 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeError-aware Quantization through Noise Tempering
Dec 11, 2022



Quantization has become a predominant approach for model compression, enabling deployment of large models trained on GPUs onto smaller form-factor devices for inference. Quantization-aware training (QAT) optimizes model parameters with respect to the end task while simulating quantization error, leading to better performance than post-training quantization. Approximation of gradients through the non-differentiable quantization operator is typically achieved using the straight-through estimator (STE) or additive noise. However, STE-based methods suffer from instability due to biased gradients, whereas existing noise-based methods cannot reduce the resulting variance. In this work, we incorporate exponentially decaying quantization-error-aware noise together with a learnable scale of task loss gradient to approximate the effect of a quantization operator. We show this method combines gradient scale and quantization noise in a better optimized way, providing finer-grained estimation of gradients at each weight and activation layer's quantizer bin size. Our controlled noise also contains an implicit curvature term that could encourage flatter minima, which we show is indeed the case in our experiments. Experiments training ResNet architectures on the CIFAR-10, CIFAR-100 and ImageNet benchmarks show that our method obtains state-of-the-art top-1 classification accuracy for uniform (non mixed-precision) quantization, out-performing previous methods by 0.5-1.2% absolute.
Normalized Contrastive Learning for Text-Video Retrieval
Nov 30, 2022



Cross-modal contrastive learning has led the recent advances in multimodal retrieval with its simplicity and effectiveness. In this work, however, we reveal that cross-modal contrastive learning suffers from incorrect normalization of the sum retrieval probabilities of each text or video instance. Specifically, we show that many test instances are either over- or under-represented during retrieval, significantly hurting the retrieval performance. To address this problem, we propose Normalized Contrastive Learning (NCL) which utilizes the Sinkhorn-Knopp algorithm to compute the instance-wise biases that properly normalize the sum retrieval probabilities of each instance so that every text and video instance is fairly represented during cross-modal retrieval. Empirical study shows that NCL brings consistent and significant gains in text-video retrieval on different model architectures, with new state-of-the-art multimodal retrieval metrics on the ActivityNet, MSVD, and MSR-VTT datasets without any architecture engineering.
Token-level Sequence Labeling for Spoken Language Understanding using Compositional End-to-End Models
Oct 27, 2022End-to-end spoken language understanding (SLU) systems are gaining popularity over cascaded approaches due to their simplicity and ability to avoid error propagation. However, these systems model sequence labeling as a sequence prediction task causing a divergence from its well-established token-level tagging formulation. We build compositional end-to-end SLU systems that explicitly separate the added complexity of recognizing spoken mentions in SLU from the NLU task of sequence labeling. By relying on intermediate decoders trained for ASR, our end-to-end systems transform the input modality from speech to token-level representations that can be used in the traditional sequence labeling framework. This composition of ASR and NLU formulations in our end-to-end SLU system offers direct compatibility with pre-trained ASR and NLU systems, allows performance monitoring of individual components and enables the use of globally normalized losses like CRF, making them attractive in practical scenarios. Our models outperform both cascaded and direct end-to-end models on a labeling task of named entity recognition across SLU benchmarks.
