 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAre Big Recommendation Models Fair to Cold Users?
Feb 28, 2022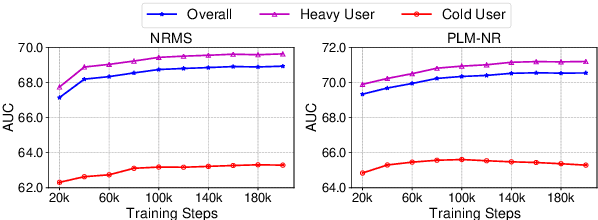
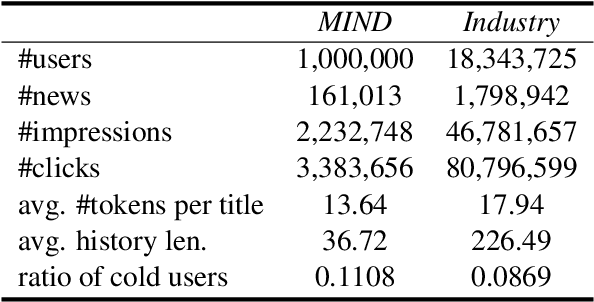
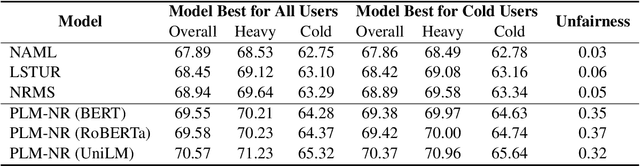
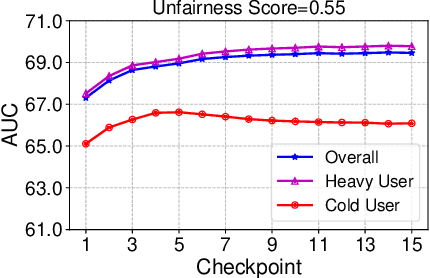
Big models are widely used by online recommender systems to boost recommendation performance. They are usually learned on historical user behavior data to infer user interest and predict future user behaviors (e.g., clicks). In fact, the behaviors of heavy users with more historical behaviors can usually provide richer clues than cold users in interest modeling and future behavior prediction. Big models may favor heavy users by learning more from their behavior patterns and bring unfairness to cold users. In this paper, we study whether big recommendation models are fair to cold users. We empirically demonstrate that optimizing the overall performance of big recommendation models may lead to unfairness to cold users in terms of performance degradation. To solve this problem, we propose a BigFair method based on self-distillation, which uses the model predictions on original user data as a teacher to regularize predictions on augmented data with randomly dropped user behaviors, which can encourage the model to fairly capture interest distributions of heavy and cold users. Experiments on two datasets show that BigFair can effectively improve the performance fairness of big recommendation models on cold users without harming the performance on heavy users.
Quality-aware News Recommendation
Feb 28, 2022
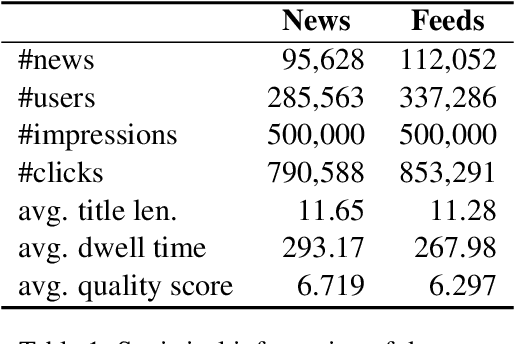
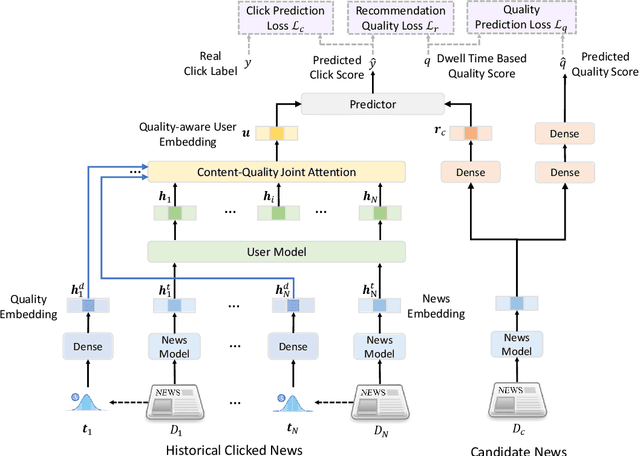
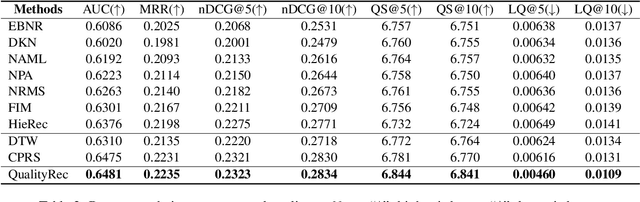
News recommendation is a core technique used by many online news platforms. Recommending high-quality news to users is important for keeping good user experiences and news platforms' reputations. However, existing news recommendation methods mainly aim to optimize news clicks while ignoring the quality of news they recommended, which may lead to recommending news with uninformative content or even clickbaits. In this paper, we propose a quality-aware news recommendation method named QualityRec that can effectively improve the quality of recommended news. In our approach, we first propose an effective news quality evaluation method based on the distributions of users' reading dwell time on news. Next, we propose to incorporate news quality information into user interest modeling by designing a content-quality attention network to select clicked news based on both