 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Building a Multilingual Sememe Knowledge Base: Predicting Sememes for BabelNet Synsets
Dec 04, 2019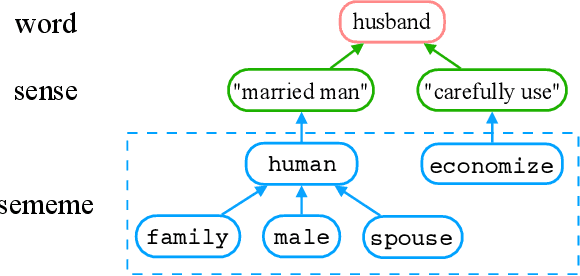
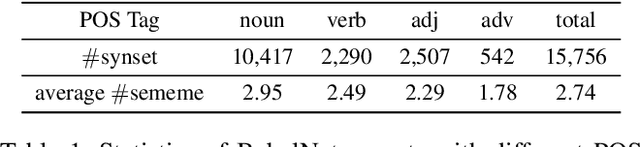
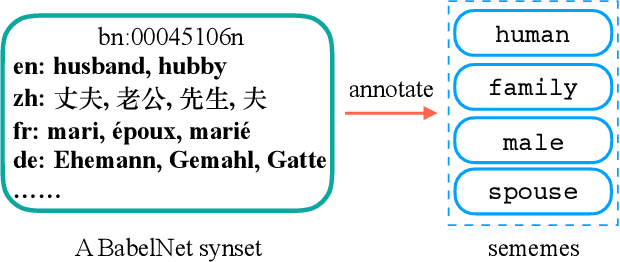
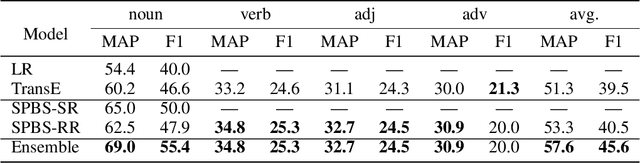
A sememe is defined as the minimum semantic unit of human languages. Sememe knowledge bases (KBs), which contain words annotated with sememes, have been successfully applied to many NLP tasks. However, existing sememe KBs are built on only a few languages, which hinders their widespread utilization. To address the issue, we propose to build a unified sememe KB for multiple languages based on BabelNet, a multilingual encyclopedic dictionary. We first build a dataset serving as the seed of the multilingual sememe KB. It manually annotates sememes for over $15$ thousand synsets (the entries of BabelNet). Then, we present a novel task of automatic sememe prediction for synsets, aiming to expand the seed dataset into a usable KB. We also propose two simple and effective models, which exploit different information of synsets. Finally, we conduct quantitative and qualitative analyses to explore important factors and difficulties in the task. All the source code and data of this work can be obtained on https://github.com/thunlp/BabelNet-Sememe-Prediction.
Textual Adversarial Attack as Combinatorial Optimization
Nov 10, 2019



Adversarial attack is carried out to reveal the vulnerability of deep neural networks. Textual adversarial attack is challenging because text is discrete and any perturbation might bring big semantic change. Word substitution is a class of effective textual attack method and has been extensively explored. However, all existing word substitution-based attack methods suffer the problems of bad semantic preservation, insufficient adversarial examples or suboptimal attack results. In this paper, we formalize the word substitution-based attack as a combinatorial optimization problem. We also propose a novel attack model, which comprises a sememe-based word substitution strategy and the particle swarm optimization algorithm, to tackle the existing problems. In experiments, we evaluate our attack model on the sentiment analysis task. Experimental results demonstrate our model achieves higher attack success rates and less modification than the baseline methods. The ablation study also verifies the superiority of the two parts of our model over previous ones.
