 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeVideo Unlearning via Low-Rank Refusal Vector
Jun 09, 2025
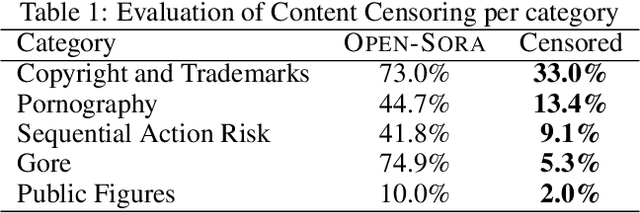
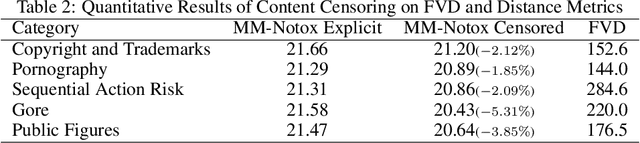

Video generative models democratize the creation of visual content through intuitive instruction following, but they also inherit the biases and harmful concepts embedded within their web-scale training data. This inheritance creates a significant risk, as users can readily generate undesirable and even illegal content. This work introduces the first unlearning technique tailored explicitly for video diffusion models to address this critical issue. Our method requires 5 multi-modal prompt pairs only. Each pair contains a "safe" and an "unsafe" example that differ only by the target concept. Averaging their per-layer latent differences produces a "refusal vector", which, once subtracted from the model parameters, neutralizes the unsafe concept. We introduce a novel low-rank factorization approach on the covariance difference of embeddings that yields robust refusal vectors. This isolates the target concept while minimizing collateral unlearning of other semantics, thus preserving the visual quality of the generated video. Our method preserves the model's generation quality while operating without retraining or access to the original training data. By embedding the refusal direction directly into the model's weights, the suppression mechanism becomes inherently more robust against adversarial bypass attempts compared to surface-level input-output filters. In a thorough qualitative and quantitative evaluation, we show that we can neutralize a variety of harmful contents, including explicit nudity, graphic violence, copyrights, and trademarks. Project page: https://www.pinlab.org/video-unlearning.
Human Motion Unlearning
Mar 24, 2025We introduce the task of human motion unlearning to prevent the synthesis of toxic animations while preserving the general text-to-motion generative performance. Unlearning toxic motions is challenging as those can be generated from explicit text prompts and from implicit toxic combinations of safe motions (e.g., ``kicking" is ``loading and swinging a leg"). We propose the first motion unlearning benchmark by filtering toxic motions from the large and recent text-to-motion datasets of HumanML3D and Motion-X. We propose baselines, by adapting state-of-the-art image unlearning techniques to process spatio-temporal signals. Finally, we propose a novel motion unlearning model based on Latent Code Replacement, which we dub LCR. LCR is training-free and suitable to the discrete latent spaces of state-of-the-art text-to-motion diffusion models. LCR is simple and consistently outperforms baselines qualitatively and quantitatively. Project page: \href{https://www.pinlab.org/hmu}{https://www.pinlab.org/hmu}.
Social EgoMesh Estimation
Nov 07, 2024



Accurately estimating the 3D pose of the camera wearer in egocentric video sequences is crucial to modeling human behavior in virtual and augmented reality applications. The task presents unique challenges due to the limited visibility of the user's body caused by the front-facing camera mounted on their head. Recent research has explored the utilization of the scene and ego-motion, but it has overlooked humans' interactive nature. We propose a novel framework for Social Egocentric Estimation of body MEshes (SEE-ME). Our approach is the first to estimate the wearer's mesh using only a latent probabilistic diffusion model, which we condition on the scene and, for the first time, on the social wearer-interactee interactions. Our in-depth study sheds light on when social interaction matters most for ego-mesh estimation; it quantifies the impact of interpersonal distance and gaze direction. Overall, SEE-ME surpasses the current best technique, reducing the pose estimation error (MPJPE) by 53%. The code is available at https://github.com/L-Scofano/SEEME.
TI-PREGO: Chain of Thought and In-Context Learning for Online Mistake Detection in PRocedural EGOcentric Videos
Nov 04, 2024



