 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMachine Learning for Detection and Severity Estimation of Sweetpotato Weevil Damage in Field and Lab Conditions
Feb 06, 2026Sweetpotato weevils (Cylas spp.) are considered among the most destructive pests impacting sweetpotato production, particularly in sub-Saharan Africa. Traditional methods for assessing weevil damage, predominantly relying on manual scoring, are labour-intensive, subjective, and often yield inconsistent results. These challenges significantly hinder breeding programs aimed at developing resilient sweetpotato varieties. This study introduces a computer vision-based approach for the automated evaluation of weevil damage in both field and laboratory contexts. In the field settings, we collected data to train classification models to predict root-damage severity levels, achieving a test accuracy of 71.43%. Additionally, we established a laboratory dataset and designed an object detection pipeline employing YOLO12, a leading real-time detection model. This methodology incorporated a two-stage laboratory pipeline that combined root segmentation with a tiling strategy to improve the detectability of small objects. The resulting model demonstrated a mean average precision of 77.7% in identifying minute weevil feeding holes. Our findings indicate that computer vision technologies can provide efficient, objective, and scalable assessment tools that align seamlessly with contemporary breeding workflows. These advancements represent a significant improvement in enhancing phenotyping efficiency within sweetpotato breeding programs and play a crucial role in mitigating the detrimental effects of weevils on food security.
WAXAL: A Large-Scale Multilingual African Language Speech Corpus
Feb 02, 2026The advancement of speech technology has predominantly favored high-resource languages, creating a significant digital divide for speakers of most Sub-Saharan African languages. To address this gap, we introduce WAXAL, a large-scale, openly accessible speech dataset for 21 languages representing over 100 million speakers. The collection consists of two main components: an Automated Speech Recognition (ASR) dataset containing approximately 1,250 hours of transcribed, natural speech from a diverse range of speakers, and a Text-to-Speech (TTS) dataset with over 180 hours of high-quality, single-speaker recordings reading phonetically balanced scripts. This paper details our methodology for data collection, annotation, and quality control, which involved partnerships with four African academic and community organizations. We provide a detailed statistical overview of the dataset and discuss its potential limitations and ethical considerations. The WAXAL datasets are released at https://huggingface.co/datasets/google/WaxalNLP under the permissive CC-BY-4.0 license to catalyze research, enable the development of inclusive technologies, and serve as a vital resource for the digital preservation of these languages.
mSTEB: Massively Multilingual Evaluation of LLMs on Speech and Text Tasks
Jun 10, 2025Large Language models (LLMs) have demonstrated impressive performance on a wide range of tasks, including in multimodal settings such as speech. However, their evaluation is often limited to English and a few high-resource languages. For low-resource languages, there is no standardized evaluation benchmark. In this paper, we address this gap by introducing mSTEB, a new benchmark to evaluate the performance of LLMs on a wide range of tasks covering language identification, text classification, question answering, and translation tasks on both speech and text modalities. We evaluated the performance of leading LLMs such as Gemini 2.0 Flash and GPT-4o (Audio) and state-of-the-art open models such as Qwen 2 Audio and Gemma 3 27B. Our evaluation shows a wide gap in performance between high-resource and low-resource languages, especially for languages spoken in Africa and Americas/Oceania. Our findings show that more investment is needed to address their under-representation in LLMs coverage.
Amplify Initiative: Building A Localized Data Platform for Globalized AI
Apr 18, 2025Current AI models often fail to account for local context and language, given the predominance of English and Western internet content in their training data. This hinders the global relevance, usefulness, and safety of these models as they gain more users around the globe. Amplify Initiative, a data platform and methodology, leverages expert communities to collect diverse, high-quality data to address the limitations of these models. The platform is designed to enable co-creation of datasets, provide access to high-quality multilingual datasets, and offer recognition to data authors. This paper presents the approach to co-creating datasets with domain experts (e.g., health workers, teachers) through a pilot conducted in Sub-Saharan Africa (Ghana, Kenya, Malawi, Nigeria, and Uganda). In partnership with local researchers situated in these countries, the pilot demonstrated an end-to-end approach to co-creating data with 155 experts in sensitive domains (e.g., physicians, bankers, anthropologists, human and civil rights advocates). This approach, implemented with an Android app, resulted in an annotated dataset of 8,091 adversarial queries in seven languages (e.g., Luganda, Swahili, Chichewa), capturing nuanced and contextual information related to key themes such as misinformation and public interest topics. This dataset in turn can be used to evaluate models for their safety and cultural relevance within the context of these languages.
