 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep CG2Real: Synthetic-to-Real Translation via Image Disentanglement
Mar 27, 2020
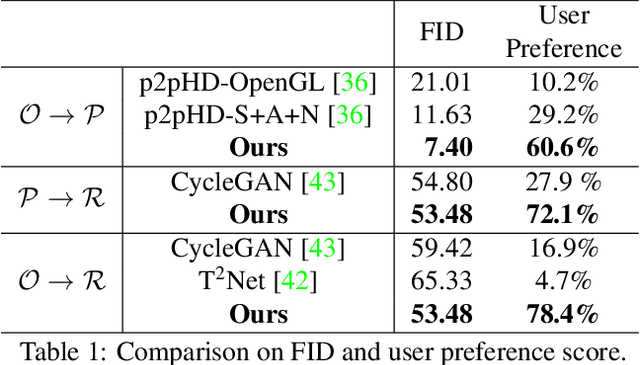
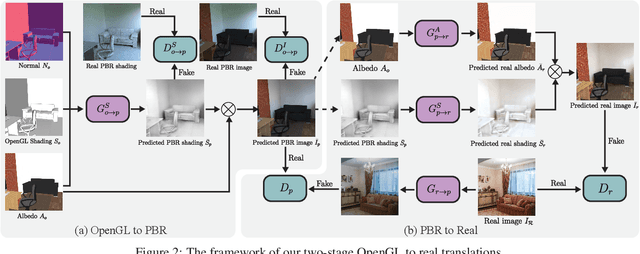
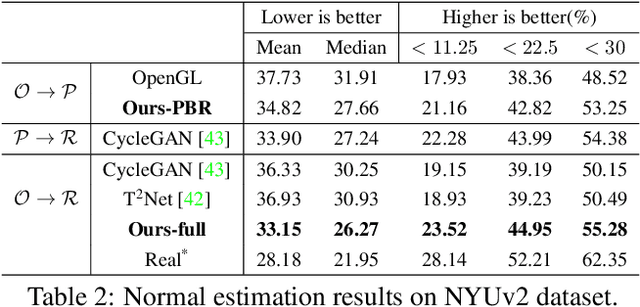
We present a method to improve the visual realism of low-quality, synthetic images, e.g. OpenGL renderings. Training an unpaired synthetic-to-real translation network in image space is severely under-constrained and produces visible artifacts. Instead, we propose a semi-supervised approach that operates on the disentangled shading and albedo layers of the image. Our two-stage pipeline first learns to predict accurate shading in a supervised fashion using physically-based renderings as targets, and further increases the realism of the textures and shading with an improved CycleGAN network. Extensive evaluations on the SUNCG indoor scene dataset demonstrate that our approach yields more realistic images compared to other state-of-the-art approaches. Furthermore, networks trained on our generated "real" images predict more accurate depth and normals than domain adaptation approaches, suggesting that improving the visual realism of the images can be more effective than imposing task-specific losses.
