 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSpatiotemporal Deformable Models for Long-Term Complex Activity Detection
Apr 16, 2021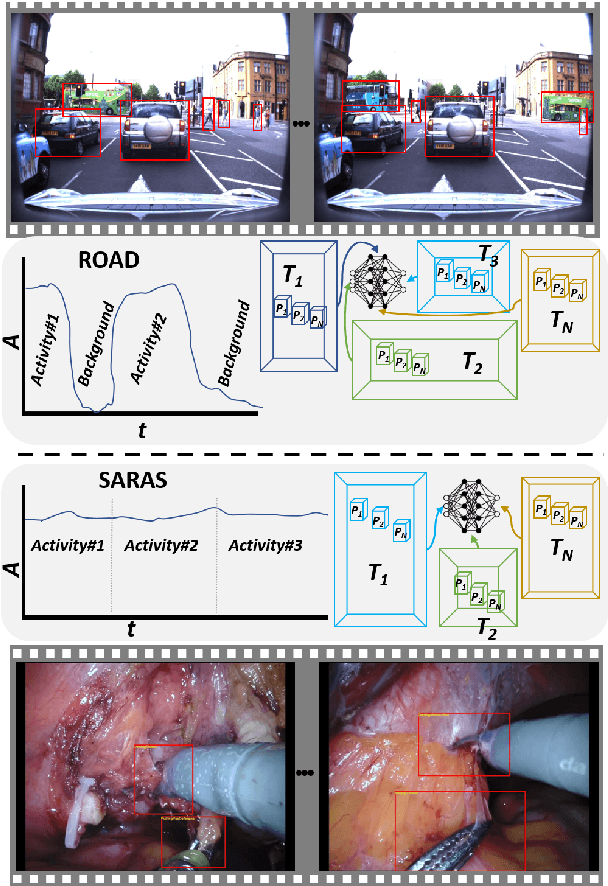
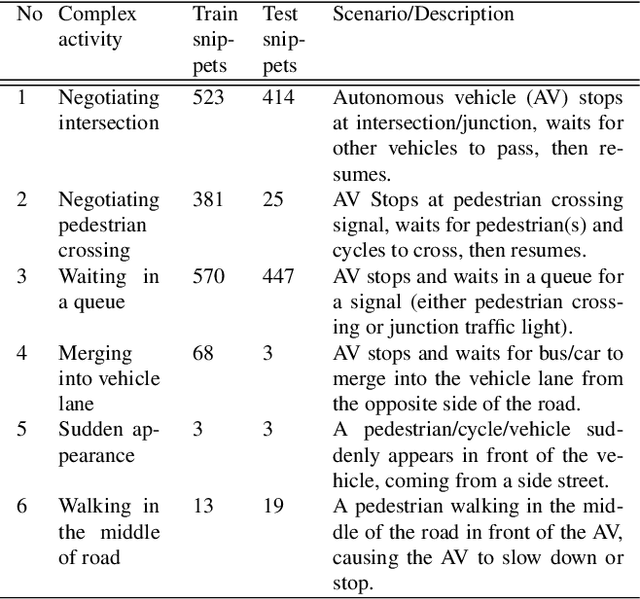
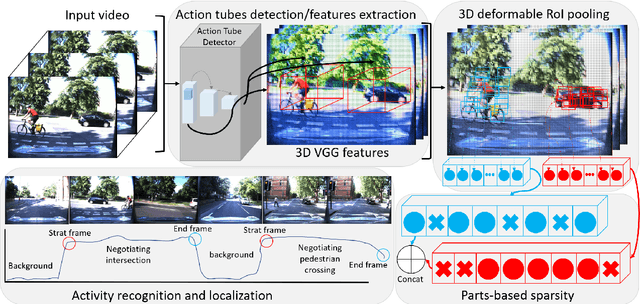
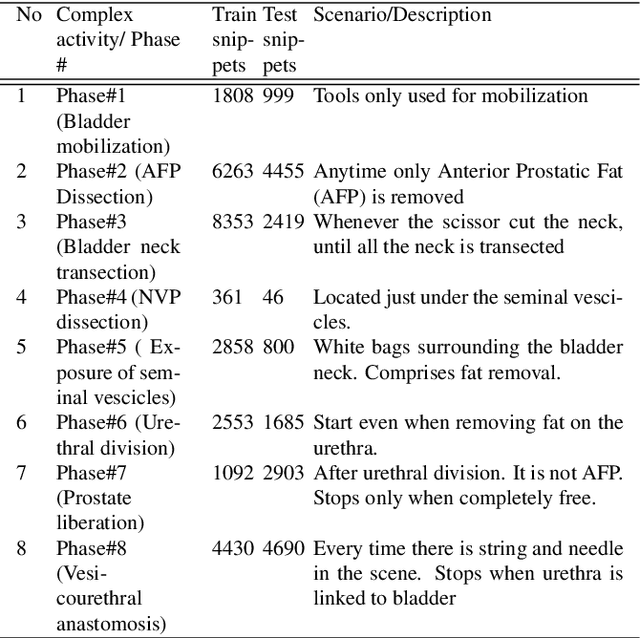
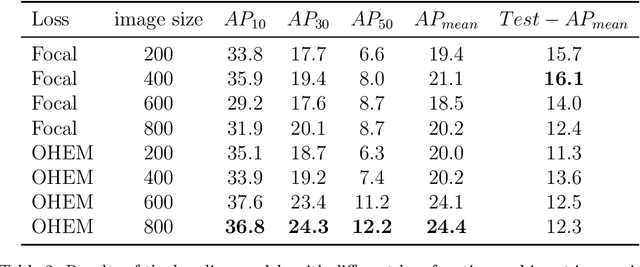
Long-term complex activity recognition and localisation can be crucial for the decision-making process of several autonomous systems, such as smart cars and surgical robots. Nonetheless, most current methods are designed to merely localise short-term action/activities or combinations of atomic actions that only last for a few frames or seconds. In this paper, we address the problem of long-term complex activity detection via a novel deformable, spatiotemporal parts-based model. Our framework consists of three main building blocks: (i) action tube detection, (ii) the modelling of the deformable geometry of parts, and (iii) a sparsity mechanism. Firstly, action tubes are detected in a series of snippets using an action tube detector. Next, a new 3D deformable RoI pooling layer is designed for learning the flexible, deformable geometry