SQuAT: Sharpness- and Quantization-Aware Training for BERT
Oct 13, 2022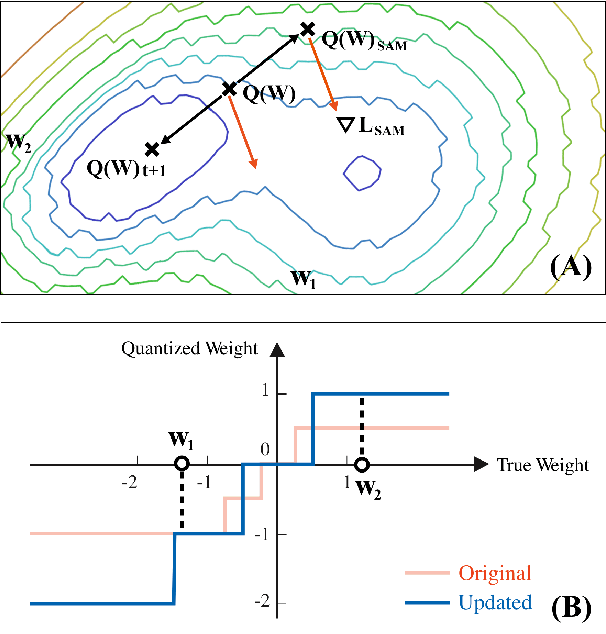
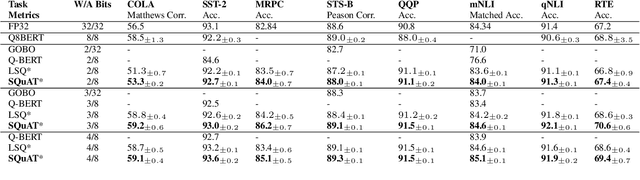
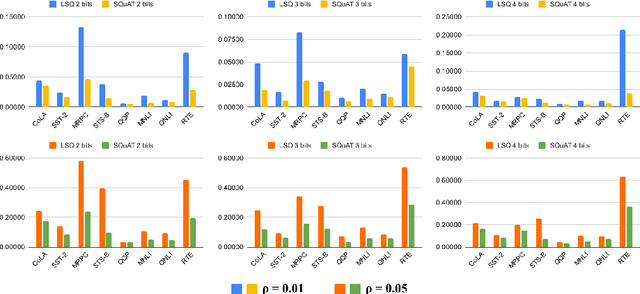
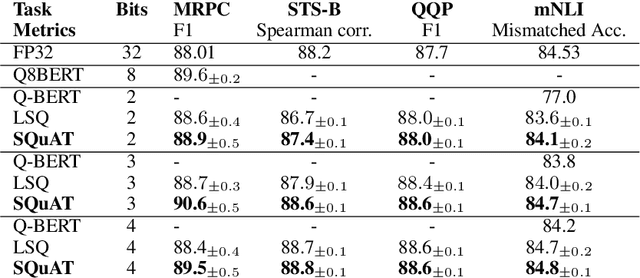
Quantization is an effective technique to reduce memory footprint, inference latency, and power consumption of deep learning models. However, existing quantization methods suffer from accuracy degradation compared to full-precision (FP) models due to the errors introduced by coarse gradient estimation through non-differentiable quantization layers. The existence of sharp local minima in the loss landscapes of overparameterized models (e.g., Transformers) tends to aggravate such performance penalty in low-bit (2, 4 bits) settings. In this work, we propose sharpness- and quantization-aware training (SQuAT), which would encourage the model to converge to flatter minima while performing quantization-aware training. Our proposed method alternates training between sharpness objective and step-size objective, which could potentially let the model learn the most suitable parameter update magnitude to reach convergence near-flat minima. Extensive experiments show that our method can consistently outperform state-of-the-art quantized BERT models under 2, 3, and 4-bit settings on GLUE benchmarks by 1%, and can sometimes even outperform full precision (32-bit) models. Our experiments on empirical measurement of sharpness also suggest that our method would lead to flatter minima compared to other quantization methods.