Basis Prediction Networks for Effective Burst Denoising with Large Kernels
Dec 09, 2019
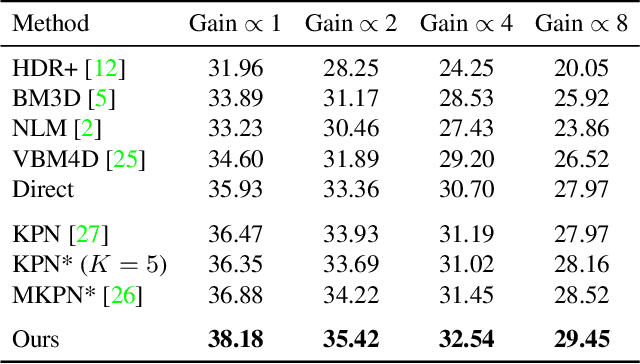
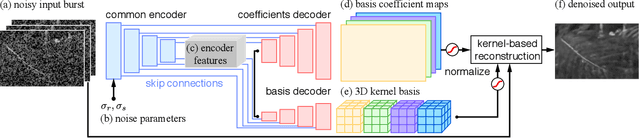
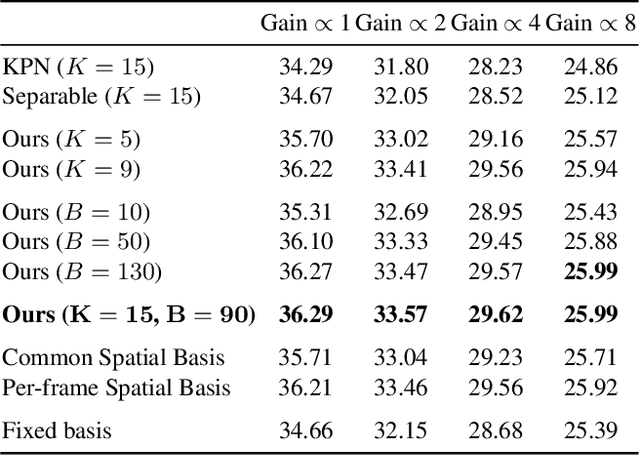
Bursts of images exhibit significant self-similarity across both time and space. This motivates a representation of the kernels as linear combinations of a small set of basis elements. To this end, we introduce a novel basis prediction network that, given an input burst, predicts a set of global basis kernels --- shared within the image --- and the corresponding mixing coefficients --- which are specific to individual pixels. Compared to other state-of-the-art deep learning techniques that output a large tensor of per-pixel spatiotemporal kernels, our formulation substantially reduces the dimensionality of the network output. This allows us to effectively exploit larger denoising kernels and achieve significant quality improvements (over 1dB PSNR) at reduced run-times compared to state-of-the-art methods.
Scaling Object Detection by Transferring Classification Weights
Sep 15, 2019
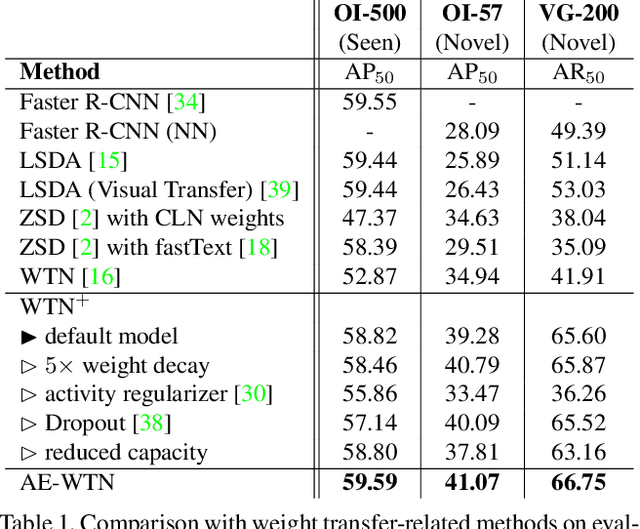
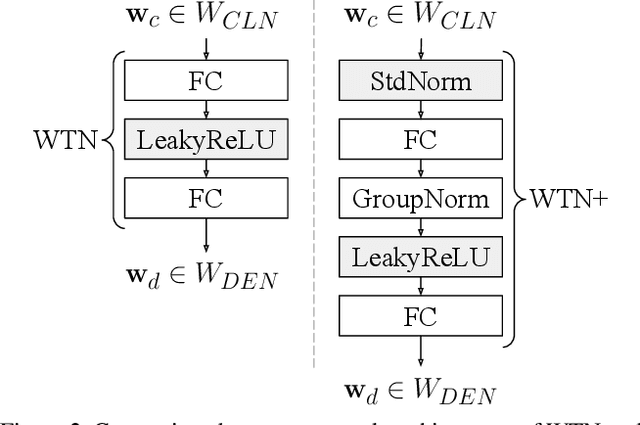
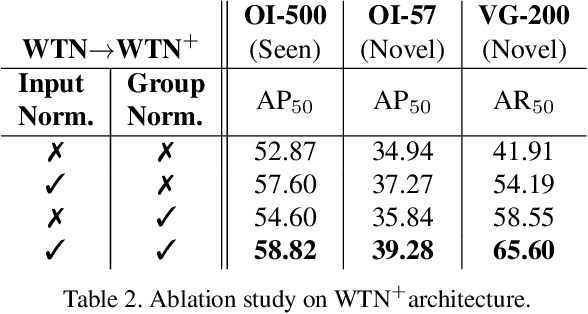
Large scale object detection datasets are constantly increasing their size in terms of the number of classes and annotations count. Yet, the number of object-level categories annotated in detection datasets is an order of magnitude smaller than image-level classification labels. State-of-the art object detection models are trained in a supervised fashion and this limits the number of object classes they can detect. In this paper, we propose a novel weight transfer network (WTN) to effectively and efficiently transfer knowledge from classification network's weights to detection network's weights to allow detection of novel classes without box supervision. We first introduce input and feature normalization schemes to curb the under-fitting during training of a vanilla WTN. We then propose autoencoder-WTN (AE-WTN) which uses reconstruction loss to preserve classification network's information over all classes in the target latent space to ensure generalization to novel classes. Compared to vanilla WTN, AE-WTN obtains absolute performance gains of 6% on two Open Images evaluation sets with 500 seen and 57 novel classes respectively, and 25% on a Visual Genome evaluation set with 200 novel classes. The code is available at https://github.com/xternalz/AE-WTN.