of the constellation of parts. Finally, a sparsity strategy differentiates between activated and deactivate features. We also provide temporal complex activity annotation for the recently released ROAD autonomous driving dataset and the SARAS-ESAD surgical action dataset, to validate our method and show the adaptability of our framework to different domains. As they both contain long videos portraying long-term activities they can be used as benchmarks for future work in this area.
Uncertainty measures: The big picture
Apr 14, 2021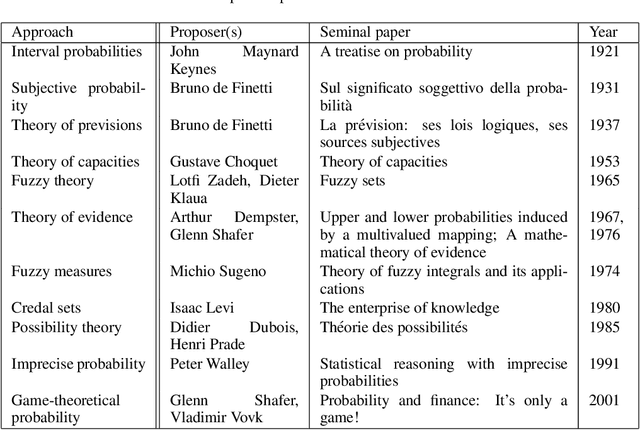
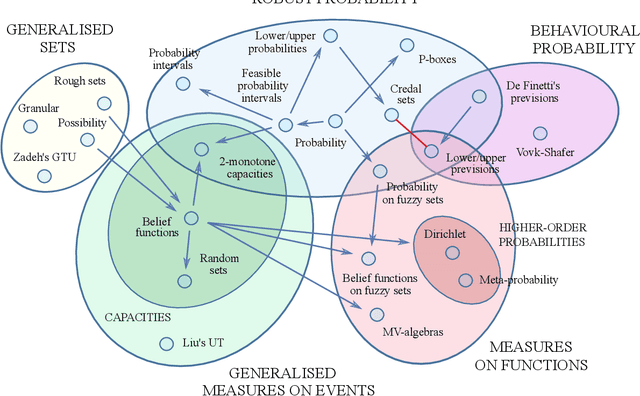
Probability theory is far from being the most general mathematical theory of uncertainty. A number of arguments point at its inability to describe second-order ('Knightian') uncertainty. In response, a wide array of theories of uncertainty have been proposed, many of them generalisations of classical probability. As we show here, such frameworks can be organised into clusters sharing a common rationale, exhibit complex links, and are characterised by different levels of generality. Our goal is a critical appraisal of the current landscape in uncertainty theory.
