 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThink Natively: Unlocking Multilingual Reasoning with Consistency-Enhanced Reinforcement Learning
Oct 08, 2025



Large Reasoning Models (LRMs) have achieved remarkable performance on complex reasoning tasks by adopting the "think-then-answer" paradigm, which enhances both accuracy and interpretability. However, current LRMs exhibit two critical limitations when processing non-English languages: (1) They often struggle to maintain input-output language consistency; (2) They generally perform poorly with wrong reasoning paths and lower answer accuracy compared to English. These limitations significantly degrade the user experience for non-English speakers and hinder the global deployment of LRMs. To address these limitations, we propose M-Thinker, which is trained by the GRPO algorithm that involves a Language Consistency (LC) reward and a novel Cross-lingual Thinking Alignment (CTA) reward. Specifically, the LC reward defines a strict constraint on the language consistency between the input, thought, and answer. Besides, the CTA reward compares the model's non-English reasoning paths with its English reasoning path to transfer its own reasoning capability from English to non-English languages. Through an iterative RL procedure, our M-Thinker-1.5B/7B models not only achieve nearly 100% language consistency and superior performance on two multilingual benchmarks (MMATH and PolyMath), but also exhibit excellent generalization on out-of-domain languages.
CM-Align: Consistency-based Multilingual Alignment for Large Language Models
Sep 10, 2025Current large language models (LLMs) generally show a significant performance gap in alignment between English and other languages. To bridge this gap, existing research typically leverages the model's responses in English as a reference to select the best/worst responses in other languages, which are then used for Direct Preference Optimization (DPO) training. However, we argue that there are two limitations in the current methods that result in noisy multilingual preference data and further limited alignment performance: 1) Not all English responses are of high quality, and using a response with low quality may mislead the alignment for other languages. 2) Current methods usually use biased or heuristic approaches to construct multilingual preference pairs. To address these limitations, we design a consistency-based data selection method to construct high-quality multilingual preference data for improving multilingual alignment (CM-Align). Specifically, our method includes two parts: consistency-guided English reference selection and cross-lingual consistency-based multilingual preference data construction. Experimental results on three LLMs and three common tasks demonstrate the effectiveness and superiority of our method, which further indicates the necessity of constructing high-quality preference data.
LaCo: Efficient Layer-wise Compression of Visual Tokens for Multimodal Large Language Models
Jul 03, 2025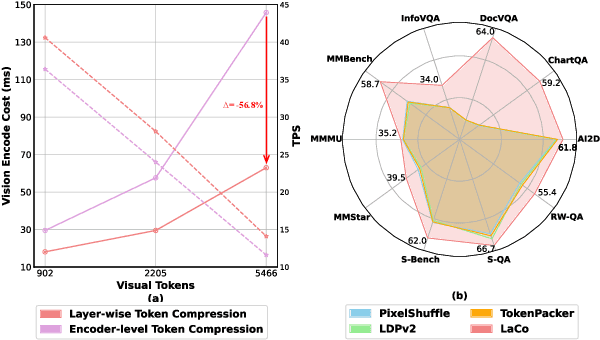
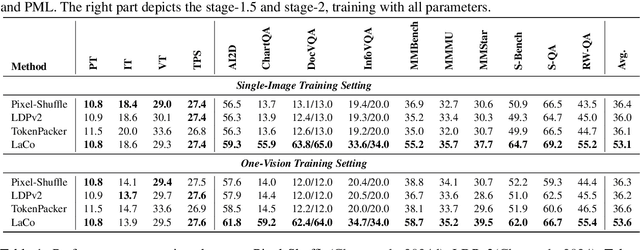
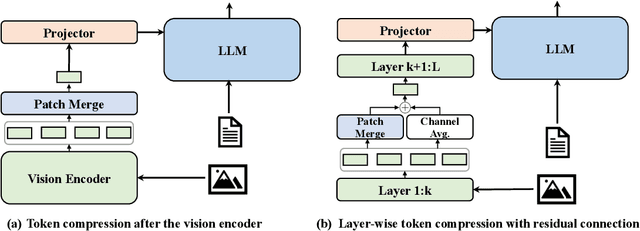

Existing visual token compression methods for Multimodal Large Language Models (MLLMs) predominantly operate as post-encoder modules, limiting their potential for efficiency gains. To address this limitation, we propose LaCo (Layer-wise Visual Token Compression), a novel framework that enables effective token compression within the intermediate layers of the vision encoder. LaCo introduces two core components: 1) a layer-wise pixel-shuffle mechanism that systematically merges adjacent tokens through space-to-channel transformations, and 2) a residual learning architecture with non-parametric shortcuts that preserves critical visual information during compression. Extensive experiments indicate that our LaCo outperforms all existing methods when compressing tokens in the intermediate layers of the vision encoder, demonstrating superior effectiveness. In addition, compared to external compression, our method improves training efficiency beyond 20% and inference throughput over 15% while maintaining strong performance.
