 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWeEdit: A Dataset, Benchmark and Glyph-Guided Framework for Text-centric Image Editing
Mar 12, 2026Instruction-based image editing aims to modify specific content within existing images according to user-provided instructions while preserving non-target regions. Beyond traditional object- and style-centric manipulation, text-centric image editing focuses on modifying, translating, or rearranging textual elements embedded within images. However, existing leading models often struggle to execute complex text editing precisely, frequently producing blurry or hallucinated characters. We attribute these failures primarily to the lack of specialized training paradigms tailored for text-centric editing, as well as the absence of large-scale datasets and standardized benchmarks necessary for a closed-loop training and evaluation system. To address these limitations, we present WeEdit, a systematic solution encompassing a scalable data construction pipeline, two benchmarks, and a tailored two-stage training strategy. Specifically, we propose a novel HTML-based automatic editing pipeline, which generates 330K training pairs covering diverse editing operations and 15 languages, accompanied by standardized bilingual and multilingual benchmarks for comprehensive evaluation. On the algorithmic side, we employ glyph-guided supervised fine-tuning to inject explicit spatial and content priors, followed by a multi-objective reinforcement learning stage to align generation with instruction adherence, text clarity, and background preservation. Extensive experiments demonstrate that WeEdit outperforms previous open-source models by a clear margin across diverse editing operations.
LaCo: Efficient Layer-wise Compression of Visual Tokens for Multimodal Large Language Models
Jul 03, 2025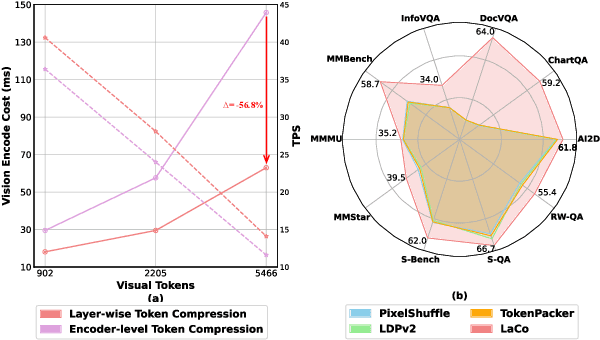
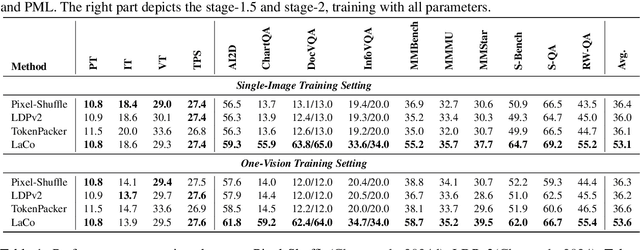
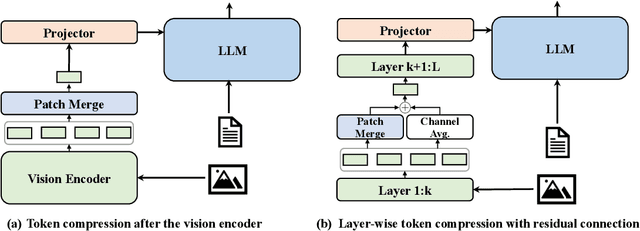

Existing visual token compression methods for Multimodal Large Language Models (MLLMs) predominantly operate as post-encoder modules, limiting their potential for efficiency gains. To address this limitation, we propose LaCo (Layer-wise Visual Token Compression), a novel framework that enables effective token compression within the intermediate layers of the vision encoder. LaCo introduces two core components: 1) a layer-wise pixel-shuffle mechanism that systematically merges adjacent tokens through space-to-channel transformations, and 2) a residual learning architecture with non-parametric shortcuts that preserves critical visual information during compression. Extensive experiments indicate that our LaCo outperforms all existing methods when compressing tokens in the intermediate layers of the vision encoder, demonstrating superior effectiveness. In addition, compared to external compression, our method improves training efficiency beyond 20% and inference throughput over 15% while maintaining strong performance.
WeLayout: WeChat Layout Analysis System for the ICDAR 2023 Competition on Robust Layout Segmentation in Corporate Documents
May 11, 2023



In this paper, we introduce WeLayout, a novel system for segmenting the layout of corporate documents, which stands for WeChat Layout Analysis System. Our approach utilizes a sophisticated ensemble of DINO and YOLO models, specifically developed for the ICDAR 2023 Competition on Robust Layout Segmentation. Our method significantly surpasses the baseline, securing a top position on the leaderboard with a mAP of 70.0. To achieve this performance, we concentrated on enhancing various aspects of the task, such as dataset augmentation, model architecture, bounding box refinement, and model ensemble techniques. Additionally, we trained the data separately for each document category to ensure a higher mean submission score. We also developed an algorithm for cell matching to further improve our performance. To identify the optimal weights and IoU thresholds for our model ensemble, we employed a Bayesian optimization algorithm called the Tree-Structured Parzen Estimator. Our approach effectively demonstrates the benefits of combining query-based and anchor-free models for achieving robust layout segmentation in corporate documents.