 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHyperbolic Learning with Multimodal Large Language Models
Aug 09, 2024Hyperbolic embeddings have demonstrated their effectiveness in capturing measures of uncertainty and hierarchical relationships across various deep-learning tasks, including image segmentation and active learning. However, their application in modern vision-language models (VLMs) has been limited. A notable exception is MERU, which leverages the hierarchical properties of hyperbolic space in the CLIP ViT-large model, consisting of hundreds of millions parameters. In our work, we address the challenges of scaling multi-modal hyperbolic models by orders of magnitude in terms of parameters (billions) and training complexity using the BLIP-2 architecture. Although hyperbolic embeddings offer potential insights into uncertainty not present in Euclidean embeddings, our analysis reveals that scaling these models is particularly difficult. We propose a novel training strategy for a hyperbolic version of BLIP-2, which allows to achieve comparable performance to its Euclidean counterpart, while maintaining stability throughout the training process and showing a meaningful indication of uncertainty with each embedding.
Hyp2Nav: Hyperbolic Planning and Curiosity for Crowd Navigation
Jul 19, 2024



Autonomous robots are increasingly becoming a strong fixture in social environments. Effective crowd navigation requires not only safe yet fast planning, but should also enable interpretability and computational efficiency for working in real-time on embedded devices. In this work, we advocate for hyperbolic learning to enable crowd navigation and we introduce Hyp2Nav. Different from conventional reinforcement learning-based crowd navigation methods, Hyp2Nav leverages the intrinsic properties of hyperbolic geometry to better encode the hierarchical nature of decision-making processes in navigation tasks. We propose a hyperbolic policy model and a hyperbolic curiosity module that results in effective social navigation, best success rates, and returns across multiple simulation settings, using up to 6 times fewer parameters than competitor state-of-the-art models. With our approach, it becomes even possible to obtain policies that work in 2-dimensional embedding spaces, opening up new possibilities for low-resource crowd navigation and model interpretability. Insightfully, the internal hyperbolic representation of Hyp2Nav correlates with how much attention the robot pays to the surrounding crowds, e.g. due to multiple people occluding its pathway or to a few of them showing colliding plans, rather than to its own planned route.
Length-Aware Motion Synthesis via Latent Diffusion
Jul 16, 2024The target duration of a synthesized human motion is a critical attribute that requires modeling control over the motion dynamics and style. Speeding up an action performance is not merely fast-forwarding it. However, state-of-the-art techniques for human behavior synthesis have limited control over the target sequence length. We introduce the problem of generating length-aware 3D human motion sequences from textual descriptors, and we propose a novel model to synthesize motions of variable target lengths, which we dub "Length-Aware Latent Diffusion" (LADiff). LADiff consists of two new modules: 1) a length-aware variational auto-encoder to learn motion representations with length-dependent latent codes; 2) a length-conforming latent diffusion model to generate motions with a richness of details that increases with the required target sequence length. LADiff significantly improves over the state-of-the-art across most of the existing motion synthesis metrics on the two established benchmarks of HumanML3D and KIT-ML.
MoDiPO: text-to-motion alignment via AI-feedback-driven Direct Preference Optimization
May 06, 2024



Diffusion Models have revolutionized the field of human motion generation by offering exceptional generation quality and fine-grained controllability through natural language conditioning. Their inherent stochasticity, that is the ability to generate various outputs from a single input, is key to their success. However, this diversity should not be unrestricted, as it may lead to unlikely generations. Instead, it should be confined within the boundaries of text-aligned and realistic generations. To address this issue, we propose MoDiPO (Motion Diffusion DPO), a novel methodology that leverages Direct Preference Optimization (DPO) to align text-to-motion models. We streamline the laborious and expensive process of gathering human preferences needed in DPO by leveraging AI feedback instead. This enables us to experiment with novel DPO strategies, using both online and offline generated motion-preference pairs. To foster future research we contribute with a motion-preference dataset which we dub Pick-a-Move. We demonstrate, both qualitatively and quantitatively, that our proposed method yields significantly more realistic motions. In particular, MoDiPO substantially improves Frechet Inception Distance (FID) while retaining the same RPrecision and Multi-Modality performances.
Following the Human Thread in Social Navigation
Apr 17, 2024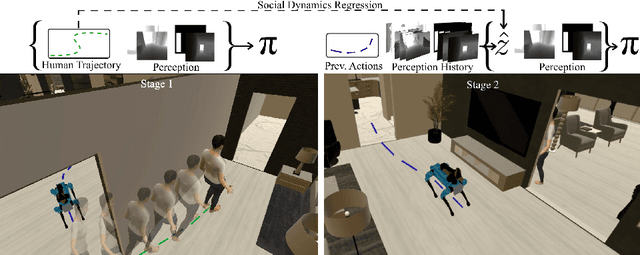

