 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Training-Aided Time-Varying Channel Prediction for TDD/FDD Systems
Apr 25, 2022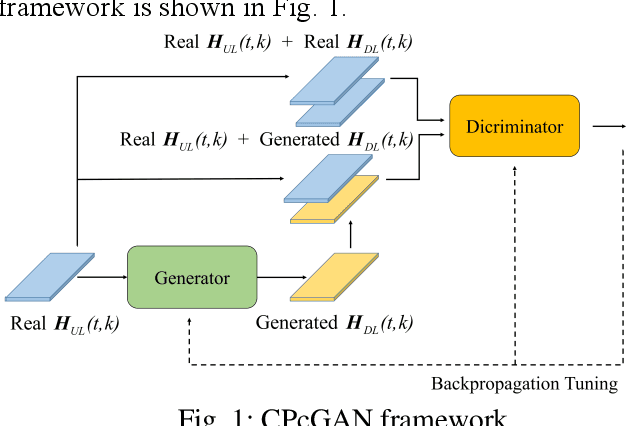
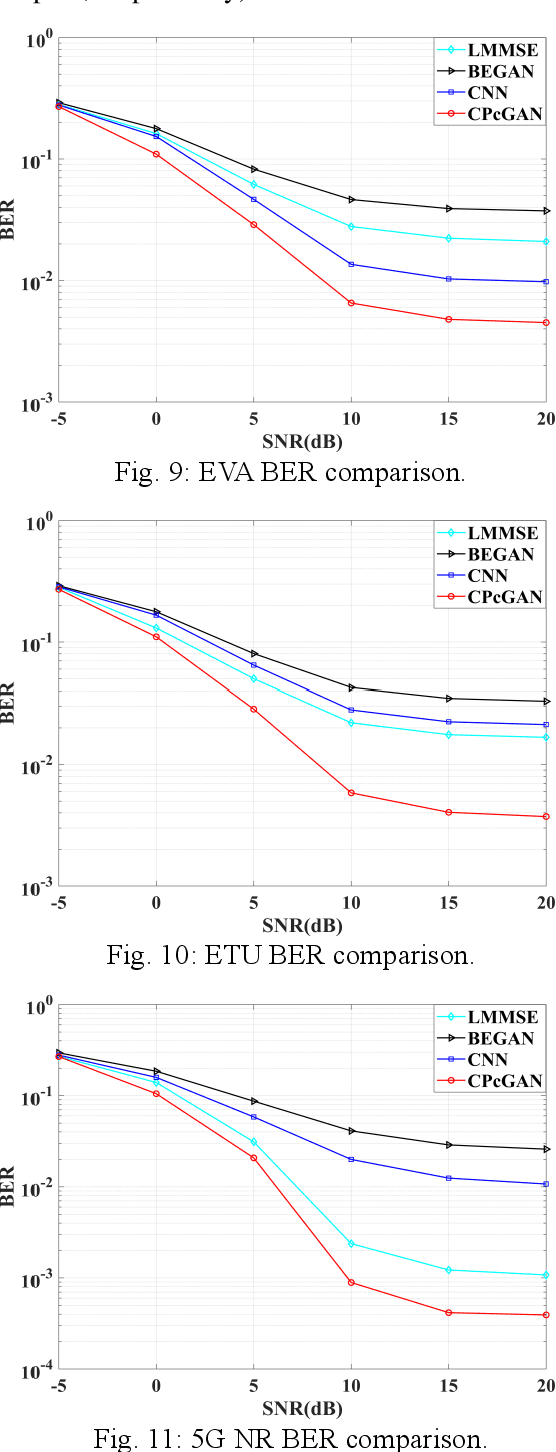
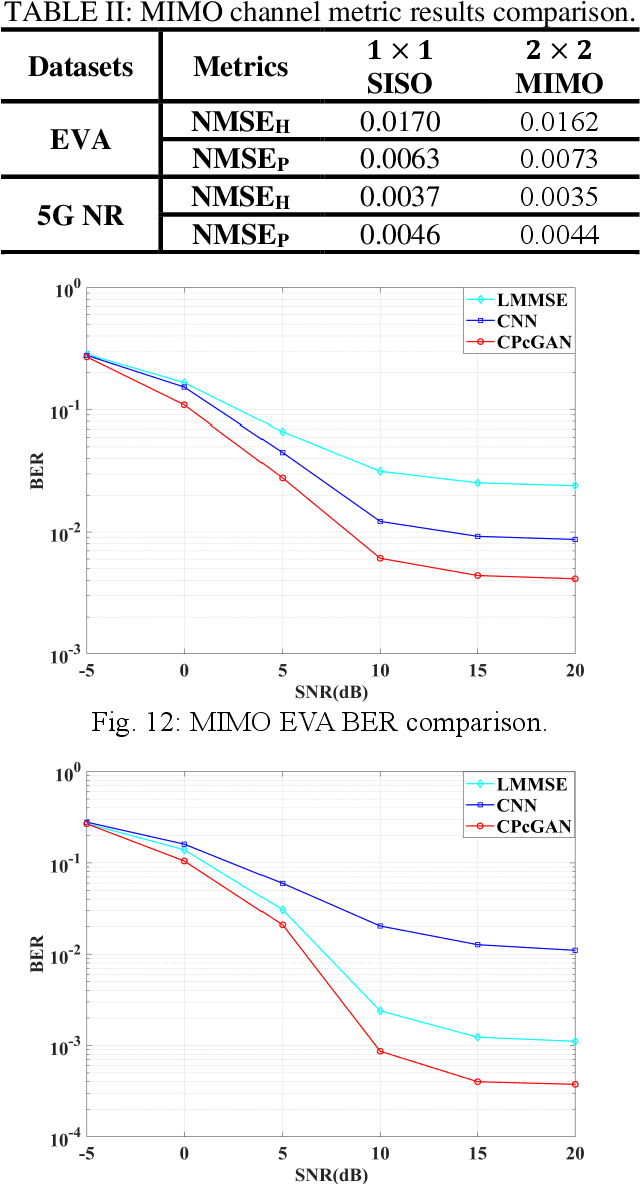
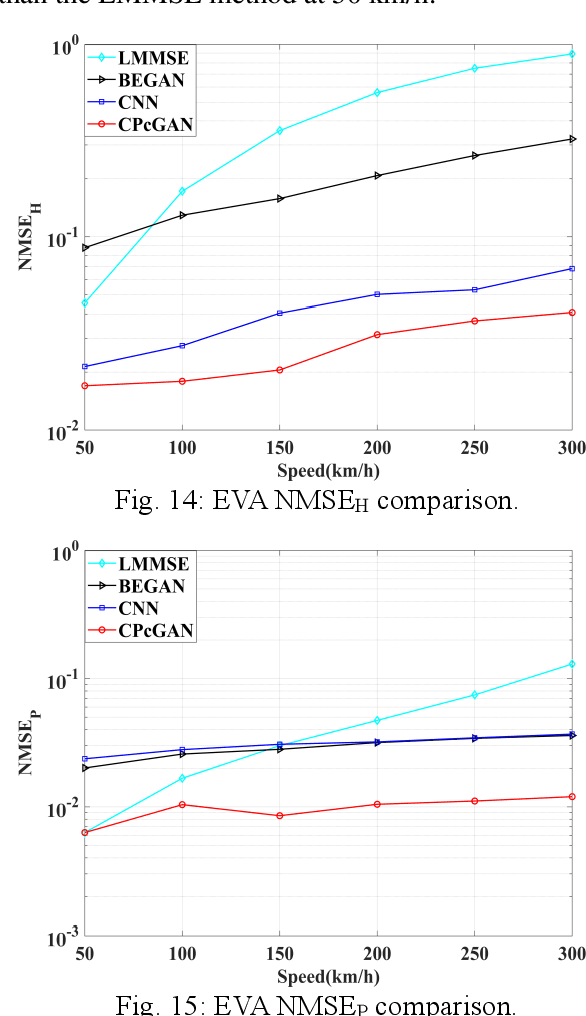
In this paper, a time-varying channel prediction method based on conditional generative adversarial network (CPcGAN) is proposed for time division duplexing/frequency division duplexing (TDD/FDD) systems. CPcGAN utilizes a discriminator to calculate the divergence between the predicted downlink channel state information (CSI) and the real sample distributions under a conditional constraint that is previous uplink CSI. The generator of CPcGAN learns the function relationship between the conditional constraint and the predicted downlink CSI and reduces the divergence between predicted CSI and real CSI. The capability of CPcGAN fitting data distribution can capture the time-varying and multipath characteristics of the channel well. Considering the propagation characteristics of real channel, we further develop a channel prediction error indicator to determine whether the generator reaches the best state. Simulations show that the CPcGAN can obtain higher prediction accuracy and lower system bit error rate than the existing methods under the same user speeds.
Reconfigurable Intelligent Surface for Near Field Communications: Beamforming and Sensing
Apr 21, 2022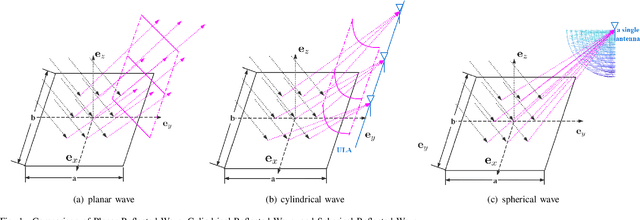
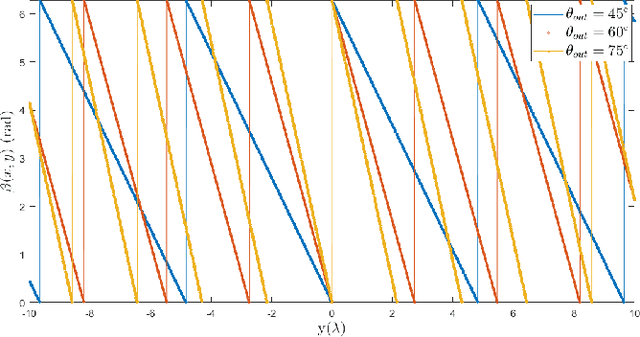
