 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDistilling Optimal Neural Networks: Rapid Search in Diverse Spaces
Dec 16, 2020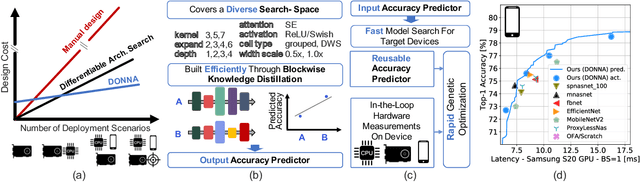



This work presents DONNA (Distilling Optimal Neural Network Architectures), a novel pipeline for rapid neural architecture search and search space exploration, targeting multiple different hardware platforms and user scenarios. In DONNA, a search consists of three phases. First, an accuracy predictor is built for a diverse search space using blockwise knowledge distillation. This predictor enables searching across diverse macro-architectural network parameters such as layer types, attention mechanisms, and channel widths, as well as across micro-architectural parameters such as block repeats, kernel sizes, and expansion rates. Second, a rapid evolutionary search phase finds a Pareto-optimal set of architectures in terms of accuracy and latency for any scenario using the predictor and on-device measurements. Third, Pareto-optimal models can be quickly finetuned to full accuracy. With this approach, DONNA finds architectures that outperform the state of the art. In ImageNet classification, architectures found by DONNA are 20% faster than EfficientNet-B0 and MobileNetV2 on a Nvidia V100 GPU at similar accuracy and 10% faster with 0.5% higher accuracy than MobileNetV2-1.4x on a Samsung S20 smartphone. In addition to neural architecture search, DONNA is used for search-space exploration and hardware-aware model compression.
NeuNetS: An Automated Synthesis Engine for Neural Network Design
Jan 17, 2019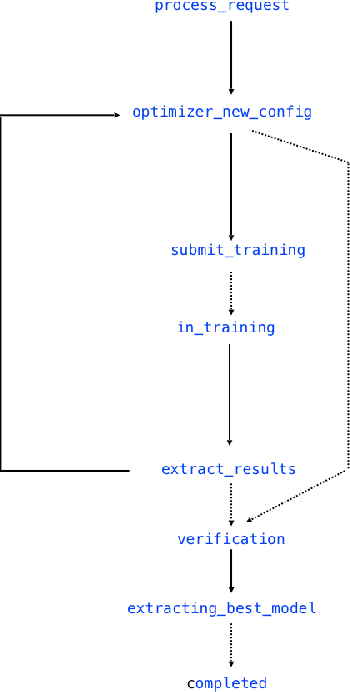
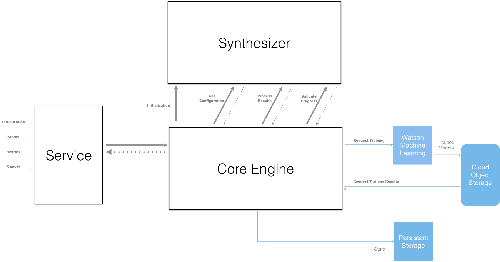
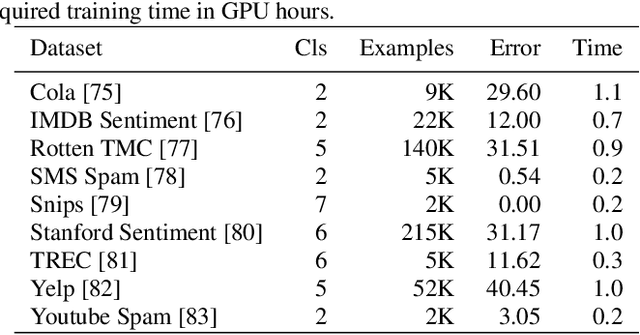
Application of neural networks to a vast variety of practical applications is transforming the way AI is applied in practice. Pre-trained neural network models available through APIs or capability to custom train pre-built neural network architectures with customer data has made the consumption of AI by developers much simpler and resulted in broad adoption of these complex AI models. While prebuilt network models exist for certain scenarios, to try and meet the constraints that are unique to each application, AI teams need to think about developing custom neural network architectures that can meet the tradeoff between accuracy and memory footprint to achieve the tight constraints of their unique use-cases. However, only a small proportion of data science teams have the skills and experience needed to create a neural network from scratch, and the demand far exceeds the supply. In this paper, we present NeuNetS : An automated Neural Network Synthesis engine for custom neural network design that is available as part of IBM's AI OpenScale's product. NeuNetS is available for both Text and Image domains and can build neural networks for specific tasks in a fraction of the time it takes today with human effort, and with accuracy similar to that of human-designed AI models.