news semantics and qualities. We further train the recommendation model with an auxiliary news quality prediction task to learn quality-aware recommendation model, and we add a recommendation quality regularization loss to encourage the model to recommend higher-quality news. Extensive experiments on two real-world datasets show that QualityRec can effectively improve the overall quality of recommended news and reduce the recommendation of low-quality news, with even slightly better recommendation accuracy.
Game of Privacy: Towards Better Federated Platform Collaboration under Privacy Restriction
Feb 24, 2022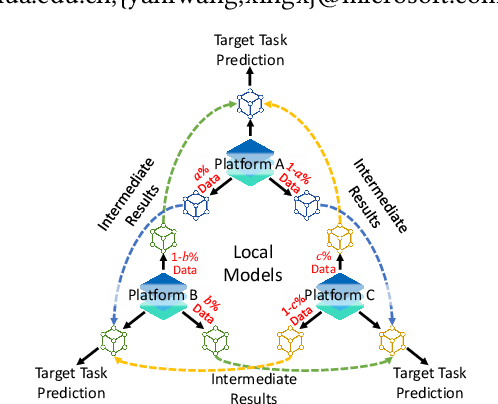
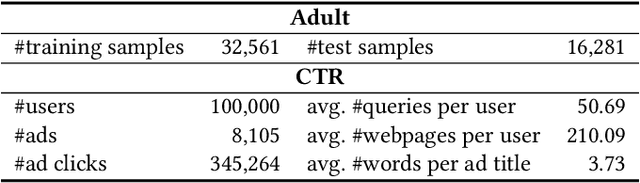
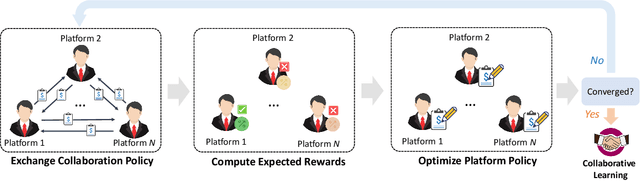
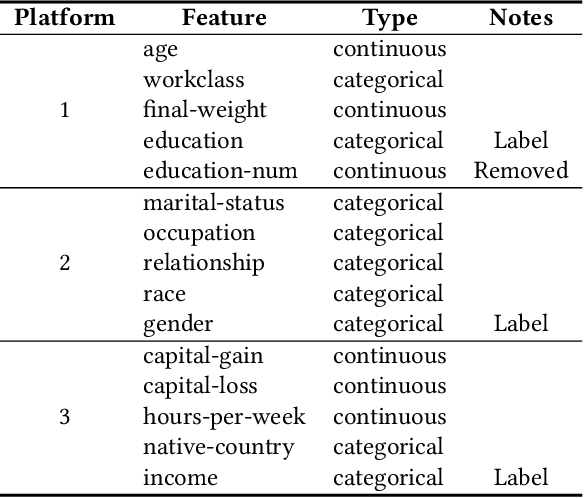
Vertical federated learning (VFL) aims to train models from cross-silo data with different feature spaces stored on different platforms. Existing VFL methods usually assume all data on each platform can be used for model training. However, due to the intrinsic privacy risks of federated learning, the total amount of involved data may be constrained. In addition, existing VFL studies usually assume only one platform has task labels and can benefit from the collaboration, making it difficult to attract other platforms to join in the collaborative learning. In this paper, we study the platform collaboration problem in VFL under privacy constraint. We propose to incent different platforms through a reciprocal collaboration, where all platforms can exploit multi-platform information in the VFL framework to benefit their own tasks. With limited privacy budgets, each platform needs to wisely allocate its data quotas for collaboration with other platforms. Thereby, they naturally form a multi-party game. There are two core problems in this game, i.e., how to appraise other platforms' data value to compute game rewards and how to optimize policies to solve the game. To evaluate the contributions of other platforms' data, each platform offers a small amount of "deposit" data to participate in the VFL. We propose a performance estimation method to predict the expected model performance when involving different amount combinations of inter-platform data. To solve the game, we propose a platform negotiation method that simulates the bargaining among platforms and locally optimizes their policies via gradient descent. Extensive experiments on two real-world datasets show that our approach can effectively facilitate the collaborative exploitation of multi-platform data in VFL under privacy restrictions.
