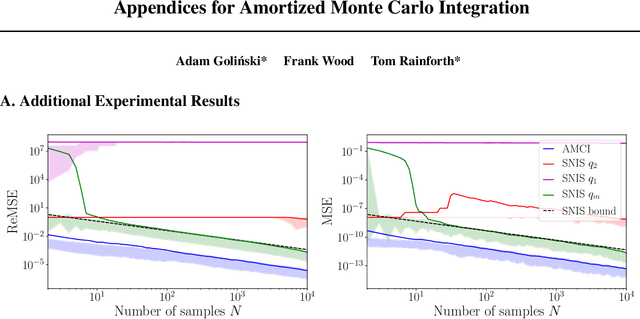
Current approaches to amortizing Bayesian inference focus solely on approximating the posterior distribution. Typically, this approximation is, in turn, used to calculate expectations for one or more target functions - a computational pipeline which is inefficient when the target function(s) are known upfront. In this paper, we address this inefficiency by introducing AMCI, a method for amortizing Monte Carlo integration directly. AMCI operates similarly to amortized inference but produces three distinct amortized proposals, each tailored to a different component of the overall expectation calculation. At runtime, samples are produced separately from each amortized proposal, before being combined to an overall estimate of the expectation. We show that while existing approaches are fundamentally limited in the level of accuracy they can achieve, AMCI can theoretically produce arbitrarily small errors for any integrable target function using only a single sample from each proposal at runtime. We further show that it is able to empirically outperform the theoretically optimal self-normalized importance sampler on a number of example problems. Furthermore, AMCI allows not only for amortizing over datasets but also amortizing over target functions.
Etalumis: Bringing Probabilistic Programming to Scientific Simulators at Scale
Jul 08, 2019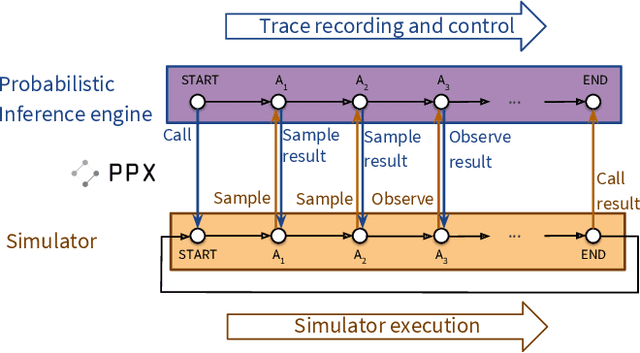

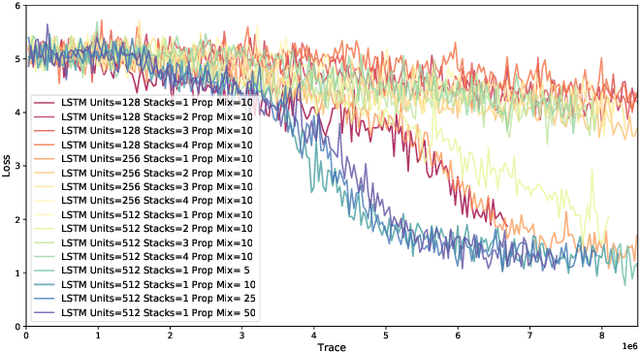
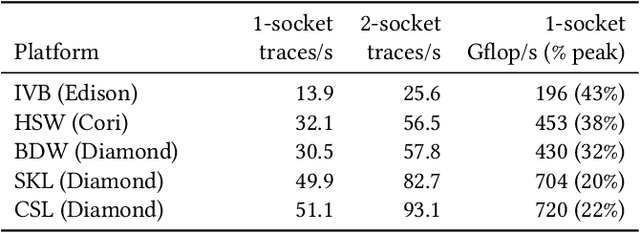
Probabilistic programming languages (PPLs) are receiving widespread attention for performing Bayesian inference in complex generative models. However, applications to science remain limited because of the impracticability of rewriting complex scientific simulators in a PPL, the computational cost of inference, and the lack of scalable implementations. To address these, we present a novel PPL framework that couples directly to existing scientific simulators through a cross-platform probabilistic execution protocol and provides Markov chain Monte Carlo (MCMC) and deep-learning-based inference compilation (IC) engines for tractable inference. To guide IC inference, we perform distributed training of a dynamic 3DCNN--LSTM architecture with a PyTorch-MPI-based framework on 1,024 32-core CPU nodes of the Cori supercomputer with a global minibatch size of 128k: achieving a performance of 450 Tflop/s through enhancements to PyTorch. We demonstrate a Large Hadron Collider (LHC) use-case with the C++ Sherpa simulator and achieve the largest-scale posterior inference in a Turing-complete PPL.