BAGAN: Data Augmentation with Balancing GAN
Jun 05, 2018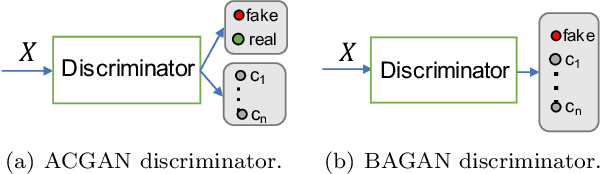
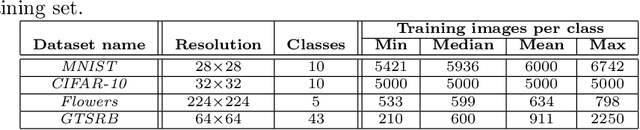

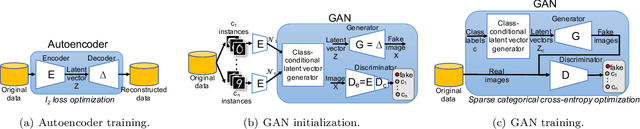
Image classification datasets are often imbalanced, characteristic that negatively affects the accuracy of deep-learning classifiers. In this work we propose balancing GAN (BAGAN) as an augmentation tool to restore balance in imbalanced datasets. This is challenging because the few minority-class images may not be enough to train a GAN. We overcome this issue by including during the adversarial training all available images of majority and minority classes. The generative model learns useful features from majority classes and uses these to generate images for minority classes. We apply class conditioning in the latent space to drive the generation process towards a target class. The generator in the GAN is initialized with the encoder module of an autoencoder that enables us to learn an accurate class-conditioning in the latent space. We compare the proposed methodology with state-of-the-art GANs and demonstrate that BAGAN generates images of superior quality when trained with an imbalanced dataset.
Efficient Image Dataset Classification Difficulty Estimation for Predicting Deep-Learning Accuracy
Mar 26, 2018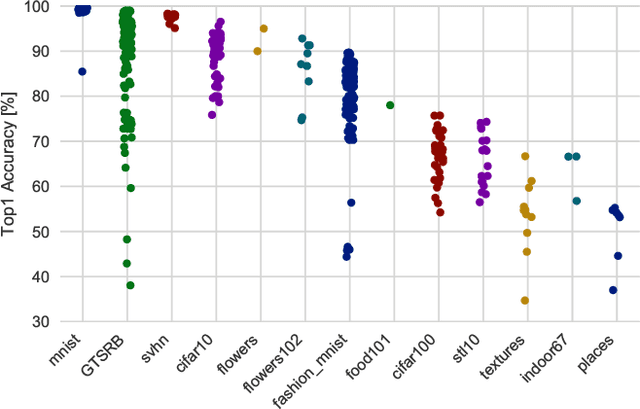
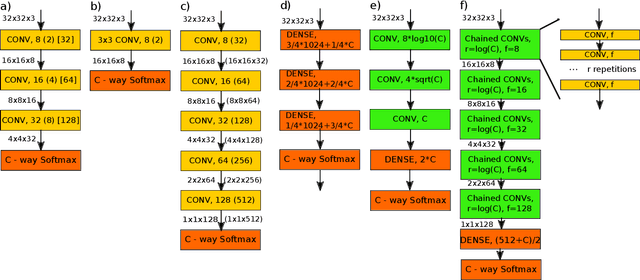
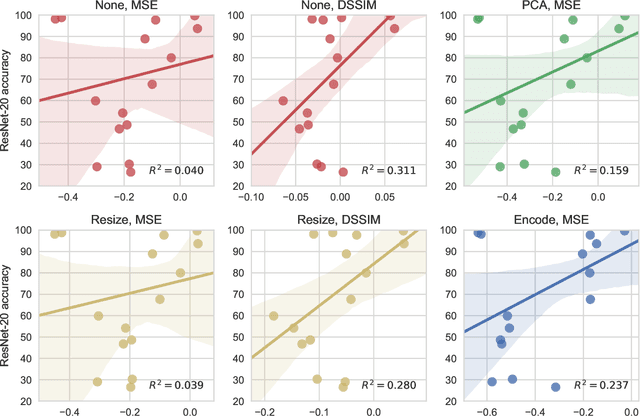
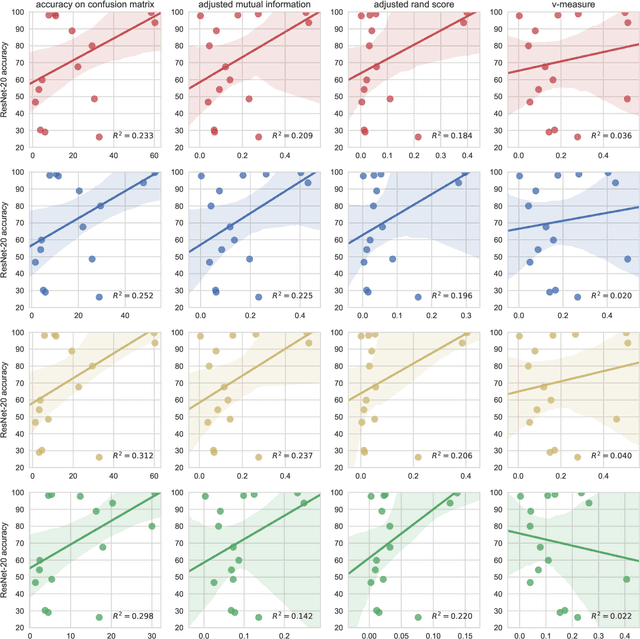
In the deep-learning community new algorithms are published at an incredible pace. Therefore, solving an image classification problem for new datasets becomes a challenging task, as it requires to re-evaluate published algorithms and their different configurations in order to find a close to optimal classifier. To facilitate this process, before biasing our decision towards a class of neural networks or running an expensive search over the network space, we propose to estimate the classification difficulty of the dataset. Our method computes a single number that characterizes the dataset difficulty 27x faster than training state-of-the-art networks. The proposed method can be used in combination with network topology and hyper-parameter search optimizers to efficiently drive the search towards promising neural-network configurations.