 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMorig: Motion-aware rigging of character meshes from point clouds
Oct 17, 2022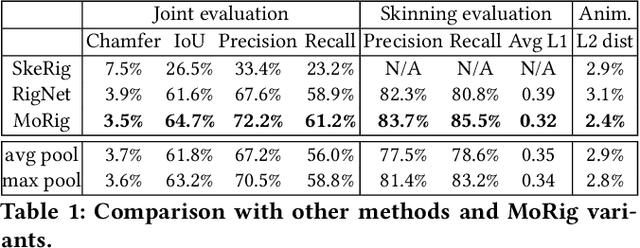
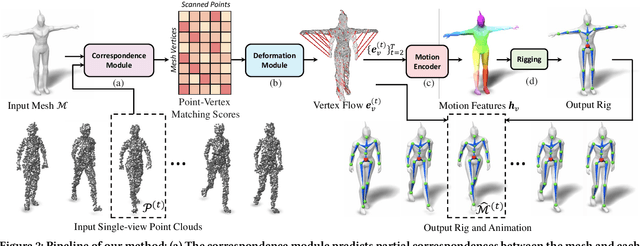
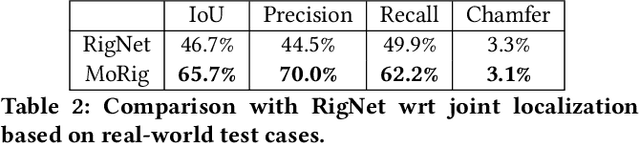

We present MoRig, a method that automatically rigs character meshes driven by single-view point cloud streams capturing the motion of performing characters. Our method is also able to animate the 3D meshes according to the captured point cloud motion. MoRig's neural network encodes motion cues from the point clouds into features that are informative about the articulated parts of the performing character. These motion-aware features guide the inference of an appropriate skeletal rig for the input mesh, which is then animated based on the point cloud motion. Our method can rig and animate diverse characters, including humanoids, quadrupeds, and toys with varying articulation. It accounts for occluded regions in the point clouds and mismatches in the part proportions between the input mesh and captured character. Compared to other rigging approaches that ignore motion cues, MoRig produces more accurate rigs, well-suited for re-targeting motion from captured characters.
MvDeCor: Multi-view Dense Correspondence Learning for Fine-grained 3D Segmentation
Aug 18, 2022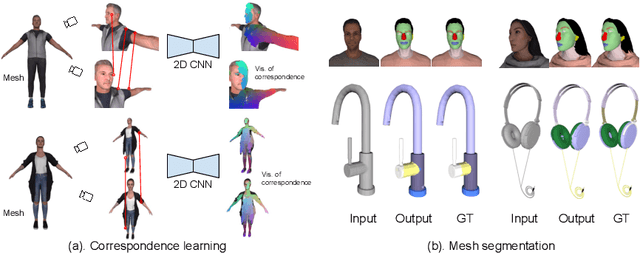
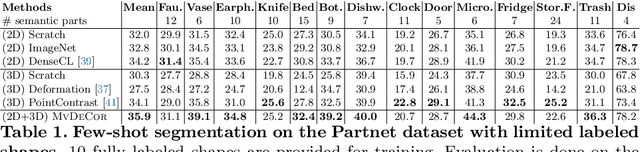
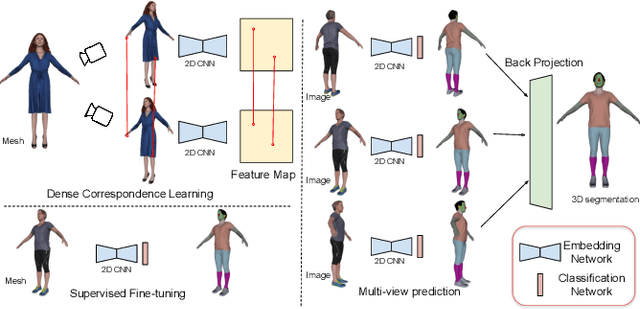
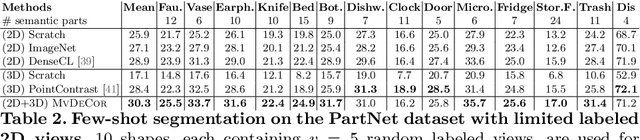
We propose to utilize self-supervised techniques in the 2D domain for fine-grained 3D shape segmentation tasks. This is inspired by the observation that view-based surface representations are more effective at modeling high-resolution surface details and texture than their 3D counterparts based on point clouds or voxel occupancy. Specifically, given a 3D shape, we render it from multiple views, and set up a dense correspondence learning task within the contrastive learning framework. As a result, the learned 2D representations are view-invariant and geometrically consistent, leading to better generalization when trained on a limited number of labeled shapes compared to alternatives that utilize self-supervision in 2D or 3D alone. Experiments on textured (RenderPeople) and untextured (PartNet) 3D datasets show that our method outperforms state-of-the-art alternatives in fine-grained part segmentation. The improvements over baselines are greater when only a sparse set of views is available for training or when shapes are textured, indicating that MvDeCor benefits from both 2D processing and 3D geometric reasoning.