CTC Alignments Improve Autoregressive Translation
Oct 11, 2022
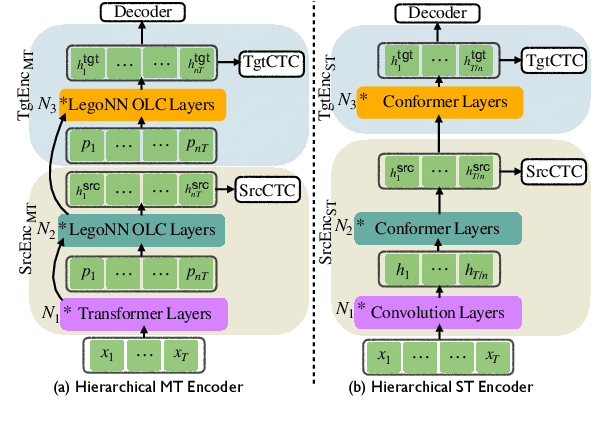

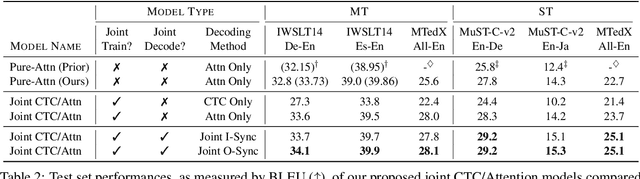
Connectionist Temporal Classification (CTC) is a widely used approach for automatic speech recognition (ASR) that performs conditionally independent monotonic alignment. However for translation, CTC exhibits clear limitations due to the contextual and non-monotonic nature of the task and thus lags behind attentional decoder approaches in terms of translation quality. In this work, we argue that CTC does in fact make sense for translation if applied in a joint CTC/attention framework wherein CTC's core properties can counteract several key weaknesses of pure-attention models during training and decoding. To validate this conjecture, we modify the Hybrid CTC/Attention model originally proposed for ASR to support text-to-text translation (MT) and speech-to-text translation (ST). Our proposed joint CTC/attention models outperform pure-attention baselines across six benchmark translation tasks.
ASR2K: Speech Recognition for Around 2000 Languages without Audio
Sep 06, 2022
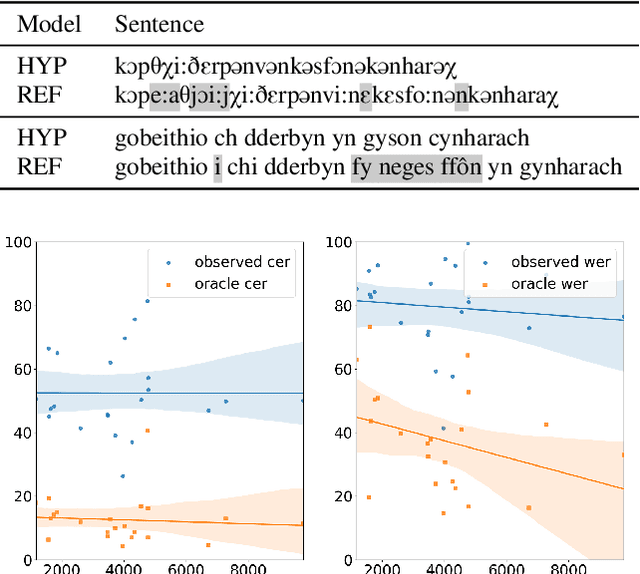
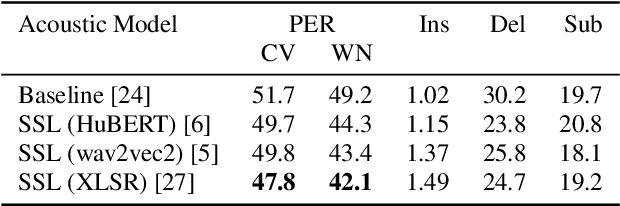
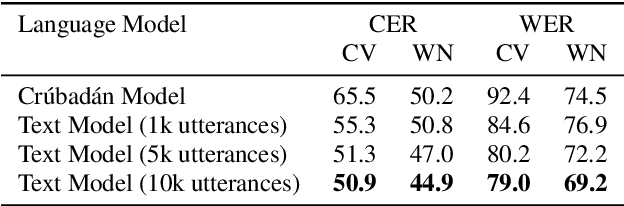
Most recent speech recognition models rely on large supervised datasets, which are unavailable for many low-resource languages. In this work, we present a speech recognition pipeline that does not require any audio for the target language. The only assumption is that we have access to raw text datasets or a set of n-gram statistics. Our speech pipeline consists of three components: acoustic, pronunciation, and language models. Unlike the standard pipeline, our acoustic and pronunciation models use multilingual models without any supervision. The language model is built using n-gram statistics or the raw text dataset. We build speech recognition for 1909 languages by combining it with Crubadan: a large endangered languages n-gram database. Furthermore, we test our approach on 129 languages across two datasets: Common Voice and CMU Wilderness dataset. We achieve 50% CER and 74% WER on the Wilderness dataset with Crubadan statistics only and improve them to 45% CER and 69% WER when using 10000 raw text utterances.