Dense Retrievers Can Fail on Simple Queries: Revealing The Granularity Dilemma of Embeddings
Jun 10, 2025This work focuses on an observed limitation of text encoders: embeddings may not be able to recognize fine-grained entities or events within the semantics, resulting in failed dense retrieval on even simple cases. To examine such behaviors, we first introduce a new evaluation dataset in Chinese, named CapRetrieval, whose passages are image captions, and queries are phrases inquiring entities or events in various forms. Zero-shot evaluation suggests that encoders may fail on these fine-grained matching, regardless of training sources or model sizes. Aiming for enhancement, we proceed to finetune encoders with our proposed data generation strategies, which obtains the best performance on CapRetrieval. Within this process, we further identify an issue of granularity dilemma, a challenge for embeddings to express fine-grained salience while aligning with overall semantics. Our dataset, code and models in this work are publicly released at https://github.com/lxucs/CapRetrieval.
Dissecting Long Reasoning Models: An Empirical Study
Jun 05, 2025



Despite recent progress in training long-context reasoning models via reinforcement learning (RL), several open questions and counterintuitive behaviors remain. This work focuses on three key aspects: (1) We systematically analyze the roles of positive and negative samples in RL, revealing that positive samples mainly facilitate data fitting, whereas negative samples significantly enhance generalization and robustness. Interestingly, training solely on negative samples can rival standard RL training performance. (2) We identify substantial data inefficiency in group relative policy optimization, where over half of the samples yield zero advantage. To address this, we explore two straightforward strategies, including relative length rewards and offline sample injection, to better leverage these data and enhance reasoning efficiency and capability. (3) We investigate unstable performance across various reasoning models and benchmarks, attributing instability to uncertain problems with ambiguous outcomes, and demonstrate that multiple evaluation runs mitigate this issue.
Less, but Better: Efficient Multilingual Expansion for LLMs via Layer-wise Mixture-of-Experts
May 28, 2025Continually expanding new languages for existing large language models (LLMs) is a promising yet challenging approach to building powerful multilingual LLMs. The biggest challenge is to make the model continuously learn new languages while preserving the proficient ability of old languages. To achieve this, recent work utilizes the Mixture-of-Experts (MoE) architecture to expand new languages by adding new experts and avoid catastrophic forgetting of old languages by routing corresponding tokens to the original model backbone (old experts). Although intuitive, this kind of method is parameter-costly when expanding new languages and still inevitably impacts the performance of old languages. To address these limitations, we analyze the language characteristics of different layers in LLMs and propose a layer-wise expert allocation algorithm (LayerMoE) to determine the appropriate number of new experts for each layer. Specifically, we find different layers in LLMs exhibit different representation similarities between languages and then utilize the similarity as the indicator to allocate experts for each layer, i.e., the higher similarity, the fewer experts. Additionally, to further mitigate the forgetting of old languages, we add a classifier in front of the router network on the layers with higher similarity to guide the routing of old language tokens. Experimental results show that our method outperforms the previous state-of-the-art baseline with 60% fewer experts in the single-expansion setting and with 33.3% fewer experts in the lifelong-expansion setting, demonstrating the effectiveness of our method.
SlangDIT: Benchmarking LLMs in Interpretative Slang Translation
May 20, 2025The challenge of slang translation lies in capturing context-dependent semantic extensions, as slang terms often convey meanings beyond their literal interpretation. While slang detection, explanation, and translation have been studied as isolated tasks in the era of large language models (LLMs), their intrinsic interdependence remains underexplored. The main reason is lacking of a benchmark where the two tasks can be a prerequisite for the third one, which can facilitate idiomatic translation. In this paper, we introduce the interpretative slang translation task (named SlangDIT) consisting of three sub-tasks: slang detection, cross-lingual slang explanation, and slang translation within the current context, aiming to generate more accurate translation with the help of slang detection and slang explanation. To this end, we construct a SlangDIT dataset, containing over 25k English-Chinese sentence pairs. Each source sentence mentions at least one slang term and is labeled with corresponding cross-lingual slang explanation. Based on the benchmark, we propose a deep thinking model, named SlangOWL. It firstly identifies whether the sentence contains a slang, and then judges whether the slang is polysemous and analyze its possible meaning. Further, the SlangOWL provides the best explanation of the slang term targeting on the current context. Finally, according to the whole thought, the SlangOWL offers a suitable translation. Our experiments on LLMs (\emph{e.g.}, Qwen2.5 and LLama-3.1), show that our deep thinking approach indeed enhances the performance of LLMs where the proposed SLangOWL significantly surpasses the vanilla models and supervised fine-tuned models without thinking.