Audio-driven Neural Gesture Reenactment with Video Motion Graphs
Jul 23, 2022
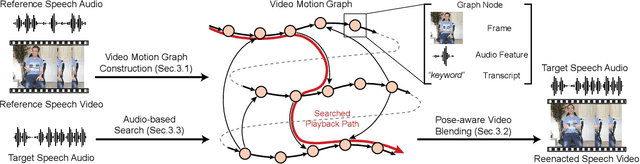
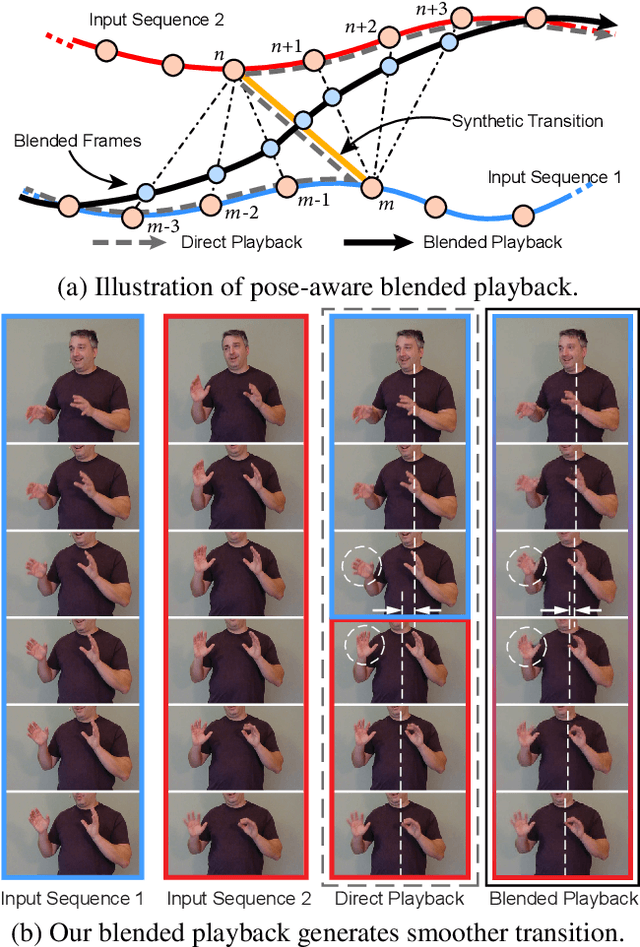
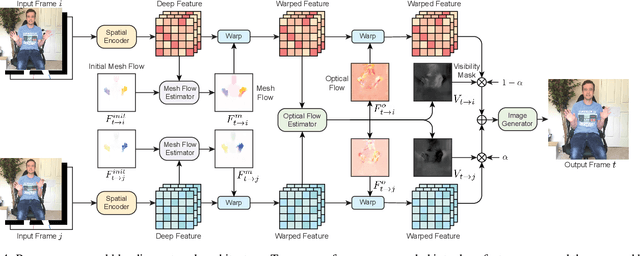
Human speech is often accompanied by body gestures including arm and hand gestures. We present a method that reenacts a high-quality video with gestures matching a target speech audio. The key idea of our method is to split and re-assemble clips from a reference video through a novel video motion graph encoding valid transitions between clips. To seamlessly connect different clips in the reenactment, we propose a pose-aware video blending network which synthesizes video frames around the stitched frames between two clips. Moreover, we developed an audio-based gesture searching algorithm to find the optimal order of the reenacted frames. Our system generates reenactments that are consistent with both the audio rhythms and the speech content. We evaluate our synthesized video quality quantitatively, qualitatively, and with user studies, demonstrating that our method produces videos of much higher quality and consistency with the target audio compared to previous work and baselines.
