 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIterative Graph Self-Distillation
Oct 23, 2020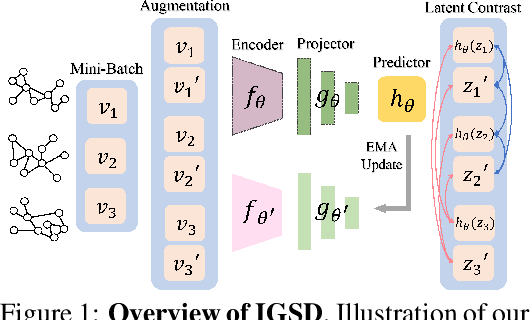
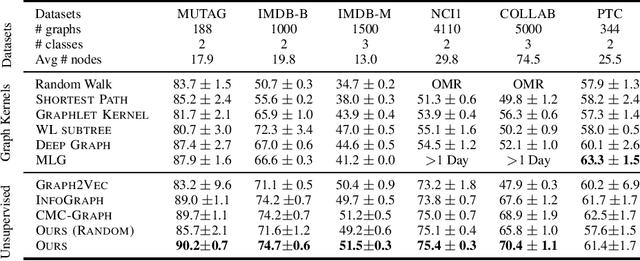
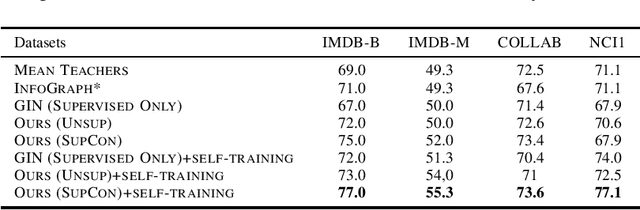
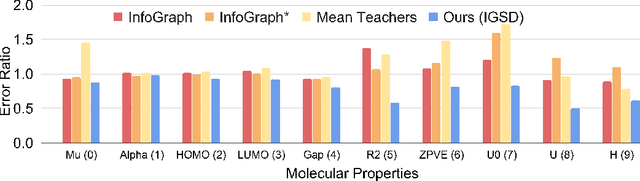
How to discriminatively vectorize graphs is a fundamental challenge that attracts increasing attentions in recent years. Inspired by the recent success of unsupervised contrastive learning, we aim to learn graph-level representation in an unsupervised manner. Specifically, we propose a novel unsupervised graph learning paradigm called Iterative Graph Self-Distillation (IGSD) which iteratively performs the teacher-student distillation with graph augmentations. Different from conventional knowledge distillation, IGSD constructs the teacher with an exponential moving average of the student model and distills the knowledge of itself. The intuition behind IGSD is to predict the teacher network representation of the graph pairs under different augmented views. As a natural extension, we also apply IGSD to semi-supervised scenarios by jointly regularizing the network with both supervised and unsupervised contrastive loss. Finally, we show that finetuning the IGSD-trained models with self-training can further improve the graph representation power. Empirically, we achieve significant and consistent performance gain on various graph datasets in both unsupervised and semi-supervised settings, which well validates the superiority of IGSD.
