 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobotic Policy Adaptation via Weight-Space Meta-Learning
Jun 05, 2026Vision-Language-Action (VLA) models are emerging as a promising paradigm for robotic manipulation, enabling general-purpose policies trained from large corpora of demonstrations and action labels. However, adapting these models to new tasks still typically requires task-specific demonstrations, action annotations, and additional fine-tuning, making deployment costly and difficult to scale. We propose WIZARD, a weight-space meta-learning framework that sidesteps task-specific fine-tuning by generating task-specific LoRA parameters for a frozen VLA policy. Given only a language instruction and a short demonstration video, WIZARD predicts the corresponding adaptation weights in a single forward pass, without target-task action labels or test-time optimization. During meta-training, WIZARD learns to map task evidence directly to expert LoRA updates, capturing relationships between tasks in weight space. Experiments on LIBERO show that WIZARD improves performance by up to ~2x on unseen dataset collections and up to ~14x on unseen tasks. On a Franka Emika Panda, WIZARD consistently improves over a real-domain adapted baseline, showing that generated adapters provide task-level specialization beyond simulation.
Not All Latent Spaces Are Flat: Hyperbolic Concept Control
Mar 14, 2026As modern text-to-image (T2I) models draw closer to synthesizing highly realistic content, the threat of unsafe content generation grows, and it becomes paramount to exercise control. Existing approaches steer these models by applying Euclidean adjustments to text embeddings, redirecting the generation away from unsafe concepts. In this work, we introduce hyperbolic control (HyCon): a novel control mechanism based on parallel transport that leverages semantically aligned hyperbolic representation space to yield more expressive and stable manipulation of concepts. HyCon reuses off-the-shelf generative models and a state-of-the-art hyperbolic text encoder, linked via a lightweight adapter. HyCon achieves state-of-the-art results across four safety benchmarks and four T2I backbones, showing that hyperbolic steering is a practical and flexible approach for more reliable T2I generation.
Video Unlearning via Low-Rank Refusal Vector
Jun 09, 2025
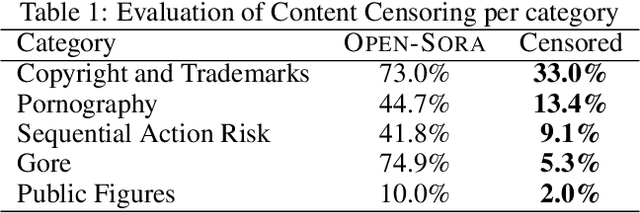
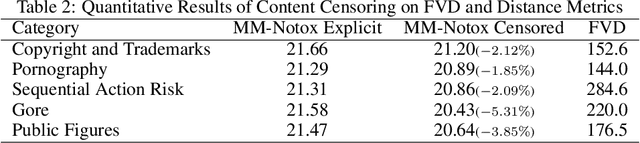

Video generative models democratize the creation of visual content through intuitive instruction following, but they also inherit the biases and harmful concepts embedded within their web-scale training data. This inheritance creates a significant risk, as users can readily generate undesirable and even illegal content. This work introduces the first unlearning technique tailored explicitly for video diffusion models to address this critical issue. Our method requires 5 multi-modal prompt pairs only. Each pair contains a "safe" and an "unsafe" example that differ only by the target concept. Averaging their per-layer latent differences produces a "refusal vector", which, once subtracted from the model parameters, neutralizes the unsafe concept. We introduce a novel low-rank factorization approach on the covariance difference of embeddings that yields robust refusal vectors. This isolates the target concept while minimizing collateral unlearning of other semantics, thus preserving the visual quality of the generated video. Our method preserves the model's generation quality while operating without retraining or access to the original training data. By embedding the refusal direction directly into the model's weights, the suppression mechanism becomes inherently more robust against adversarial bypass attempts compared to surface-level input-output filters. In a thorough qualitative and quantitative evaluation, we show that we can neutralize a variety of harmful contents, including explicit nudity, graphic violence, copyrights, and trademarks. Project page: https://www.pinlab.org/video-unlearning.
LongCodeBench: Evaluating Coding LLMs at 1M Context Windows
May 12, 2025



