 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVP Lab: a PEFT-Enabled Visual Prompting Laboratory for Semantic Segmentation
May 21, 2025Large-scale pretrained vision backbones have transformed computer vision by providing powerful feature extractors that enable various downstream tasks, including training-free approaches like visual prompting for semantic segmentation. Despite their success in generic scenarios, these models often fall short when applied to specialized technical domains where the visual features differ significantly from their training distribution. To bridge this gap, we introduce VP Lab, a comprehensive iterative framework that enhances visual prompting for robust segmentation model development. At the core of VP Lab lies E-PEFT, a novel ensemble of parameter-efficient fine-tuning techniques specifically designed to adapt our visual prompting pipeline to specific domains in a manner that is both parameter- and data-efficient. Our approach not only surpasses the state-of-the-art in parameter-efficient fine-tuning for the Segment Anything Model (SAM), but also facilitates an interactive, near-real-time loop, allowing users to observe progressively improving results as they experiment within the framework. By integrating E-PEFT with visual prompting, we demonstrate a remarkable 50\% increase in semantic segmentation mIoU performance across various technical datasets using only 5 validated images, establishing a new paradigm for fast, efficient, and interactive model deployment in new, challenging domains. This work comes in the form of a demonstration.
Position-based Content Attention for Time Series Forecasting with Sequence-to-sequence RNNs
Aug 21, 2017
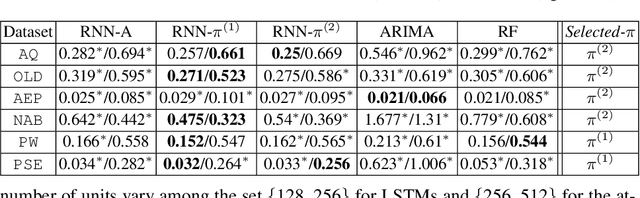
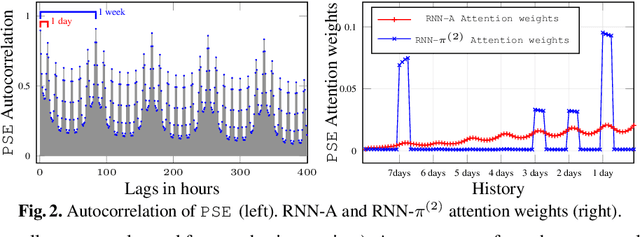
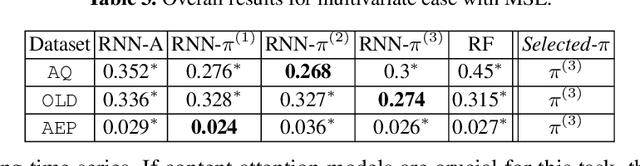
We propose here an extended attention model for sequence-to-sequence recurrent neural networks (RNNs) designed to capture (pseudo-)periods in time series. This extended attention model can be deployed on top of any RNN and is shown to yield state-of-the-art performance for time series forecasting on several univariate and multivariate time series.