 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBimanual Robot Manipulation via Multi-Agent In-Context Learning
Apr 22, 2026Language Models (LLMs) have emerged as powerful reasoning engines for embodied control. In particular, In-Context Learning (ICL) enables off-the-shelf, text-only LLMs to predict robot actions without any task-specific training while preserving their generalization capabilities. Applying ICL to bimanual manipulation remains challenging, as the high-dimensional joint action space and tight inter-arm coordination constraints rapidly overwhelm standard context windows. To address this, we introduce BiCICLe (Bimanual Coordinated In-Context Learning), the first framework that enables standard LLMs to perform few-shot bimanual manipulation without fine-tuning. BiCICLe frames bimanual control as a multi-agent leader-follower problem, decoupling the action space into sequential, conditioned single-arm predictions. This naturally extends to Arms' Debate, an iterative refinement process, and to the introduction of a third LLM-as-Judge to evaluate and select the most plausible coordinated trajectories. Evaluated on 13 tasks from the TWIN benchmark, BiCICLe achieves up to 71.1% average success rate, outperforming the best training-free baseline by 6.7 percentage points and surpassing most supervised methods. We further demonstrate strong few-shot generalization on novel tasks.
Social EgoMesh Estimation
Nov 07, 2024



Accurately estimating the 3D pose of the camera wearer in egocentric video sequences is crucial to modeling human behavior in virtual and augmented reality applications. The task presents unique challenges due to the limited visibility of the user's body caused by the front-facing camera mounted on their head. Recent research has explored the utilization of the scene and ego-motion, but it has overlooked humans' interactive nature. We propose a novel framework for Social Egocentric Estimation of body MEshes (SEE-ME). Our approach is the first to estimate the wearer's mesh using only a latent probabilistic diffusion model, which we condition on the scene and, for the first time, on the social wearer-interactee interactions. Our in-depth study sheds light on when social interaction matters most for ego-mesh estimation; it quantifies the impact of interpersonal distance and gaze direction. Overall, SEE-ME surpasses the current best technique, reducing the pose estimation error (MPJPE) by 53%. The code is available at https://github.com/L-Scofano/SEEME.
TI-PREGO: Chain of Thought and In-Context Learning for Online Mistake Detection in PRocedural EGOcentric Videos
Nov 04, 2024



Identifying procedural errors online from egocentric videos is a critical yet challenging task across various domains, including manufacturing, healthcare, and skill-based training. The nature of such mistakes is inherently open-set, as unforeseen or novel errors may occur, necessitating robust detection systems that do not rely on prior examples of failure. Currently, however, no technique effectively detects open-set procedural mistakes online. We propose a dual branch architecture to address this problem in an online fashion: one branch continuously performs step recognition from the input egocentric video, while the other anticipates future steps based on the recognition module's output. Mistakes are detected as mismatches between the currently recognized action and the action predicted by the anticipation module. The recognition branch takes input frames, predicts the current action, and aggregates frame-level results into action tokens. The anticipation branch, specifically, leverages the solid pattern-matching capabilities of Large Language Models (LLMs) to predict action tokens based on previously predicted ones. Given the online nature of the task, we also thoroughly benchmark the difficulties associated with per-frame evaluations, particularly the need for accurate and timely predictions in dynamic online scenarios. Extensive experiments on two procedural datasets demonstrate the challenges and opportunities of leveraging a dual-branch architecture for mistake detection, showcasing the effectiveness of our proposed approach. In a thorough evaluation including recognition and anticipation variants and state-of-the-art models, our method reveals its robustness and effectiveness in online applications.
Following the Human Thread in Social Navigation
Apr 17, 2024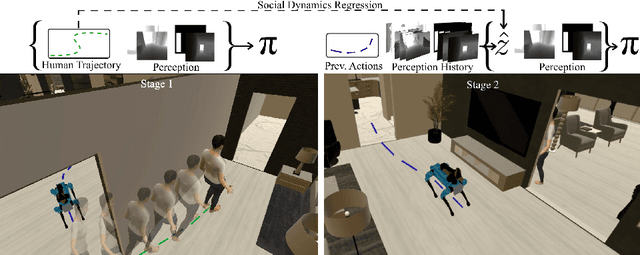

