 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLight 'em Up: Enabling Few-Shot Low-Light 3D Gaussian Splatting with Multi-Scale Explicit Retinex Illumination Decoupling
Apr 27, 2026Full 360$^\circ$ novel view synthesis under low-light conditions remains challenging. Insufficient illumination, noise amplification, and view-dependent photometric inconsistencies prevent existing methods from jointly preserving geometric consistency and photorealism. Unsupervised approaches often exhibit color drift under large viewpoint variations, while supervised low-light enhancement models, though effective for 2D tasks, struggle to generalize to new scenes and typically require retraining. To address this issue, we propose MERID-GS, a Multi-Scale Explicit Retinex Illumination-Decoupled Gaussian framework for low-light 360$^\circ$ synthesis. Based on Retinex theory, the method explicitly separates illumination and reflectance, and suppresses noise propagation while enhancing dark-region structures via a learnable gain and Illumination-State-Guided Frequency Gating. Combined with lightweight Reflection Head and 3D Gaussian Splatting, MERID-GS adapts to new scenes with only a few shots and enables stable low-light novel view synthesis from sparse-view observations. In addition, we construct a low-light multi-view dataset covering full 360$^\circ$ scenes for joint evaluation. Thorough experiments across multiple datasets in this area demonstrate that MERID-GS achieves SOTA performance, exhibiting superior cross-scene generalization and view consistency. The source code and pre-trained models are available at https://github.com/YhuoyuH/MERID-GS..
What Do You See in Vehicle? Comprehensive Vision Solution for In-Vehicle Gaze Estimation
Mar 23, 2024Driver's eye gaze holds a wealth of cognitive and intentional cues crucial for intelligent vehicles. Despite its significance, research on in-vehicle gaze estimation remains limited due to the scarcity of comprehensive and well-annotated datasets in real driving scenarios. In this paper, we present three novel elements to advance in-vehicle gaze research. Firstly, we introduce IVGaze, a pioneering dataset capturing in-vehicle gaze, collected from 125 subjects and covering a large range of gaze and head poses within vehicles. Conventional gaze collection systems are inadequate for in-vehicle use. In this dataset, we propose a new vision-based solution for in-vehicle gaze collection, introducing a refined gaze target calibration method to tackle annotation challenges. Second, our research focuses on in-vehicle gaze estimation leveraging the IVGaze. In-vehicle face images often suffer from low resolution, prompting our introduction of a gaze pyramid transformer that leverages transformer-based multilevel features integration. Expanding upon this, we introduce the dual-stream gaze pyramid transformer (GazeDPTR). Employing perspective transformation, we rotate virtual cameras to normalize images, utilizing camera pose to merge normalized and original images for accurate gaze estimation. GazeDPTR shows state-of-the-art performance on the IVGaze dataset. Thirdly, we explore a novel strategy for gaze zone classification by extending the GazeDPTR. A foundational tri-plane and project gaze onto these planes are newly defined. Leveraging both positional features from the projection points and visual attributes from images, we achieve superior performance compared to relying solely on visual features, substantiating the advantage of gaze estimation. Our project is available at https://yihua.zone/work/ivgaze.
Neural Implicit Field Editing Considering Object-environment Interaction
Nov 01, 2023



The 3D scene editing method based on neural implicit field has gained wide attention. It has achieved excellent results in 3D editing tasks. However, existing methods often blend the interaction between objects and scene environment. The change of scene appearance like shadows is failed to be displayed in the rendering view. In this paper, we propose an Object and Scene environment Interaction aware (OSI-aware) system, which is a novel two-stream neural rendering system considering object and scene environment interaction. To obtain illuminating conditions from the mixture soup, the system successfully separates the interaction between objects and scene environment by intrinsic decomposition method. To study the corresponding changes to the scene appearance from object-level editing tasks, we introduce a depth map guided scene inpainting method and shadow rendering method by point matching strategy. Extensive experiments demonstrate that our novel pipeline produce reasonable appearance changes in scene editing tasks. It also achieve competitive performance for the rendering quality in novel-view synthesis tasks.
