 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSAUCE: Selective Concept Unlearning in Vision-Language Models with Sparse Autoencoders
Mar 20, 2025



Unlearning methods for vision-language models (VLMs) have primarily adapted techniques from large language models (LLMs), relying on weight updates that demand extensive annotated forget sets. Moreover, these methods perform unlearning at a coarse granularity, often leading to excessive forgetting and reduced model utility. To address this issue, we introduce SAUCE, a novel method that leverages sparse autoencoders (SAEs) for fine-grained and selective concept unlearning in VLMs. Briefly, SAUCE first trains SAEs to capture high-dimensional, semantically rich sparse features. It then identifies the features most relevant to the target concept for unlearning. During inference, it selectively modifies these features to suppress specific concepts while preserving unrelated information. We evaluate SAUCE on two distinct VLMs, LLaVA-v1.5-7B and LLaMA-3.2-11B-Vision-Instruct, across two types of tasks: concrete concept unlearning (objects and sports scenes) and abstract concept unlearning (emotions, colors, and materials), encompassing a total of 60 concepts. Extensive experiments demonstrate that SAUCE outperforms state-of-the-art methods by 18.04% in unlearning quality while maintaining comparable model utility. Furthermore, we investigate SAUCE's robustness against widely used adversarial attacks, its transferability across models, and its scalability in handling multiple simultaneous unlearning requests. Our findings establish SAUCE as an effective and scalable solution for selective concept unlearning in VLMs.
$\textit{GeoHard}$: Towards Measuring Class-wise Hardness through Modelling Class Semantics
Jul 17, 2024



Recent advances in measuring hardness-wise properties of data guide language models in sample selection within low-resource scenarios. However, class-specific properties are overlooked for task setup and learning. How will these properties influence model learning and is it generalizable across datasets? To answer this question, this work formally initiates the concept of $\textit{class-wise hardness}$. Experiments across eight natural language understanding (NLU) datasets demonstrate a consistent hardness distribution across learning paradigms, models, and human judgment. Subsequent experiments unveil a notable challenge in measuring such class-wise hardness with instance-level metrics in previous works. To address this, we propose $\textit{GeoHard}$ for class-wise hardness measurement by modeling class geometry in the semantic embedding space. $\textit{GeoHard}$ surpasses instance-level metrics by over 59 percent on $\textit{Pearson}$'s correlation on measuring class-wise hardness. Our analysis theoretically and empirically underscores the generality of $\textit{GeoHard}$ as a fresh perspective on data diagnosis. Additionally, we showcase how understanding class-wise hardness can practically aid in improving task learning.
$\texttt{MixGR}$: Enhancing Retriever Generalization for Scientific Domain through Complementary Granularity
Jul 15, 2024



Recent studies show the growing significance of document retrieval in the generation of LLMs, i.e., RAG, within the scientific domain by bridging their knowledge gap. However, dense retrievers often struggle with domain-specific retrieval and complex query-document relationships, particularly when query segments correspond to various parts of a document. To alleviate such prevalent challenges, this paper introduces $\texttt{MixGR}$, which improves dense retrievers' awareness of query-document matching across various levels of granularity in queries and documents using a zero-shot approach. $\texttt{MixGR}$ fuses various metrics based on these granularities to a united score that reflects a comprehensive query-document similarity. Our experiments demonstrate that $\texttt{MixGR}$ outperforms previous document retrieval by 24.7% and 9.8% on nDCG@5 with unsupervised and supervised retrievers, respectively, averaged on queries containing multiple subqueries from five scientific retrieval datasets. Moreover, the efficacy of two downstream scientific question-answering tasks highlights the advantage of $\texttt{MixGR}$to boost the application of LLMs in the scientific domain.
Finetuning Large Language Model for Personalized Ranking
May 25, 2024Large Language Models (LLMs) have demonstrated remarkable performance across various domains, motivating researchers to investigate their potential use in recommendation systems. However, directly applying LLMs to recommendation tasks has proven challenging due to the significant disparity between the data used for pre-training LLMs and the specific requirements of recommendation tasks. In this study, we introduce Direct Multi-Preference Optimization (DMPO), a streamlined framework designed to bridge the gap and enhance the alignment of LLMs for recommendation tasks. DMPO enhances the performance of LLM-based recommenders by simultaneously maximizing the probability of positive samples and minimizing the probability of multiple negative samples. We conducted experimental evaluations to compare DMPO against traditional recommendation methods and other LLM-based recommendation approaches. The results demonstrate that DMPO significantly improves the recommendation capabilities of LLMs across three real-world public datasets in few-shot scenarios. Additionally, the experiments indicate that DMPO exhibits superior generalization ability in cross-domain recommendations. A case study elucidates the reasons behind these consistent improvements and also underscores DMPO's potential as an explainable recommendation system.
A Survey of Language Model Confidence Estimation and Calibration
Nov 14, 2023