Context lengths for models have grown rapidly, from thousands to millions of tokens in just a few years. The extreme context sizes of modern long-context models have made it difficult to construct realistic long-context benchmarks -- not only due to the cost of collecting million-context tasks but also in identifying realistic scenarios that require significant contexts. We identify code comprehension and repair as a natural testbed and challenge task for long-context models and introduce LongCodeBench (LCB), a benchmark to test LLM coding abilities in long-context scenarios. Our benchmark tests both the comprehension and repair capabilities of LCLMs in realistic and important settings by drawing from real-world GitHub issues and constructing QA (LongCodeQA) and bug fixing (LongSWE-Bench) tasks. We carefully stratify the complexity of our benchmark, enabling us to evaluate models across different scales -- ranging from Qwen2.5 14B Instruct to Google's flagship Gemini model. We find that long-context remains a weakness for all models, with performance drops such as from 29% to 3% for Claude 3.5 Sonnet, or from 70.2% to 40% for Qwen2.5.
Human Motion Unlearning
Mar 24, 2025We introduce the task of human motion unlearning to prevent the synthesis of toxic animations while preserving the general text-to-motion generative performance. Unlearning toxic motions is challenging as those can be generated from explicit text prompts and from implicit toxic combinations of safe motions (e.g., ``kicking" is ``loading and swinging a leg"). We propose the first motion unlearning benchmark by filtering toxic motions from the large and recent text-to-motion datasets of HumanML3D and Motion-X. We propose baselines, by adapting state-of-the-art image unlearning techniques to process spatio-temporal signals. Finally, we propose a novel motion unlearning model based on Latent Code Replacement, which we dub LCR. LCR is training-free and suitable to the discrete latent spaces of state-of-the-art text-to-motion diffusion models. LCR is simple and consistently outperforms baselines qualitatively and quantitatively. Project page: \href{https://www.pinlab.org/hmu}{https://www.pinlab.org/hmu}.
Social EgoMesh Estimation
Nov 07, 2024



Accurately estimating the 3D pose of the camera wearer in egocentric video sequences is crucial to modeling human behavior in virtual and augmented reality applications. The task presents unique challenges due to the limited visibility of the user's body caused by the front-facing camera mounted on their head. Recent research has explored the utilization of the scene and ego-motion, but it has overlooked humans' interactive nature. We propose a novel framework for Social Egocentric Estimation of body MEshes (SEE-ME). Our approach is the first to estimate the wearer's mesh using only a latent probabilistic diffusion model, which we condition on the scene and, for the first time, on the social wearer-interactee interactions. Our in-depth study sheds light on when social interaction matters most for ego-mesh estimation; it quantifies the impact of interpersonal distance and gaze direction. Overall, SEE-ME surpasses the current best technique, reducing the pose estimation error (MPJPE) by 53%. The code is available at https://github.com/L-Scofano/SEEME.
Length-Aware Motion Synthesis via Latent Diffusion
Jul 16, 2024



The target duration of a synthesized human motion is a critical attribute that requires modeling control over the motion dynamics and style. Speeding up an action performance is not merely fast-forwarding it. However, state-of-the-art techniques for human behavior synthesis have limited control over the target sequence length. We introduce the problem of generating length-aware 3D human motion sequences from textual descriptors, and we propose a novel model to synthesize motions of variable target lengths, which we dub "Length-Aware Latent Diffusion" (LADiff). LADiff consists of two new modules: 1) a length-aware variational auto-encoder to learn motion representations with length-dependent latent codes; 2) a length-conforming latent diffusion model to generate motions with a richness of details that increases with the required target sequence length. LADiff significantly improves over the state-of-the-art across most of the existing motion synthesis metrics on the two established benchmarks of HumanML3D and KIT-ML.
Following the Human Thread in Social Navigation
Apr 17, 2024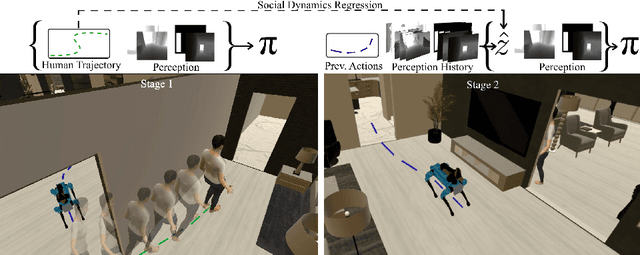

