 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGR-Diffusion: 3D Gaussian Representation Meets Diffusion in Whole-Body PET Reconstruction
Feb 12, 2026Positron emission tomography (PET) reconstruction is a critical challenge in molecular imaging, often hampered by noise amplification, structural blurring, and detail loss due to sparse sampling and the ill-posed nature of inverse problems. The three-dimensional discrete Gaussian representation (GR), which efficiently encodes 3D scenes using parameterized discrete Gaussian distributions, has shown promise in computer vision. In this work, we pro-pose a novel GR-Diffusion framework that synergistically integrates the geometric priors of GR with the generative power of diffusion models for 3D low-dose whole-body PET reconstruction. GR-Diffusion employs GR to generate a reference 3D PET image from projection data, establishing a physically grounded and structurally explicit benchmark that overcomes the low-pass limitations of conventional point-based or voxel-based methods. This reference image serves as a dual guide during the diffusion process, ensuring both global consistency and local accuracy. Specifically, we employ a hierarchical guidance mechanism based on the GR reference. Fine-grained guidance leverages differences to refine local details, while coarse-grained guidance uses multi-scale difference maps to correct deviations. This strategy allows the diffusion model to sequentially integrate the strong geometric prior from GR and recover sub-voxel information. Experimental results on the UDPET and Clinical datasets with varying dose levels show that GR-Diffusion outperforms state-of-the-art methods in enhancing 3D whole-body PET image quality and preserving physiological details.
Meta-information Guided Cross-domain Synergistic Diffusion Model for Low-dose PET Reconstruction
Dec 23, 2025Low-dose PET imaging is crucial for reducing patient radiation exposure but faces challenges like noise interference, reduced contrast, and difficulty in preserving physiological details. Existing methods often neglect both projection-domain physics knowledge and patient-specific meta-information, which are critical for functional-semantic correlation mining. In this study, we introduce a meta-information guided cross-domain synergistic diffusion model (MiG-DM) that integrates comprehensive cross-modal priors to generate high-quality PET images. Specifically, a meta-information encoding module transforms clinical parameters into semantic prompts by considering patient characteristics, dose-related information, and semi-quantitative parameters, enabling cross-modal alignment between textual meta-information and image reconstruction. Additionally, the cross-domain architecture combines projection-domain and image-domain processing. In the projection domain, a specialized sinogram adapter captures global physical structures through convolution operations equivalent to global image-domain filtering. Experiments on the UDPET public dataset and clinical datasets with varying dose levels demonstrate that MiG-DM outperforms state-of-the-art methods in enhancing PET image quality and preserving physiological details.
Enhancing Sa2VA for Referent Video Object Segmentation: 2nd Solution for 7th LSVOS RVOS Track
Sep 19, 2025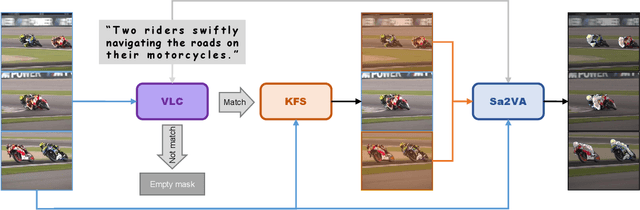



Referential Video Object Segmentation (RVOS) aims to segment all objects in a video that match a given natural language description, bridging the gap between vision and language understanding. Recent work, such as Sa2VA, combines Large Language Models (LLMs) with SAM~2, leveraging the strong video reasoning capability of LLMs to guide video segmentation. In this work, we present a training-free framework that substantially improves Sa2VA's performance on the RVOS task. Our method introduces two key components: (1) a Video-Language Checker that explicitly verifies whether the subject and action described in the query actually appear in the video, thereby reducing false positives; and (2) a Key-Frame Sampler that adaptively selects informative frames to better capture both early object appearances and long-range temporal context. Without any additional training, our approach achieves a J&F score of 64.14% on the MeViS test set, ranking 2nd place in the RVOS track of the 7th LSVOS Challenge at ICCV 2025.
Pseudo-Label Enhanced Cascaded Framework: 2nd Technical Report for LSVOS 2025 VOS Track
Sep 18, 2025



Complex Video Object Segmentation (VOS) presents significant challenges in accurately segmenting objects across frames, especially in the presence of small and similar targets, frequent occlusions, rapid motion, and complex interactions. In this report, we present our solution for the LSVOS 2025 VOS Track based on the SAM2 framework. We adopt a pseudo-labeling strategy during training: a trained SAM2 checkpoint is deployed within the SAM2Long framework to generate pseudo labels for the MOSE test set, which are then combined with existing data for further training. For inference, the SAM2Long framework is employed to obtain our primary segmentation results, while an open-source SeC model runs in parallel to produce complementary predictions. A cascaded decision mechanism dynamically integrates outputs from both models, exploiting the temporal stability of SAM2Long and the concept-level robustness of SeC. Benefiting from pseudo-label training and cascaded multi-model inference, our approach achieves a J\&F score of 0.8616 on the MOSE test set -- +1.4 points over our SAM2Long baseline -- securing the 2nd place in the LSVOS 2025 VOS Track, and demonstrating strong robustness and accuracy in long, complex video segmentation scenarios.
st-DTPM: Spatial-Temporal Guided Diffusion Transformer Probabilistic Model for Delayed Scan PET Image Prediction
Oct 30, 2024



PET imaging is widely employed for observing biological metabolic activities within the human body. However, numerous benign conditions can cause increased uptake of radiopharmaceuticals, confounding differentiation from malignant tumors. Several studies have indicated that dual-time PET imaging holds promise in distinguishing between malignant and benign tumor processes. Nevertheless, the hour-long distribution period of radiopharmaceuticals post-injection complicates the determination of optimal timing for the second scan, presenting challenges in both practical applications and research. Notably, we have identified that delay time PET imaging can be framed as an image-to-image conversion problem. Motivated by this insight, we propose a novel spatial-temporal guided diffusion transformer probabilistic model (st-DTPM) to solve dual-time PET imaging prediction problem. Specifically, this architecture leverages the U-net framework that integrates patch-wise features of CNN and pixel-wise relevance of Transformer to obtain local and global information. And then employs a conditional DDPM model for image synthesis. Furthermore, on spatial condition, we concatenate early scan PET images and noisy PET images on every denoising step to guide the spatial distribution of denoising sampling. On temporal condition, we convert diffusion time steps and delay time to a universal time vector, then embed it to each layer of model architecture to further improve the accuracy of predictions. Experimental results demonstrated the superiority of our method over alternative approaches in preserving image quality and structural information, thereby affirming its efficacy in predictive task.