Enhanced Infield Agriculture with Interpretable Machine Learning Approaches for Crop Classification
Aug 22, 2024



The increasing popularity of Artificial Intelligence in recent years has led to a surge in interest in image classification, especially in the agricultural sector. With the help of Computer Vision, Machine Learning, and Deep Learning, the sector has undergone a significant transformation, leading to the development of new techniques for crop classification in the field. Despite the extensive research on various image classification techniques, most have limitations such as low accuracy, limited use of data, and a lack of reporting model size and prediction. The most significant limitation of all is the need for model explainability. This research evaluates four different approaches for crop classification, namely traditional ML with handcrafted feature extraction methods like SIFT, ORB, and Color Histogram; Custom Designed CNN and established DL architecture like AlexNet; transfer learning on five models pre-trained using ImageNet such as EfficientNetV2, ResNet152V2, Xception, Inception-ResNetV2, MobileNetV3; and cutting-edge foundation models like YOLOv8 and DINOv2, a self-supervised Vision Transformer Model. All models performed well, but Xception outperformed all of them in terms of generalization, achieving 98% accuracy on the test data, with a model size of 80.03 MB and a prediction time of 0.0633 seconds. A key aspect of this research was the application of Explainable AI to provide the explainability of all the models. This journal presents the explainability of Xception model with LIME, SHAP, and GradCAM, ensuring transparency and trustworthiness in the models' predictions. This study highlights the importance of selecting the right model according to task-specific needs. It also underscores the important role of explainability in deploying AI in agriculture, providing insightful information to help enhance AI-driven crop management strategies.
Building a Luganda Text-to-Speech Model From Crowdsourced Data
May 16, 2024

Text-to-speech (TTS) development for African languages such as Luganda is still limited, primarily due to the scarcity of high-quality, single-speaker recordings essential for training TTS models. Prior work has focused on utilizing the Luganda Common Voice recordings of multiple speakers aged between 20-49. Although the generated speech is intelligible, it is still of lower quality than the model trained on studio-grade recordings. This is due to the insufficient data preprocessing methods applied to improve the quality of the Common Voice recordings. Furthermore, speech convergence is more difficult to achieve due to varying intonations, as well as background noise. In this paper, we show that the quality of Luganda TTS from Common Voice can improve by training on multiple speakers of close intonation in addition to further preprocessing of the training data. Specifically, we selected six female speakers with close intonation determined by subjectively listening and comparing their voice recordings. In addition to trimming out silent portions from the beginning and end of the recordings, we applied a pre-trained speech enhancement model to reduce background noise and enhance audio quality. We also utilized a pre-trained, non-intrusive, self-supervised Mean Opinion Score (MOS) estimation model to filter recordings with an estimated MOS over 3.5, indicating high perceived quality. Subjective MOS evaluations from nine native Luganda speakers demonstrate that our TTS model achieves a significantly better MOS of 3.55 compared to the reported 2.5 MOS of the existing model. Moreover, for a fair comparison, our model trained on six speakers outperforms models trained on a single-speaker (3.13 MOS) or two speakers (3.22 MOS). This showcases the effectiveness of compensating for the lack of data from one speaker with data from multiple speakers of close intonation to improve TTS quality.