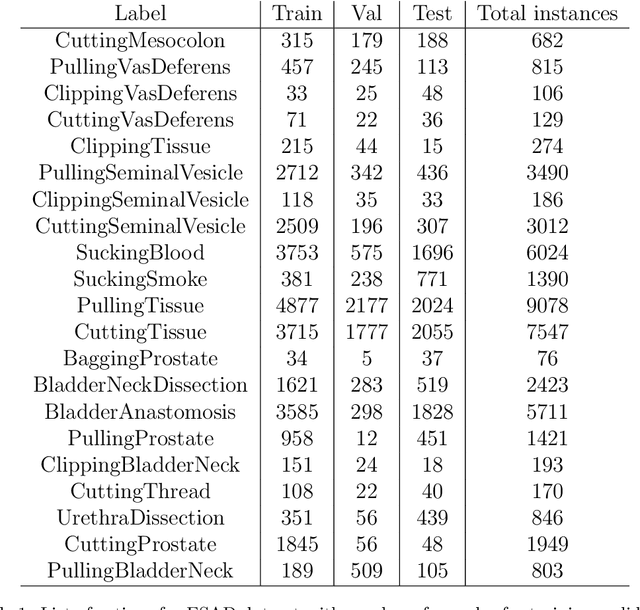
The SARAS Endoscopic Surgeon Action Detection (ESAD) dataset: Challenges and methods
Apr 07, 2021
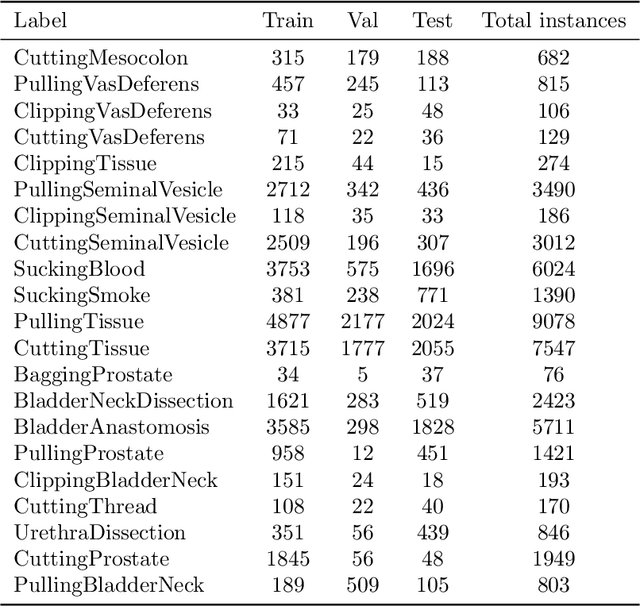
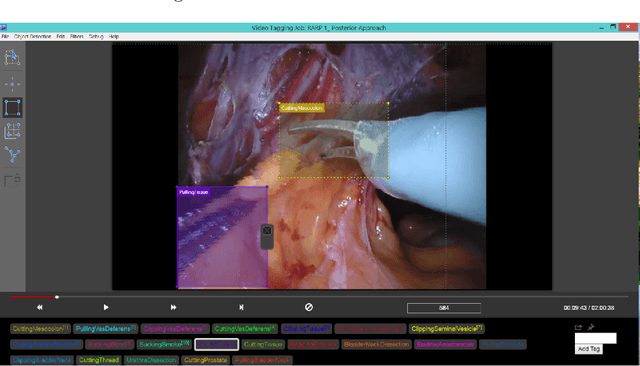
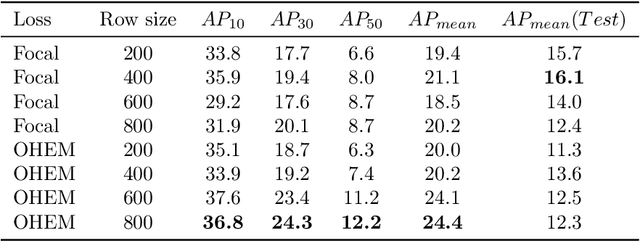
For an autonomous robotic system, monitoring surgeon actions and assisting the main surgeon during a procedure can be very challenging. The challenges come from the peculiar structure of the surgical scene, the greater similarity in appearance of actions performed via tools in a cavity compared to, say, human actions in unconstrained environments, as well as from the motion of the endoscopic camera. This paper presents ESAD, the first large-scale dataset designed to tackle the problem of surgeon action detection in endoscopic minimally invasive surgery. ESAD aims at contributing to increase the effectiveness and reliability of surgical assistant robots by realistically testing their awareness of the actions performed by a surgeon. The dataset provides bounding box annotation for 21 action classes on real endoscopic video frames captured during prostatectomy, and was used as the basis of a recent MIDL 2020 challenge. We also present an analysis of the dataset conducted using the baseline model which was released as part of the challenge, and a description of the top performing models submitted to the challenge together with the results they obtained. This study provides significant insight into what approaches can be effective and can be extended further. We believe that ESAD will serve in the future as a useful benchmark for all researchers active in surgeon action detection and assistive robotics at large.