Discriminative feature encoding for intrinsic image decomposition
Sep 25, 2022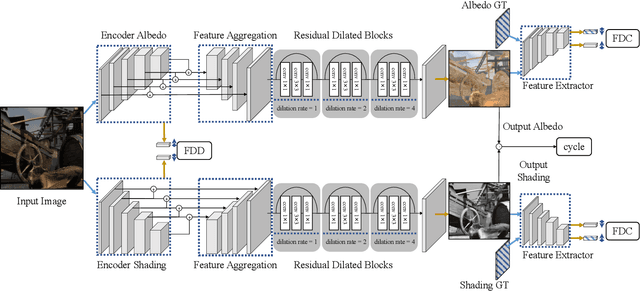



Intrinsic image decomposition is an important and long-standing computer vision problem. Given an input image, recovering the physical scene properties is ill-posed. Several physically motivated priors have been used to restrict the solution space of the optimization problem for intrinsic image decomposition. This work takes advantage of deep learning, and shows that it can solve this challenging computer vision problem with high efficiency. The focus lies in the feature encoding phase to extract discriminative features for different intrinsic layers from an input image. To achieve this goal, we explore the distinctive characteristics of different intrinsic components in the high dimensional feature embedding space. We define feature distribution divergence to efficiently separate the feature vectors of different intrinsic components. The feature distributions are also constrained to fit the real ones through a feature distribution consistency. In addition, a data refinement approach is provided to remove data inconsistency from the Sintel dataset, making it more suitable for intrinsic image decomposition. Our method is also extended to intrinsic video decomposition based on pixel-wise correspondences between adjacent frames. Experimental results indicate that our proposed network structure can outperform the existing state-of-the-art.
Cloud Sphere: A 3D Shape Representation via Progressive Deformation
Dec 21, 2021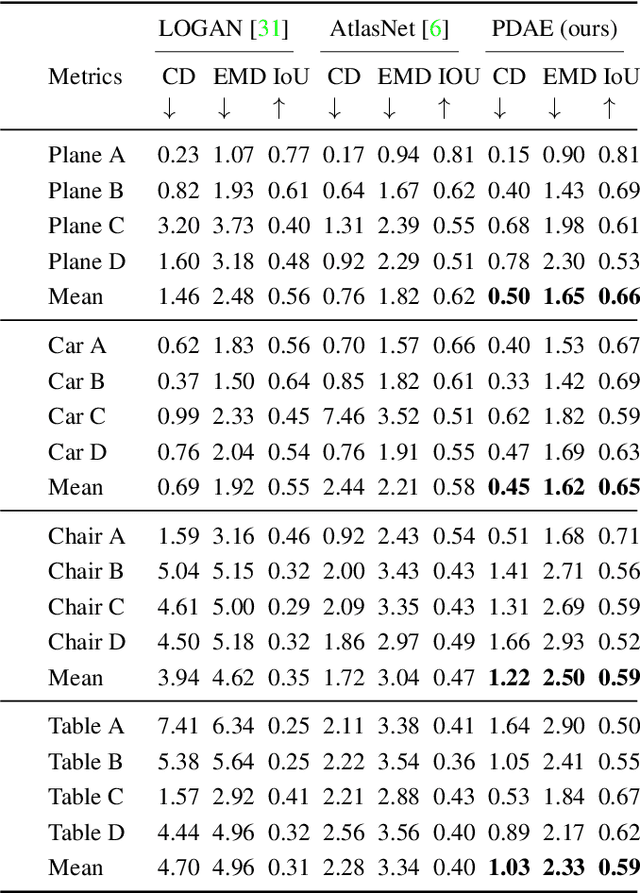
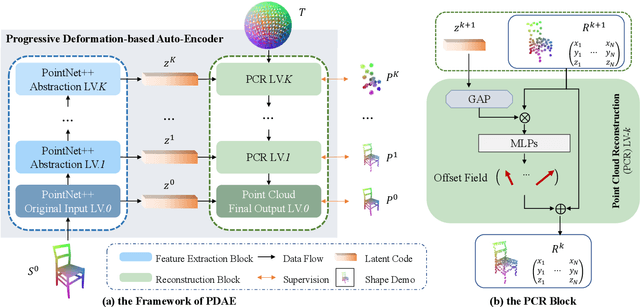
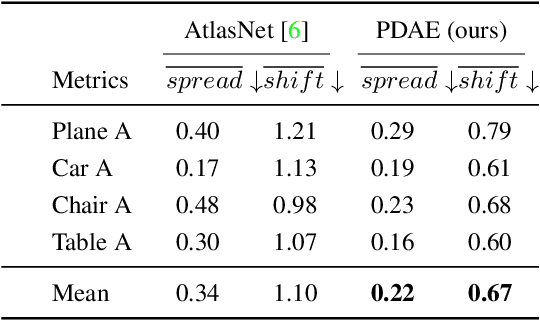
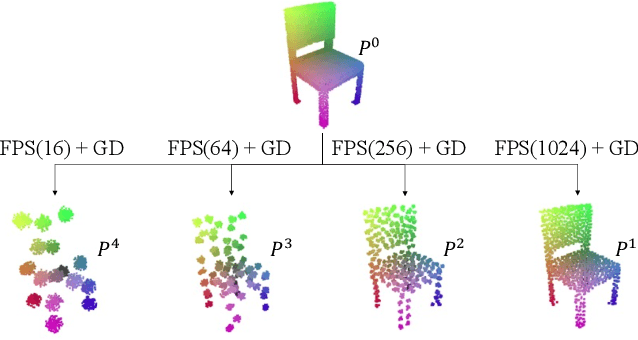
In the area of 3D shape analysis, the geometric properties of a shape have long been studied. Instead of directly extracting representative features using expert-designed descriptors or end-to-end deep neural networks, this paper is dedicated to discovering distinctive information from the shape formation process. Concretely, a spherical point cloud served as the template is progressively deformed to fit the target shape in a coarse-to-fine manner. During