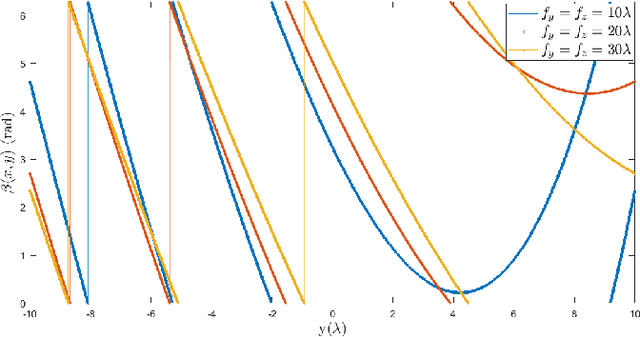
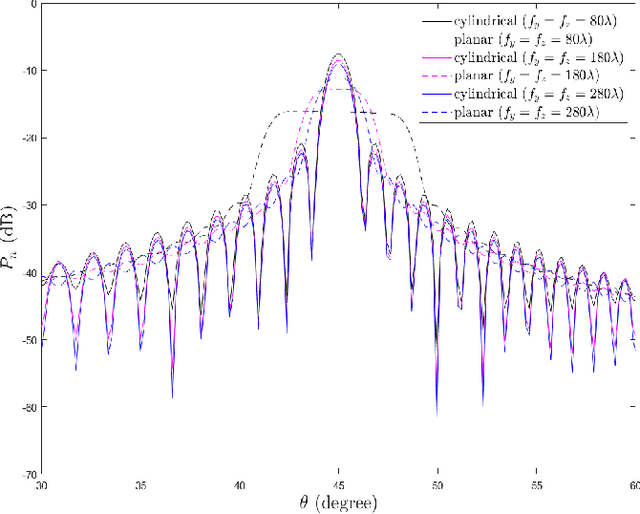
Reconfigurable intelligent surface (RIS) can improve the communications between a source and a destination. The surface contains metamaterial that is configured to reflect the incident wave from the source towards the destination, especially when there is a blockage in between. Recently, continuous aperture RIS is proved to have better communication performance than discrete aperture RIS and has received much attention. However, the conventional continuous aperture RIS is designed to convert the incoming planar waves into the outgoing planar waves, which is not the optimal reflecting scheme when the receiver is not a planar array and is located in the near field of the RIS. In this paper, we consider two types of receivers in the radiating near field of the RIS: (1) when the receiver is equipped with a uniform linear array (ULA), we design RIS coefficient to convert planar waves into cylindrical waves; (2) when the receiver is equipped with a single antenna, we design RIS coefficient to convert planar waves into spherical waves. Simulation results demonstrate that the proposed scheme can reduce energy leakage at the receiver and thus enhance the channel capacity compared to the conventional scheme. More interestingly, with cylindrical or spherical wave radiation, the power received by the receiver is a function of its location and attitude, which could be utilized to sense the location and the attitude of the receiver with communication signaling.