Masked Autoencoders that Listen
Jul 13, 2022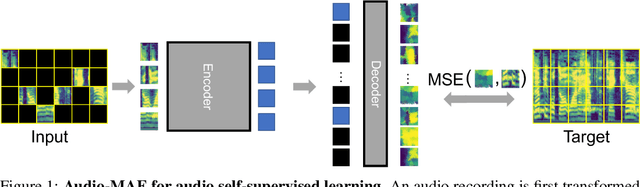
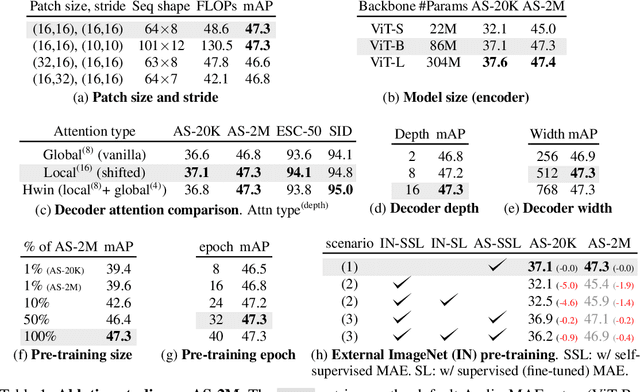

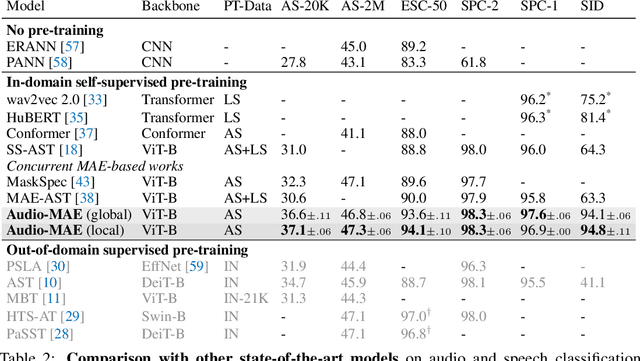
This paper studies a simple extension of image-based Masked Autoencoders (MAE) to self-supervised representation learning from audio spectrograms. Following the Transformer encoder-decoder design in MAE, our Audio-MAE first encodes audio spectrogram patches with a high masking ratio, feeding only the non-masked tokens through encoder layers. The decoder then re-orders and decodes the encoded context padded with mask tokens, in order to reconstruct the input spectrogram. We find it beneficial to incorporate local window attention in the decoder, as audio spectrograms are highly correlated in local time and frequency bands. We then fine-tune the encoder with a lower masking ratio on target datasets. Empirically, Audio-MAE sets new state-of-the-art performance on six audio and speech classification tasks, outperforming other recent models that use external supervised pre-training. The code and models will be at https://github.com/facebookresearch/AudioMAE.