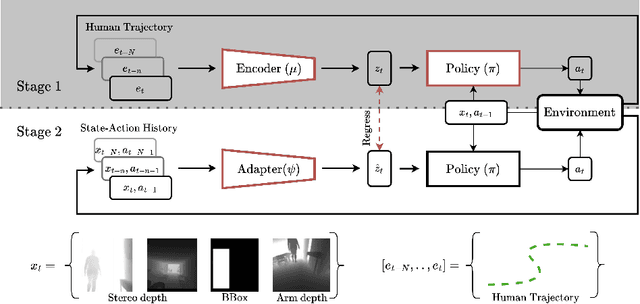

The success of collaboration between humans and robots in shared environments relies on the robot's real-time adaptation to human motion. Specifically, in Social Navigation, the agent should be close enough to assist but ready to back up to let the human move freely, avoiding collisions. Human trajectories emerge as crucial cues in Social Navigation, but they are partially observable from the robot's egocentric view and computationally complex to process. We propose the first Social Dynamics Adaptation model (SDA) based on the robot's state-action history to infer the social dynamics. We propose a two-stage Reinforcement Learning framework: the first learns to encode the human trajectories into social dynamics and learns a motion policy conditioned on this encoded information, the current status, and the previous action. Here, the trajectories are fully visible, i.e., assumed as privileged information. In the second stage, the trained policy operates without direct access to trajectories. Instead, the model infers the social dynamics solely from the history of previous actions and statuses in real-time. Tested on the novel Habitat 3.0 platform, SDA sets a novel state of the art (SoA) performance in finding and following humans.
PREGO: online mistake detection in PRocedural EGOcentric videos
Apr 02, 2024



Promptly identifying procedural errors from egocentric videos in an online setting is highly challenging and valuable for detecting mistakes as soon as they happen. This capability has a wide range of applications across various fields, such as manufacturing and healthcare. The nature of procedural mistakes is open-set since novel types of failures might occur, which calls for one-class classifiers trained on correctly executed procedures. However, no technique can currently detect open-set procedural mistakes online. We propose PREGO, the first online one-class classification model for mistake detection in PRocedural EGOcentric videos. PREGO is based on an online action recognition component to model the current action, and a symbolic reasoning module to predict the next actions. Mistake detection is performed by comparing the recognized current action with the expected future one. We evaluate PREGO on two procedural egocentric video datasets, Assembly101 and Epic-tent, which we adapt for online benchmarking of procedural mistake detection to establish suitable benchmarks, thus defining the Assembly101-O and Epic-tent-O datasets, respectively.
TopoX: A Suite of Python Packages for Machine Learning on Topological Domains
Feb 07, 2024

We introduce topox, a Python software suite that provides reliable and user-friendly building blocks for computing and machine learning on topological domains that extend graphs: hypergraphs, simplicial, cellular, path and combinatorial complexes. topox consists of three packages: toponetx facilitates constructing and computing on these domains, including working with nodes, edges and higher-order cells; topoembedx provides methods to embed topological domains into vector spaces, akin to popular graph-based embedding algorithms such as node2vec; topomodelx is built on top of PyTorch and offers a comprehensive toolbox of higher-order message passing functions for neural networks on topological domains. The extensively documented and unit-tested source code of topox is available under MIT license at https://github.com/pyt-team.
ICML 2023 Topological Deep Learning Challenge : Design and Results
Oct 02, 2023

This paper presents the computational challenge on topological deep learning that was hosted within the ICML 2023 Workshop on Topology and Geometry in Machine Learning. The competition asked participants to provide open-source implementations of topological neural networks from the literature by contributing to the python packages TopoNetX (data processing) and TopoModelX (deep learning). The challenge attracted twenty-eight qualifying submissions in its two-month duration. This paper describes the design of the challenge and summarizes its main findings.
Staged Contact-Aware Global Human Motion Forecasting
Sep 16, 2023