Language models (LMs) have demonstrated remarkable capabilities across a wide range of tasks in various domains. Despite their impressive performance, the reliability of their output is concerning and questionable regarding the demand for AI safety. Assessing the confidence of LM predictions and calibrating them across different tasks with the aim to align LM confidence with accuracy can help mitigate risks and enable LMs to make better decisions. There have been various works in this respect, but there has been no comprehensive overview of this important research area. The present survey aims to bridge this gap. In particular, we discuss methods and techniques for LM confidence estimation and calibration, encompassing different LMs and various tasks. We further outline the challenges of estimating the confidence for large language models and we suggest some promising directions for future work.
Self-training Improves Pre-training for Few-shot Learning in Task-oriented Dialog Systems
Aug 28, 2021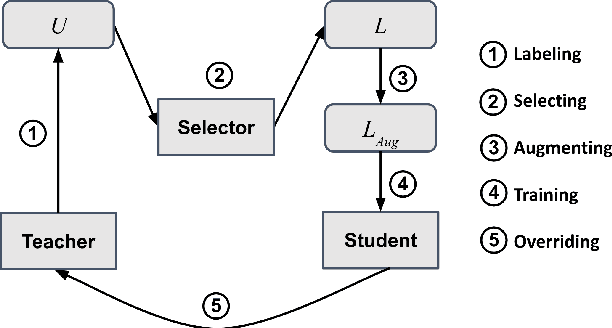
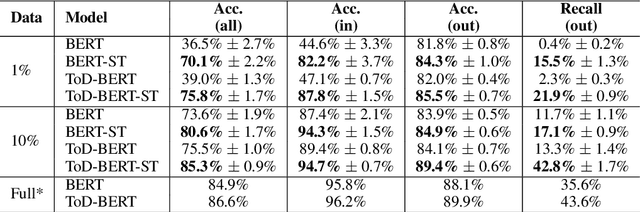
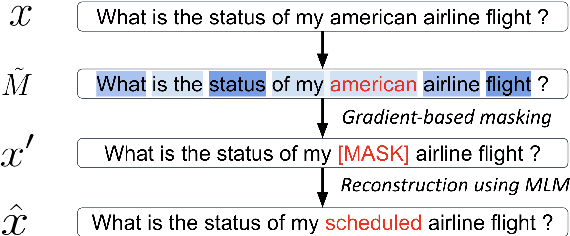
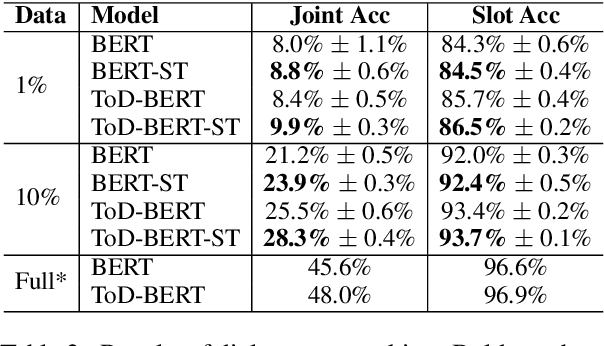
As the labeling cost for different modules in task-oriented dialog (ToD) systems is expensive, a major challenge is to train different modules with the least amount of labeled data. Recently, large-scale pre-trained language models, have shown promising results for few-shot learning in ToD. In this paper, we devise a self-training approach to utilize the abundant unlabeled dialog data to further improve state-of-the-art pre-trained models in few-shot learning scenarios for ToD systems. Specifically, we propose a self-training approach that iteratively labels the most confident unlabeled data to train a stronger Student model. Moreover, a new text augmentation technique (GradAug) is proposed to better train the Student by replacing non-crucial tokens using a masked language model. We conduct extensive experiments and present analyses on four downstream tasks in ToD, including intent classification, dialog state tracking, dialog act prediction, and response selection. Empirical results demonstrate that the proposed self-training approach consistently improves state-of-the-art pre-trained models (BERT, ToD-BERT) when only a small number of labeled data are available.