No One Left Behind: Inclusive Federated Learning over Heterogeneous Devices
Feb 16, 2022
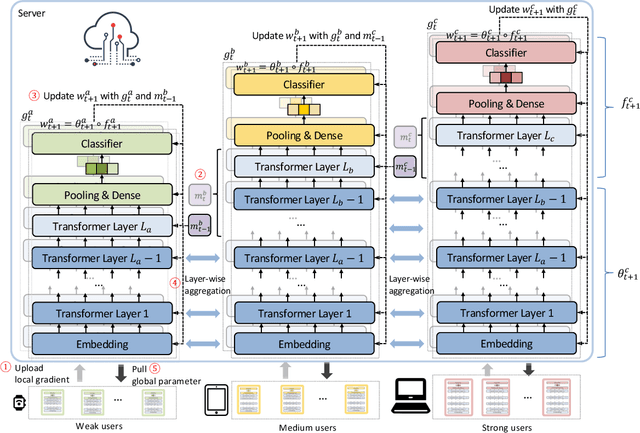

Federated learning (FL) is an important paradigm for training global models from decentralized data in a privacy-preserving way. Existing FL methods usually assume the global model can be trained on any participating client. However, in real applications, the devices of clients are usually heterogeneous, and have different computing power. Although big models like BERT have achieved huge success in AI, it is difficult to apply them to heterogeneous FL with weak clients. The straightforward solutions like removing the weak clients or using a small model to fit all clients will lead to some problems, such as under-representation of dropped clients and inferior accuracy due to data loss or limited model representation ability. In this work, we propose InclusiveFL, a client-inclusive federated learning method to handle this problem. The core idea of InclusiveFL is to assign models of different sizes to clients with different computing capabilities, bigger models for powerful clients and smaller ones for weak clients. We also propose an effective method to share the knowledge among multiple local models with different sizes. In this way, all the clients can participate in the model learning in FL, and the final model can be big and powerful enough. Besides, we propose a momentum knowledge distillation method to better transfer knowledge in big models on powerful clients to the small models on weak clients. Extensive experiments on many real-world benchmark datasets demonstrate the effectiveness of the proposed method in learning accurate models from clients with heterogeneous devices under the FL framework.