Word Shape Matters: Robust Machine Translation with Visual Embedding
Oct 20, 2020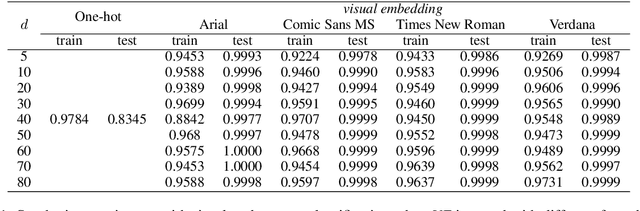
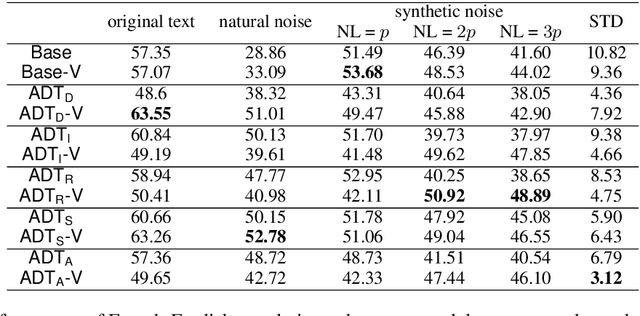
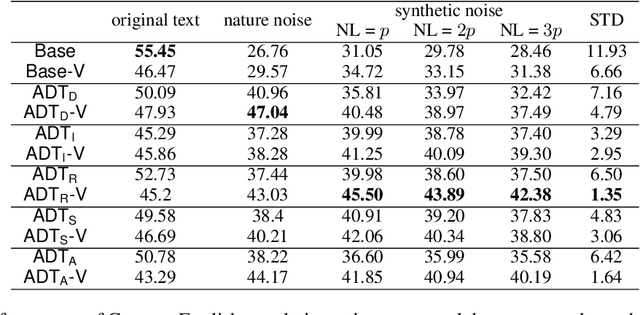
Neural machine translation has achieved remarkable empirical performance over standard benchmark datasets, yet recent evidence suggests that the models can still fail easily dealing with substandard inputs such as misspelled words, To overcome this issue, we introduce a new encoding heuristic of the input symbols for character-level NLP models: it encodes the shape of each character through the images depicting the letters when printed. We name this new strategy visual embedding and it is expected to improve the robustness of NLP models because humans also process the corpus visually through printed letters, instead of machinery one-hot vectors. Empirically, our method improves models' robustness against substandard inputs, even in the test scenario where the models are tested with the noises that are beyond what is available during the training phase.
Summarizing Text on Any Aspects: A Knowledge-Informed Weakly-Supervised Approach
Oct 18, 2020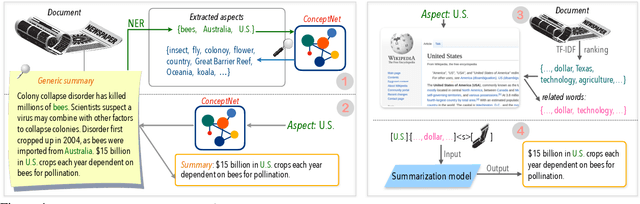
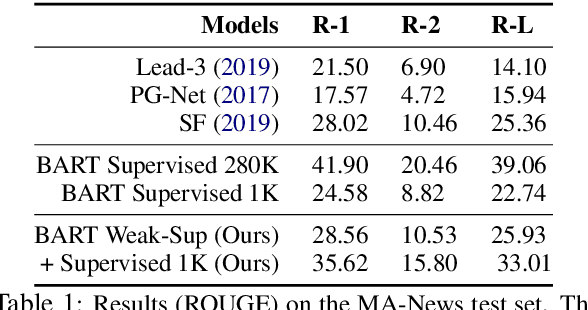
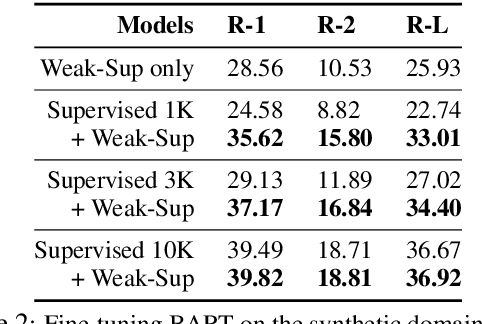
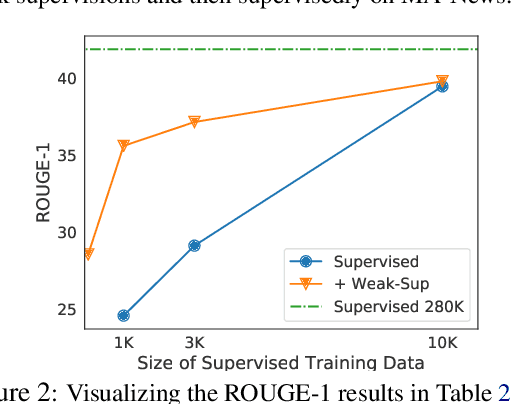
Given a document and a target aspect (e.g., a topic of interest), aspect-based abstractive summarization attempts to generate a summary with respect to the aspect. Previous studies usually assume a small pre-defined set of aspects and fall short of summarizing on other diverse topics. In this work, we study summarizing on arbitrary aspects relevant to the document, which significantly expands the application of the task in practice. Due to the lack of supervision data, we develop a new weak supervision construction method and an aspect modeling scheme, both of which integrate rich external knowledge sources such as ConceptNet and Wikipedia. Experiments show our approach achieves performance boosts on summarizing both real and synthetic documents given pre-defined or arbitrary aspects.