the shape formation process, several checkpoints are inserted to facilitate recording and investigating the intermediate stages. For each stage, the offset field is evaluated as a stage-aware description. The summation of the offsets throughout the shape formation process can completely define the target shape in terms of geometry. In this perspective, one can derive the point-wise shape correspondence from the template inexpensively, which benefits various graphic applications. In this paper, the Progressive Deformation-based Auto-Encoder (PDAE) is proposed to learn the stage-aware description through a coarse-to-fine shape fitting task. Experimental results show that the proposed PDAE has the ability to reconstruct 3D shapes with high fidelity, and consistent topology is preserved in the multi-stage deformation process. Additional applications based on the stage-aware description are performed, demonstrating its universality.
Pathological Evidence Exploration in Deep Retinal Image Diagnosis
Dec 06, 2018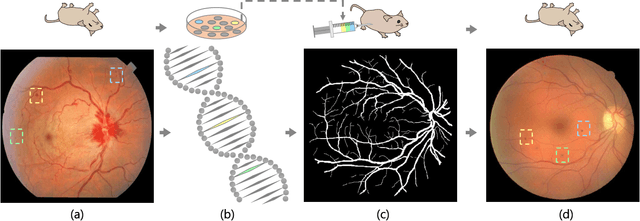

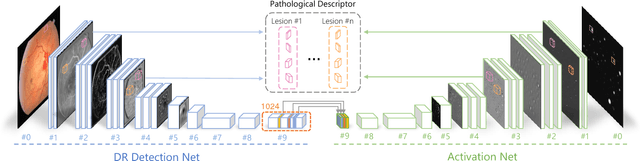

Though deep learning has shown successful performance in classifying the label and severity stage of certain disease, most of them give few evidence on how to make prediction. Here, we propose to exploit the interpretability of deep learning application in medical diagnosis. Inspired by Koch's Postulates, a well-known strategy in medical research to identify the property of pathogen, we define a pathological descriptor that can be extracted from the activated neurons of a diabetic retinopathy detector. To visualize the symptom and feature encoded in this descriptor, we propose a GAN based method to synthesize pathological retinal image given the descriptor and a binary vessel segmentation. Besides, with this descriptor, we can arbitrarily manipulate the position and quantity of lesions. As verified by a panel of 5 licensed ophthalmologists, our synthesized images carry the symptoms that are directly related to diabetic retinopathy diagnosis. The panel survey also shows that our generated images is both qualitatively and quantitatively superior to existing methods.