Deblurring Face Images using Uncertainty Guided Multi-Stream Semantic Networks
Jul 30, 2019
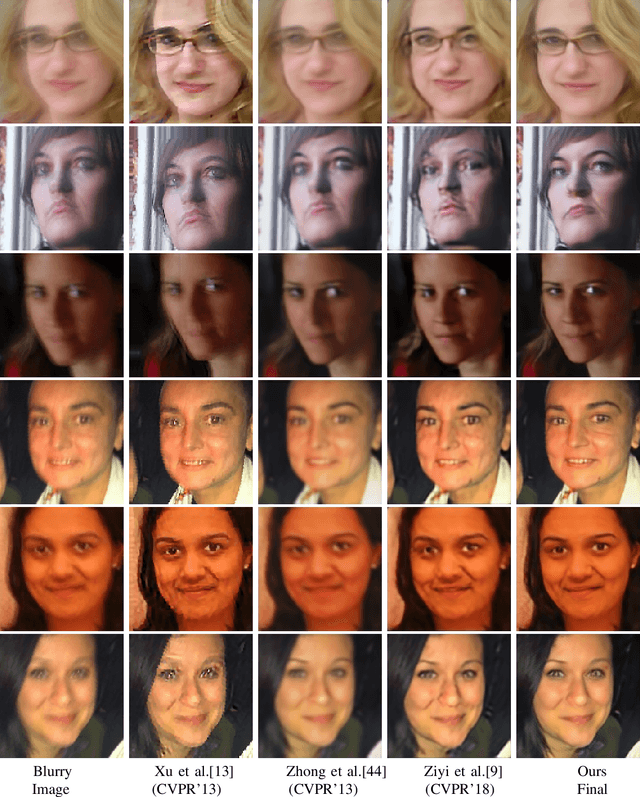


We propose a novel multi-stream architecture and training methodology that exploits semantic labels for facial image deblurring. The proposed Uncertainty Guided Multi-Stream Semantic Network (UMSN) processes regions belonging to each semantic class independently and learns to combine their outputs into the final deblurred result. Pixel-wise semantic labels are obtained using a segmentation network. A predicted confidence measure is used during training to guide the network towards challenging regions of the human face such as the eyes and nose. The entire network is trained in an end-to-end fashion. Comprehensive experiments on three different face datasets demonstrate that the proposed method achieves significant improvements over the recent state-of-the-art face deblurring methods. Code is available at: https://github.com/rajeevyasarla/UMSN-Face-Deblurring
The 2019 DAVIS Challenge on VOS: Unsupervised Multi-Object Segmentation
May 02, 2019

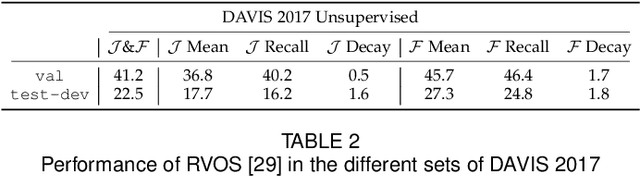
We present the 2019 DAVIS Challenge on Video Object Segmentation, the third edition of the DAVIS Challenge series, a public competition designed for the task of Video Object Segmentation (VOS). In addition to the original semi-supervised track and the interactive track introduced in the previous edition, a new unsupervised multi-object track will be featured this year. In the newly introduced track, participants are asked to provide non-overlapping object proposals on each image, along with an identifier linking them between frames (i.e. video object proposals), without any test-time human supervision (no scribbles or masks provided on the test video). In order to do so, we have re-annotated the train and val sets of DAVIS 2017 in a concise way that facilitates the unsupervised track, and created new test-dev and test-challenge sets for the competition. Definitions, rules, and evaluation metrics for the unsupervised track are described in detail in this paper.