Scene-aware global human motion forecasting is critical for manifold applications, including virtual reality, robotics, and sports. The task combines human trajectory and pose forecasting within the provided scene context, which represents a significant challenge. So far, only Mao et al. NeurIPS'22 have addressed scene-aware global motion, cascading the prediction of future scene contact points and the global motion estimation. They perform the latter as the end-to-end forecasting of future trajectories and poses. However, end-to-end contrasts with the coarse-to-fine nature of the task and it results in lower performance, as we demonstrate here empirically. We propose a STAGed contact-aware global human motion forecasting STAG, a novel three-stage pipeline for predicting global human motion in a 3D environment. We first consider the scene and the respective human interaction as contact points. Secondly, we model the human trajectory forecasting within the scene, predicting the coarse motion of the human body as a whole. The third and last stage matches a plausible fine human joint motion to complement the trajectory considering the estimated contacts. Compared to the state-of-the-art (SoA), STAG achieves a 1.8% and 16.2% overall improvement in pose and trajectory prediction, respectively, on the scene-aware GTA-IM dataset. A comprehensive ablation study confirms the advantages of staged modeling over end-to-end approaches. Furthermore, we establish the significance of a newly proposed temporal counter called the "time-to-go", which tells how long it is before reaching scene contact and endpoints. Notably, STAG showcases its ability to generalize to datasets lacking a scene and achieves a new state-of-the-art performance on CMU-Mocap, without leveraging any social cues. Our code is released at: https://github.com/L-Scofano/STAG
About latent roles in forecasting players in team sports
Apr 23, 2023Forecasting players in sports has grown in popularity due to the potential for a tactical advantage and the applicability of such research to multi-agent interaction systems. Team sports contain a significant social component that influences interactions between teammates and opponents. However, it still needs to be fully exploited. In this work, we hypothesize that each participant has a specific function in each action and that role-based interaction is critical for predicting players' future moves. We create RolFor, a novel end-to-end model for Role-based Forecasting. RolFor uses a new module we developed called Ordering Neural Networks (OrderNN) to permute the order of the players such that each player is assigned to a latent role. The latent role is then modeled with a RoleGCN. Thanks to its graph representation, it provides a fully learnable adjacency matrix that captures the relationships between roles and is subsequently used to forecast the players' future trajectories. Extensive experiments on a challenging NBA basketball dataset back up the importance of roles and justify our goal of modeling them using optimizable models. When an oracle provides roles, the proposed RolFor compares favorably to the current state-of-the-art (it ranks first in terms of ADE and second in terms of FDE errors). However, training the end-to-end RolFor incurs the issues of differentiability of permutation methods, which we experimentally review. Finally, this work restates differentiable ranking as a difficult open problem and its great potential in conjunction with graph-based interaction models. Project is available at: https://www.pinlab.org/aboutlatentroles
Best Practices for 2-Body Pose Forecasting
Apr 12, 2023



The task of collaborative human pose forecasting stands for predicting the future poses of multiple interacting people, given those in previous frames. Predicting two people in interaction, instead of each separately, promises better performance, due to their body-body motion correlations. But the task has remained so far primarily unexplored. In this paper, we review the progress in human pose forecasting and provide an in-depth assessment of the single-person practices that perform best for 2-body collaborative motion forecasting. Our study confirms the positive impact of frequency input representations, space-time separable and fully-learnable interaction adjacencies for the encoding GCN and FC decoding. Other single-person practices do not transfer to 2-body, so the proposed best ones do not include hierarchical body modeling or attention-based interaction encoding. We further contribute a novel initialization procedure for the 2-body spatial interaction parameters of the encoder, which benefits performance and stability. Altogether, our proposed 2-body pose forecasting best practices yield a performance improvement of 21.9% over the state-of-the-art on the most recent ExPI dataset, whereby the novel initialization accounts for 3.5%. See our project page at https://www.pinlab.org/bestpractices2body