Pollux: Co-adaptive Cluster Scheduling for Goodput-Optimized Deep Learning
Aug 27, 2020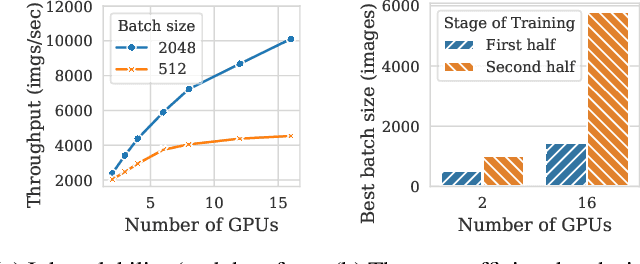

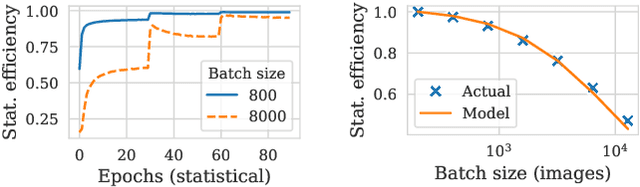
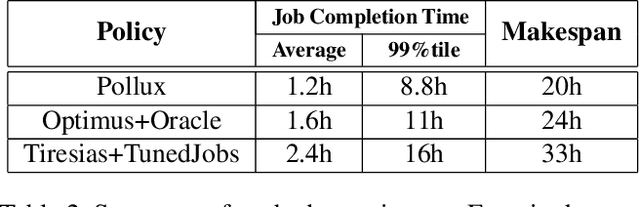
Pollux improves scheduling performance in deep learning (DL) clusters by adaptively co-optimizing inter-dependent factors both at the per-job level and at the cluster-wide level. Most existing schedulers will assign each job a number of resources requested by the user, which can allow jobs to use those resources inefficiently. Some recent schedulers choose job resources for users, but do so without awareness of how DL training can be re-optimized to better utilize those resources. Pollux simultaneously considers both aspects. By observing each job during training, Pollux models how their goodput (system throughput combined with statistical efficiency) would change by adding or removing resources. Leveraging these models, Pollux dynamically (re-)assigns resources to maximize cluster-wide goodput, while continually optimizing each DL job to better utilize those resources. In experiments with real DL training jobs and with trace-driven simulations, Pollux reduces average job completion time by 25%-50% relative to state-of-the-art DL schedulers, even when all jobs are submitted with ideal resource and training configurations. Based on the observation that the statistical efficiency of DL training can change over time, we also show that Pollux can reduce the cost of training large models in cloud environments by 25%.