UA-FedRec: Untargeted Attack on Federated News Recommendation
Feb 14, 2022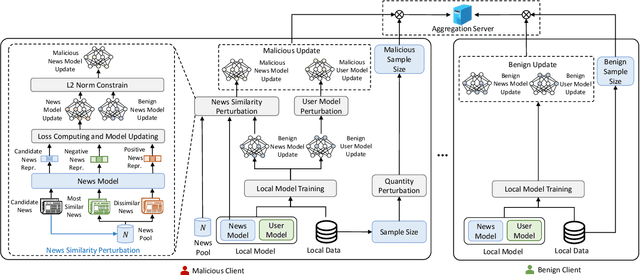
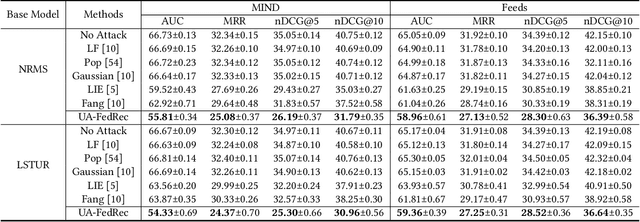
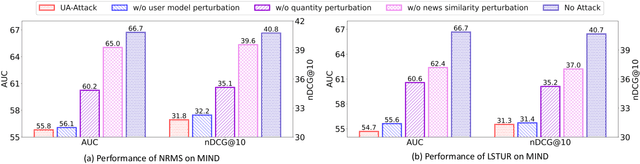
News recommendation is critical for personalized news distribution. Federated news recommendation enables collaborative model learning from many clients without sharing their raw data. It is promising for privacy-preserving news recommendation. However, the security of federated news recommendation is still unclear. In this paper, we study this problem by proposing an untargeted attack called UA-FedRec. By exploiting the prior knowledge of news recommendation and federated learning, UA-FedRec can effectively degrade the model performance with a small percentage of malicious clients. First, the effectiveness of news recommendation highly depends on user modeling and news modeling. We design a news similarity perturbation method to make representations of similar news farther and those of dissimilar news closer to interrupt news modeling, and propose a user model perturbation method to make malicious user updates in opposite directions of benign updates to interrupt user modeling. Second, updates from different clients are typically aggregated by weighted-averaging based on their sample sizes. We propose a quantity perturbation method to enlarge sample sizes of malicious clients in a reasonable range to amplify the impact of malicious updates. Extensive experiments on two real-world datasets show that UA-FedRec can effectively degrade the accuracy of existing federated news recommendation methods, even when defense is applied. Our study reveals a critical security issue in existing federated news recommendation systems and calls for research efforts to address the issue.
FedAttack: Effective and Covert Poisoning Attack on Federated Recommendation via Hard Sampling
Feb 10, 2022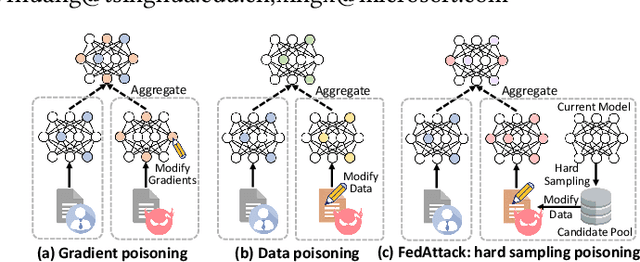

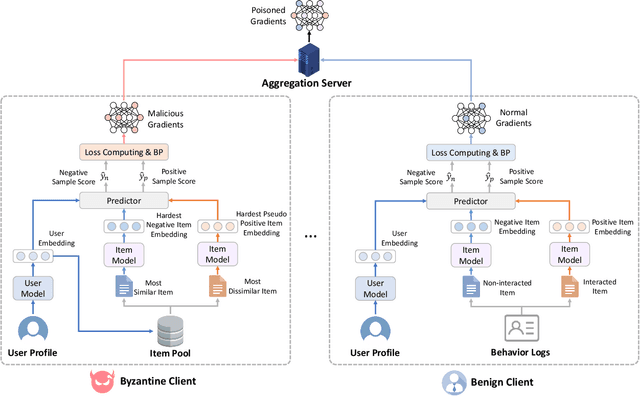
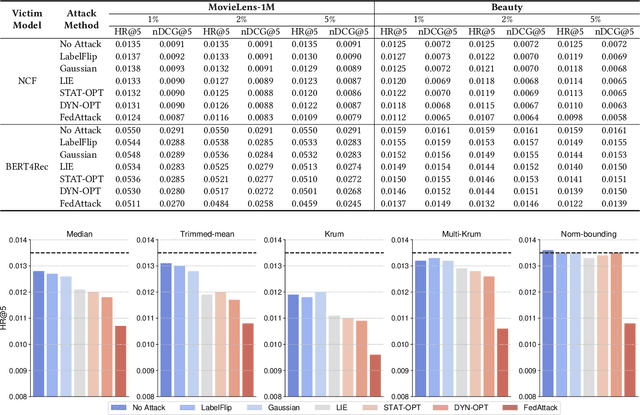
Federated learning (FL) is a feasible technique to learn personalized recommendation models from decentralized user data. Unfortunately, federated recommender systems are vulnerable to poisoning attacks by malicious clients. Existing recommender system poisoning methods mainly focus on promoting the recommendation chances of target items due to financial incentives. In fact, in real-world scenarios, the attacker may also attempt to degrade the overall performance of recommender systems. However, existing general FL poisoning methods for degrading model performance are either ineffective or not concealed in poisoning federated recommender systems. In this paper, we propose a simple yet effective and covert poisoning attack method on federated recommendation, named FedAttack. Its core idea is using globally hardest samples to subvert model training. More specifically, the malicious clients first infer user embeddings based on local user profiles. Next, they choose the candidate items that are most relevant to the user embeddings as hardest negative samples, and find the candidates farthest from the user embeddings as hardest positive samples. The model gradients inferred from these poisoned samples are then uploaded to the server for aggregation and model update. Since the behaviors of malicious clients are somewhat similar to users with diverse interests, they cannot be effectively distinguished from normal clients by the server. Extensive experiments on two benchmark datasets show that FedAttack can effectively degrade the performance of various federated recommender systems, meanwhile cannot be effectively detected nor defended by many existing methods.