Cluster Head Detection for Hierarchical UAV Swarm With Graph Self-supervised Learning
Mar 08, 2022
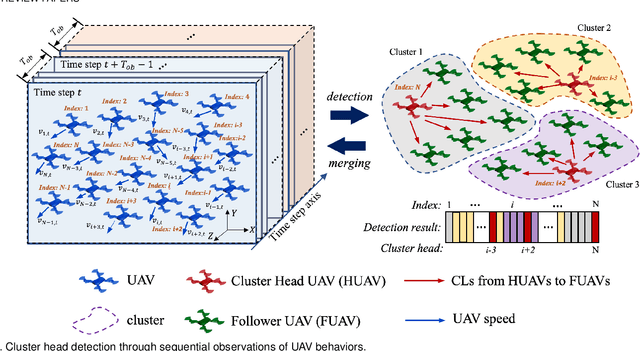
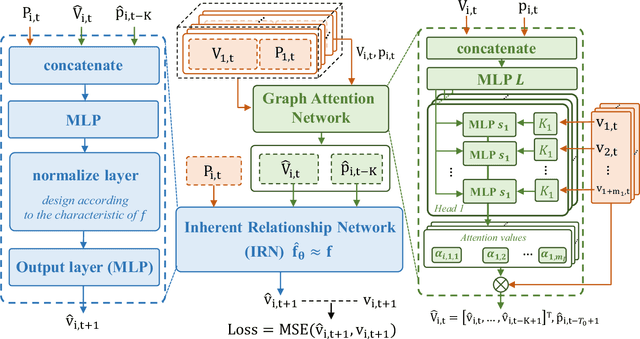

In this paper, we study the cluster head detection problem of a two-level unmanned aerial vehicle (UAV) swarm network (USNET) with multiple UAV clusters, where the inherent follow strategy (IFS) of low-level follower UAVs (FUAVs) with respect to high-level cluster head UAVs (HUAVs) is unknown. We first propose a graph attention self-supervised learning algorithm (GASSL) to detect the HUAVs of a single UAV cluster, where the GASSL can fit the IFS at the same time. Then, to detect the HUAVs in the USNET with multiple UAV clusters, we develop a multi-cluster graph attention self-supervised learning algorithm (MC-GASSL) based on the GASSL. The MC-GASSL clusters the USNET with a gated recurrent unit (GRU)-based metric learning scheme and finds the HUAVs in each cluster with GASSL. Numerical results show that the GASSL can detect the HUAVs in single UAV clusters obeying various kinds of IFSs with over 98% average accuracy. The simulation results also show that the clustering purity of the USNET with MC-GASSL exceeds that with traditional clustering algorithms by at least 10% average. Furthermore, the MC-GASSL can efficiently detect all the HUAVs in USNETs with various IFSs and cluster numbers with low detection redundancies.