Enhancing Recurrent Neural Networks with Sememes
Oct 20, 2019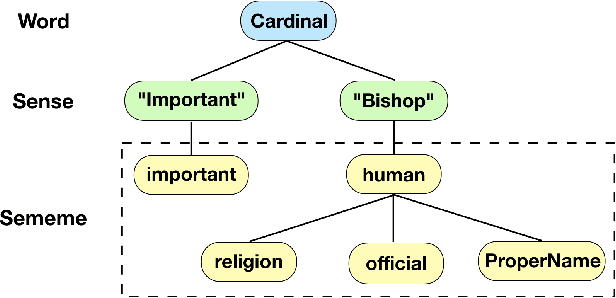
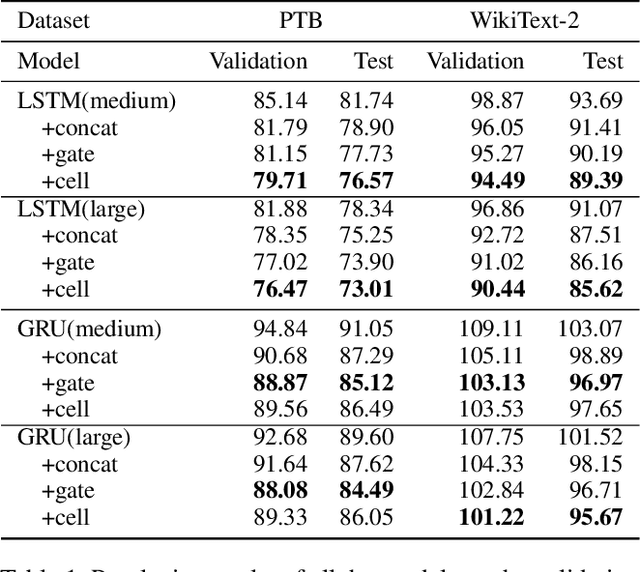
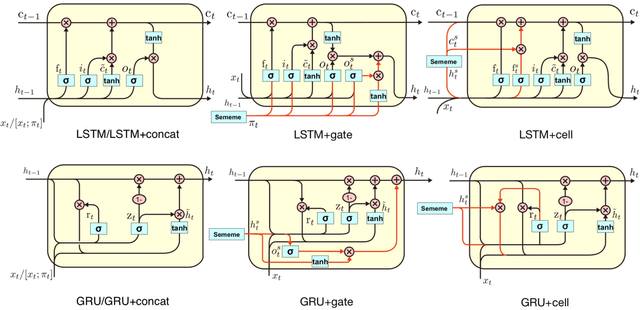
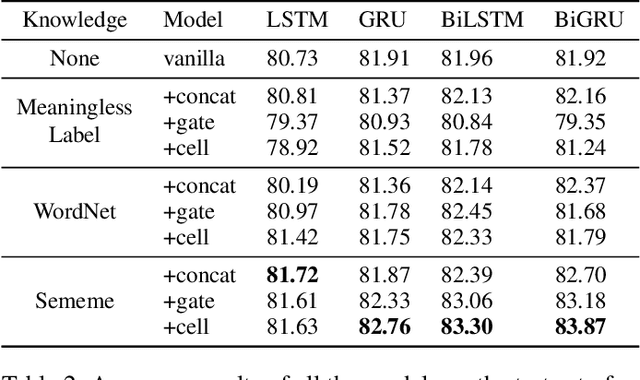
Sememes, the minimum semantic units of human languages, have been successfully utilized in various natural language processing applications. However, most existing studies exploit sememes in specific tasks and few efforts are made to utilize sememes more fundamentally. In this paper, we propose to incorporate sememes into recurrent neural networks (RNNs) to improve their sequence modeling ability, which is beneficial to all kinds of downstream tasks. We design three different sememe incorporation methods and employ them in typical RNNs including LSTM, GRU and their bidirectional variants. For evaluation, we use several benchmark datasets involving PTB and WikiText-2 for language modeling, SNLI for natural language inference. Experimental results show evident and consistent improvement of our sememe-incorporated models compared with vanilla RNNs, which proves the effectiveness of our sememe incorporation methods. Moreover, we find the sememe-incorporated models have great robustness and outperform adversarial training in defending adversarial attack. All the code and data of this work will be made available to the public.
