 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePCFGaze: Physics-Consistent Feature for Appearance-based Gaze Estimation
Sep 05, 2023Although recent deep learning based gaze estimation approaches have achieved much improvement, we still know little about how gaze features are connected to the physics of gaze. In this paper, we try to answer this question by analyzing the gaze feature manifold. Our analysis revealed the insight that the geodesic distance between gaze features is consistent with the gaze differences between samples. According to this finding, we construct the Physics- Consistent Feature (PCF) in an analytical way, which connects gaze feature to the physical definition of gaze. We further propose the PCFGaze framework that directly optimizes gaze feature space by the guidance of PCF. Experimental results demonstrate that the proposed framework alleviates the overfitting problem and significantly improves cross-domain gaze estimation accuracy without extra training data. The insight of gaze feature has the potential to benefit other regression tasks with physical meanings.
RT-MonoDepth: Real-time Monocular Depth Estimation on Embedded Systems
Aug 21, 2023



Depth sensing is a crucial function of unmanned aerial vehicles and autonomous vehicles. Due to the small size and simple structure of monocular cameras, there has been a growing interest in depth estimation from a single RGB image. However, state-of-the-art monocular CNN-based depth estimation methods using fairly complex deep neural networks are too slow for real-time inference on embedded platforms. This paper addresses the problem of real-time depth estimation on embedded systems. We propose two efficient and lightweight encoder-decoder network architectures, RT-MonoDepth and RT-MonoDepth-S, to reduce computational complexity and latency. Our methodologies demonstrate that it is possible to achieve similar accuracy as prior state-of-the-art works on depth estimation at a faster inference speed. Our proposed networks, RT-MonoDepth and RT-MonoDepth-S, runs at 18.4\&30.5 FPS on NVIDIA Jetson Nano and 253.0\&364.1 FPS on NVIDIA Jetson AGX Orin on a single RGB image of resolution 640$\times$192, and achieve relative state-of-the-art accuracy on the KITTI dataset. To the best of the authors' knowledge, this paper achieves the best accuracy and fastest inference speed compared with existing fast monocular depth estimation methods.
DVGaze: Dual-View Gaze Estimation
Aug 20, 2023



Gaze estimation methods estimate gaze from facial appearance with a single camera. However, due to the limited view of a single camera, the captured facial appearance cannot provide complete facial information and thus complicate the gaze estimation problem. Recently, camera devices are rapidly updated. Dual cameras are affordable for users and have been integrated in many devices. This development suggests that we can further improve gaze estimation performance with dual-view gaze estimation. In this paper, we propose a dual-view gaze estimation network (DV-Gaze). DV-Gaze estimates dual-view gaze directions from a pair of images. We first propose a dual-view interactive convolution (DIC) block in DV-Gaze. DIC blocks exchange dual-view information during convolution in multiple feature scales. It fuses dual-view features along epipolar lines and compensates for the original feature with the fused feature. We further propose a dual-view transformer to estimate gaze from dual-view features. Camera poses are encoded to indicate the position information in the transformer. We also consider the geometric relation between dual-view gaze directions and propose a dual-view gaze consistency loss for DV-Gaze. DV-Gaze achieves state-of-the-art performance on ETH-XGaze and EVE datasets. Our experiments also prove the potential of dual-view gaze estimation. We release codes in https://github.com/yihuacheng/DVGaze.
SRMAE: Masked Image Modeling for Scale-Invariant Deep Representations
Aug 17, 2023



Due to the prevalence of scale variance in nature images, we propose to use image scale as a self-supervised signal for Masked Image Modeling (MIM). Our method involves selecting random patches from the input image and downsampling them to a low-resolution format. Our framework utilizes the latest advances in super-resolution (SR) to design the prediction head, which reconstructs the input from low-resolution clues and other patches. After 400 epochs of pre-training, our Super Resolution Masked Autoencoders (SRMAE) get an accuracy of 82.1% on the ImageNet-1K task. Image scale signal also allows our SRMAE to capture scale invariance representation. For the very low resolution (VLR) recognition task, our model achieves the best performance, surpassing DeriveNet by 1.3%. Our method also achieves an accuracy of 74.84% on the task of recognizing low-resolution facial expressions, surpassing the current state-of-the-art FMD by 9.48%.
Visibility Enhancement for Low-light Hazy Scenarios
Aug 01, 2023Low-light hazy scenes commonly appear at dusk and early morning. The visual enhancement for low-light hazy images is an ill-posed problem. Even though numerous methods have been proposed for image dehazing and low-light enhancement respectively, simply integrating them cannot deliver pleasing results for this particular task. In this paper, we present a novel method to enhance visibility for low-light hazy scenarios. To handle this challenging task, we propose two key techniques, namely cross-consistency dehazing-enhancement framework and physically based simulation for low-light hazy dataset. Specifically, the framework is designed for enhancing visibility of the input image via fully utilizing the clues from different sub-tasks. The simulation is designed for generating the dataset with ground-truths by the proposed low-light hazy imaging model. The extensive experimental results show that the proposed method outperforms the SOTA solutions on different metrics including SSIM (9.19%) and PSNR(5.03%). In addition, we conduct a user study on real images to demonstrate the effectiveness and necessity of the proposed method by human visual perception.