Avalanche: an End-to-End Library for Continual Learning
Apr 01, 2021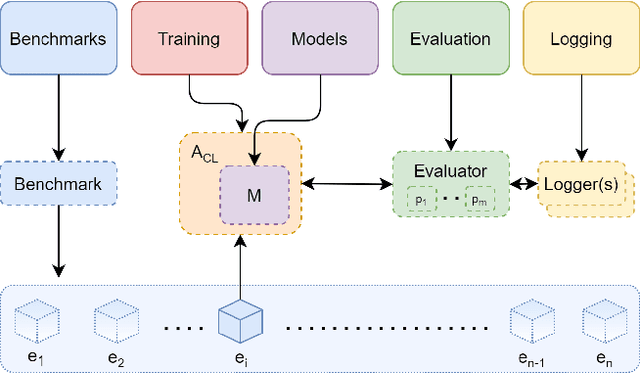

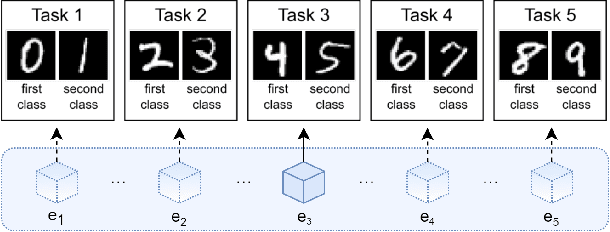

Learning continually from non-stationary data streams is a long-standing goal and a challenging problem in machine learning. Recently, we have witnessed a renewed and fast-growing interest in continual learning, especially within the deep learning community. However, algorithmic solutions are often difficult to re-implement, evaluate and port across different settings, where even results on standard benchmarks are hard to reproduce. In this work, we propose Avalanche, an open-source end-to-end library for continual learning research based on PyTorch. Avalanche is designed to provide a shared and collaborative codebase for fast prototyping, training, and reproducible evaluation of continual learning algorithms.
ROAD: The ROad event Awareness Dataset for Autonomous Driving
Feb 25, 2021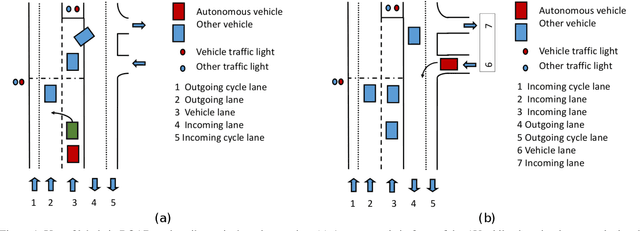

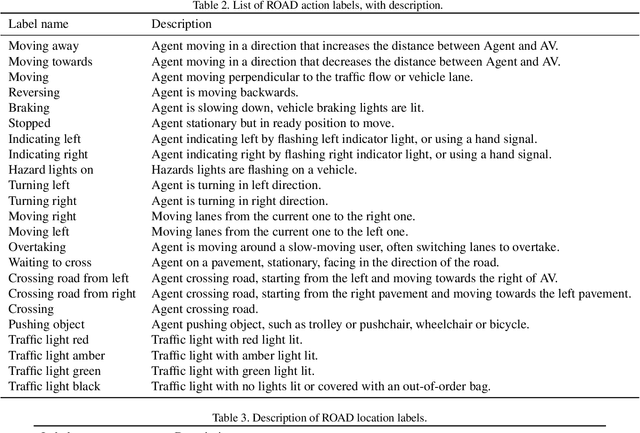

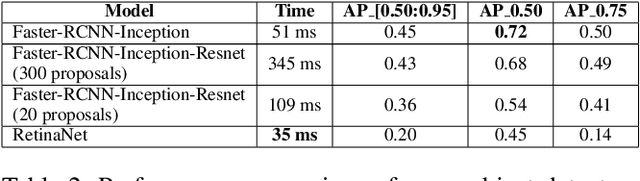
Humans approach driving in a holistic fashion which entails, in particular, understanding road events and their evolution. Injecting these capabilities in an autonomous vehicle has thus the potential to take situational awareness and decision making closer to human-level performance. To this purpose, we introduce the ROad event Awareness Dataset (ROAD) for Autonomous Driving, to our knowledge the first of its kind. ROAD is designed to test an autonomous vehicle's ability to detect road events, defined as triplets composed by a moving agent, the action(s) it performs and the corresponding scene locations. ROAD comprises 22 videos, originally from the Oxford RobotCar Dataset, annotated with bounding boxes showing the location in the image plane of each road event. We also provide as baseline a new incremental algorithm for online road event awareness, based on inflating RetinaNet along time, which achieves a mean average precision of 16.8% and 6.1% for frame-level and video-level event detection, respectively, at 50% overlap. Though promising, these figures highlight the challenges faced by situation awareness in autonomous driving. Finally, ROAD allows scholars to investigate exciting tasks such as complex (road) activity detection, future road event anticipation and the modelling of sentient road agents in terms of mental states. Dataset can be obtained from https://github.com/gurkirt/road-dataset and baseline code from https://github.com/gurkirt/3D-RetinaNet.