VoxSegNet: Volumetric CNNs for Semantic Part Segmentation of 3D Shapes
Sep 01, 2018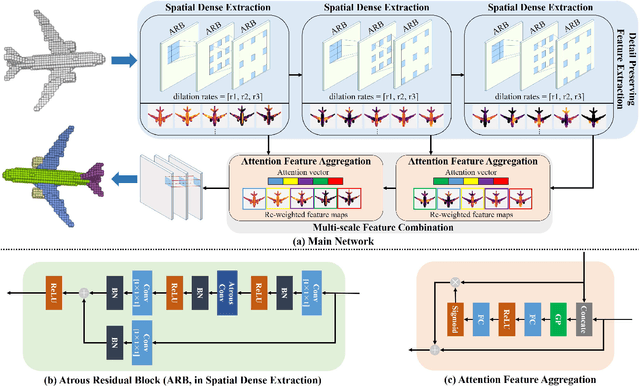
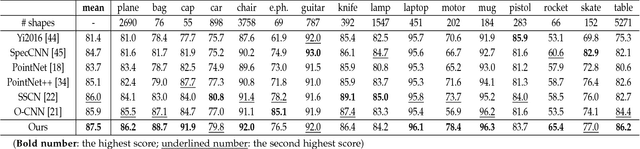
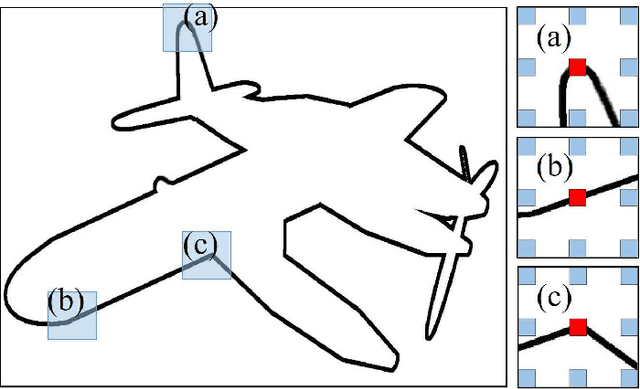
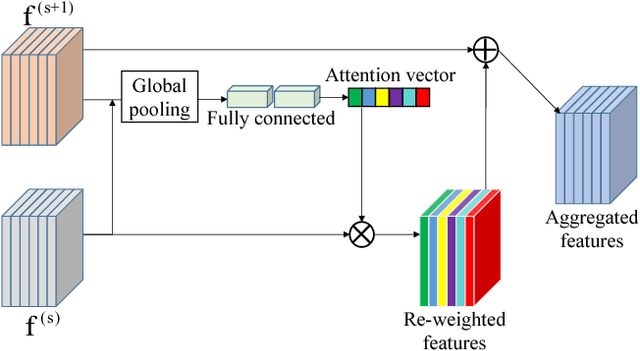
Voxel is an important format to represent geometric data, which has been widely used for 3D deep learning in shape analysis due to its generalization ability and regular data format. However, fine-grained tasks like part segmentation require detailed structural information, which increases voxel resolution and thus causes other issues such as the exhaustion of computational resources. In this paper, we propose a novel volumetric convolutional neural network, which could extract discriminative features encoding detailed information from voxelized 3D data under a limited resolution. To this purpose, a spatial dense extraction (SDE) module is designed to preserve the spatial resolution during the feature extraction procedure, alleviating the loss of detail caused by sub-sampling operations such as max-pooling. An attention feature aggregation (AFA) module is also introduced to adaptively select informative features from different abstraction scales, leading to segmentation with both semantic consistency and high accuracy of details. Experiment results on the large-scale dataset demonstrate the effectiveness of our method in 3D shape part segmentation.