Using BERT for Word Sense Disambiguation
Sep 18, 2019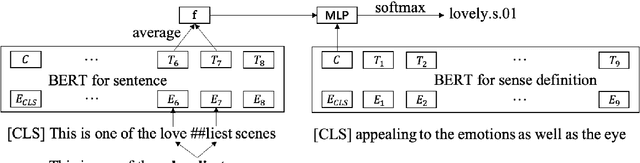
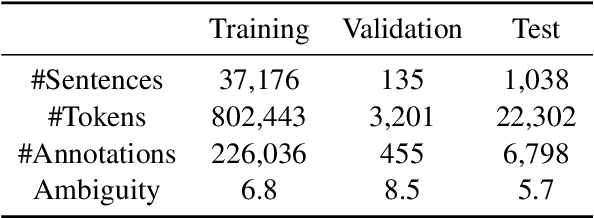
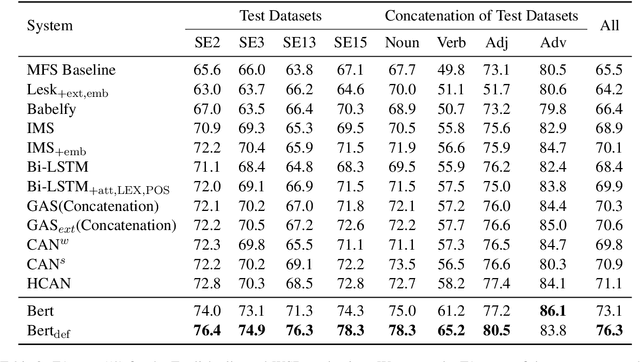
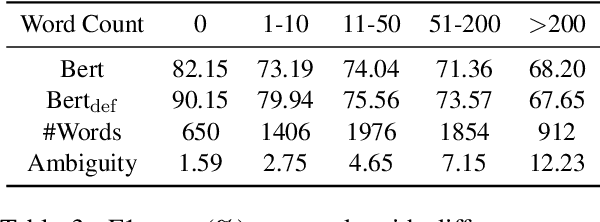
Word Sense Disambiguation (WSD), which aims to identify the correct sense of a given polyseme, is a long-standing problem in NLP. In this paper, we propose to use BERT to extract better polyseme representations for WSD and explore several ways of combining BERT and the classifier. We also utilize sense definitions to train a unified classifier for all words, which enables the model to disambiguate unseen polysemes. Experiments show that our model achieves the state-of-the-art results on the standard English All-word WSD evaluation.
Modeling Semantic Compositionality with Sememe Knowledge
Jul 10, 2019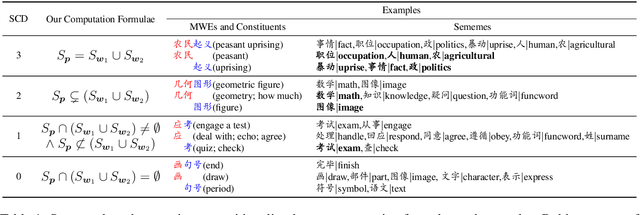
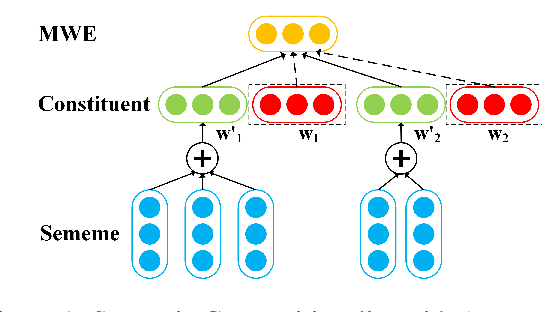
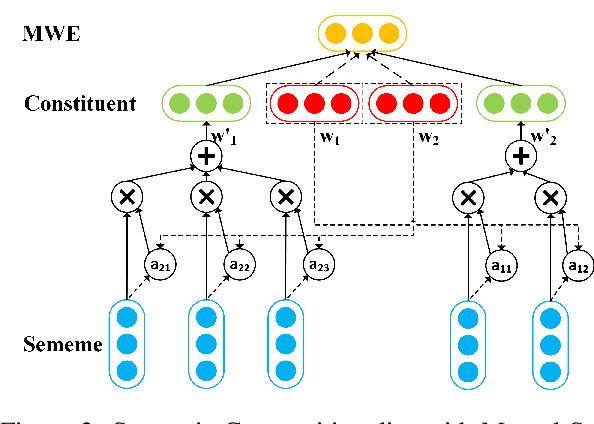
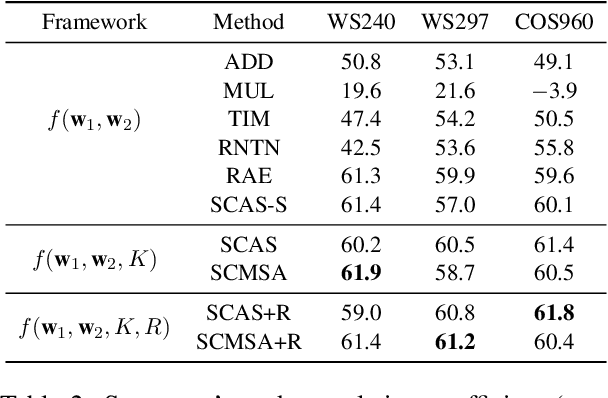
Semantic compositionality (SC) refers to the phenomenon that the meaning of a complex linguistic unit can be composed of the meanings of its constituents. Most related works focus on using complicated compositionality functions to model SC while few works consider external knowledge in models. In this paper, we verify the effectiveness of sememes, the minimum semantic units of human