Articulated Shape Matching Using Laplacian Eigenfunctions and Unsupervised Point Registration
Dec 14, 2020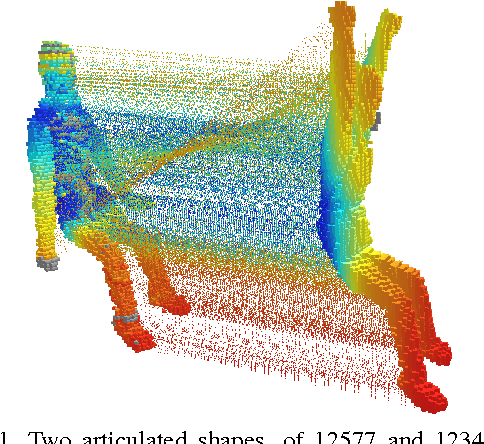
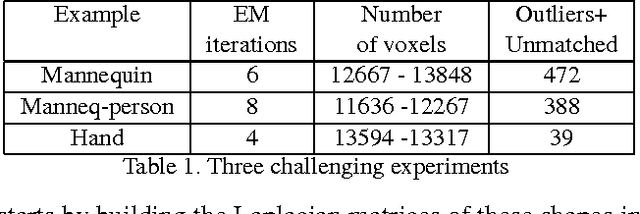
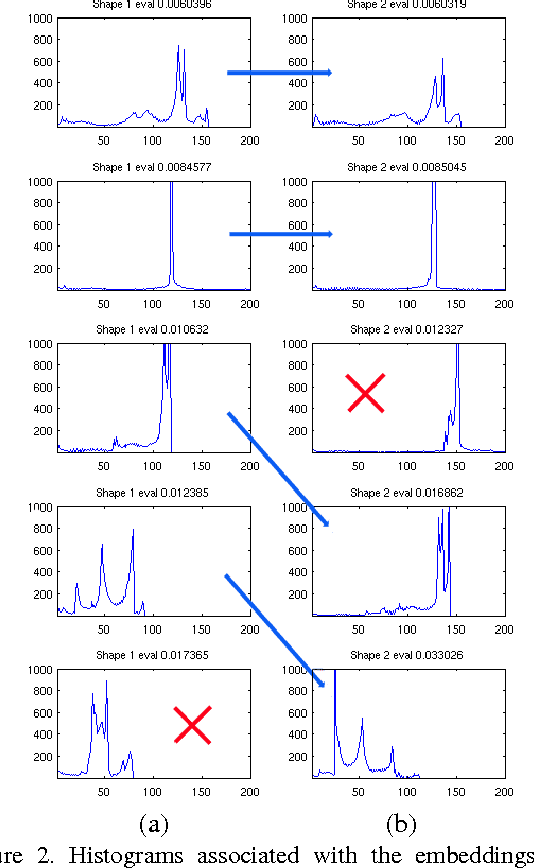
Matching articulated shapes represented by voxel-sets reduces to maximal sub-graph isomorphism when each set is described by a weighted graph. Spectral graph theory can be used to map these graphs onto lower dimensional spaces and match shapes by aligning their embeddings in virtue of their invariance to change of pose. Classical graph isomorphism schemes relying on the ordering of the eigenvalues to align the eigenspaces fail when handling large data-sets or noisy data. We derive a new formulation that finds the best alignment between two congruent $K$-dimensional sets of points by selecting the best subset of eigenfunctions of the Laplacian matrix. The selection is done by matching eigenfunction signatures built with histograms, and the retained set provides a smart initialization for the alignment problem with a considerable impact on the overall performance. Dense shape matching casted into graph matching reduces then, to point registration of embeddings under orthogonal transformations; the registration is solved using the framework of unsupervised clustering and the EM algorithm. Maximal subset matching of non identical shapes is handled by defining an appropriate outlier class. Experimental results on challenging examples show how the algorithm naturally treats changes of topology, shape variations and different sampling densities.
