 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePOET: Prompt Offset Tuning for Continual Human Action Adaptation
Apr 25, 2025As extended reality (XR) is redefining how users interact with computing devices, research in human action recognition is gaining prominence. Typically, models deployed on immersive computing devices are static and limited to their default set of classes. The goal of our research is to provide users and developers with the capability to personalize their experience by adding new action classes to their device models continually. Importantly, a user should be able to add new classes in a low-shot and efficient manner, while this process should not require storing or replaying any of user's sensitive training data. We formalize this problem as privacy-aware few-shot continual action recognition. Towards this end, we propose POET: Prompt-Offset Tuning. While existing prompt tuning approaches have shown great promise for continual learning of image, text, and video modalities; they demand access to extensively pretrained transformers. Breaking away from this assumption, POET demonstrates the efficacy of prompt tuning a significantly lightweight backbone, pretrained exclusively on the base class data. We propose a novel spatio-temporal learnable prompt offset tuning approach, and are the first to apply such prompt tuning to Graph Neural Networks. We contribute two new benchmarks for our new problem setting in human action recognition: (i) NTU RGB+D dataset for activity recognition, and (ii) SHREC-2017 dataset for hand gesture recognition. We find that POET consistently outperforms comprehensive benchmarks. Source code at https://github.com/humansensinglab/POET-continual-action-recognition.
* ECCV 2024 (Oral), webpage https://humansensinglab.github.io/POET-continual-action-recognition/
Taming 3DGS: High-Quality Radiance Fields with Limited Resources
Jun 21, 2024



3D Gaussian Splatting (3DGS) has transformed novel-view synthesis with its fast, interpretable, and high-fidelity rendering. However, its resource requirements limit its usability. Especially on constrained devices, training performance degrades quickly and often cannot complete due to excessive memory consumption of the model. The method converges with an indefinite number of Gaussians -- many of them redundant -- making rendering unnecessarily slow and preventing its usage in downstream tasks that expect fixed-size inputs. To address these issues, we tackle the challenges of training and rendering 3DGS models on a budget. We use a guided, purely constructive densification process that steers densification toward Gaussians that raise the reconstruction quality. Model size continuously increases in a controlled manner towards an exact budget, using score-based densification of Gaussians with training-time priors that measure their contribution. We further address training speed obstacles: following a careful analysis of 3DGS' original pipeline, we derive faster, numerically equivalent solutions for gradient