Protecting Intellectual Property of Language Generation APIs with Lexical Watermark
Dec 05, 2021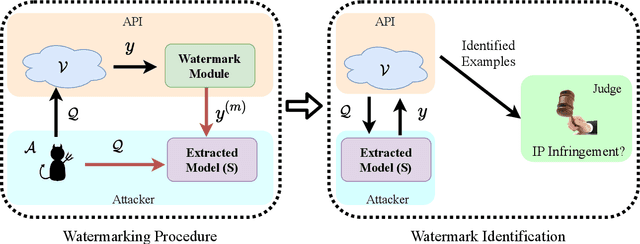
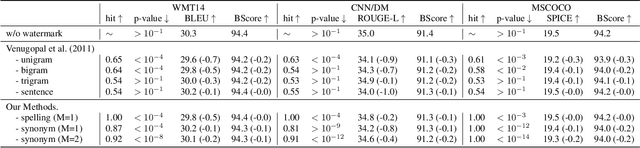
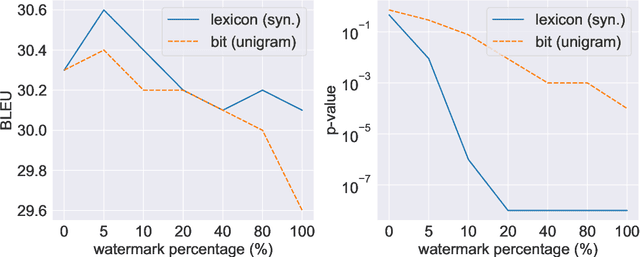
Nowadays, due to the breakthrough in natural language generation (NLG), including machine translation, document summarization, image captioning, etc NLG models have been encapsulated in cloud APIs to serve over half a billion people worldwide and process over one hundred billion word generations per day. Thus, NLG APIs have already become essential profitable services in many commercial companies. Due to the substantial financial and intellectual investments, service providers adopt a pay-as-you-use policy to promote sustainable market growth. However, recent works have shown that cloud platforms suffer from financial losses imposed by model extraction attacks, which aim to imitate the functionality and utility of the victim services, thus violating the intellectual property (IP) of cloud APIs. This work targets at protecting IP of NLG APIs by identifying the attackers who have utilized watermarked responses from the victim NLG APIs. However, most existing watermarking techniques are not directly amenable for IP protection of NLG APIs. To bridge this gap, we first present a novel watermarking method for text generation APIs by conducting lexical modification to the original outputs. Compared with the competitive baselines, our watermark approach achieves better identifiable performance in terms of p-value, with fewer semantic losses. In addition, our watermarks are more understandable and intuitive to humans than the baselines. Finally, the empirical studies show our approach is also applicable to queries from different domains, and is effective on the attacker trained on a mixture of the corpus which includes less than 10\% watermarked samples.