APES: Articulated Part Extraction from Sprite Sheets
Jun 04, 2022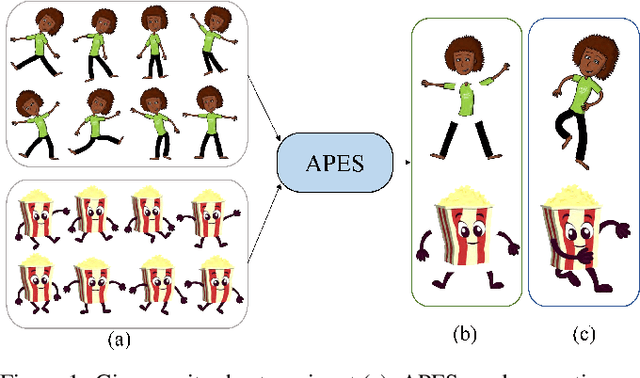
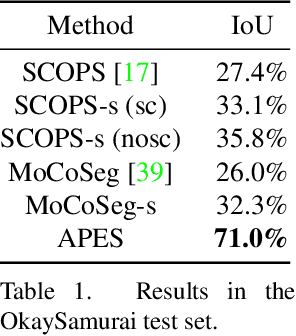


Rigged puppets are one of the most prevalent representations to create 2D character animations. Creating these puppets requires partitioning characters into independently moving parts. In this work, we present a method to automatically identify such articulated parts from a small set of character poses shown in a sprite sheet, which is an illustration of the character that artists often draw before puppet creation. Our method is trained to infer articulated parts, e.g. head, torso and limbs, that can be re-assembled to best reconstruct the given poses. Our results demonstrate significantly better performance than alternatives qualitatively and quantitatively.Our project page https://zhan-xu.github.io/parts/ includes our code and data.
ANISE: Assembly-based Neural Implicit Surface rEconstruction
May 27, 2022
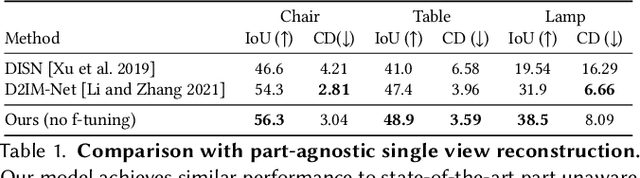

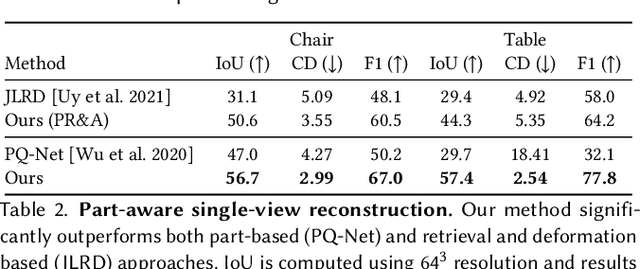
We present ANISE, a method that reconstructs a 3D shape from partial observations (images or sparse point clouds) using a part-aware neural implicit shape representation. It is formulated as an assembly of neural implicit functions, each representing a different shape part. In contrast to previous approaches, the prediction of this representation proceeds in a coarse-to-fine manner. Our network first predicts part transformations which are associated with part neural implicit functions conditioned on those transformations. The part implicit functions can then be combined into a single, coherent shape, enabling part-aware shape reconstructions from images and point clouds. Those reconstructions can be obtained in two ways: (i) by directly decoding combining the refined part implicit functions; or (ii) by using part latents to query similar parts in a part database and assembling them in a single shape. We demonstrate that, when performing reconstruction by decoding part representations into implicit functions, our method achieves state-of-the-art part-aware reconstruction results from both images and sparse point clouds. When reconstructing shapes by assembling parts queried from a dataset, our approach significantly outperforms traditional shape retrieval methods even when significantly restricting the size of the shape database. We present our results in well-known sparse point cloud reconstruction and single-view reconstruction benchmarks.