computation and attribute updates, including an alternative parallelization for efficient backpropagation. We also propose quality-preserving approximations where suitable to reduce training time even further. Taken together, these enhancements yield a robust, scalable solution with reduced training times, lower compute and memory requirements, and high quality. Our evaluation shows that in a budgeted setting, we obtain competitive quality metrics with 3DGS while achieving a 4--5x reduction in both model size and training time. With more generous budgets, our measured quality surpasses theirs. These advances open the door for novel-view synthesis in constrained environments, e.g., mobile devices.
Pixel Codec Avatars
Apr 09, 2021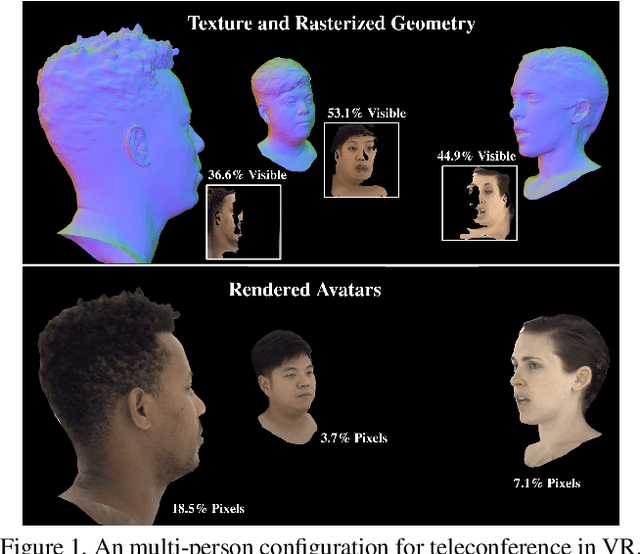
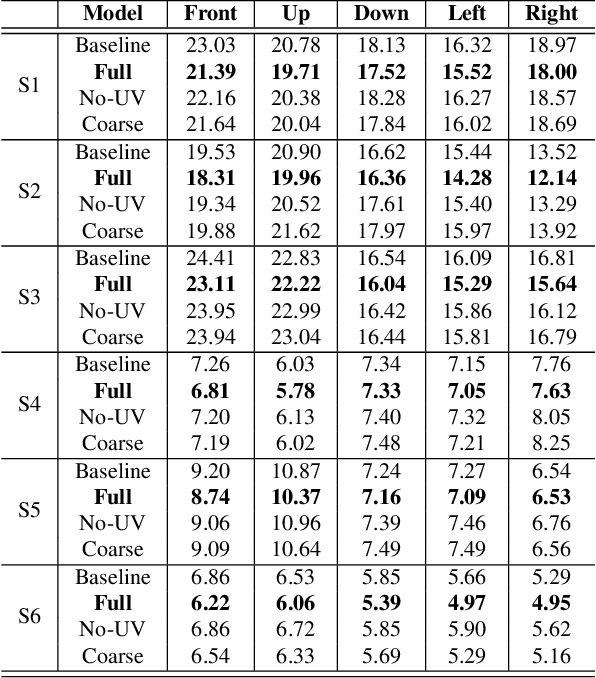
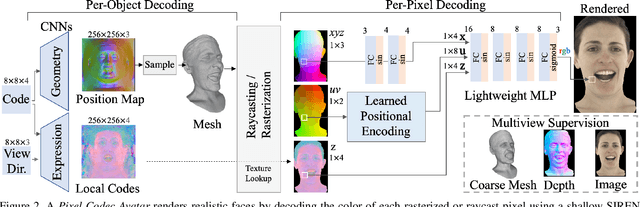
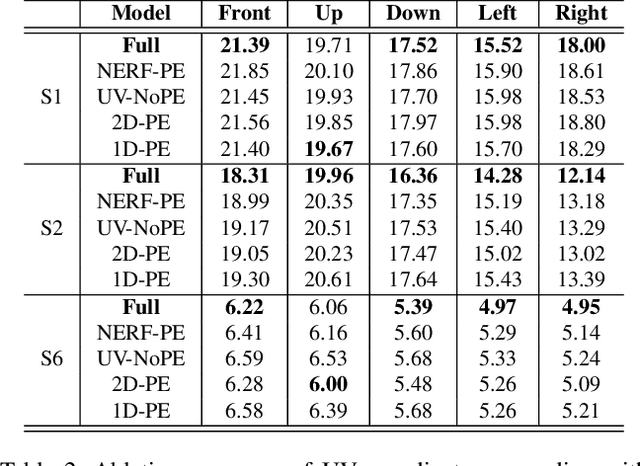
Telecommunication with photorealistic avatars in virtual or augmented reality is a promising path for achieving authentic face-to-face communication in 3D over remote physical distances. In this work, we present the Pixel Codec Avatars (PiCA): a deep generative model of 3D human faces that achieves state of the art reconstruction performance while being computationally efficient and adaptive to the rendering conditions during execution. Our model combines two core ideas: (1) a fully convolutional architecture for decoding spatially varying features, and (2) a rendering-adaptive per-pixel decoder. Both techniques are integrated via a dense surface representation that is learned in a weakly-supervised manner from low-topology mesh tracking over training images. We demonstrate that PiCA improves reconstruction over existing techniques across testing expressions and views on persons of different gender and skin tone. Importantly, we show that the PiCA model is much smaller than the state-of-art baseline model, and makes multi-person telecommunicaiton possible: on a single Oculus Quest 2 mobile VR headset, 5 avatars are rendered in realtime in the same scene.
High-Resolution Deep Convolutional Generative Adversarial Networks
Jun 10, 2018

Generative Adversarial Networks (GANs) convergence in a high-resolution setting with a computational constrain of GPU memory capacity (from 12GB to 24 GB) has been beset with difficulty due to the known lack of convergence rate stability. In order to boost network convergence of DCGAN (Deep Convolutional Generative Adversarial Networks) and achieve good-looking high-resolution results we propose a new layered network structure, HDCGAN, that incorporates current state-of-the-art techniques for this effect. A novel dataset, Curt\'o & Zarza, containing human faces from different ethnical groups in a wide variety of illumination conditions and image resolutions is introduced. Curt\'o is enhanced with HDCGAN synthetic images, thus being the first GAN augmented face dataset. We conduct extensive experiments on CelebA (MS-SSIM 0.1978 and Distance of Fr\'echet 8.77) and Curt\'o.