The Thermodynamic Variational Objective
Jun 28, 2019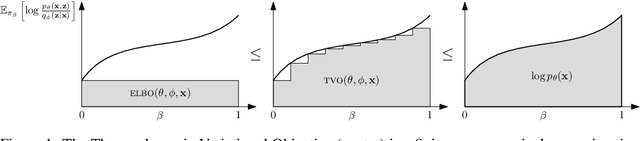
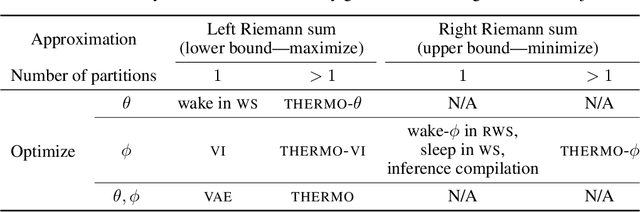
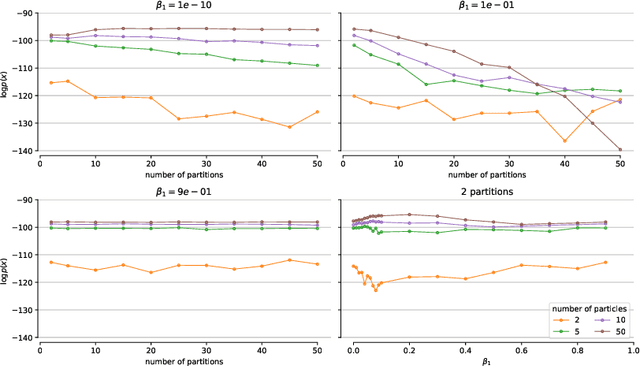
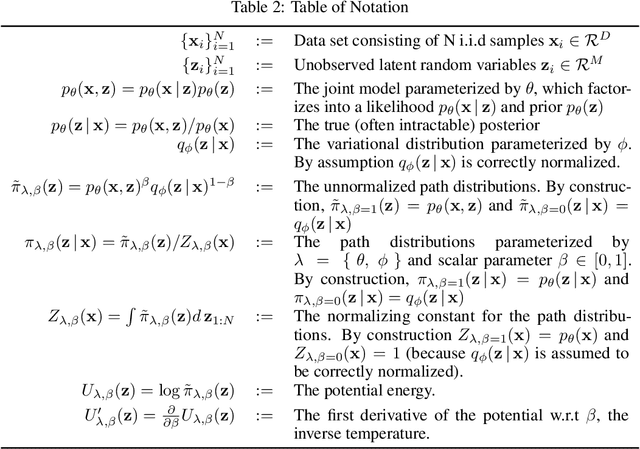
We introduce the thermodynamic variational objective (TVO) for learning in both continuous and discrete deep generative models. The TVO arises from a key connection between variational inference and thermodynamic integration that results in a tighter lower bound to the log marginal likelihood than the standard variational evidence lower bound (ELBO), while remaining as broadly applicable. We provide a computationally efficient gradient estimator for the TVO that applies to continuous, discrete, and non-reparameterizable distributions and show that the objective functions used in variational inference, variational autoencoders, wake sleep, and inference compilation are all special cases of the TVO. We evaluate the TVO for learning of discrete and continuous variational auto encoders, and find it achieves state of the art for learning in discrete variable models, and outperform VAEs on continuous variable models without using the reparameterization trick.