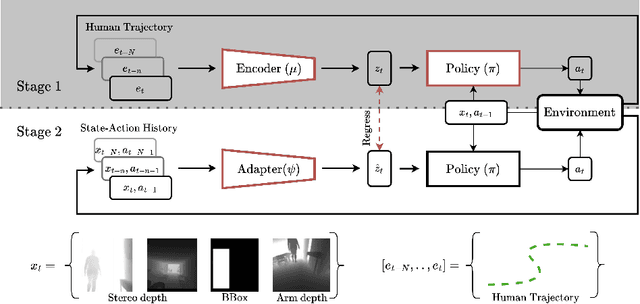

The success of collaboration between humans and robots in shared environments relies on the robot's real-time adaptation to human motion. Specifically, in Social Navigation, the agent should be close enough to assist but ready to back up to let the human move freely, avoiding collisions. Human trajectories emerge as crucial cues in Social Navigation, but they are partially observable from the robot's egocentric view and computationally complex to process. We propose the first Social Dynamics Adaptation model (SDA) based on the robot's state-action history to infer the social dynamics. We propose a two-stage Reinforcement Learning framework: the first learns to encode the human trajectories into social dynamics and learns a motion policy conditioned on this encoded information, the current status, and the previous action. Here, the trajectories are fully visible, i.e., assumed as privileged information. In the second stage, the trained policy operates without direct access to trajectories. Instead, the model infers the social dynamics solely from the history of previous actions and statuses in real-time. Tested on the novel Habitat 3.0 platform, SDA sets a novel state of the art (SoA) performance in finding and following humans.
Staged Contact-Aware Global Human Motion Forecasting
Sep 16, 2023



Scene-aware global human motion forecasting is critical for manifold applications, including virtual reality, robotics, and sports. The task combines human trajectory and pose forecasting within the provided scene context, which represents a significant challenge. So far, only Mao et al. NeurIPS'22 have addressed scene-aware global motion, cascading the prediction of future scene contact points and the global motion estimation. They perform the latter as the end-to-end forecasting of future trajectories and poses. However, end-to-end contrasts with the coarse-to-fine nature of the task and it results in lower performance, as we demonstrate here empirically. We propose a STAGed contact-aware global human motion forecasting STAG, a novel three-stage pipeline for predicting global human motion in a 3D environment. We first consider the scene and the respective human interaction as contact points. Secondly, we model the human trajectory forecasting within the scene, predicting the coarse motion of the human body as a whole. The third and last stage matches a plausible fine human joint motion to complement the trajectory considering the estimated contacts. Compared to the state-of-the-art (SoA), STAG achieves a 1.8% and 16.2% overall improvement in pose and trajectory prediction, respectively, on the scene-aware GTA-IM dataset. A comprehensive ablation study confirms the advantages of staged modeling over end-to-end approaches. Furthermore, we establish the significance of a newly proposed temporal counter called the "time-to-go", which tells how long it is before reaching scene contact and endpoints. Notably, STAG showcases its ability to generalize to datasets lacking a scene and achieves a new state-of-the-art performance on CMU-Mocap, without leveraging any social cues. Our code is released at: https://github.com/L-Scofano/STAG
About latent roles in forecasting players in team sports
Apr 23, 2023Forecasting players in sports has grown in popularity due to the potential for a tactical advantage and the applicability of such research to multi-agent interaction systems. Team sports contain a significant social component that influences interactions between teammates and opponents. However, it still needs to be fully exploited. In this work, we hypothesize that each participant has a specific function in each action and that role-based interaction is critical for predicting players' future moves. We create RolFor, a novel end-to-end model for Role-based Forecasting. RolFor uses a new module we developed called Ordering Neural Networks (OrderNN) to permute the order of the players such that each player is assigned to a latent role. The latent role is then modeled with a RoleGCN. Thanks to its graph representation, it provides a fully learnable adjacency matrix that captures the relationships between roles and is subsequently used to forecast the players' future trajectories. Extensive experiments on a challenging NBA basketball dataset back up the importance of roles and justify our goal of modeling them using optimizable models. When an oracle provides roles, the proposed RolFor compares favorably to the current state-of-the-art (it ranks first in terms of ADE and second in terms of FDE errors). However, training the end-to-end RolFor incurs the issues of differentiability of permutation methods, which we experimentally review. Finally, this work restates differentiable ranking as a difficult open problem and its great potential in conjunction with graph-based interaction models. Project is available at: https://www.pinlab.org/aboutlatentroles