Tiny-NewsRec: Efficient and Effective PLM-based News Recommendation
Dec 02, 2021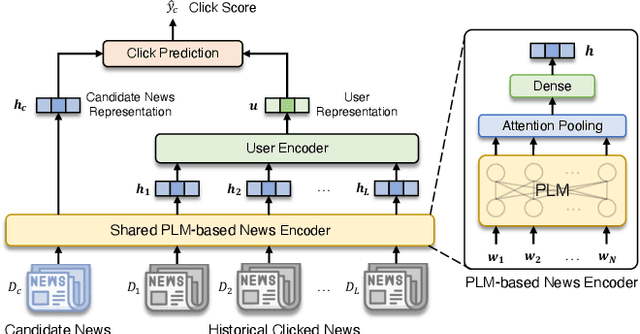
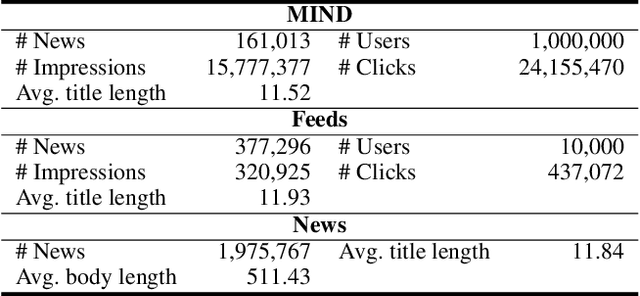
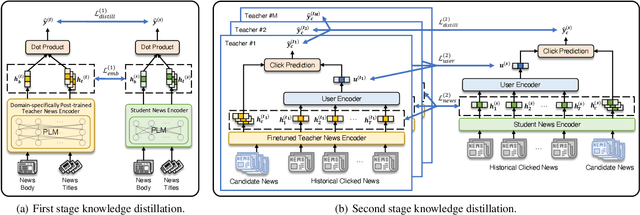
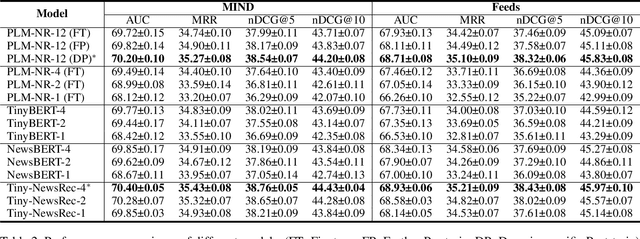
Personalized news recommendation has been widely adopted to improve user experience. Recently, pre-trained language models (PLMs) have demonstrated the great capability of natural language understanding and the potential of improving news modeling for news recommendation. However, existing PLMs are usually pre-trained on general corpus such as BookCorpus and Wikipedia, which have some gaps with the news domain. Directly finetuning PLMs with the news recommendation task may be sub-optimal for news understanding. Besides, PLMs usually contain a large volume of parameters and have high computational overhead, which imposes a great burden on the low-latency online services. In this paper, we propose Tiny-NewsRec, which can improve both the effectiveness and the efficiency of PLM-based news recommendation. In order to reduce the domain gap between general corpora and the news data, we propose a self-supervised domain-specific post-training method to adapt the generally pre-trained language models to the news domain with the task of news title and news body matching. To improve the efficiency of PLM-based news recommendation while maintaining the performance, we propose a two-stage knowledge distillation method. In the first stage, we use the domain-specific teacher PLM to guide the student model for news semantic modeling. In the second stage, we use a multi-teacher knowledge distillation framework to transfer the comprehensive knowledge from a set of teacher models finetuned for news recommendation to the student. Experiments on two real-world datasets show that our methods can achieve better performance in news recommendation with smaller models.
Efficient-FedRec: Efficient Federated Learning Framework for Privacy-Preserving News Recommendation
Sep 16, 2021
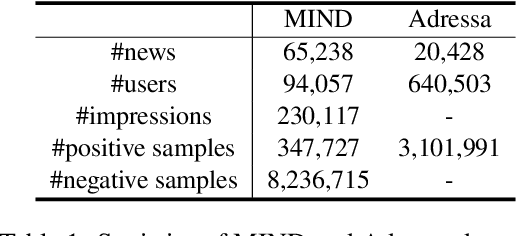
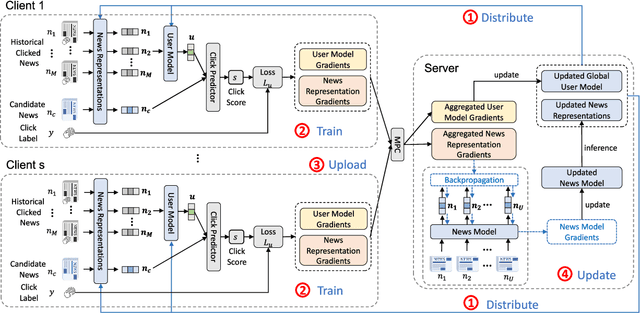
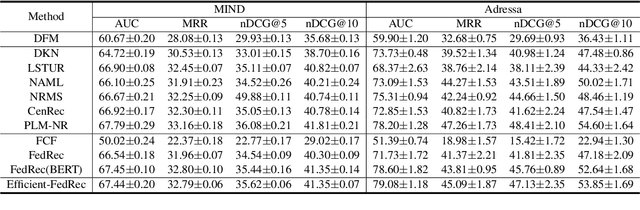
News recommendation is critical for personalized news access. Most existing news recommendation methods rely on centralized storage of users' historical news click behavior data, which may lead to privacy concerns and hazards. Federated Learning is a privacy-preserving framework for multiple clients to collaboratively train models without sharing their private data. However, the computation and communication cost of directly learning many existing news recommendation models in a federated way are unacceptable for user clients. In this paper, we propose an efficient federated learning framework for privacy-preserving news recommendation. Instead of training and communicating the whole model, we decompose the news recommendation model into a large news model maintained in the server and a light-weight user model shared on both server and clients, where news representations and user model are communicated between server and clients. More specifically, the clients request the user model and news representations from the server, and send their locally computed gradients to the server for aggregation. The server updates its global user model with the aggregated gradients, and further updates its news model to infer updated news representations. Since the local gradients may contain private information, we propose a secure aggregation method to aggregate gradients in a privacy-preserving way. Experiments on two real-world datasets show that our method can reduce the computation and communication cost on clients while keep promising model performance.