ESAD: Endoscopic Surgeon Action Detection Dataset
Jun 12, 2020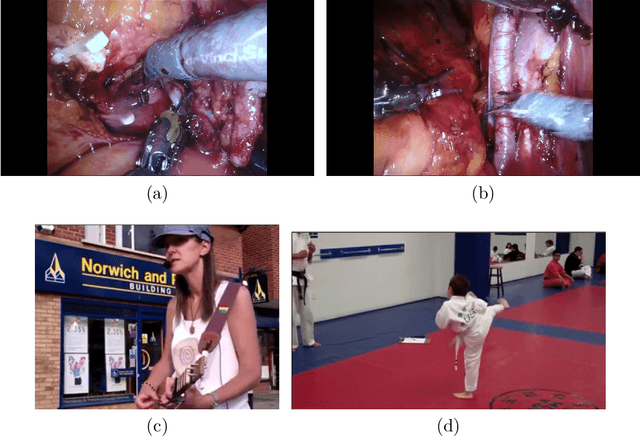
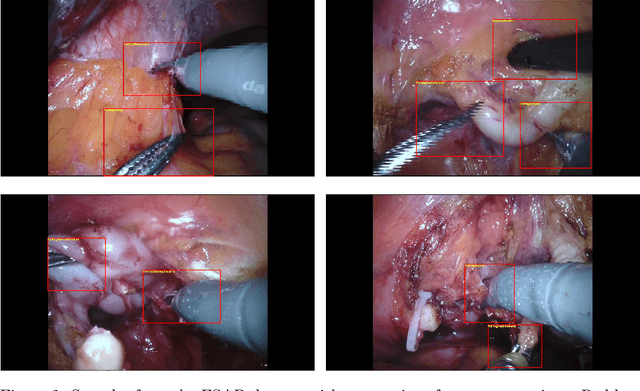
In this work, we take aim towards increasing the effectiveness of surgical assistant robots. We intended to make assistant robots safer by making them aware about the actions of surgeon, so it can take appropriate assisting actions. In other words, we aim to solve the problem of surgeon action detection in endoscopic videos. To this, we introduce a challenging dataset for surgeon action detection in real-world endoscopic videos. Action classes are picked based on the feedback of surgeons and annotated by medical professional. Given a video frame, we draw bounding box around surgical tool which is performing action and label it with action label. Finally, we presenta frame-level action detection baseline model based on recent advances in ob-ject detection. Results on our new dataset show that our presented dataset provides enough interesting challenges for future method and it can serveas strong benchmark corresponding research in surgeon action detection in endoscopic videos.
Challenges and Opportunities for Computer Vision in Real-life Soccer Analytics
Apr 13, 2020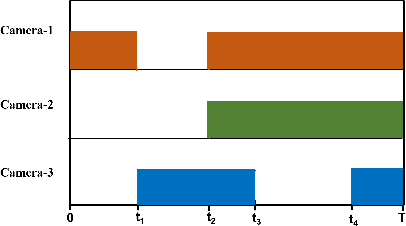
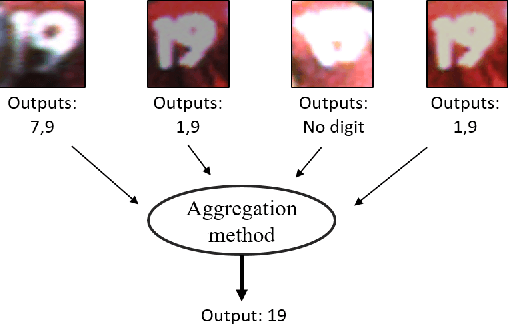
In this paper, we explore some of the applications of computer vision to sports analytics. Sport analytics deals with understanding and discovering patterns from a corpus of sports data. Analysing such data provides important performance metrics for the players, for instance in soccer matches, that could be useful for estimating their fitness and strengths. Team level statistics can also be estimated from such analysis. This paper mainly focuses on some the challenges and opportunities presented by sport video analysis in computer vision. Specifically, we use our multi-camera setup as a framework to discuss some of the real-life challenges for machine learning algorithms.