Near-Optimal Glimpse Sequences for Improved Hard Attention Neural Network Training
Jun 13, 2019
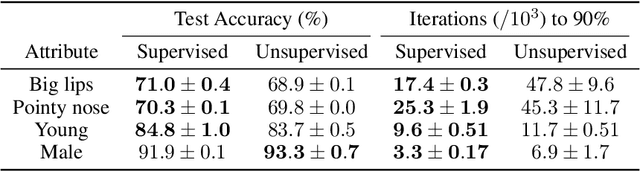
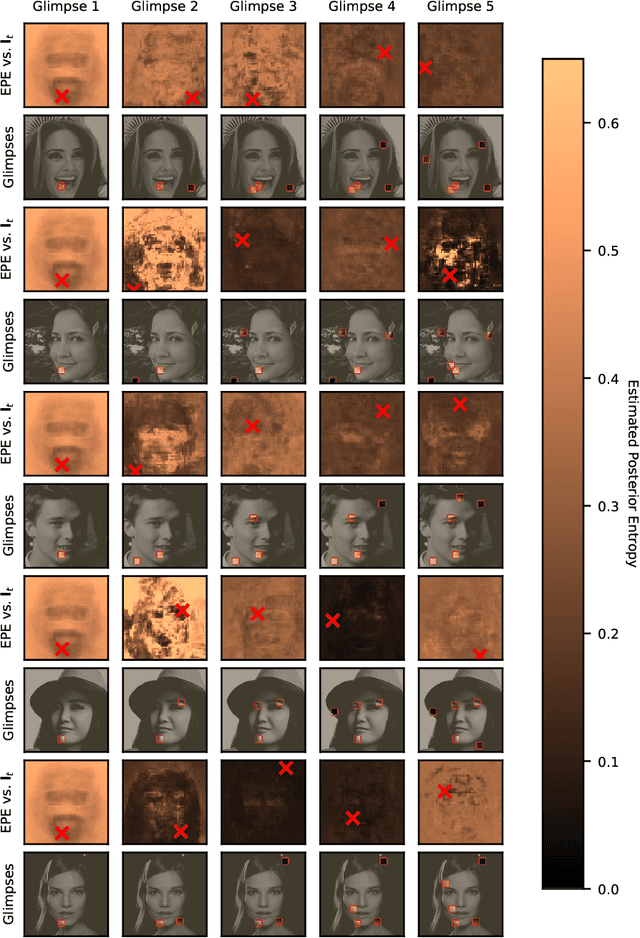
We introduce the use of Bayesian optimal experimental design techniques for generating glimpse sequences to use in semi-supervised training of hard attention networks. Hard attention holds the promise of greater energy efficiency and superior inference performance. Employing such networks for image classification usually involves choosing a sequence of glimpse locations from a stochastic policy. As the outputs of observations are typically non-differentiable with respect to their glimpse locations, unsupervised gradient learning of such a policy requires REINFORCE-style updates. Also, the only reward signal is the final classification accuracy. For these reasons hard attention networks, despite their promise, have not achieved the wide adoption that soft attention networks have and, in many practical settings, are difficult to train. We find that our method for semi-supervised training makes it easier and faster to train hard attention networks and correspondingly could make them practical to consider in situations where they were not before.
Imitation Learning of Factored Multi-agent Reactive Models
Mar 12, 2019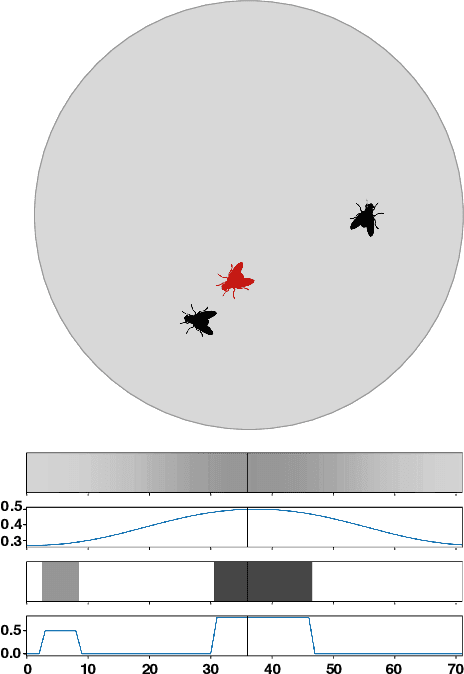

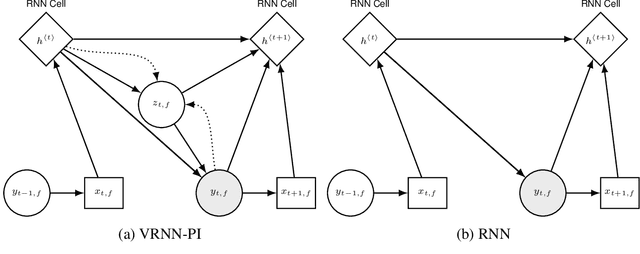
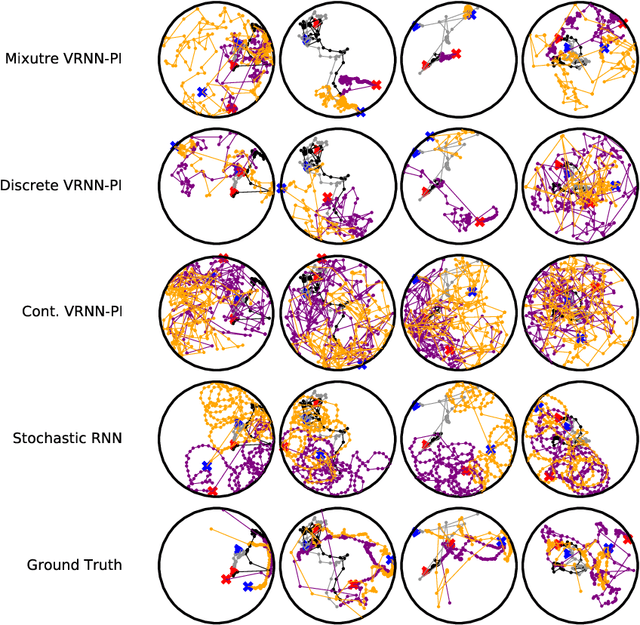
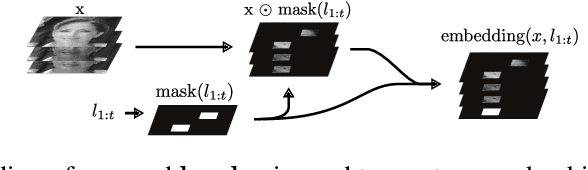
We apply recent advances in deep generative modeling to the task of imitation learning from biological agents. Specifically, we apply variations of the variational recurrent neural network model to a multi-agent setting where we learn policies of individual uncoordinated agents acting based on their perceptual inputs and their hidden belief state. We learn stochastic policies for these agents directly from observational data, without constructing a reward