Uni-FedRec: A Unified Privacy-Preserving News Recommendation Framework for Model Training and Online Serving
Sep 11, 2021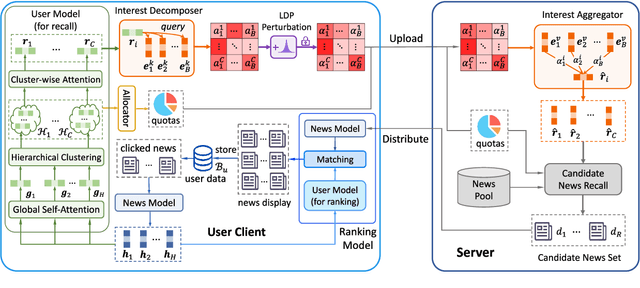
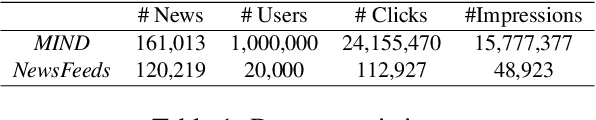
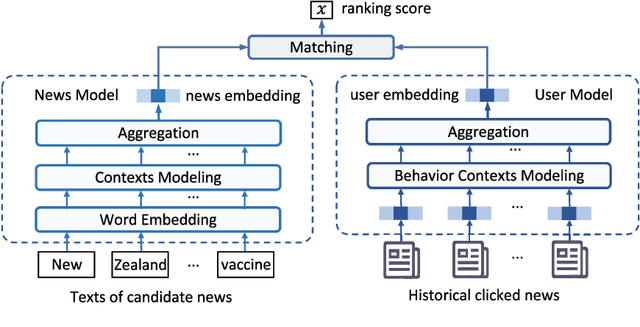
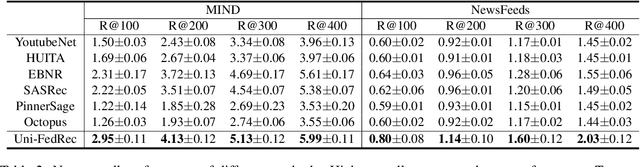
News recommendation is important for personalized online news services. Most existing news recommendation methods rely on centrally stored user behavior data to both train models offline and provide online recommendation services. However, user data is usually highly privacy-sensitive, and centrally storing them may raise privacy concerns and risks. In this paper, we propose a unified news recommendation framework, which can utilize user data locally stored in user clients to train models and serve users in a privacy-preserving way. Following a widely used paradigm in real-world recommender systems, our framework contains two stages. The first one is for candidate news generation (i.e., recall) and the second one is for candidate news ranking (i.e., ranking). At the recall stage, each client locally learns multiple interest representations from clicked news to comprehensively model user interests. These representations are uploaded to the server to recall candidate news from a large news pool, which are further distributed to the user client at the ranking stage for personalized news display. In addition, we propose an interest decomposer-aggregator method with perturbation noise to better protect private user information encoded in user interest representations. Besides, we collaboratively train both recall and ranking models on the data decentralized in a large number of user clients in a privacy-preserving way. Experiments on two real-world news datasets show that our method can outperform baseline methods and effectively protect user privacy.