Data-Driven Deep Learning Based Hybrid Beamforming for Aerial Massive MIMO-OFDM Systems with Implicit CSI
Feb 10, 2022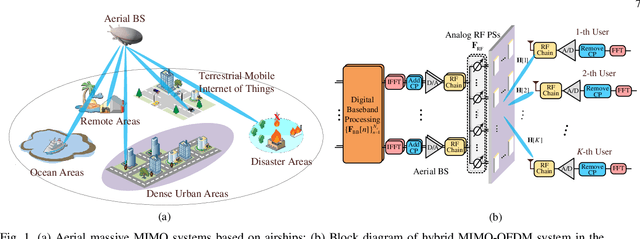
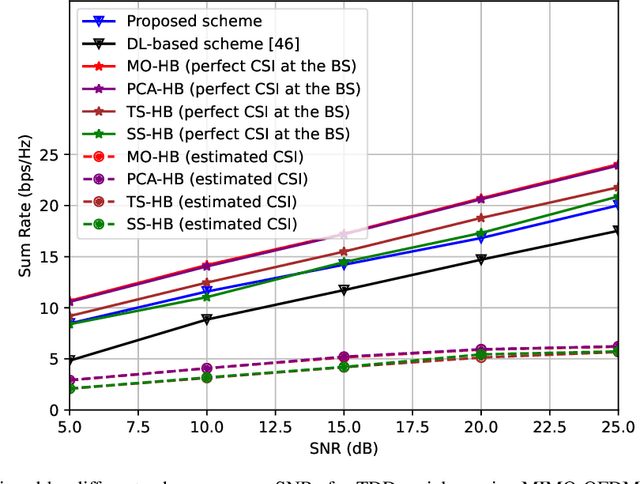
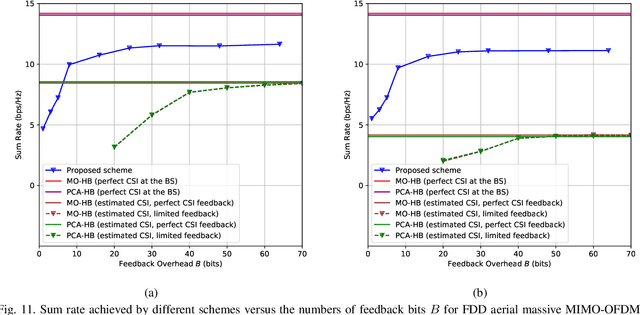
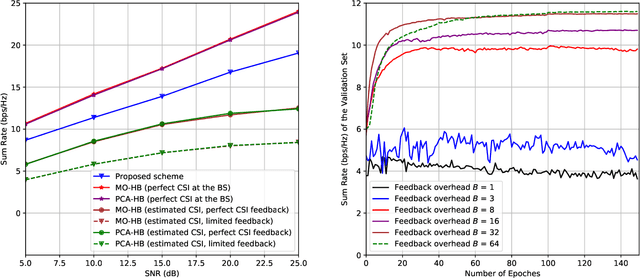
In an aerial hybrid massive multiple-input multiple-output (MIMO) and orthogonal frequency division multiplexing (OFDM) system, how to design a spectral-efficient broadband multi-user hybrid beamforming with a limited pilot and feedback overhead is challenging. To this end, by modeling the key transmission modules as an end-to-end (E2E) neural network, this paper proposes a data-driven deep learning (DL)-based unified hybrid beamforming framework for both the time division duplex (TDD) and frequency division duplex (FDD) systems with implicit channel state information (CSI). For TDD systems, the proposed DL-based approach jointly models the uplink pilot combining and downlink hybrid beamforming modules as an E2E neural network. While for FDD systems, we jointly model the downlink pilot transmission, uplink CSI feedback, and downlink hybrid beamforming modules as an E2E neural network. Different from conventional approaches separately processing different modules, the proposed solution simultaneously optimizes all modules with the sum rate as the optimization object. Therefore, by perceiving the inherent property of air-to-ground massive MIMO-OFDM channel samples, the DL-based E2E neural network can establish the mapping function from the channel to the beamformer, so that the explicit channel reconstruction can be avoided with reduced pilot and feedback overhead. Besides, practical low-resolution phase shifters (PSs) introduce the quantization constraint, leading to the intractable gradient backpropagation when training the neural network. To mitigate the performance loss caused by the phase quantization error, we adopt the transfer learning strategy to further fine-tune the E2E neural network based on a pre-trained network that assumes the ideal infinite-resolution PSs. Numerical results show that our DL-based schemes have considerable advantages over state-of-the-art schemes.
Federated Dynamic Neural Network for Deep MIMO Detection
Nov 24, 2021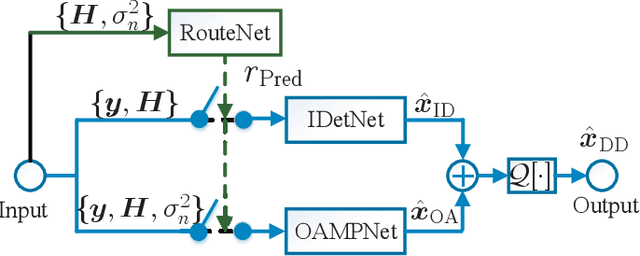
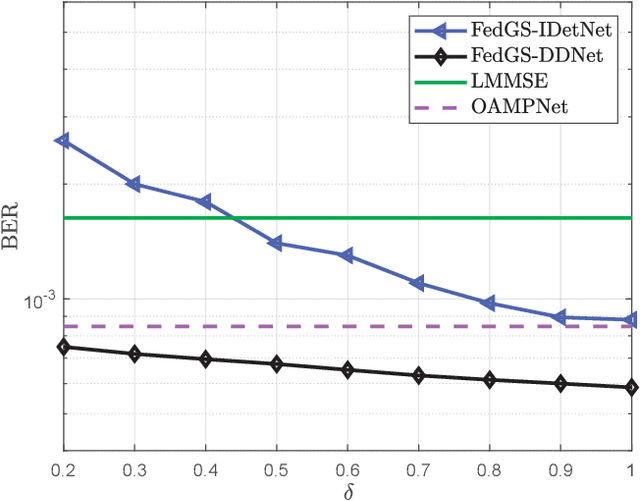
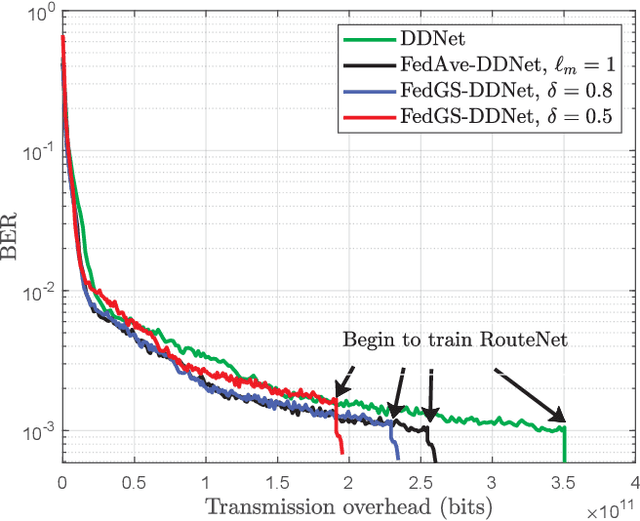
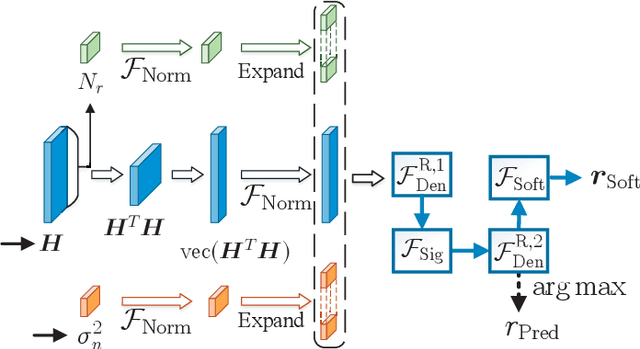