ASSET: Autoregressive Semantic Scene Editing with Transformers at High Resolutions
May 24, 2022
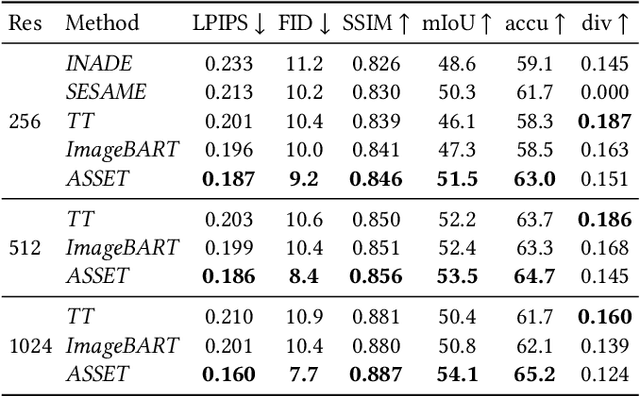
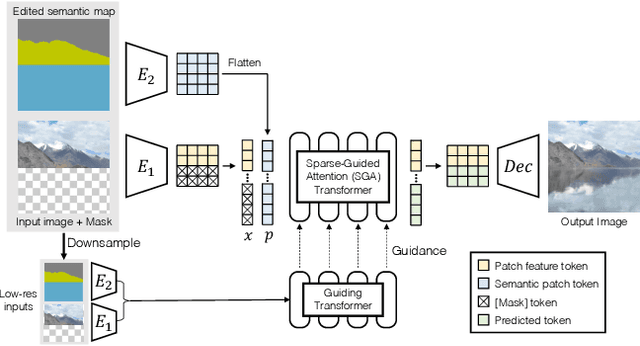
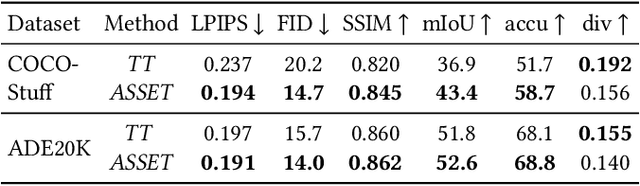
We present ASSET, a neural architecture for automatically modifying an input high-resolution image according to a user's edits on its semantic segmentation map. Our architecture is based on a transformer with a novel attention mechanism. Our key idea is to sparsify the transformer's attention matrix at high resolutions, guided by dense attention extracted at lower image resolutions. While previous attention mechanisms are computationally too expensive for handling high-resolution images or are overly constrained within specific image regions hampering long-range interactions, our novel attention mechanism is both computationally efficient and effective. Our sparsified attention mechanism is able to capture long-range interactions and context, leading to synthesizing interesting phenomena in scenes, such as reflections of landscapes onto water or flora consistent with the rest of the landscape, that were not possible to generate reliably with previous convnets and transformer approaches. We present qualitative and quantitative results, along with user studies, demonstrating the effectiveness of our method.
Projective Urban Texturing
Feb 04, 2022
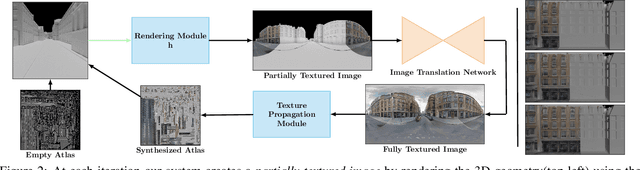
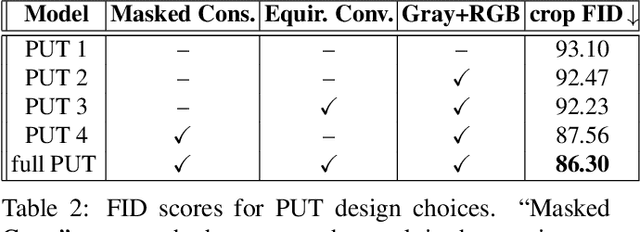

This paper proposes a method for automatic generation of textures for 3D city meshes in immersive urban environments. Many recent pipelines capture or synthesize large quantities of city geometry using scanners or procedural modeling pipelines. Such geometry is intricate and realistic, however the generation of photo-realistic textures for such large scenes remains a problem. We propose to generate textures for input target 3D meshes driven by the textural style present in readily available datasets of panoramic photos capturing urban environments. Re-targeting such 2D datasets to 3D geometry is challenging because the underlying shape, size, and layout of the urban structures in the photos do not correspond to the ones in the target meshes. Photos also often have objects (e.g., trees, vehicles) that may not even be present in the target geometry. To address these issues we present a method, called Projective Urban Texturing (PUT), which re-targets textural style from real-world panoramic images to unseen urban meshes. PUT relies on contrastive and adversarial training of a neural architecture designed for unpaired image-to-texture translation. The generated textures are stored in a texture atlas applied to the target 3D mesh geometry. To promote texture consistency, PUT employs an iterative procedure in which texture synthesis is conditioned on previously generated, adjacent textures. We demonstrate both quantitative and qualitative evaluation of the generated textures.