function. An inference network learned jointly with the policy allows for efficient inference over the agent's belief state given a sequence of its current perceptual inputs and the prior actions it performed, which lets us extrapolate observed sequences of behavior into the future while maintaining uncertainty estimates over future trajectories. We test our approach on a dataset of flies interacting in a 2D environment, where we demonstrate better predictive performance than existing approaches which learn deterministic policies with recurrent neural networks. We further show that the uncertainty estimates over future trajectories we obtain are well calibrated, which makes them useful for a variety of downstream processing tasks.
LF-PPL: A Low-Level First Order Probabilistic Programming Language for Non-Differentiable Models
Mar 06, 2019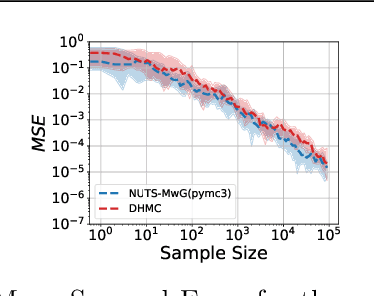
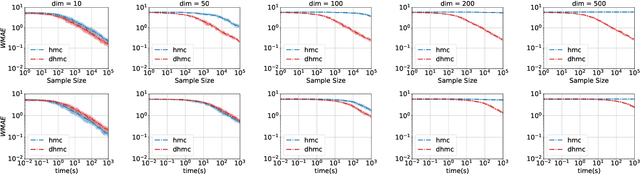

We develop a new Low-level, First-order Probabilistic Programming Language (LF-PPL) suited for models containing a mix of continuous, discrete, and/or piecewise-continuous variables. The key success of this language and its compilation scheme is in its ability to automatically distinguish parameters the density function is discontinuous with respect to, while further providing runtime checks for boundary crossings. This enables the introduction of new inference engines that are able to exploit gradient information, while remaining efficient for models which are not everywhere differentiable. We demonstrate this ability by incorporating a discontinuous Hamiltonian Monte Carlo (DHMC) inference engine that is able to deliver automated and efficient inference for non-differentiable models. Our system is backed up by a mathematical formalism that ensures that any model expressed in this language has a density with measure zero discontinuities to maintain the validity of the inference engine.