In this paper, we develop a dynamic detection network (DDNet) based detector for multiple-input multiple-output (MIMO) systems. By constructing an improved DetNet (IDetNet) detector and the OAMPNet detector as two independent network branches, the DDNet detector performs sample-wise dynamic routing to adaptively select a better one between the IDetNet and the OAMPNet detectors for every samples under different system conditions. To avoid the prohibitive transmission overhead of dataset collection in centralized learning (CL), we propose the federated averaging (FedAve)-DDNet detector, where all raw data are kept at local clients and only locally trained model parameters are transmitted to the central server for aggregation. To further reduce the transmission overhead, we develop the federated gradient sparsification (FedGS)-DDNet detector by randomly sampling gradients with elaborately calculated probability when uploading gradients to the central server. Based on simulation results, the proposed DDNet detector consistently outperforms other detectors under all system conditions thanks to the sample-wise dynamic routing. Moreover, the federated DDNet detectors, especially the FedGS-DDNet detector, can reduce the transmission overhead by at least 25.7\% while maintaining satisfactory detection accuracy.
Resilient UAV Swarm Communications with Graph Convolutional Neural Network
Jun 30, 2021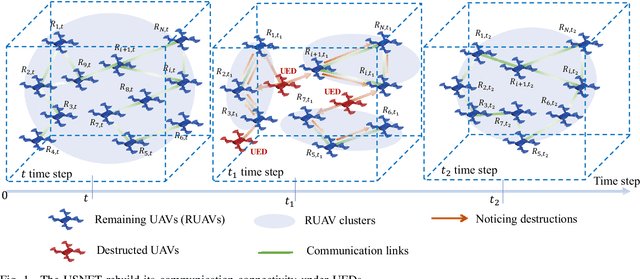
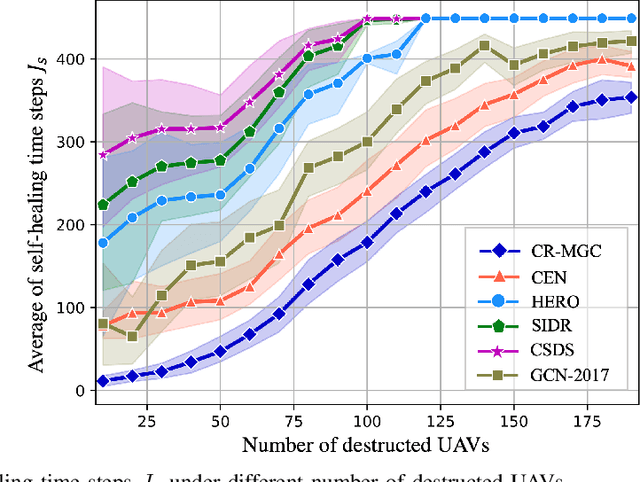
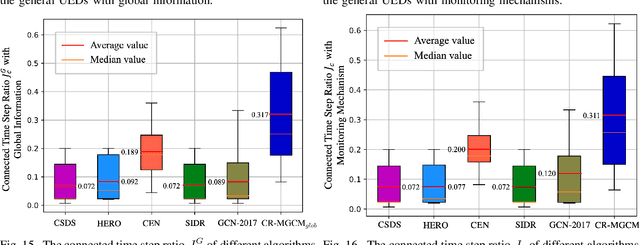
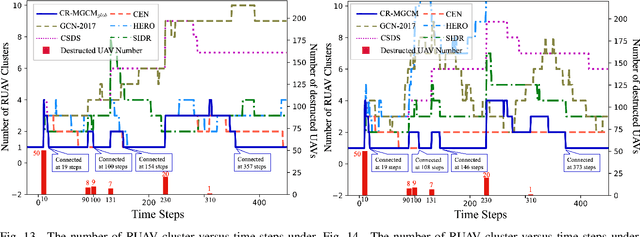
In this paper, we study the self-healing problem of unmanned aerial vehicle (UAV) swarm network (USNET) that is required to quickly rebuild the communication connectivity under unpredictable external disruptions (UEDs). Firstly, to cope with the one-off UEDs, we propose a graph convolutional neural network (GCN) and find the recovery topology of the USNET in an on-line manner. Secondly, to cope with general UEDs, we develop a GCN based trajectory planning algorithm that can make UAVs rebuild the communication connectivity during the self-healing process. We also design a meta learning scheme to facilitate the on-line executions of the GCN. Numerical results show that the proposed algorithms can rebuild the communication connectivity of the USNET more quickly than the existing algorithms under both one-off UEDs and general UEDs. The simulation results also show that the meta learning scheme can not only enhance the performance of the GCN but also reduce the time complexity of the on-line executions.