LegoNN: Building Modular Encoder-Decoder Models
Jun 07, 2022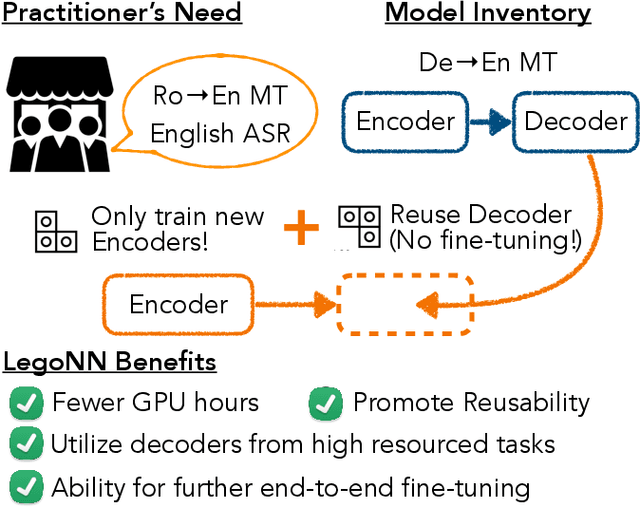
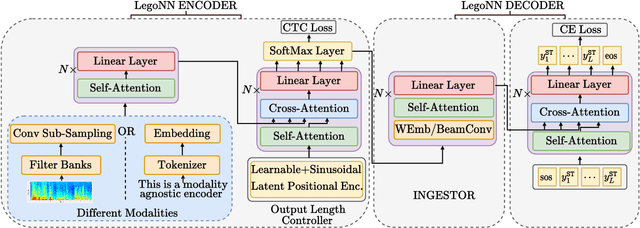
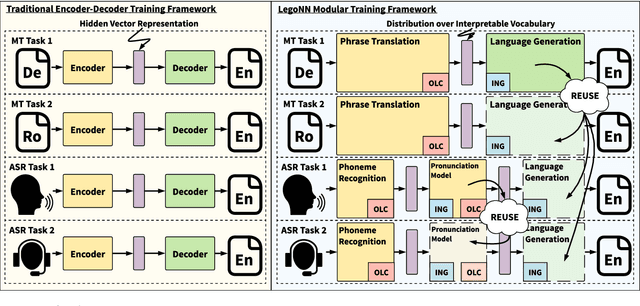
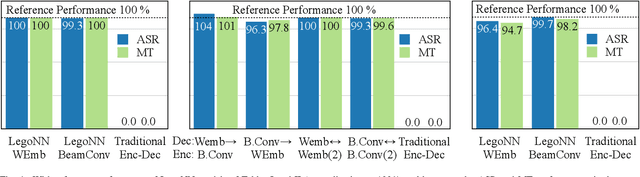
State-of-the-art encoder-decoder models (e.g. for machine translation (MT) or speech recognition (ASR)) are constructed and trained end-to-end as an atomic unit. No component of the model can be (re-)used without the others. We describe LegoNN, a procedure for building encoder-decoder architectures with decoder modules that can be reused across various MT and ASR tasks, without the need for any fine-tuning. To achieve reusability, the interface between each encoder and decoder modules is grounded to a sequence of marginal distributions over a discrete vocabulary pre-defined by the model designer. We present two approaches for ingesting these marginals; one is differentiable, allowing the flow of gradients across the entire network, and the other is gradient-isolating. To enable portability of decoder modules between MT tasks for different source languages and across other tasks like ASR, we introduce a modality agnostic encoder which consists of a length control mechanism to dynamically adapt encoders' output lengths in order to match the expected input length range of pre-trained decoders. We present several experiments to demonstrate the effectiveness of LegoNN models: a trained language generation LegoNN decoder module from German-English (De-En) MT task can be reused with no fine-tuning for the Europarl English ASR and the Romanian-English (Ro-En) MT tasks to match or beat respective baseline models. When fine-tuned towards the target task for few thousand updates, our LegoNN models improved the Ro-En MT task by 1.5 BLEU points, and achieved 12.5% relative WER reduction for the Europarl ASR task. Furthermore, to show its extensibility, we compose a LegoNN ASR model from three modules -- each has been learned within different end-to-end trained models on three different datasets -- boosting the WER reduction to 19.5%.