Identifying procedural errors online from egocentric videos is a critical yet challenging task across various domains, including manufacturing, healthcare, and skill-based training. The nature of such mistakes is inherently open-set, as unforeseen or novel errors may occur, necessitating robust detection systems that do not rely on prior examples of failure. Currently, however, no technique effectively detects open-set procedural mistakes online. We propose a dual branch architecture to address this problem in an online fashion: one branch continuously performs step recognition from the input egocentric video, while the other anticipates future steps based on the recognition module's output. Mistakes are detected as mismatches between the currently recognized action and the action predicted by the anticipation module. The recognition branch takes input frames, predicts the current action, and aggregates frame-level results into action tokens. The anticipation branch, specifically, leverages the solid pattern-matching capabilities of Large Language Models (LLMs) to predict action tokens based on previously predicted ones. Given the online nature of the task, we also thoroughly benchmark the difficulties associated with per-frame evaluations, particularly the need for accurate and timely predictions in dynamic online scenarios. Extensive experiments on two procedural datasets demonstrate the challenges and opportunities of leveraging a dual-branch architecture for mistake detection, showcasing the effectiveness of our proposed approach. In a thorough evaluation including recognition and anticipation variants and state-of-the-art models, our method reveals its robustness and effectiveness in online applications.
PREGO: online mistake detection in PRocedural EGOcentric videos
Apr 02, 2024



Promptly identifying procedural errors from egocentric videos in an online setting is highly challenging and valuable for detecting mistakes as soon as they happen. This capability has a wide range of applications across various fields, such as manufacturing and healthcare. The nature of procedural mistakes is open-set since novel types of failures might occur, which calls for one-class classifiers trained on correctly executed procedures. However, no technique can currently detect open-set procedural mistakes online. We propose PREGO, the first online one-class classification model for mistake detection in PRocedural EGOcentric videos. PREGO is based on an online action recognition component to model the current action, and a symbolic reasoning module to predict the next actions. Mistake detection is performed by comparing the recognized current action with the expected future one. We evaluate PREGO on two procedural egocentric video datasets, Assembly101 and Epic-tent, which we adapt for online benchmarking of procedural mistake detection to establish suitable benchmarks, thus defining the Assembly101-O and Epic-tent-O datasets, respectively.
Staged Contact-Aware Global Human Motion Forecasting
Sep 16, 2023



Scene-aware global human motion forecasting is critical for manifold applications, including virtual reality, robotics, and sports. The task combines human trajectory and pose forecasting within the provided scene context, which represents a significant challenge. So far, only Mao et al. NeurIPS'22 have addressed scene-aware global motion, cascading the prediction of future scene contact points and the global motion estimation. They perform the latter as the end-to-end forecasting of future trajectories and poses. However, end-to-end contrasts with the coarse-to-fine nature of the task and it results in lower performance, as we demonstrate here empirically. We propose a STAGed contact-aware global human motion forecasting STAG, a novel three-stage pipeline for predicting global human motion in a 3D environment. We first consider the scene and the respective human interaction as contact points. Secondly, we model the human trajectory forecasting within the scene, predicting the coarse motion of the human body as a whole. The third and last stage matches a plausible fine human joint motion to complement the trajectory considering the estimated contacts. Compared to the state-of-the-art (SoA), STAG achieves a 1.8% and 16.2% overall improvement in pose and trajectory prediction, respectively, on the scene-aware GTA-IM dataset. A comprehensive ablation study confirms the advantages of staged modeling over end-to-end approaches. Furthermore, we establish the significance of a newly proposed temporal counter called the "time-to-go", which tells how long it is before reaching scene contact and endpoints. Notably, STAG showcases its ability to generalize to datasets lacking a scene and achieves a new state-of-the-art performance on CMU-Mocap, without leveraging any social cues. Our code is released at: https://github.com/L-Scofano/STAG
Best Practices for 2-Body Pose Forecasting
Apr 12, 2023



The task of collaborative human pose forecasting stands for predicting the future poses of multiple interacting people, given those in previous frames. Predicting two people in interaction, instead of each separately, promises better performance, due to their body-body motion correlations. But the task has remained so far primarily unexplored. In this paper, we review the progress in human pose forecasting and provide an in-depth assessment of the single-person practices that perform best for 2-body collaborative motion forecasting. Our study confirms the positive impact of frequency input representations, space-time separable and fully-learnable interaction adjacencies for the encoding GCN and FC decoding. Other single-person practices do not transfer to 2-body, so the proposed best ones do not include hierarchical body modeling or attention-based interaction encoding. We further contribute a novel initialization procedure for the 2-body spatial interaction parameters of the encoder, which benefits performance and stability. Altogether, our proposed 2-body pose forecasting best practices yield a performance improvement of 21.9% over the state-of-the-art on the most recent ExPI dataset, whereby the novel initialization accounts for 3.5%. See our project page at https://www.pinlab.org/bestpractices2body