The Makerere Radio Speech Corpus: A Luganda Radio Corpus for Automatic Speech Recognition
Jun 20, 2022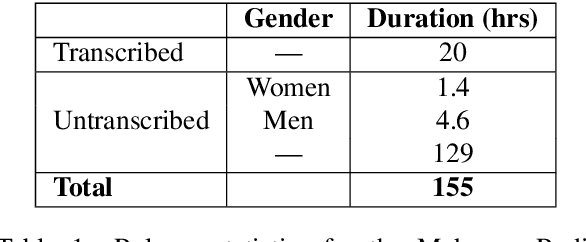
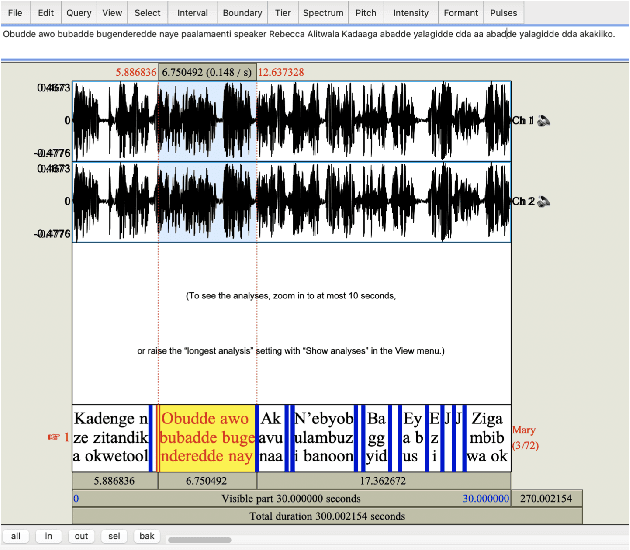

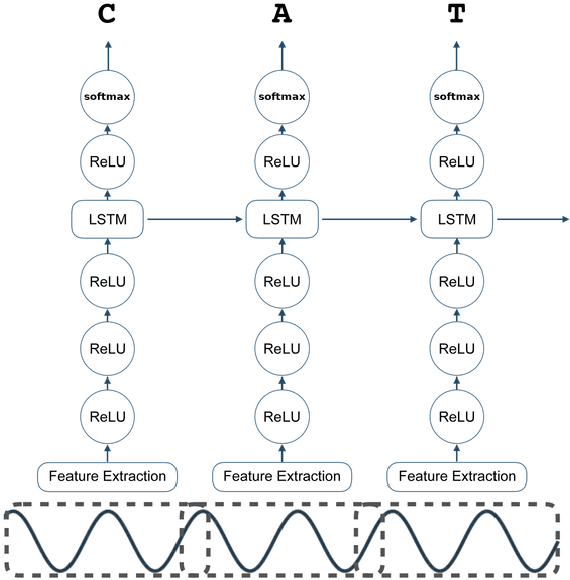
Building a usable radio monitoring automatic speech recognition (ASR) system is a challenging task for under-resourced languages and yet this is paramount in societies where radio is the main medium of public communication and discussions. Initial efforts by the United Nations in Uganda have proved how understanding the perceptions of rural people who are excluded from social media is important in national planning. However, these efforts are being challenged by the absence of transcribed speech datasets. In this paper, The Makerere Artificial Intelligence research lab releases a Luganda radio speech corpus of 155 hours. To our knowledge, this is the first publicly available radio dataset in sub-Saharan Africa. The paper describes the development of the voice corpus and presents baseline Luganda ASR performance results using Coqui STT toolkit, an open source speech recognition toolkit.
Misinformation detection in Luganda-English code-mixed social media text
Apr 03, 2021
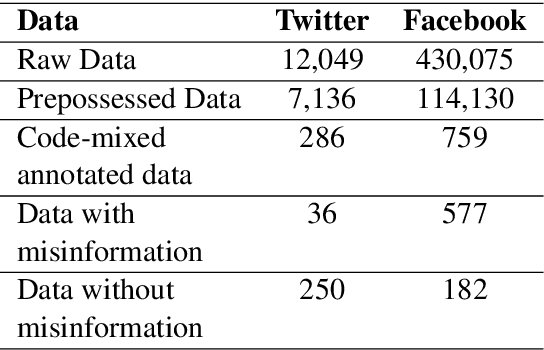

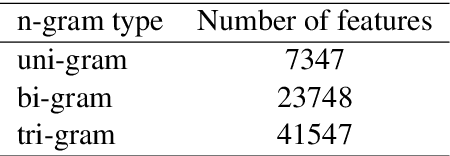
The increasing occurrence, forms, and negative effects of misinformation on social media platforms has necessitated more misinformation detection tools. Currently, work is being done addressing COVID-19 misinformation however, there are no misinformation detection tools for any of the 40 distinct indigenous Ugandan languages. This paper addresses this gap by presenting basic language resources and a misinformation detection data set based on code-mixed Luganda-English messages sourced from the Facebook and Twitter social media platforms. Several machine learning methods are applied on the misinformation detection data set to develop classification models for detecting whether a code-mixed Luganda-English message contains misinformation or not. A 10-fold cross validation evaluation of the classification methods in an experimental misinformation detection task shows that a Discriminative Multinomial Naive Bayes (DMNB) method achieves the highest accuracy and F-measure of 78.19% and 77.90% respectively. Also, Support Vector Machine and Bagging ensemble classification models achieve comparable results. These results are promising since the machine learning models are based on n-gram features from only the misinformation detection dataset.