Two-Stream AMTnet for Action Detection
Apr 03, 2020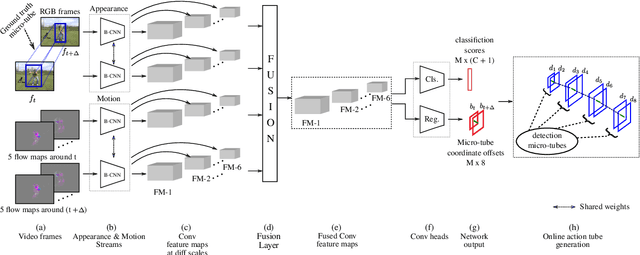
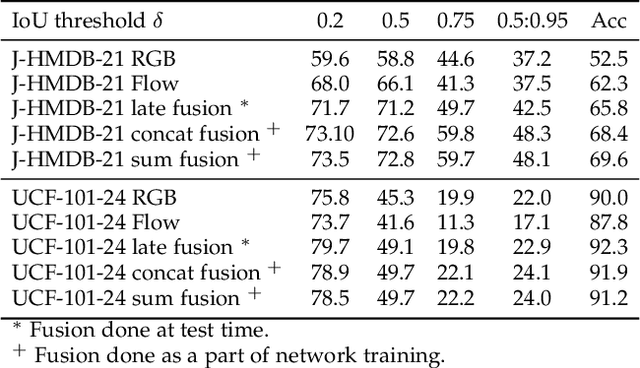
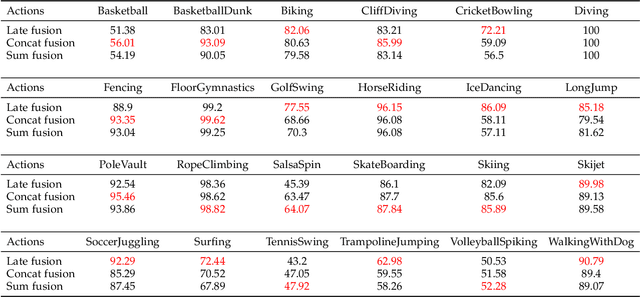
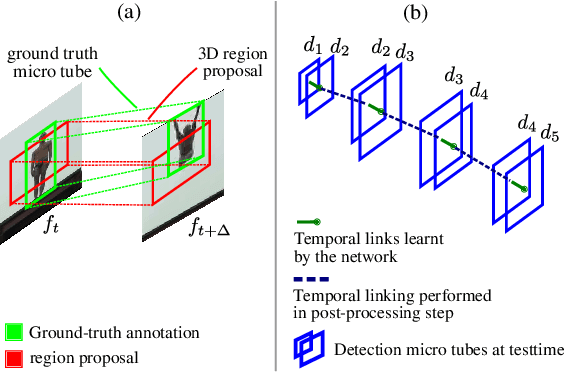
In this paper, we propose Two-Stream AMTnet, which leverages recent advances in video-based action representation[1] and incremental action tube generation[2]. Majority of the present action detectors follow a frame-based representation, a late-fusion followed by an offline action tube building steps. These are sub-optimal as: frame-based features barely encode the temporal relations; late-fusion restricts the network to learn robust spatiotemporal features; and finally, an offline action tube generation is not suitable for many real-world problems such as autonomous driving, human-robot interaction to name a few. The key contributions of this work are: (1) combining AMTnet's 3D proposal architecture with an online action tube generation technique which allows the model to learn stronger temporal features needed for accurate action detection and facilitates running inference online; (2) an efficient fusion technique allowing the deep network to learn strong spatiotemporal action representations. This is achieved by augmenting the previous Action Micro-Tube (AMTnet) action detection framework in three distinct ways: by adding a parallel motion stIn this paper, we propose a new deep neural network architecture for online action detection, termed ream to the original appearance one in AMTnet; (2) in opposition to state-of-the-art action detectors which train appearance and motion streams separately, and use a test time late fusion scheme to fuse RGB and flow cues, by jointly training both streams in an end-to-end fashion and merging RGB and optical flow features at training time; (3) by introducing an online action tube generation algorithm which works at video-level, and in real-time (when exploiting only appearance features). Two-Stream AMTnet exhibits superior action detection performance over state-of-the-art approaches on the standard action detection benchmarks.
