 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReversible Lifelong Model Editing via Semantic Routing-Based LoRA
Mar 11, 2026The dynamic evolution of real-world necessitates model editing within Large Language Models. While existing methods explore modular isolation or parameter-efficient strategies, they still suffer from semantic drift or knowledge forgetting due to continual updating. To address these challenges, we propose SoLA, a Semantic routing-based LoRA framework for lifelong model editing. In SoLA, each edit is encapsulated as an independent LoRA module, which is frozen after training and mapped to input by semantic routing, allowing dynamic activation of LoRA modules via semantic matching. This mechanism avoids semantic drift caused by cluster updating and mitigates catastrophic forgetting from parameter sharing. More importantly, SoLA supports precise revocation of specific edits by removing key from semantic routing, which restores model's original behavior. To our knowledge, this reversible rollback editing capability is the first to be achieved in existing literature. Furthermore, SoLA integrates decision-making process into edited layer, eliminating the need for auxiliary routing networks and enabling end-to-end decision-making process. Extensive experiments demonstrate that SoLA effectively learns and retains edited knowledge, achieving accurate, efficient, and reversible lifelong model editing.
A Simple Efficiency Incremental Learning Framework via Vision-Language Model with Nonlinear Multi-Adapters
Mar 11, 2026Incremental Learning (IL) aims to learn new tasks while preserving previously acquired knowledge. Integrating the zero-shot learning capabilities of pre-trained vision-language models into IL methods has marked a significant advancement. However, these methods face three primary challenges: (1) the need for improved training efficiency; (2) reliance on a memory bank to store previous data; and (3) the necessity of a strong backbone to augment the model's capabilities. In this paper, we propose SimE, a Simple and Efficient framework that employs a vision-language model with adapters designed specifically for the IL task. We report a remarkable phenomenon: there is a nonlinear correlation between the number of adaptive adapter connections and the model's IL capabilities. While increasing adapter connections between transformer blocks improves model performance, adding more adaptive connections within transformer blocks during smaller incremental steps does not enhance, and may even degrade the model's IL ability. Extensive experimental results show that SimE surpasses traditional methods by 9.6% on TinyImageNet and outperforms other CLIP-based methods by 5.3% on CIFAR-100. Furthermore, we conduct a systematic study to enhance the utilization of the zero-shot capabilities of CLIP. We suggest replacing SimE's encoder with a CLIP model trained on larger datasets (e.g., LAION2B) and stronger architectures (e.g., ViT-L/14).
Representation Finetuning for Continual Learning
Mar 11, 2026The world is inherently dynamic, and continual learning aims to enable models to adapt to ever-evolving data streams. While pre-trained models have shown powerful performance in continual learning, they still require finetuning to adapt effectively to downstream tasks. However, prevailing Parameter-Efficient Fine-Tuning (PEFT) methods operate through empirical, black-box optimization at the weight level. These approaches lack explicit control over representation drift, leading to sensitivity to domain shifts and catastrophic forgetting in continual learning scenarios. In this work, we introduce Continual Representation Learning (CoRe), a novel framework that for the first time shifts the finetuning paradigm from weight space to representation space. Unlike conventional methods, CoRe performs task-specific interventions within a low-rank linear subspace of hidden representations, adopting a learning process with explicit objectives, which ensures stability for past tasks while maintaining plasticity for new ones. By constraining updates to a low-rank subspace, CoRe achieves exceptional parameter efficiency. Extensive experiments across multiple continual learning benchmarks demonstrate that CoRe not only preserves parameter efficiency but also significantly outperforms existing state-of-the-art methods. Our work introduces representation finetuning as a new, more effective and interpretable paradigm for continual learning.
Comparison of machine learning methods for classifying mediastinal lymph node metastasis of non-small cell lung cancer from 18F-FDG PET/CT images
Feb 07, 2017
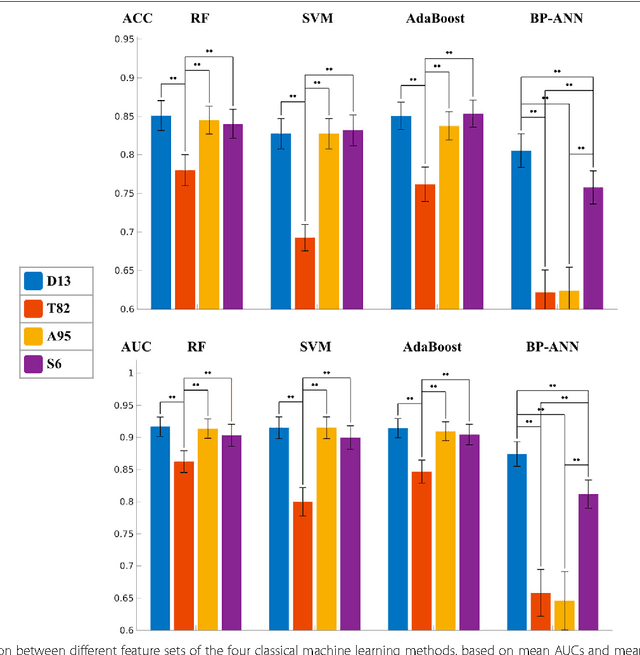
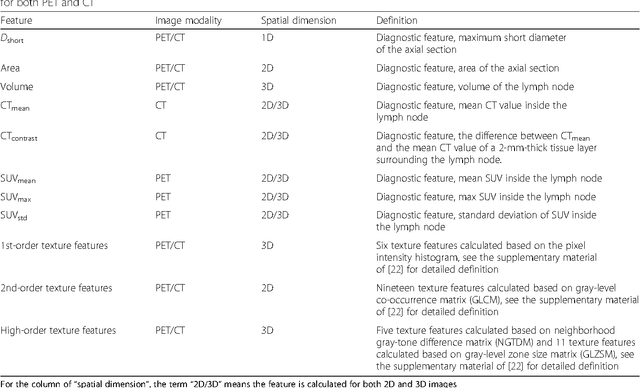
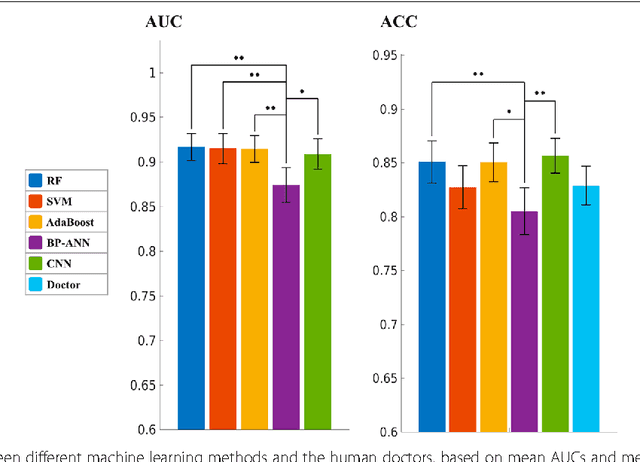
The present study shows that the performance of CNN is not significantly different from the best classical methods and human doctors for classifying mediastinal lymph node metastasis of NSCLC from PET/CT images. Because CNN does not need tumor segmentation or feature calculation, it is more convenient and more objective than the classical methods. However, CNN does not make use of the import diagnostic features, which have been proved more discriminative than the texture features for classifying small-sized lymph nodes. Therefore, incorporating the diagnostic features into CNN is a promising direction for future research.