Cascaded Channel Estimation for RIS Assisted mmWave MIMO Transmissions
Jun 19, 2021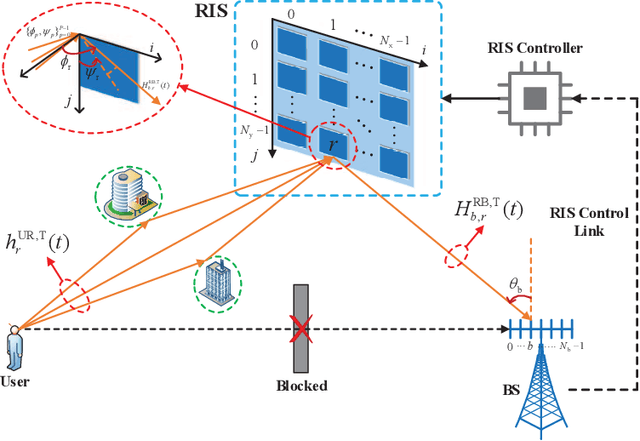
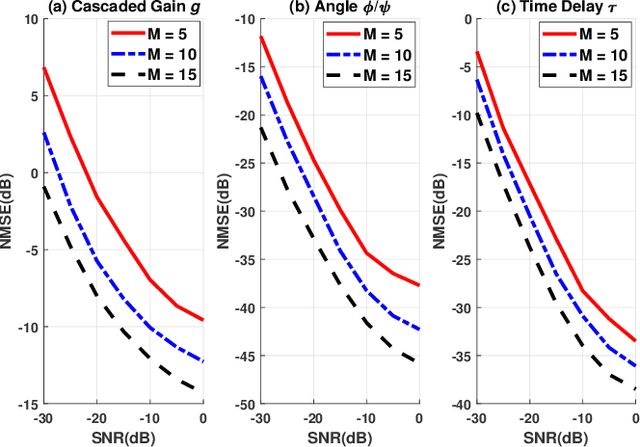
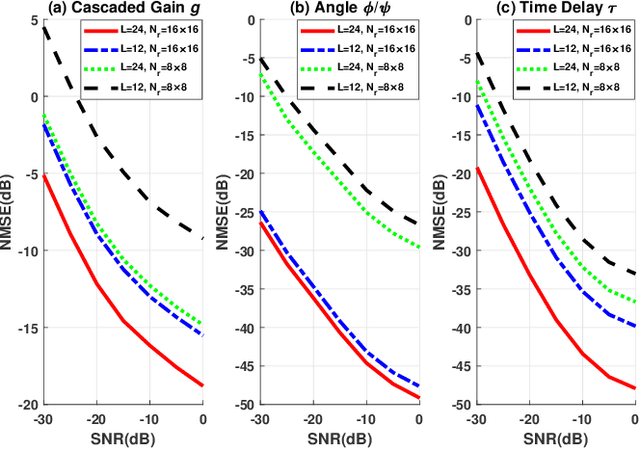
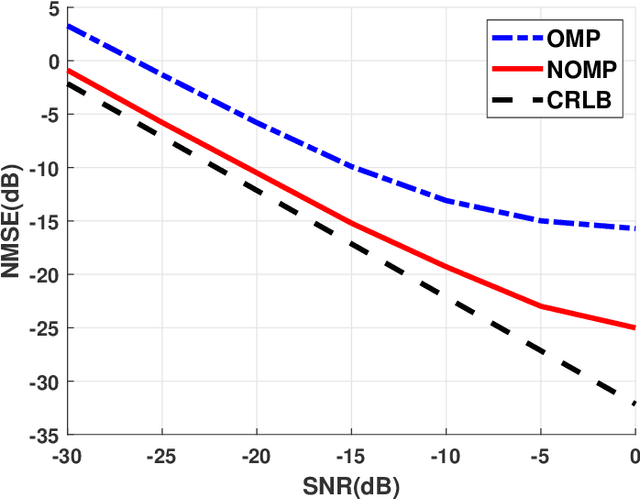
Channel estimation is challenging for the reconfigurable intelligence surface (RIS) assisted millimeter wave (mmWave) communications. Since the number of coefficients of the cascaded channels in such systems is closely dependent on the product of the number of base station antennas and the number of RIS elements, the pilot overhead would be prohibitively high. In this letter, we propose a cascaded channel estimation framework for an RIS assisted mmWave multiple-input multiple-output system, where the wideband effect on transmission model is considered. Then, we transform the wideband channel estimation into a parameter recovery problem and use a few pilot symbols to detect the channel parameters by the Newtonized orthogonal matching pursuit algorithm. Moreover, the Cramer-Rao lower bound on the channel estimation is introduced. Numerical results show the effectiveness of the proposed channel estimation scheme.