SurFit: Learning to Fit Surfaces Improves Few Shot Learning on Point Clouds
Dec 27, 2021

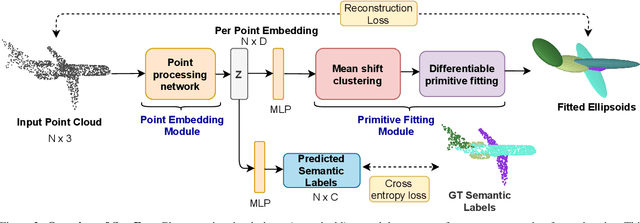
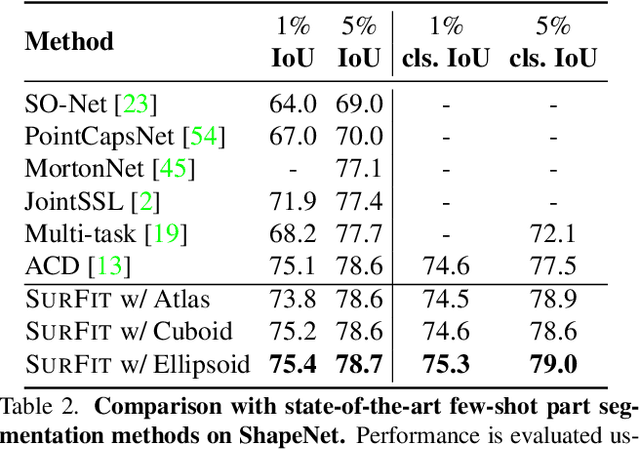
We present SurFit, a simple approach for label efficient learning of 3D shape segmentation networks. SurFit is based on a self-supervised task of decomposing the surface of a 3D shape into geometric primitives. It can be readily applied to existing network architectures for 3D shape segmentation and improves their performance in the few-shot setting, as we demonstrate in the widely used ShapeNet and PartNet benchmarks. SurFit outperforms the prior state-of-the-art in this setting, suggesting that decomposability into primitives is a useful prior for learning representations predictive of semantic parts. We present a number of experiments varying the choice of geometric primitives and downstream tasks to demonstrate the effectiveness of the method.
BuildingNet: Learning to Label 3D Buildings
Oct 11, 2021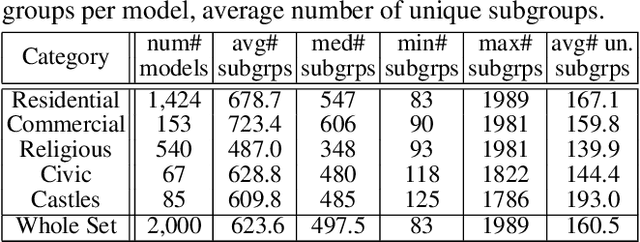
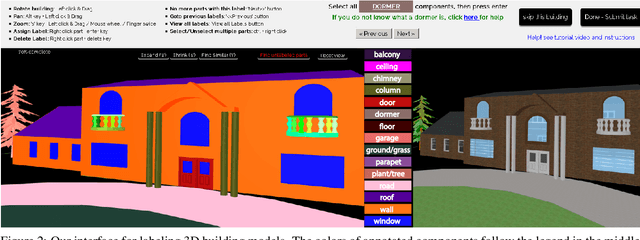
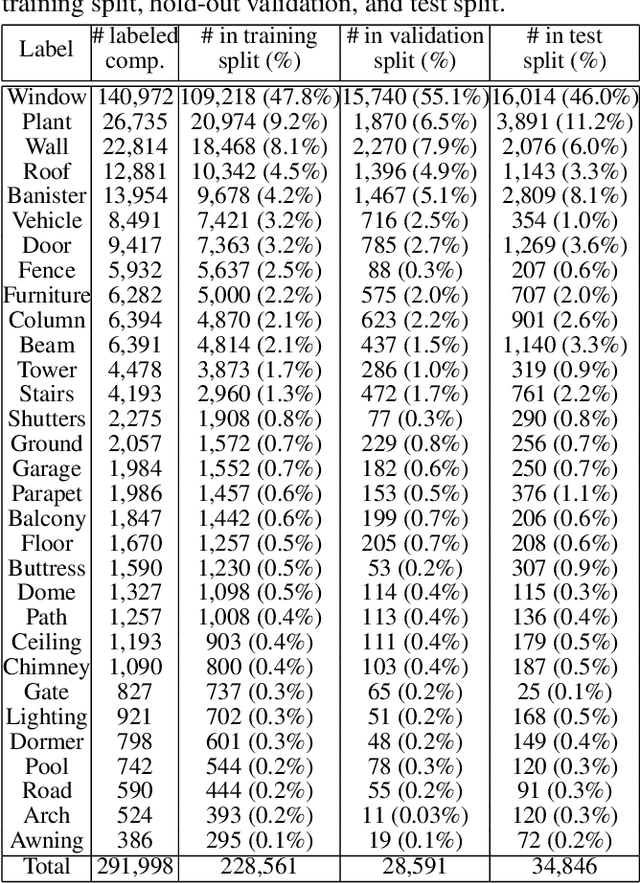
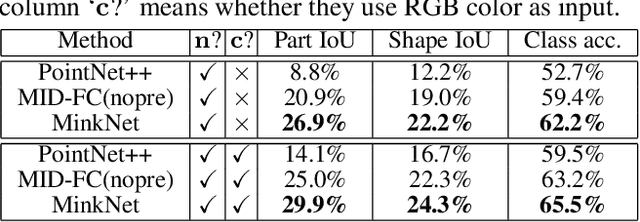
We introduce BuildingNet: (a) a large-scale dataset of 3D building models whose exteriors are consistently labeled, (b) a graph neural network that labels building meshes by analyzing spatial and structural relations of their geometric primitives. To create our dataset, we used crowdsourcing combined with expert guidance, resulting in 513K annotated mesh primitives, grouped into 292K semantic part components across 2K building models. The dataset covers several building categories, such