Web Stereo Video Supervision for Depth Prediction from Dynamic Scenes
Apr 25, 2019
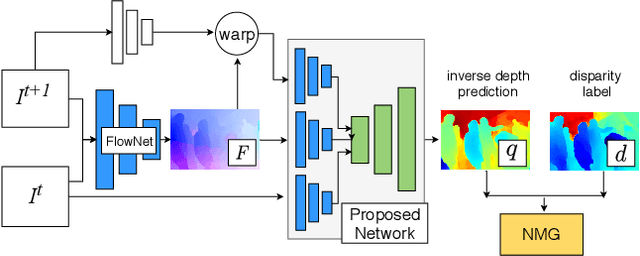
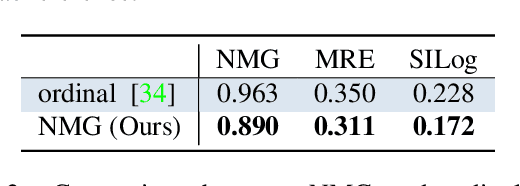

We present a fully data-driven method to compute depth from diverse monocular video sequences that contain large amounts of non-rigid objects, e.g., people. In order to learn reconstruction cues for non-rigid scenes, we introduce a new dataset consisting of stereo videos scraped in-the-wild. This dataset has a wide variety of scene types, and features large amounts of nonrigid objects, especially people. From this, we compute disparity maps to be used as supervision to train our approach. We propose a loss function that allows us to generate a depth prediction even with unknown camera intrinsics and stereo baselines in the dataset. We validate the use of large amounts of Internet video by evaluating our method on existing video datasets with depth supervision, including SINTEL, and KITTI, and show that our approach generalizes better to natural scenes.