languages, in modeling SC by a confirmatory experiment. Furthermore, we make the first attempt to incorporate sememe knowledge into SC models, and employ the sememeincorporated models in learning representations of multiword expressions, a typical task of SC. In experiments, we implement our models by incorporating knowledge from a famous sememe knowledge base HowNet and perform both intrinsic and extrinsic evaluations. Experimental results show that our models achieve significant performance boost as compared to the baseline methods without considering sememe knowledge. We further conduct quantitative analysis and case studies to demonstrate the effectiveness of applying sememe knowledge in modeling SC. All the code and data of this paper can be obtained on https://github.com/thunlp/Sememe-SC.
COS960: A Chinese Word Similarity Dataset of 960 Word Pairs
Jun 01, 2019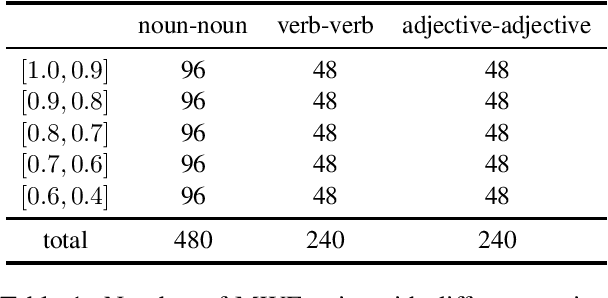
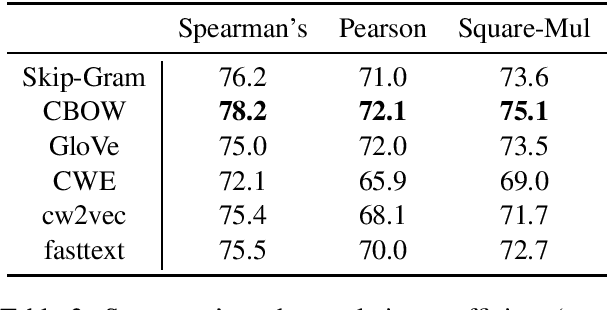
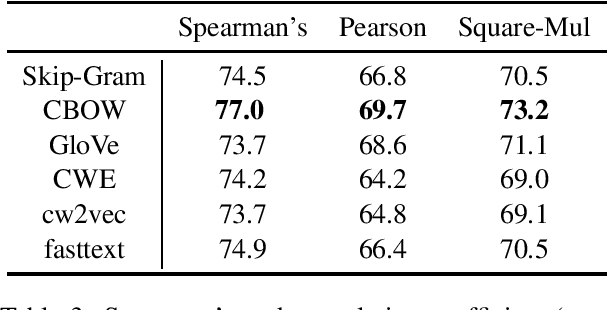
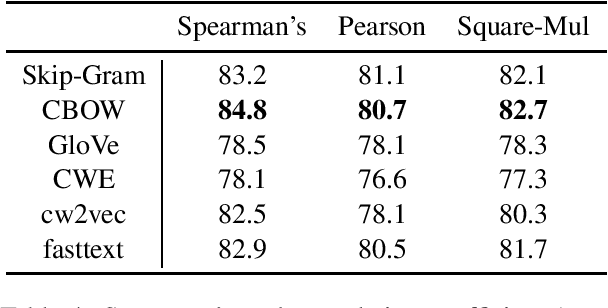
Word similarity computation is a widely recognized task in the field of lexical semantics. Most proposed tasks test on similarity of word pairs of single morpheme, while few works focus on words of two morphemes or more morphemes. In this work, we propose COS960, a benchmark dataset with 960 pairs of Chinese wOrd Similarity, where all