On Advances in Text Generation from Images Beyond Captioning: A Case Study in Self-Rationalization
May 24, 2022


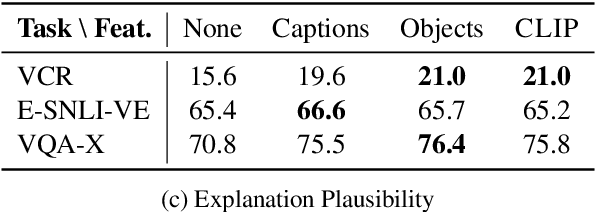
Integrating vision and language has gained notable attention following the success of pretrained language models. Despite that, a fraction of emerging multimodal models is suitable for text generation conditioned on images. This minority is typically developed and evaluated for image captioning, a text generation task conditioned solely on images with the goal to describe what is explicitly visible in an image. In this paper, we take a step back and ask: How do these models work for more complex generative tasks, conditioned on both text and images? Are models based on joint multimodal pretraining, visually adapted pretrained language models, or models that combine these two approaches, more promising for such tasks? We address these questions in the context of self-rationalization (jointly generating task labels/answers and free-text explanations) of three tasks: (i) visual question answering in VQA-X, (ii) visual commonsense reasoning in VCR, and (iii) visual-textual entailment in E-SNLI-VE. We show that recent advances in each modality, CLIP image representations and scaling of language models, do not consistently improve multimodal self-rationalization of tasks with multimodal inputs. We also observe that no model type works universally the best across tasks/datasets and finetuning data sizes. Our findings call for a backbone modelling approach that can be built on to advance text generation from images and text beyond image captioning.