Faithful Inversion of Generative Models for Effective Amortized Inference
Oct 24, 2018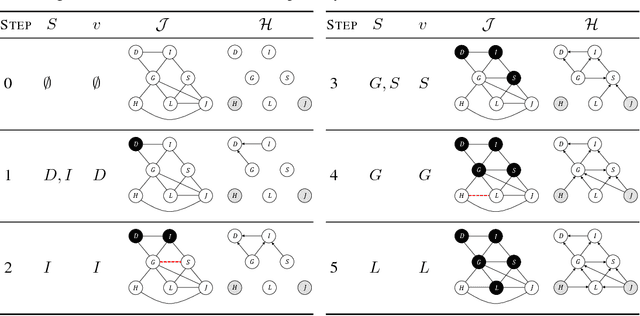
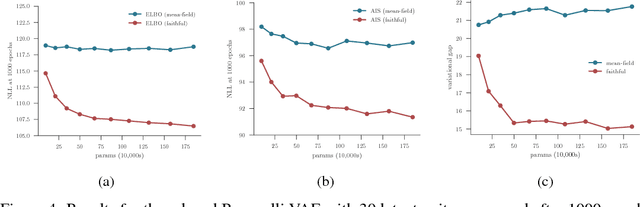

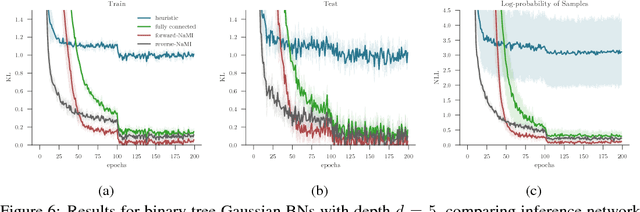
Inference amortization methods share information across multiple posterior-inference problems, allowing each to be carried out more efficiently. Generally, they require the inversion of the dependency structure in the generative model, as the modeller must learn a mapping from observations to distributions approximating the posterior. Previous approaches have involved inverting the dependency structure in a heuristic way that fails to capture these dependencies correctly, thereby limiting the achievable accuracy of the resulting approximations. We introduce an algorithm for faithfully, and minimally, inverting the graphical model structure of any generative model. Such inverses have two crucial properties: (a) they do not encode any independence assertions that are absent from the model and; (b) they are local maxima for the number of true independencies encoded. We prove the correctness of our approach and empirically show that the resulting minimally faithful inverses lead to better inference amortization than existing heuristic approaches.
An Introduction to Probabilistic Programming
Sep 27, 2018


This document is designed to be a first-year graduate-level introduction to probabilistic programming. It not only provides a thorough background for anyone wishing to use a probabilistic programming system, but also introduces the techniques needed to design and build these systems. It is aimed at people who have an undergraduate-level understanding of either or, ideally, both probabilistic machine learning and programming languages. We start with a discussion of model-based reasoning and explain why conditioning as a foundational computation is central to the fields of probabilistic machine learning and artificial intelligence. We then introduce a simple first-order probabilistic programming language (PPL) whose programs define static-computation-graph, finite-variable-cardinality models. In the context of this restricted PPL we introduce fundamental inference algorithms and describe how they can be implemented in the context of models denoted by probabilistic programs. In the second part of this document, we introduce a higher-order probabilistic programming language, with a functionality analogous to that of established programming languages. This affords the opportunity to define models with dynamic computation graphs, at the cost of requiring inference methods that generate samples by repeatedly executing the program. Foundational inference algorithms for this kind of probabilistic programming language are explained in the context of an interface between program executions and an inference controller. This document closes with a chapter on advanced topics which we believe to be, at the time of writing, interesting directions for probabilistic programming research; directions that point towards a tight integration with deep neural network research and the development of systems for next-generation artificial intelligence applications.