the words have two morphemes in three Part of Speech (POS) tags with their human annotated similarity rather than relatedness. We give a detailed description of dataset construction and annotation process, and test on a range of word embedding models. The dataset of this paper can be obtained from https://github.com/thunlp/COS960.
OpenHowNet: An Open Sememe-based Lexical Knowledge Base
Jan 28, 2019
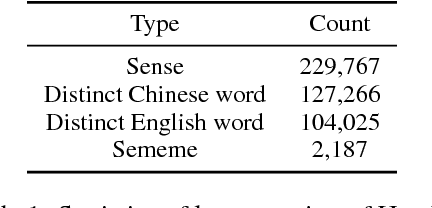
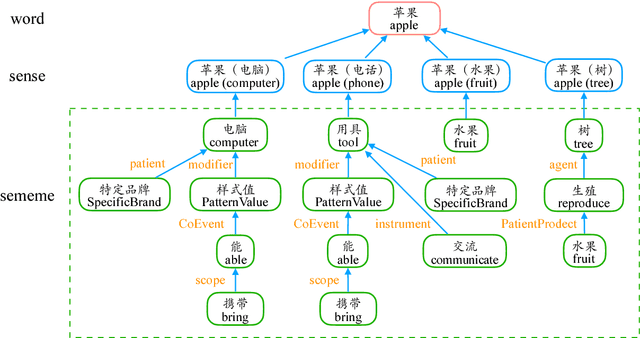
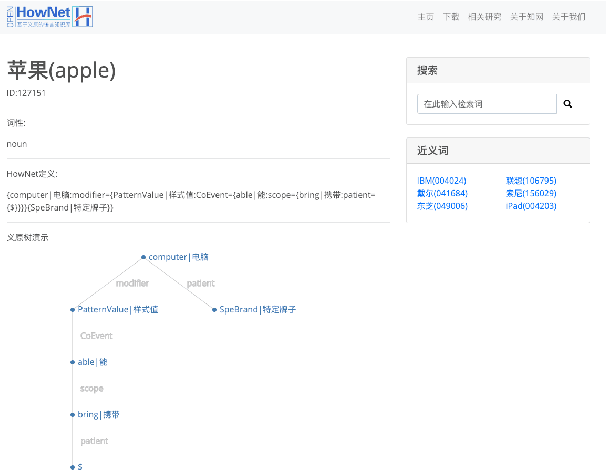
In this paper, we present an open sememe-based lexical knowledge base OpenHowNet. Based on well-known HowNet, OpenHowNet comprises three components: core data which is composed of more than 100 thousand senses annotated with sememes, OpenHowNet Web which gives a brief introduction to OpenHowNet as well as provides online exhibition of OpenHowNet information, and OpenHowNet API which includes several useful APIs such as accessing OpenHowNet core data and drawing sememe tree structures of senses. In the main text, we first give some backgrounds including definition of sememe and details of HowNet. And then we introduce some previous HowNet and sememe-based research works. Last but not least, we detail the constituents of OpenHowNet and their basic features and functionalities. Additionally, we briefly make a summary and list some future works.