Datamorphic Testing: A Methodology for Testing AI Applications
Dec 10, 2019

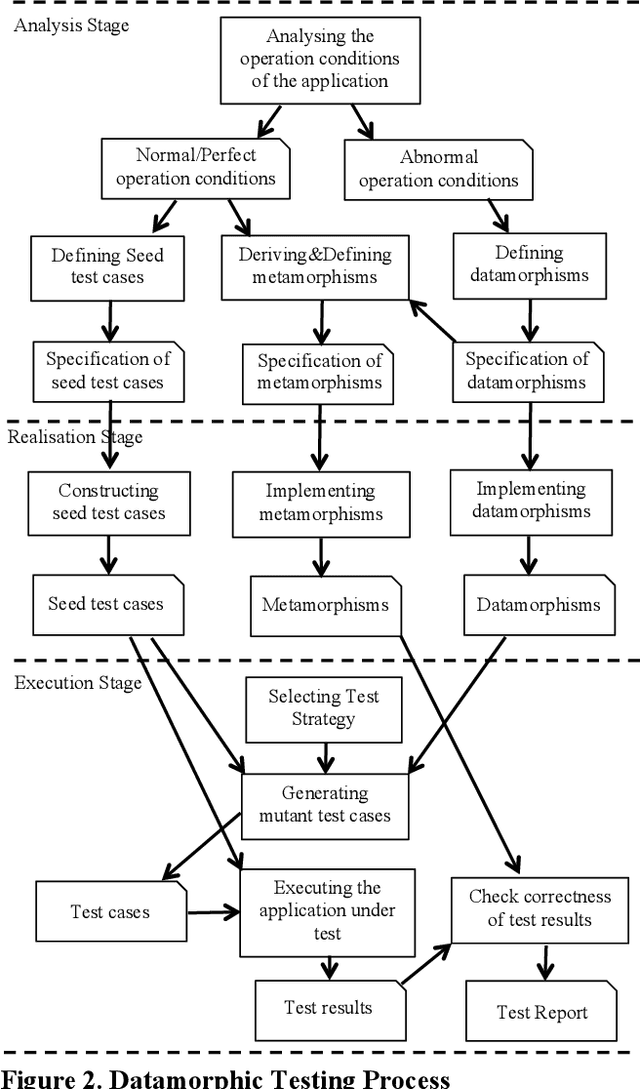
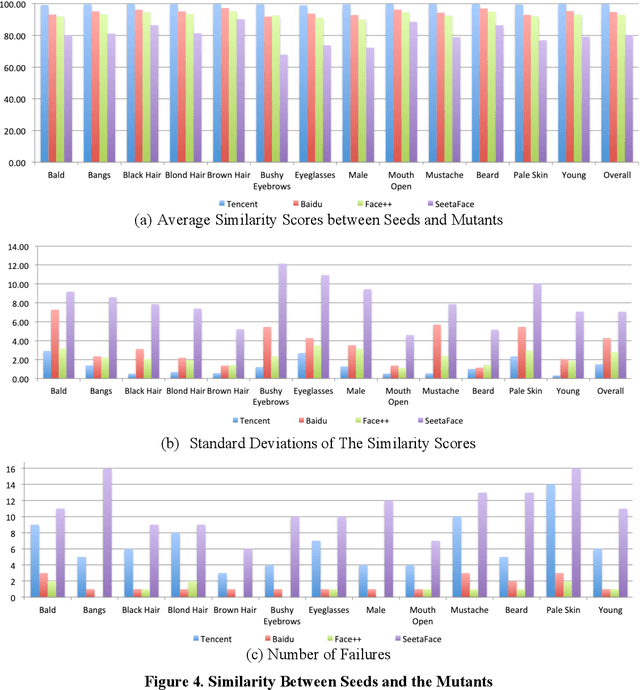
With the rapid growth of the applications of machine learning (ML) and other artificial intelligence (AI) techniques, adequate testing has become a necessity to ensure their quality. This paper identifies the characteristics of AI applications that distinguish them from traditional software, and analyses the main difficulties in applying existing testing methods. Based on this analysis, we propose a new method called datamorphic testing and illustrate the method with an example of testing face recognition applications. We also report an experiment with four real industrial application systems of face recognition to validate the proposed approach.