Joint Channel Estimation and Mixed-ADCs Allocation for Massive MIMO via Deep Learning
Jun 08, 2021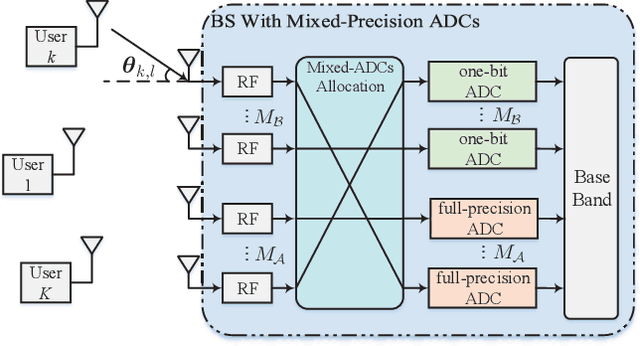
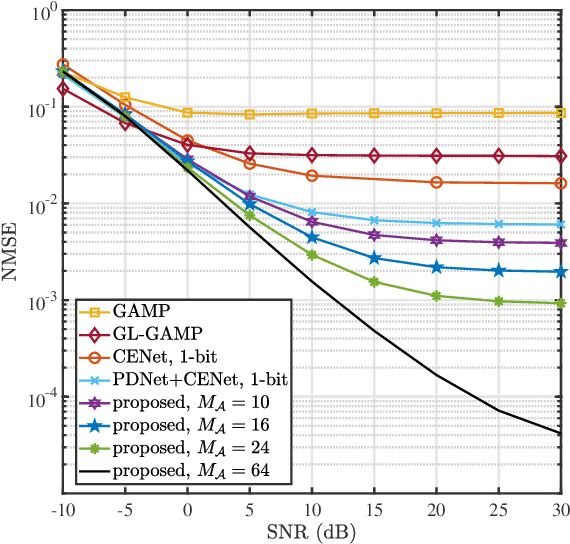
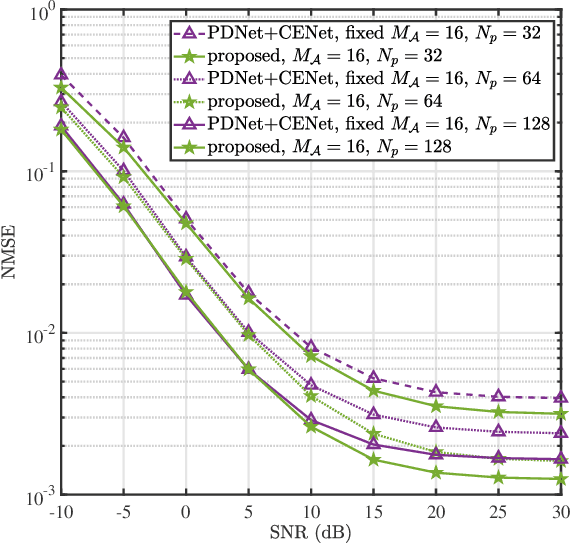
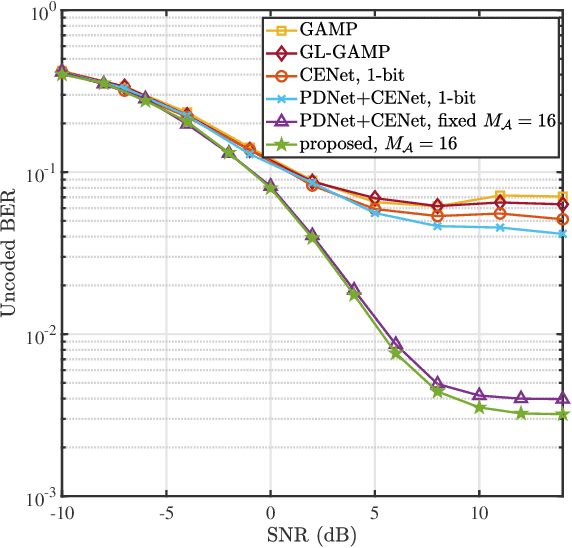
Millimeter wave (mmWave) multi-user massive multi-input multi-output (MIMO) is a promising technique for the next generation communication systems. However, the hardware cost and power consumption grow significantly as the number of radio frequency (RF) components increases, which hampers the deployment of practical massive MIMO systems. To address this issue and further facilitate the commercialization of massive MIMO, mixed analog-to-digital converters (ADCs) architecture has been considered, where parts of conventionally assumed full-resolution ADCs are replaced by one-bit ADCs. In this paper, we first propose a deep learning-based (DL) joint pilot design and channel estimation method for mixed-ADCs mmWave massive MIMO. Specifically, we devise a pilot design neural network whose weights directly represent the optimized pilots, and develop a Runge-Kutta model-driven densely connected network as the channel estimator. Instead of randomly assigning the mixed-ADCs, we then design a novel antenna selection network for mixed-ADCs allocation to further improve the channel estimation accuracy. Moreover, we adopt an autoencoder-inspired end-to-end architecture to jointly optimize the pilot design, channel estimation and mixed-ADCs allocation networks. Simulation results show that the proposed DL-based methods have advantages over the traditional channel estimators as well as the state-of-the-art networks.
Deep Unsupervised Learning for Joint Antenna Selection and Hybrid Beamforming
Jun 06, 2021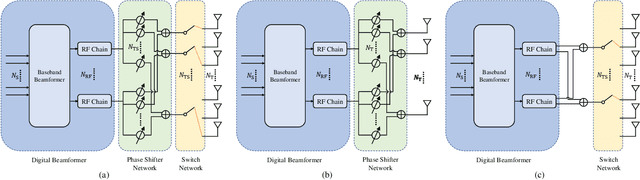
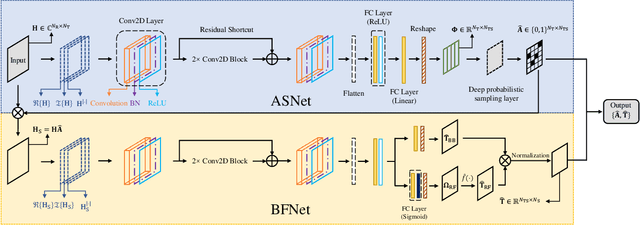
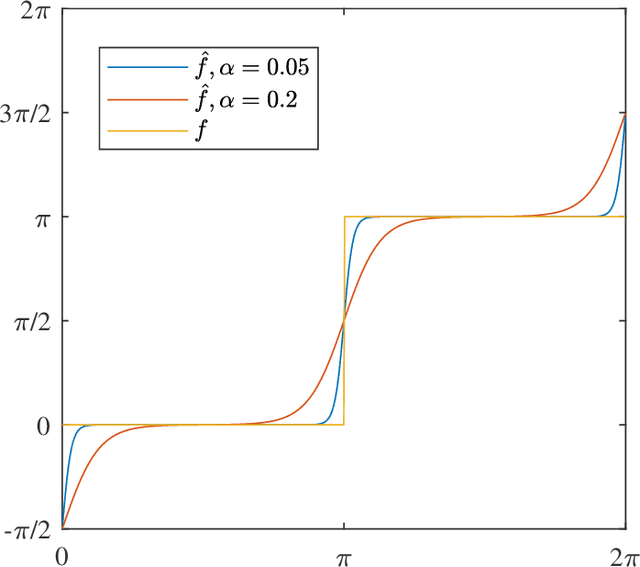
In this paper, we consider a massive multiple-input-multiple-output (MIMO) downlink system that improves the hardware efficiency by dynamically selecting the antenna subarray and utilizing 1-bit phase shifters for hybrid beamforming. To maximize the spectral efficiency, we propose a novel deep unsupervised learning-based approach that avoids the computationally prohibitive process of acquiring training labels. The proposed design has its input as the channel matrix and consists of two convolutional neural networks (CNNs). To enable unsupervised training, the problem constraints are embedded in the neural networks: the first CNN adopts deep probabilistic sampling, while the second CNN features a quantization layer designed for 1-bit phase shifters. The two networks can be trained jointly without labels by sharing an unsupervised loss function. We next propose a phased training approach to promote the convergence of the proposed networks. Simulation results demonstrate the advantage of the proposed approach over conventional optimization-based algorithms in terms of both achieved rate and computational complexity.