as houses, churches, skyscrapers, town halls, libraries, and castles. We include a benchmark for evaluating mesh and point cloud labeling. Buildings have more challenging structural complexity compared to objects in existing benchmarks (e.g., ShapeNet, PartNet), thus, we hope that our dataset can nurture the development of algorithms that are able to cope with such large-scale geometric data for both vision and graphics tasks e.g., 3D semantic segmentation, part-based generative models, correspondences, texturing, and analysis of point cloud data acquired from real-world buildings. Finally, we show that our mesh-based graph neural network significantly improves performance over several baselines for labeling 3D meshes.
Neural Strokes: Stylized Line Drawing of 3D Shapes
Oct 08, 2021
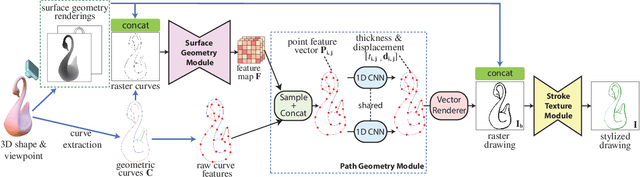

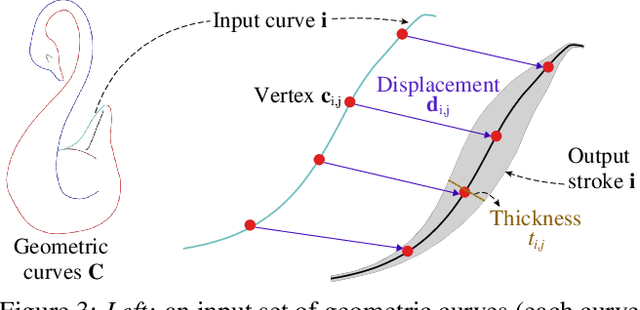
This paper introduces a model for producing stylized line drawings from 3D shapes. The model takes a 3D shape and a viewpoint as input, and outputs a drawing with textured strokes, with variations in stroke thickness, deformation, and color learned from an artist's style. The model is fully differentiable. We train its parameters from a single training drawing of another 3D shape. We show that, in contrast to previous image-based methods, the use of a geometric representation of 3D shape and 2D strokes allows the model to transfer important aspects of shape and texture style while preserving contours. Our method outputs the resulting drawing in a vector representation, enabling richer downstream analysis or editing in interactive applications.