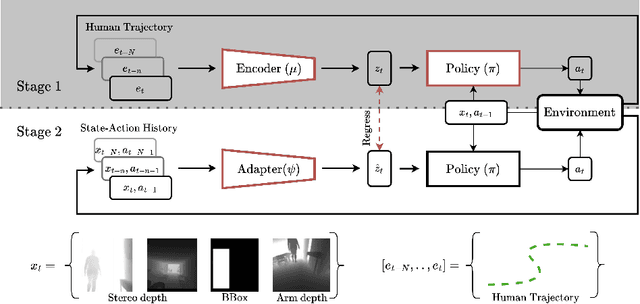

The success of collaboration between humans and robots in shared environments relies on the robot's real-time adaptation to human motion. Specifically, in Social Navigation, the agent should be close enough to assist but ready to back up to let the human move freely, avoiding collisions. Human trajectories emerge as crucial cues in Social Navigation, but they are partially observable from the robot's egocentric view and computationally complex to process. We propose the first Social Dynamics Adaptation model (SDA) based on the robot's state-action history to infer the social dynamics. We propose a two-stage Reinforcement Learning framework: the first learns to encode the human trajectories into social dynamics and learns a motion policy conditioned on this encoded information, the current status, and the previous action. Here, the trajectories are fully visible, i.e., assumed as privileged information. In the second stage, the trained policy operates without direct access to trajectories. Instead, the model infers the social dynamics solely from the history of previous actions and statuses in real-time. Tested on the novel Habitat 3.0 platform, SDA sets a novel state of the art (SoA) performance in finding and following humans.
PREGO: online mistake detection in PRocedural EGOcentric videos
Apr 02, 2024



Promptly identifying procedural errors from egocentric videos in an online setting is highly challenging and valuable for detecting mistakes as soon as they happen. This capability has a wide range of applications across various fields, such as manufacturing and healthcare. The nature of procedural mistakes is open-set since novel types of failures might occur, which calls for one-class classifiers trained on correctly executed procedures. However, no technique can currently detect open-set procedural mistakes online. We propose PREGO, the first online one-class classification model for mistake detection in PRocedural EGOcentric videos. PREGO is based on an online action recognition component to model the current action, and a symbolic reasoning module to predict the next actions. Mistake detection is performed by comparing the recognized current action with the expected future one. We evaluate PREGO on two procedural egocentric video datasets, Assembly101 and Epic-tent, which we adapt for online benchmarking of procedural mistake detection to establish suitable benchmarks, thus defining the Assembly101-O and Epic-tent-O datasets, respectively.
Staged Contact-Aware Global Human Motion Forecasting
Sep 16, 2023



Scene-aware global human motion forecasting is critical for manifold applications, including virtual reality, robotics, and sports. The task combines human trajectory and pose forecasting within the provided scene context, which represents a significant challenge. So far, only Mao et al. NeurIPS'22 have addressed scene-aware global motion, cascading the prediction of future scene contact points and the global motion estimation. They perform the latter as the end-to-end forecasting of future trajectories and poses. However, end-to-end contrasts with the coarse-to-fine nature of the task and it results in lower performance, as we demonstrate here empirically. We propose a STAGed contact-aware global human motion forecasting STAG, a novel three-stage pipeline for predicting global human motion in a 3D environment. We first consider the scene and the respective human interaction as contact points. Secondly, we model the human trajectory forecasting within the scene, predicting the coarse motion of the human body as a whole. The third and last stage matches a plausible fine human joint motion to complement the trajectory considering the estimated contacts. Compared to the state-of-the-art (SoA), STAG achieves a 1.8% and 16.2% overall improvement in pose and trajectory prediction, respectively, on the scene-aware GTA-IM dataset. A comprehensive ablation study confirms the advantages of staged modeling over end-to-end approaches. Furthermore, we establish the significance of a newly proposed temporal counter called the "time-to-go", which tells how long it is before reaching scene contact and endpoints. Notably, STAG showcases its ability to generalize to datasets lacking a scene and achieves a new state-of-the-art performance on CMU-Mocap, without leveraging any social cues. Our code is released at: https://github.com/L-Scofano/STAG
Compositional Semantic Mix for Domain Adaptation in Point Cloud Segmentation
Aug 29, 2023