NPR: Nocturnal Place Recognition in Streets
Apr 17, 2023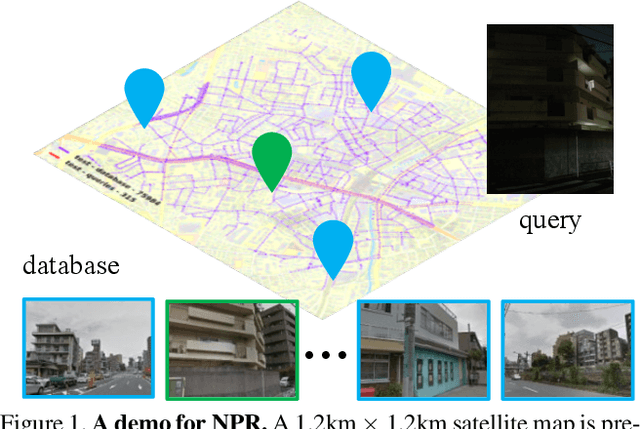
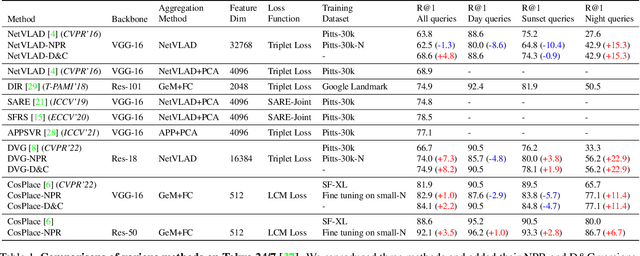


Visual Place Recognition (VPR) is the task of retrieving database images similar to a query photo by comparing it to a large database of known images. In real-world applications, extreme illumination changes caused by query images taken at night pose a significant obstacle that VPR needs to overcome. However, a training set with day-night correspondence for city-scale, street-level VPR does not exist. To address this challenge, we propose a novel pipeline that divides VPR and conquers Nocturnal Place Recognition (NPR). Specifically, we first established a street-level day-night dataset, NightStreet, and used it to train an unpaired image-to-image translation model. Then we used this model to process existing large-scale VPR datasets to generate the VPR-Night datasets and demonstrated how to combine them with two popular VPR pipelines. Finally, we proposed a divide-and-conquer VPR framework and provided explanations at the theoretical, experimental, and application levels. Under our framework, previous methods can significantly improve performance on two public datasets, including the top-ranked method.
Jitter Does Matter: Adapting Gaze Estimation to New Domains
Oct 05, 2022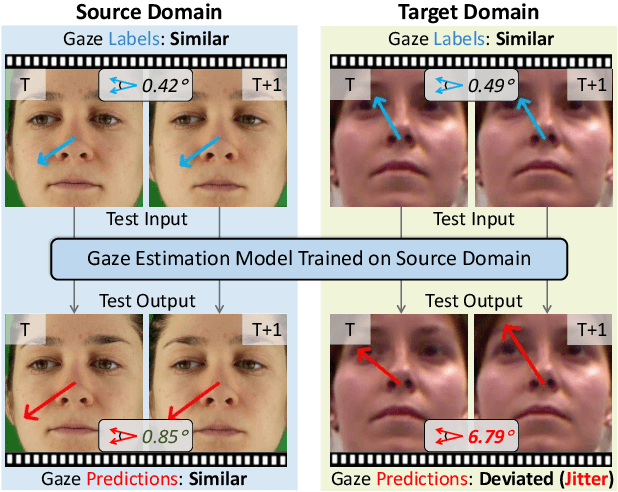
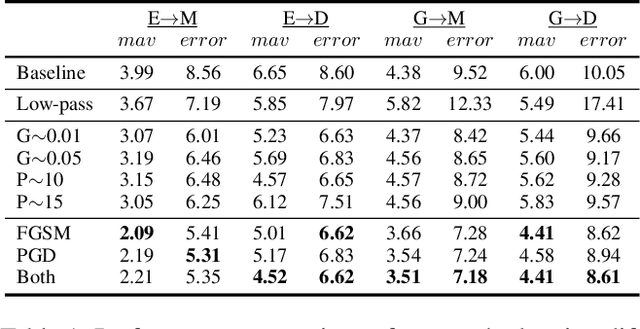
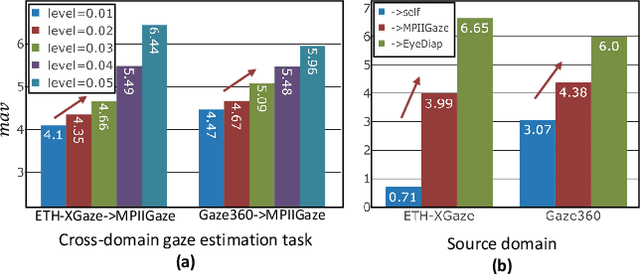
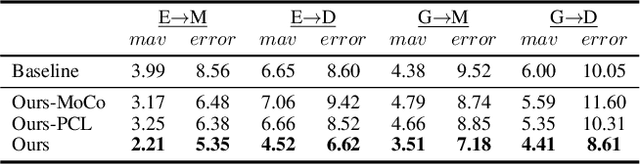
Deep neural networks have demonstrated superior performance on appearance-based gaze estimation tasks. However, due to variations in person, illuminations, and background, performance degrades dramatically when applying the model to a new domain. In this paper, we discover an interesting gaze jitter phenomenon in cross-domain gaze estimation, i.e., the gaze predictions of two similar images can be severely deviated in target domain. This is closely related to cross-domain gaze estimation tasks, but surprisingly, it has not been noticed yet previously. Therefore, we innovatively propose to utilize the gaze jitter