AIRIS: Artificial Intelligence Enhanced Signal Processing in Reconfigurable Intelligent Surface Communications
Jun 01, 2021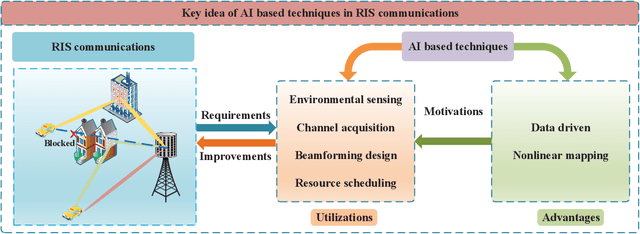
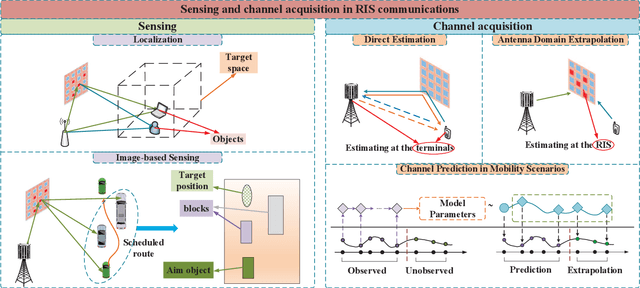
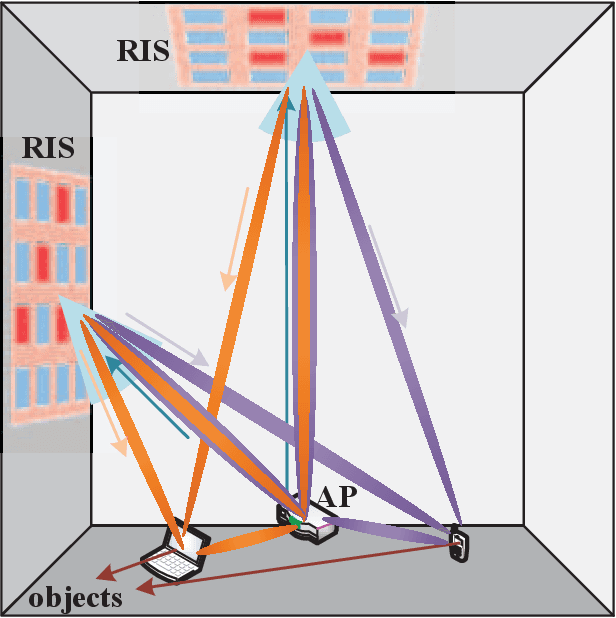
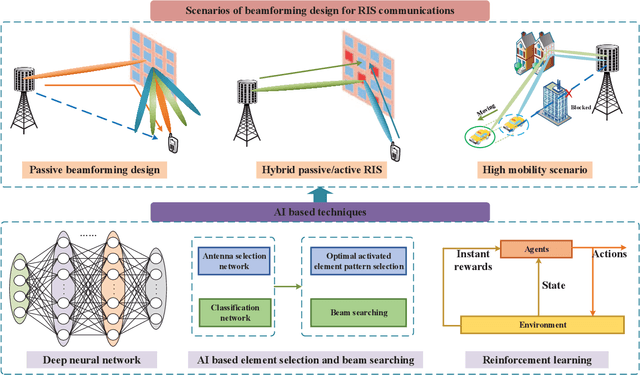
Reconfigurable intelligent surface (RIS) is an emerging meta-surface that can provide additional communications links through reflecting the signals, and has been recognized as a strong candidate of 6G mobile communications systems. Meanwhile, it has been recently admitted that implementing artificial intelligence (AI) into RIS communications will extensively benefit the reconfiguration capacity and enhance the robustness to complicated transmission environments. Besides the conventional model-driven approaches, AI can also deal with the existing signal processing problems in a data-driven manner via digging the inherent characteristic from the real data. Hence, AI is particularly suitable for the signal processing problems over RIS networks under unideal scenarios like modeling mismatching, insufficient resource, hardware impairment, as well as dynamical transmissions. As one of the earliest survey papers, we will introduce the merging of AI and RIS, called AIRIS, over various signal processing topics, including environmental sensing, channel acquisition, beamforming design, and resource scheduling, etc. We will also discuss the challenges of AIRIS and present some interesting future directions.