On Regularized Losses for Weakly-supervised CNN Segmentation
Apr 10, 2018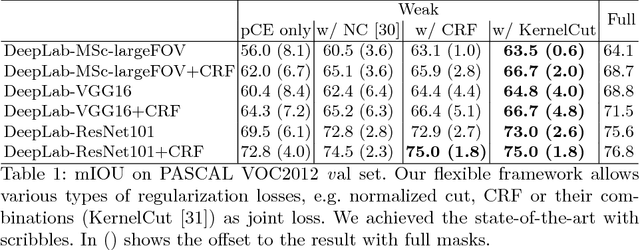
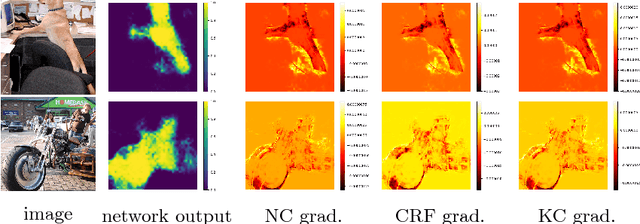
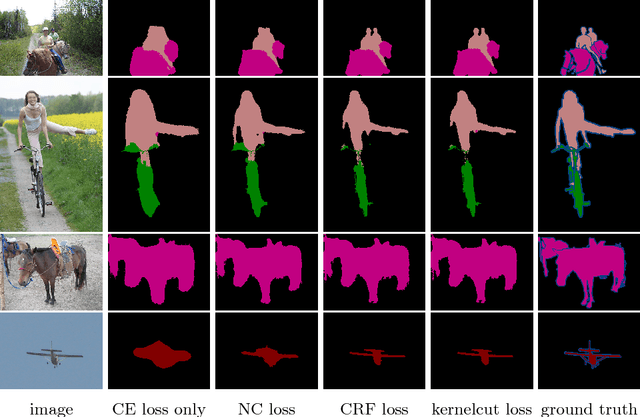
Minimization of regularized losses is a principled approach to weak supervision well-established in deep learning, in general. However, it is largely overlooked in semantic segmentation currently dominated by methods mimicking full supervision via "fake" fully-labeled training masks (proposals) generated from available partial input. To obtain such full masks the typical methods explicitly use standard regularization techniques for "shallow" segmentation, e.g. graph cuts or dense CRFs. In contrast, we integrate such standard regularizers directly into the loss functions over partial input. This approach simplifies weakly-supervised training by avoiding extra MRF/CRF inference steps or layers explicitly generating full masks, while improving both the quality and efficiency of training. This paper proposes and experimentally compares different losses integrating MRF/CRF regularization terms. We juxtapose our regularized losses with earlier proposal-generation methods using explicit regularization steps or layers. Our approach achieves state-of-the-art accuracy in semantic segmentation with near full-supervision quality.
A Fully Progressive Approach to Single-Image Super-Resolution
Apr 10, 2018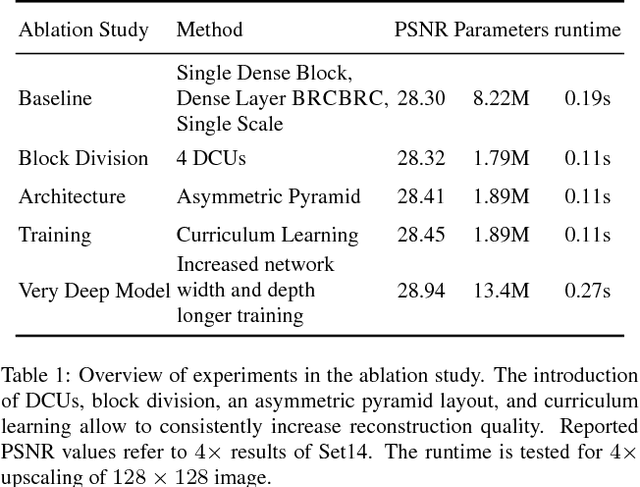
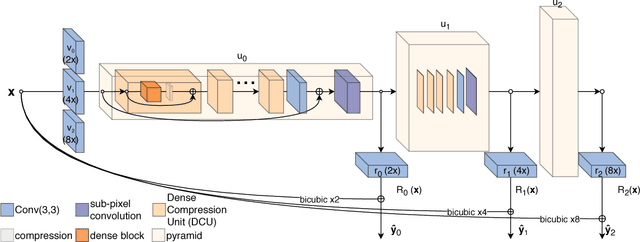

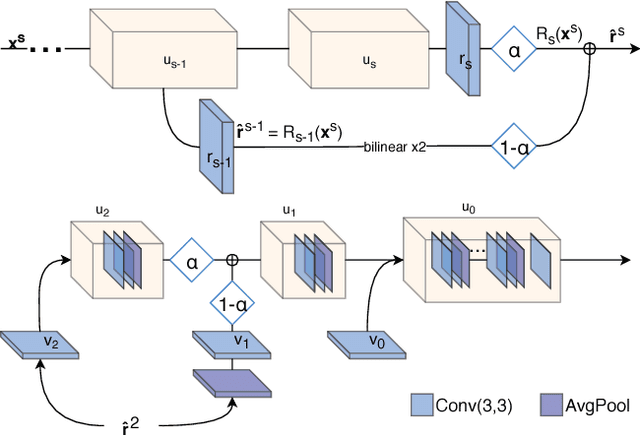
Recent deep learning approaches to single image super-resolution have achieved impressive results in terms of traditional error measures and perceptual quality. However, in each case it remains challenging to achieve high quality results for large upsampling factors. To this end, we propose a method (ProSR) that is progressive both in architecture and training: the network upsamples an image in intermediate steps, while the learning process is organized from easy to hard, as is done in curriculum learning. To obtain more photorealistic results, we design a generative adversarial network (GAN), named ProGanSR, that follows the same progressive multi-scale design principle. This not only allows to scale well to high upsampling factors (e.g., 8x) but constitutes a principled multi-scale approach that increases the reconstruction quality for all upsampling factors simultaneously. In particular ProSR ranks 2nd in terms of SSIM and 4th in terms of PSNR in the NTIRE2018 SISR challenge [34]. Compared to the top-ranking team, our model is marginally lower, but runs 5 times faster.