to analyze and optimize the gaze domain adaptation task. We find that the high-frequency component (HFC) is an important factor that leads to jitter. Based on this discovery, we add high-frequency components to input images using the adversarial attack and employ contrastive learning to encourage the model to obtain similar representations between original and perturbed data, which reduces the impacts of HFC. We evaluate the proposed method on four cross-domain gaze estimation tasks, and experimental results demonstrate that it significantly reduces the gaze jitter and improves the gaze estimation performance in target domains.
Discriminative feature encoding for intrinsic image decomposition
Sep 25, 2022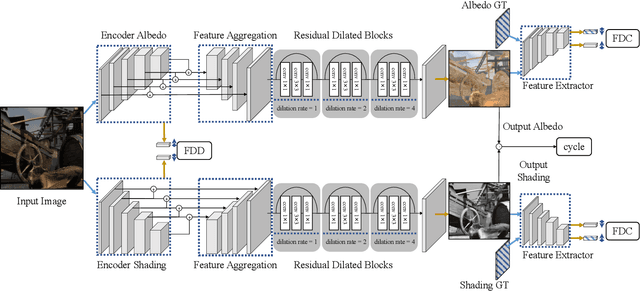



Intrinsic image decomposition is an important and long-standing computer vision problem. Given an input image, recovering the physical scene properties is ill-posed. Several physically motivated priors have been used to restrict the solution space of the optimization problem for intrinsic image decomposition. This work takes advantage of deep learning, and shows that it can solve this challenging computer vision problem with high efficiency. The focus lies in the feature encoding phase to extract discriminative features for different intrinsic layers from an input image. To achieve this goal, we explore the distinctive characteristics of different intrinsic components in the high dimensional feature embedding space. We define feature distribution divergence to efficiently separate the feature vectors of different intrinsic components. The feature distributions are also constrained to fit the real ones through a feature distribution consistency. In addition, a data refinement approach is provided to remove data inconsistency from the Sintel dataset, making it more suitable for intrinsic image decomposition. Our method is also extended to intrinsic video decomposition based on pixel-wise correspondences between adjacent frames. Experimental results indicate that our proposed network structure can outperform the existing state-of-the-art.