Robustness of Neural Architectures for Audio Event Detection
May 06, 2022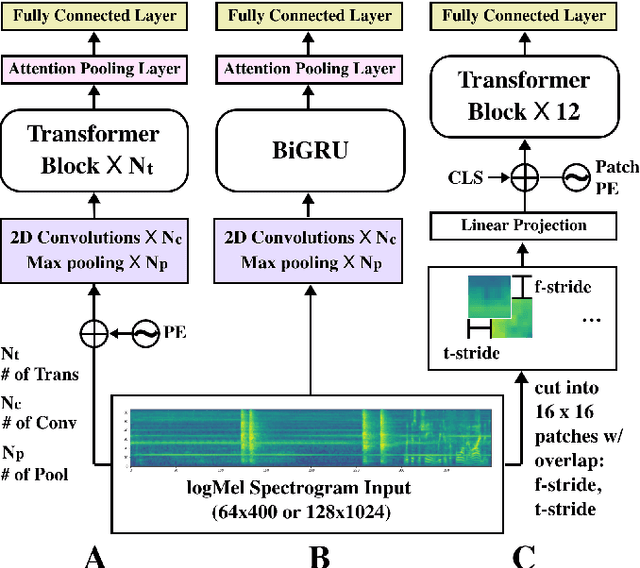
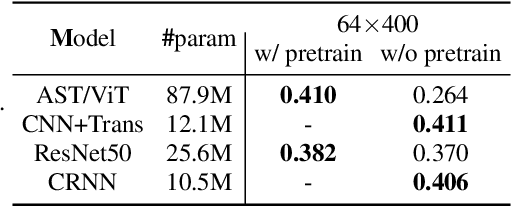
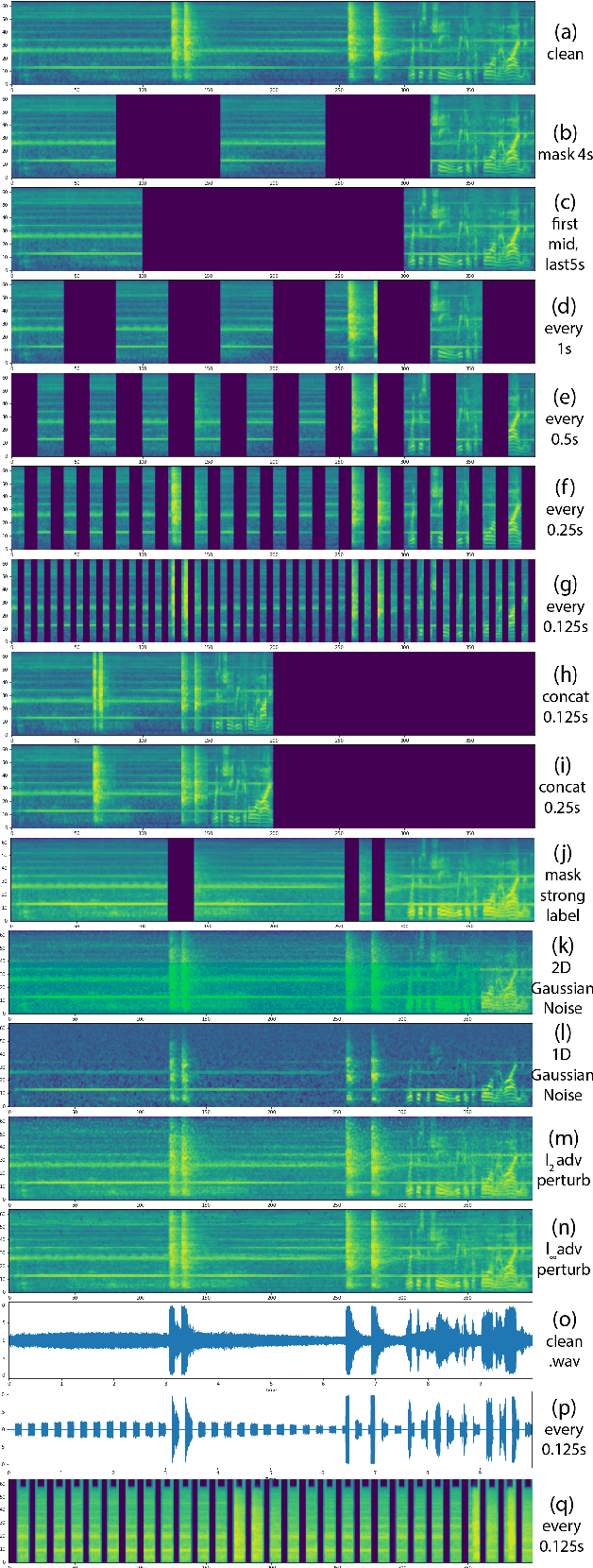
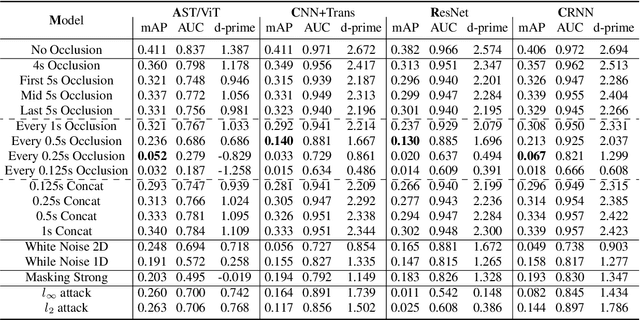
Traditionally, in Audio Recognition pipeline, noise is suppressed by the "frontend", relying on preprocessing techniques such as speech enhancement. However, it is not guaranteed that noise will not cascade into downstream pipelines. To understand the actual influence of noise on the entire audio pipeline, in this paper, we directly investigate the impact of noise on a different types of neural models without the preprocessing step. We measure the recognition performances of 4 different neural network models on the task of environment sound classification under the 3 types of noises: \emph{occlusion} (to emulate intermittent noise), \emph{Gaussian} noise (models continuous noise), and \emph{adversarial perturbations} (worst case scenario). Our intuition is that the different ways in which these models process their input (i.e. CNNs have strong locality inductive biases, which Transformers do not have) should lead to observable differences in performance and/ or robustness, an understanding of which will enable further improvements. We perform extensive experiments on AudioSet which is the largest weakly-labeled sound event dataset available. We also seek to explain the behaviors of different models through output distribution change and weight visualization.