Normalized Cut Loss for Weakly-supervised CNN Segmentation
Apr 04, 2018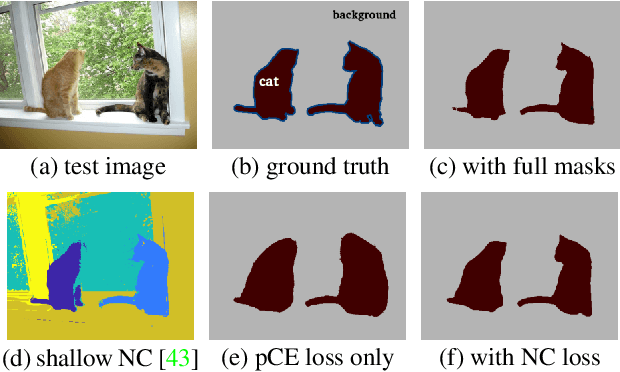
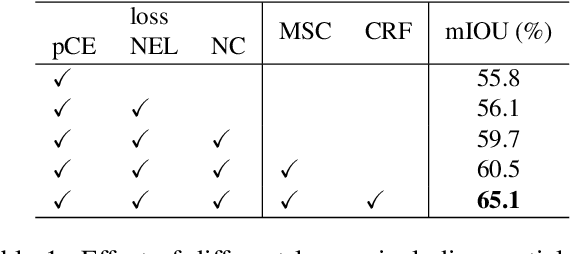
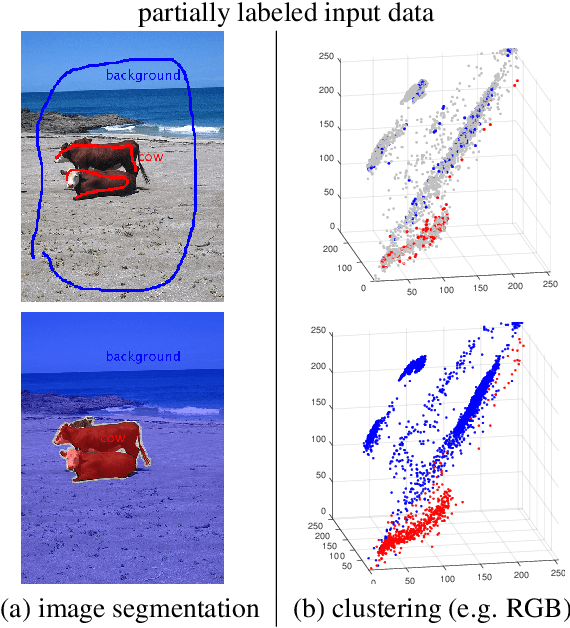
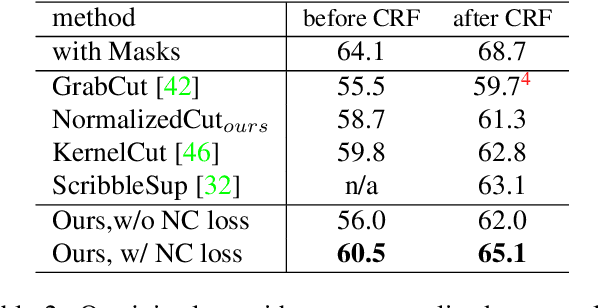
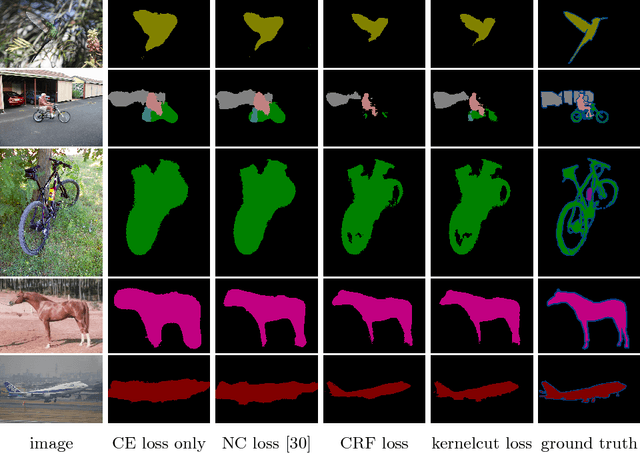
Most recent semantic segmentation methods train deep convolutional neural networks with fully annotated masks requiring pixel-accuracy for good quality training. Common weakly-supervised approaches generate full masks from partial input (e.g. scribbles or seeds) using standard interactive segmentation methods as preprocessing. But, errors in such masks result in poorer training since standard loss functions (e.g. cross-entropy) do not distinguish seeds from potentially mislabeled other pixels. Inspired by the general ideas in semi-supervised learning, we address these problems via a new principled loss function evaluating network output with criteria standard in "shallow" segmentation, e.g. normalized cut. Unlike prior work, the cross entropy part of our loss evaluates only seeds where labels are known while normalized cut softly evaluates consistency of all pixels. We focus on normalized