McKernel: A Library for Approximate Kernel Expansions in Log-linear Time
Jun 10, 2018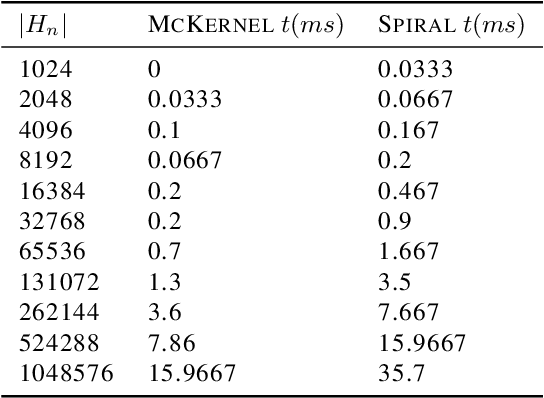
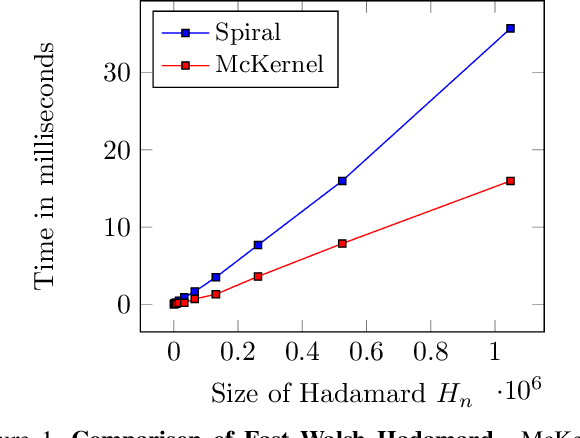
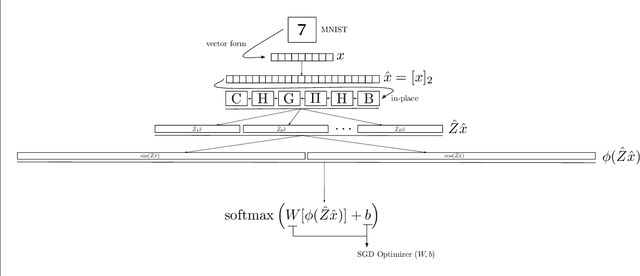
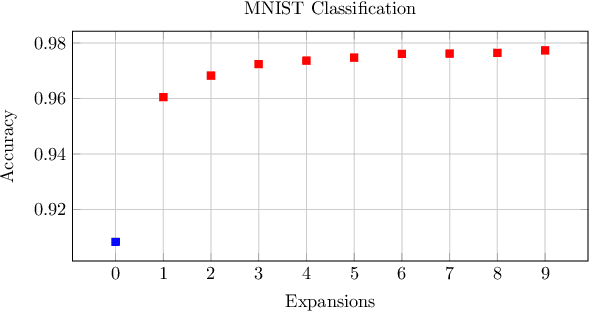
Kernel Methods Next Generation (KMNG) introduces a framework to use kernel approximates in the mini-batch setting with SGD Optimizer as an alternative to Deep Learning. McKernel is a C++ library for KMNG ML Large-scale. It contains a CPU optimized implementation of the Fastfood algorithm that allows the computation of approximated kernel expansions in log-linear time. The algorithm requires to compute the product of Walsh Hadamard Transform (WHT) matrices. A cache friendly SIMD Fast Walsh Hadamard Transform (FWHT) that achieves compelling speed and outperforms current state-of-the-art methods has been developed. McKernel allows to obtain non-linear classification combining Fastfood and a linear classifier.
Robust end-to-end deep audiovisual speech recognition
Nov 21, 2016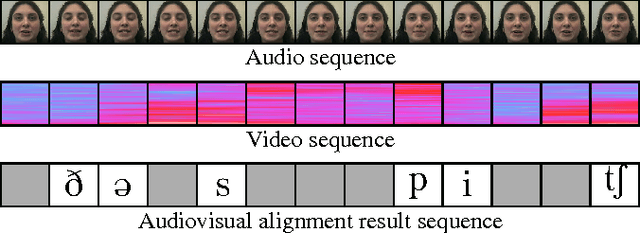
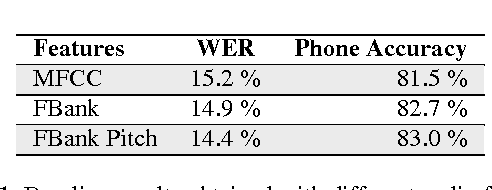
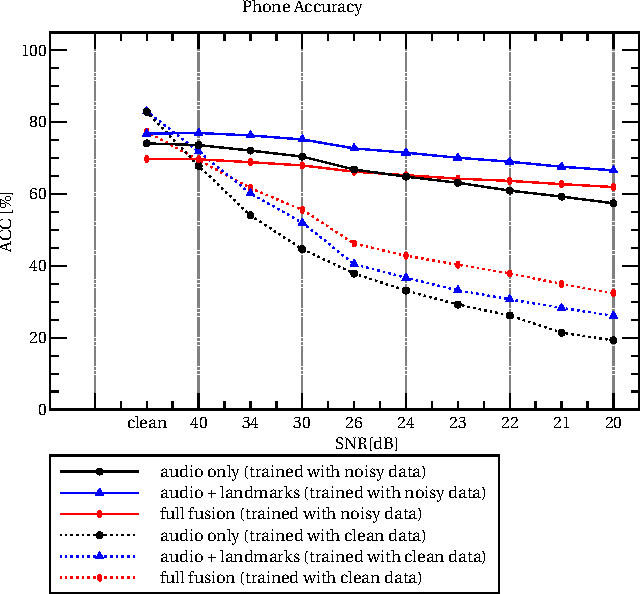

Speech is one of the most effective ways of communication among humans. Even though audio is the most common way of transmitting speech, very important information can be found in other modalities, such as vision. Vision is particularly useful when the acoustic signal is corrupted. Multi-modal speech recognition however has not yet found wide-spread use, mostly because the temporal alignment and fusion of the different information sources is challenging. This paper presents an end-to-end audiovisual speech recognizer (AVSR), based on recurrent neural networks (RNN) with a connectionist temporal classification (CTC) loss function. CTC creates sparse "peaky" output activations, and we analyze the differences in the alignments of output targets (phonemes or visemes) between audio-only, video-only, and audio-visual feature representations. We present the first such experiments on the large vocabulary IBM ViaVoice database, which outperform previously published approaches on phone accuracy in clean and noisy conditions.