Deep-learning models for 3D point cloud semantic segmentation exhibit limited generalization capabilities when trained and tested on data captured with different sensors or in varying environments due to domain shift. Domain adaptation methods can be employed to mitigate this domain shift, for instance, by simulating sensor noise, developing domain-agnostic generators, or training point cloud completion networks. Often, these methods are tailored for range view maps or necessitate multi-modal input. In contrast, domain adaptation in the image domain can be executed through sample mixing, which emphasizes input data manipulation rather than employing distinct adaptation modules. In this study, we introduce compositional semantic mixing for point cloud domain adaptation, representing the first unsupervised domain adaptation technique for point cloud segmentation based on semantic and geometric sample mixing. We present a two-branch symmetric network architecture capable of concurrently processing point clouds from a source domain (e.g. synthetic) and point clouds from a target domain (e.g. real-world). Each branch operates within one domain by integrating selected data fragments from the other domain and utilizing semantic information derived from source labels and target (pseudo) labels. Additionally, our method can leverage a limited number of human point-level annotations (semi-supervised) to further enhance performance. We assess our approach in both synthetic-to-real and real-to-real scenarios using LiDAR datasets and demonstrate that it significantly outperforms state-of-the-art methods in both unsupervised and semi-supervised settings.
Multimodal Motion Conditioned Diffusion Model for Skeleton-based Video Anomaly Detection
Jul 14, 2023



Anomalies are rare and anomaly detection is often therefore framed as One-Class Classification (OCC), i.e. trained solely on normalcy. Leading OCC techniques constrain the latent representations of normal motions to limited volumes and detect as abnormal anything outside, which accounts satisfactorily for the openset'ness of anomalies. But normalcy shares the same openset'ness property, since humans can perform the same action in several ways, which the leading techniques neglect. We propose a novel generative model for video anomaly detection (VAD), which assumes that both normality and abnormality are multimodal. We consider skeletal representations and leverage state-of-the-art diffusion probabilistic models to generate multimodal future human poses. We contribute a novel conditioning on the past motion of people, and exploit the improved mode coverage capabilities of diffusion processes to generate different-but-plausible future motions. Upon the statistical aggregation of future modes, anomaly is detected when the generated set of motions is not pertinent to the actual future. We validate our model on 4 established benchmarks: UBnormal, HR-UBnormal, HR-STC, and HR-Avenue, with extensive experiments surpassing state-of-the-art results.
Hyperbolic Active Learning for Semantic Segmentation under Domain Shift
Jun 26, 2023For the task of semantic segmentation (SS) under domain shift, active learning (AL) acquisition strategies based on image regions and pseudo labels are state-of-the-art (SoA). The presence of diverse pseudo-labels within a region identifies pixels between different classes, which is a labeling efficient active learning data acquisition strategy. However, by design, pseudo-label variations are limited to only select the contours of classes, limiting the final AL performance. We approach AL for SS in the Poincar\'e hyperbolic ball model for the first time and leverage the variations of the radii of pixel embeddings within regions as a novel data acquisition strategy. This stems from a novel geometric property of a hyperbolic space trained without enforced hierarchies, which we experimentally prove. Namely, classes are mapped into compact hyperbolic areas with a comparable intra-class radii variance, as the model places classes of increasing explainable difficulty at denser hyperbolic areas, i.e. closer to the Poincar\'e ball edge. The variation of pixel embedding radii identifies well the class contours, but they also select a few intra-class peculiar details, which boosts the final performance. Our proposed HALO (Hyperbolic Active Learning Optimization) surpasses the supervised learning performance for the first time in AL for SS under domain shift, by only using a small portion of labels (i.e., 1%). The extensive experimental analysis is based on two established benchmarks, i.e. GTAV $\rightarrow$ Cityscapes and SYNTHIA $\rightarrow$ Cityscapes, where we set a new SoA. The code will be released.