cut loss where dense Gaussian kernel is efficiently implemented in linear time by fast Bilateral filtering. Our normalized cut loss approach to segmentation brings the quality of weakly-supervised training significantly closer to fully supervised methods.
The 2018 DAVIS Challenge on Video Object Segmentation
Mar 27, 2018

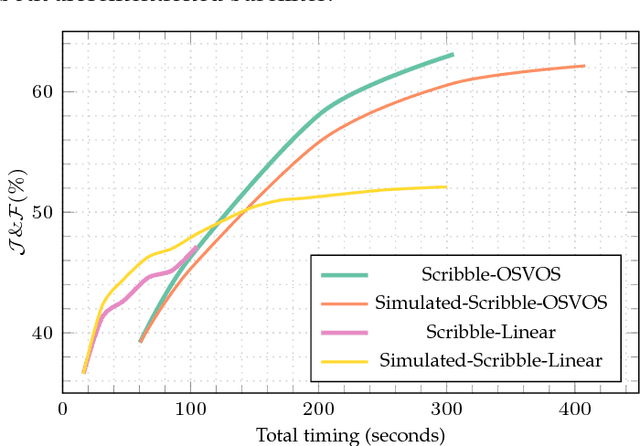
We present the 2018 DAVIS Challenge on Video Object Segmentation, a public competition specifically designed for the task of video object segmentation. It builds upon the DAVIS 2017 dataset, which was presented in the previous edition of the DAVIS Challenge, and added 100 videos with multiple objects per sequence to the original DAVIS 2016 dataset. Motivated by the analysis of the results of the 2017 edition, the main track of the competition will be the same than in the previous edition (segmentation given the full mask of the objects in the first frame -- semi-supervised scenario). This edition, however, also adds an interactive segmentation teaser track, where the participants will interact with a web service simulating the input of a human that provides scribbles to iteratively improve the result.