 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Sa2VA for Referent Video Object Segmentation: 2nd Solution for 7th LSVOS RVOS Track
Sep 19, 2025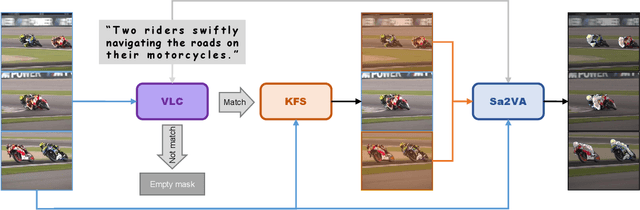



Referential Video Object Segmentation (RVOS) aims to segment all objects in a video that match a given natural language description, bridging the gap between vision and language understanding. Recent work, such as Sa2VA, combines Large Language Models (LLMs) with SAM~2, leveraging the strong video reasoning capability of LLMs to guide video segmentation. In this work, we present a training-free framework that substantially improves Sa2VA's performance on the RVOS task. Our method introduces two key components: (1) a Video-Language Checker that explicitly verifies whether the subject and action described in the query actually appear in the video, thereby reducing false positives; and (2) a Key-Frame Sampler that adaptively selects informative frames to better capture both early object appearances and long-range temporal context. Without any additional training, our approach achieves a J&F score of 64.14% on the MeViS test set, ranking 2nd place in the RVOS track of the 7th LSVOS Challenge at ICCV 2025.
Pseudo-Label Enhanced Cascaded Framework: 2nd Technical Report for LSVOS 2025 VOS Track
Sep 18, 2025



Complex Video Object Segmentation (VOS) presents significant challenges in accurately segmenting objects across frames, especially in the presence of small and similar targets, frequent occlusions, rapid motion, and complex interactions. In this report, we present our solution for the LSVOS 2025 VOS Track based on the SAM2 framework. We adopt a pseudo-labeling strategy during training: a trained SAM2 checkpoint is deployed within the SAM2Long framework to generate pseudo labels for the MOSE test set, which are then combined with existing data for further training. For inference, the SAM2Long framework is employed to obtain our primary segmentation results, while an open-source SeC model runs in parallel to produce complementary predictions. A cascaded decision mechanism dynamically integrates outputs from both models, exploiting the temporal stability of SAM2Long and the concept-level robustness of SeC. Benefiting from pseudo-label training and cascaded multi-model inference, our approach achieves a J\&F score of 0.8616 on the MOSE test set -- +1.4 points over our SAM2Long baseline -- securing the 2nd place in the LSVOS 2025 VOS Track, and demonstrating strong robustness and accuracy in long, complex video segmentation scenarios.
PLDNet: PLD-Guided Lightweight Deep Network Boosted by Efficient Attention for Handheld Dual-Microphone Speech Enhancement
Jun 06, 2024



Low-complexity speech enhancement on mobile phones is crucial in the era of 5G. Thus, focusing on handheld mobile phone communication scenario, based on power level difference (PLD) algorithm and lightweight U-Net, we propose PLD-guided lightweight deep network (PLDNet), an extremely lightweight dual-microphone speech enhancement method that integrates the guidance of signal processing algorithm and lightweight attention-augmented U-Net. For the guidance information, we employ PLD algorithm to pre-process dual-microphone spectrum, and feed the output into subsequent deep neural network, which utilizes a lightweight U-Net with our proposed gated convolution augmented frequency attention (GCAFA) module to extract desired clean speech. Experimental results demonstrate that our proposed method achieves competitive performance with recent top-performing models while reducing computational cost by over 90%, highlighting the potential for low-complexity speech enhancement on mobile phones.