Layout-Bridging Text-to-Image Synthesis
Aug 12, 2022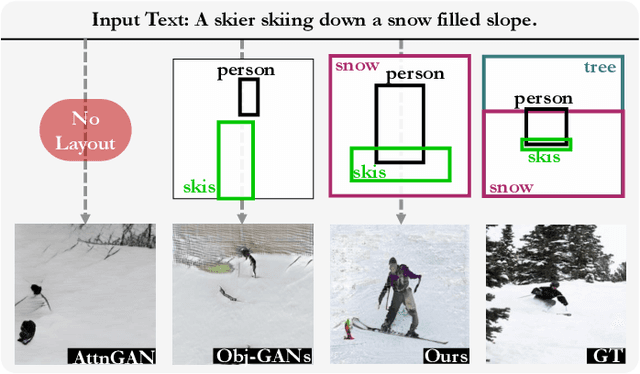

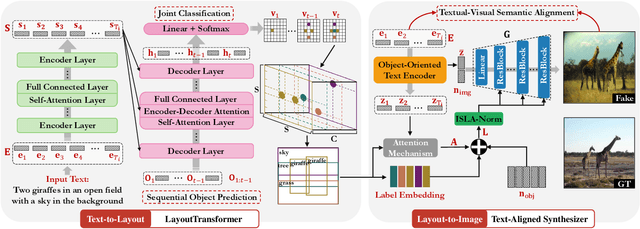
The crux of text-to-image synthesis stems from the difficulty of preserving the cross-modality semantic consistency between the input text and the synthesized image. Typical methods, which seek to model the text-to-image mapping directly, could only capture keywords in the text that indicates common objects or actions but fail to learn their spatial distribution patterns. An effective way to circumvent this limitation is to generate an image layout as guidance, which is attempted by a few methods. Nevertheless, these methods fail to generate practically effective layouts due to the diversity of input text and object location. In this paper we push for effective modeling in both text-to-layout generation and layout-to-image synthesis. Specifically, we formulate the text-to-layout generation as a sequence-to-sequence modeling task, and build our model upon Transformer to learn the spatial relationships between objects by modeling the sequential dependencies between them. In the stage of layout-to-image synthesis, we focus on learning the textual-visual semantic alignment per object in the layout to precisely incorporate the input text into the layout-to-image synthesizing process. To evaluate the quality of generated layout, we design a new metric specifically, dubbed Layout Quality Score, which considers both the absolute distribution errors of bounding boxes in the layout and the mutual spatial relationships between them. Extensive experiments on three datasets demonstrate the superior performance of our method over state-of-the-art methods on both predicting the layout and synthesizing the image from the given text.
Gaze-Vergence-Controlled See-Through Vision in Augmented Reality
Jul 06, 2022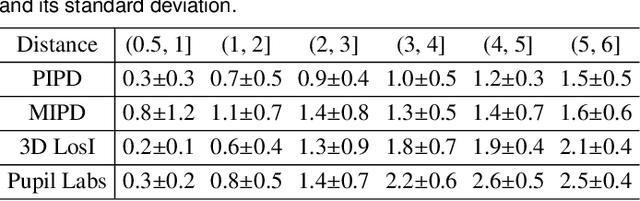
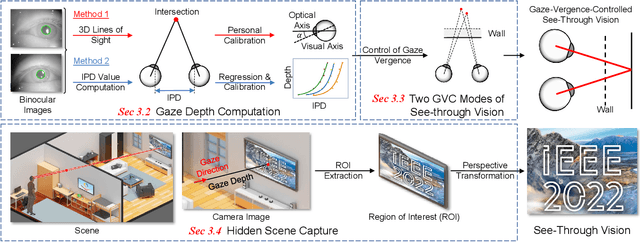
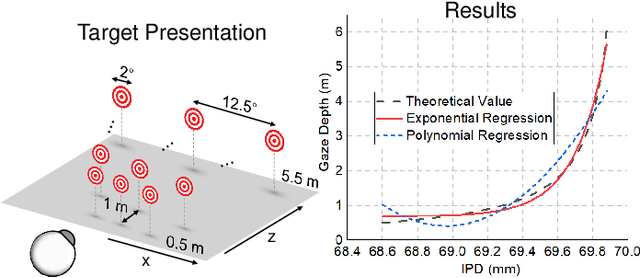
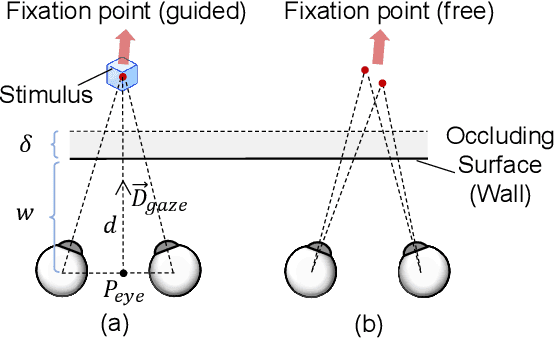
Augmented Reality (AR) see-through vision is an interesting research topic since it enables users to see through a wall and see the occluded objects. Most existing research focuses on the visual effects of see-through vision, while the interaction method is less studied. However, we argue that using common interaction modalities, e.g., midair click and speech, may not be the optimal way to control see-through vision. This is because when we want to see through something, it is physically related to our gaze depth/vergence and thus should be naturally controlled by the eyes. Following this idea, this paper proposes a novel gaze-vergence-controlled (GVC) see-through vision technique in AR. Since gaze depth is needed, we build a gaze tracking module with two infrared cameras and the corresponding algorithm and assemble it into the Microsoft HoloLens 2 to achieve gaze depth estimation. We then propose two different GVC modes for see-through vision to fit different scenarios. Extensive experimental results demonstrate that our gaze depth estimation is efficient and accurate. By comparing with conventional interaction modalities, our GVC techniques are also shown to be superior in terms of efficiency and more preferred by users. Finally, we present four example applications of gaze-vergence-controlled see-through vision.