THOR-MoE: Hierarchical Task-Guided and Context-Responsive Routing for Neural Machine Translation
May 20, 2025The sparse Mixture-of-Experts (MoE) has achieved significant progress for neural machine translation (NMT). However, there exist two limitations in current MoE solutions which may lead to sub-optimal performance: 1) they directly use the task knowledge of NMT into MoE (\emph{e.g.}, domain/linguistics-specific knowledge), which are generally unavailable at practical application and neglect the naturally grouped domain/linguistic properties; 2) the expert selection only depends on the localized token representation without considering the context, which fully grasps the state of each token in a global view. To address the above limitations, we propose THOR-MoE via arming the MoE with hierarchical task-guided and context-responsive routing policies. Specifically, it 1) firstly predicts the domain/language label and then extracts mixed domain/language representation to allocate task-level experts in a hierarchical manner; 2) injects the context information to enhance the token routing from the pre-selected task-level experts set, which can help each token to be accurately routed to more specialized and suitable experts. Extensive experiments on multi-domain translation and multilingual translation benchmarks with different architectures consistently demonstrate the superior performance of THOR-MoE. Additionally, the THOR-MoE operates as a plug-and-play module compatible with existing Top-$k$~\cite{shazeer2017} and Top-$p$~\cite{huang-etal-2024-harder} routing schemes, ensuring broad applicability across diverse MoE architectures. For instance, compared with vanilla Top-$p$~\cite{huang-etal-2024-harder} routing, the context-aware manner can achieve an average improvement of 0.75 BLEU with less than 22\% activated parameters on multi-domain translation tasks.
An Empirical Study of Many-to-Many Summarization with Large Language Models
May 19, 2025



Many-to-many summarization (M2MS) aims to process documents in any language and generate the corresponding summaries also in any language. Recently, large language models (LLMs) have shown strong multi-lingual abilities, giving them the potential to perform M2MS in real applications. This work presents a systematic empirical study on LLMs' M2MS ability. Specifically, we first reorganize M2MS data based on eight previous domain-specific datasets. The reorganized data contains 47.8K samples spanning five domains and six languages, which could be used to train and evaluate LLMs. Then, we benchmark 18 LLMs in a zero-shot manner and an instruction-tuning manner. Fine-tuned traditional models (e.g., mBART) are also conducted for comparisons. Our experiments reveal that, zero-shot LLMs achieve competitive results with fine-tuned traditional models. After instruct-tuning, open-source LLMs can significantly improve their M2MS ability, and outperform zero-shot LLMs (including GPT-4) in terms of automatic evaluations. In addition, we demonstrate that this task-specific improvement does not sacrifice the LLMs' general task-solving abilities. However, as revealed by our human evaluation, LLMs still face the factuality issue, and the instruction tuning might intensify the issue. Thus, how to control factual errors becomes the key when building LLM summarizers in real applications, and is worth noting in future research.
ExTrans: Multilingual Deep Reasoning Translation via Exemplar-Enhanced Reinforcement Learning
May 19, 2025In recent years, the emergence of large reasoning models (LRMs), such as OpenAI-o1 and DeepSeek-R1, has shown impressive capabilities in complex problems, e.g., mathematics and coding. Some pioneering studies attempt to bring the success of LRMs in neural machine translation (MT). They try to build LRMs with deep reasoning MT ability via reinforcement learning (RL). Despite some progress that has been made, these attempts generally focus on several high-resource languages, e.g., English and Chinese, leaving the performance on other languages unclear. Besides, the reward modeling methods in previous work do not fully unleash the potential of reinforcement learning in MT. In this work, we first design a new reward modeling method that compares the translation results of the policy MT model with a strong LRM (i.e., DeepSeek-R1-671B), and quantifies the comparisons to provide rewards. Experimental results demonstrate the superiority of the reward modeling method. Using Qwen2.5-7B-Instruct as the backbone, the trained model achieves the new state-of-the-art performance in literary translation, and outperforms strong LRMs including OpenAI-o1 and DeepSeeK-R1. Furthermore, we extend our method to the multilingual settings with 11 languages. With a carefully designed lightweight reward modeling in RL, we can simply transfer the strong MT ability from a single direction into multiple (i.e., 90) translation directions and achieve impressive multilingual MT performance.