MasakhaNER: Named Entity Recognition for African Languages
Mar 22, 2021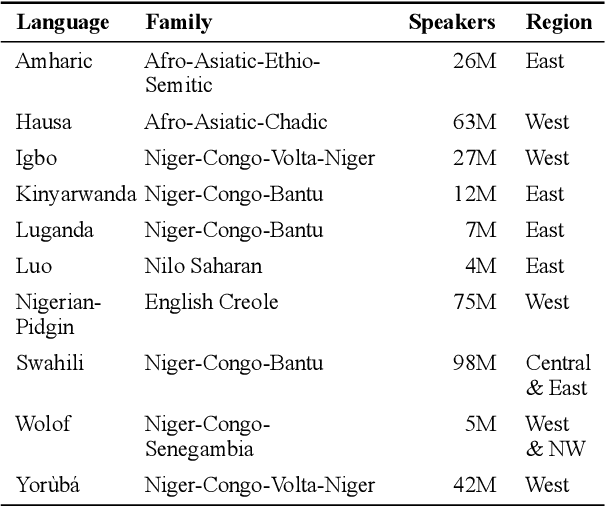

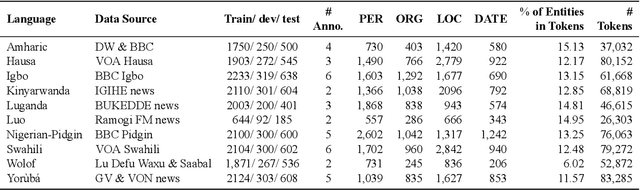
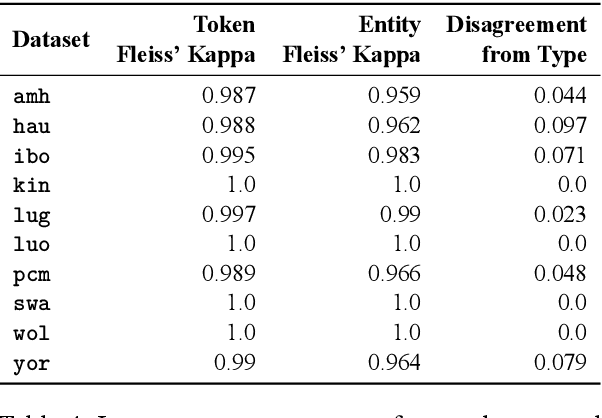
We take a step towards addressing the under-representation of the African continent in NLP research by creating the first large publicly available high-quality dataset for named entity recognition (NER) in ten African languages, bringing together a variety of stakeholders. We detail characteristics of the languages to help researchers understand the challenges that these languages pose for NER. We analyze our datasets and conduct an extensive empirical evaluation of state-of-the-art methods across both supervised and transfer learning settings. We release the data, code, and models in order to inspire future research on African NLP.
Scoring Root Necrosis in Cassava Using Semantic Segmentation
May 07, 2020


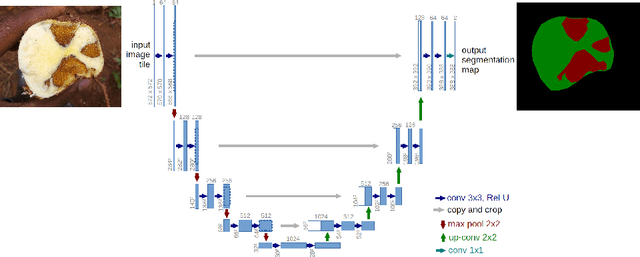
Cassava a major food crop in many parts of Africa, has majorly been affected by Cassava Brown Streak Disease (CBSD). The disease affects tuberous roots and presents symptoms that include a yellow/brown, dry, corky necrosis within the starch-bearing tissues. Cassava breeders currently depend on visual inspection to score necrosis in roots based on a qualitative score which is quite subjective. In this paper we present an approach to automate root necrosis scoring using deep convolutional neural networks with semantic segmentation. Our experiments show that the UNet model performs this task with high accuracy achieving a mean Intersection over Union (IoU) of 0.90 on the test set. This method provides a means to use a quantitative measure for necrosis scoring on root cross-sections. This is done by segmentation and classifying the necrotized and non-necrotized pixels of cassava root cross-sections without any additional feature engineering.