SLIM: Explicit Slot-Intent Mapping with BERT for Joint Multi-Intent Detection and Slot Filling
Aug 26, 2021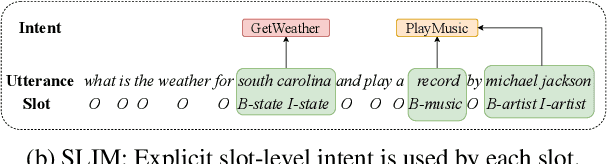
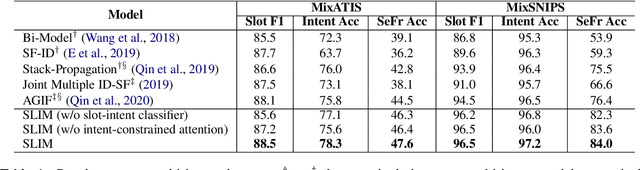
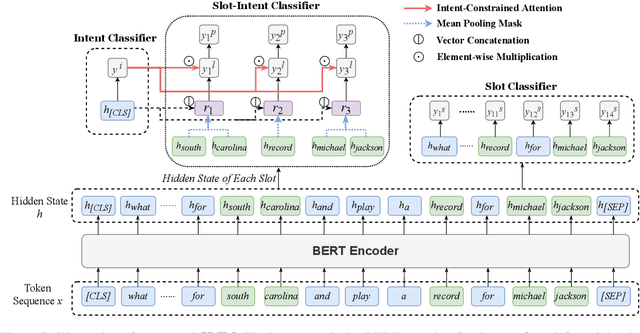
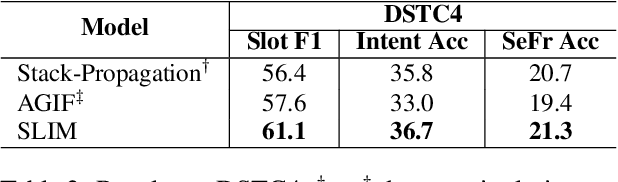
Utterance-level intent detection and token-level slot filling are two key tasks for natural language understanding (NLU) in task-oriented systems. Most existing approaches assume that only a single intent exists in an utterance. However, there are often multiple intents within an utterance in real-life scenarios. In this paper, we propose a multi-intent NLU framework, called SLIM, to jointly learn multi-intent detection and slot filling based on BERT. To fully exploit the existing annotation data and capture the interactions between slots and intents, SLIM introduces an explicit slot-intent classifier to learn the many-to-one mapping between slots and intents. Empirical results on three public multi-intent datasets demonstrate (1) the superior performance of SLIM compared to the current state-of-the-art for NLU with multiple intents and (2) the benefits obtained from the slot-intent classifier.
A Collaborative Aerial-Ground Robotic System for Fast Exploration
Jun 07, 2018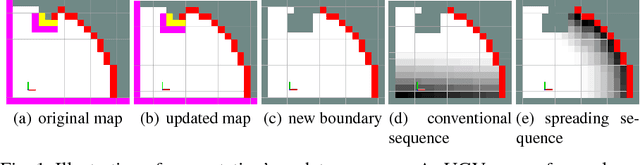
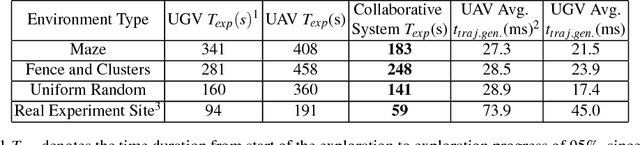


Autonomous exploration of unknown environments has been widely applied in inspection, surveillance, and search and rescue. In exploration task, the basic requirement for robots is to detect the unknown space as fast as possible. In this paper, we propose an autonomous collaborative system consists of an aerial robot and a ground vehicle to explore in unknown environments. We combine the frontier based method and the harmonic field to generate a path. Then, For the ground robot, a minimum jerk piecewise Bezier curve which can guarantee safety and dynamical feasibility is generated amid obstacles. For the aerial robot, a motion primitive method is adopted for local path planning. We implement the proposed framework on an autonomous collaborative aerial-ground system. Extensive field experiments as well as simulations are presented to validate the method and demonstrate its higher efficiency against each single vehicle.