Self-Challenging Improves Cross-Domain Generalization
Jul 05, 2020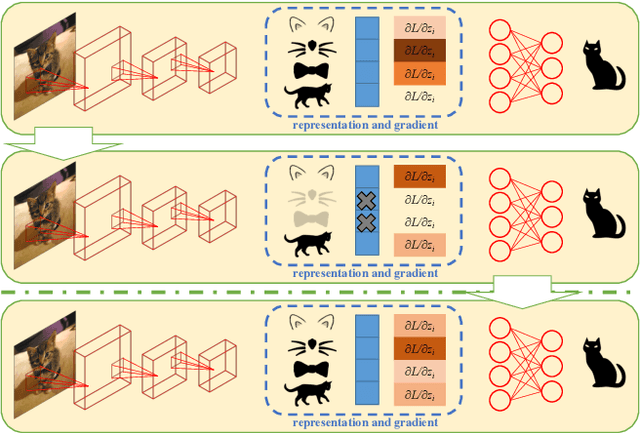
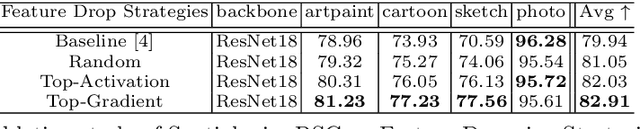
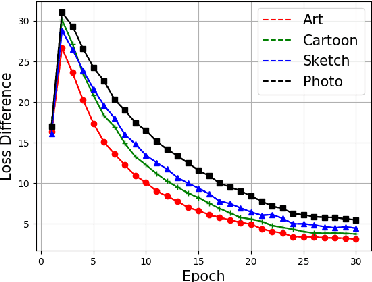
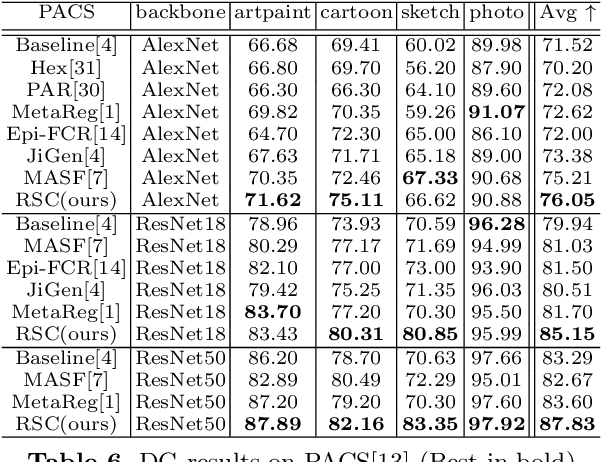
Convolutional Neural Networks (CNN) conduct image classification by activating dominant features that correlated with labels. When the training and testing data are under similar distributions, their dominant features are similar, which usually facilitates decent performance on the testing data. The performance is nonetheless unmet when tested on samples from different distributions, leading to the challenges in cross-domain image classification. We introduce a simple training heuristic, Representation Self-Challenging (RSC), that significantly improves the generalization of CNN to the out-of-domain data. RSC iteratively challenges (discards) the dominant features activated on the training data, and forces the network to activate remaining features that correlates with labels. This process appears to activate feature representations applicable to out-of-domain data without prior knowledge of new domain and without learning extra network parameters. We present theoretical properties and conditions of RSC for improving cross-domain generalization. The experiments endorse the simple, effective and architecture-agnostic nature of our RSC method.
On Dropout, Overfitting, and Interaction Effects in Deep Neural Networks
Jul 02, 2020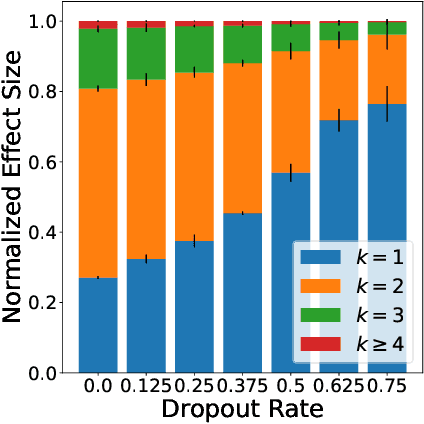

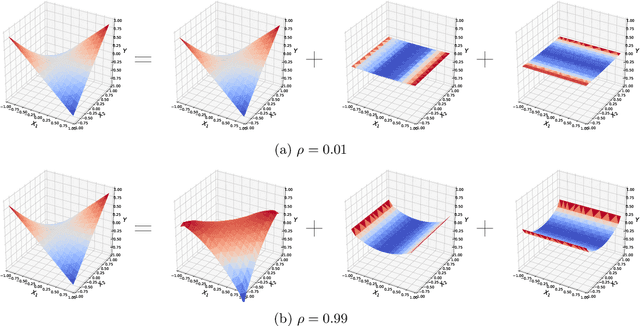
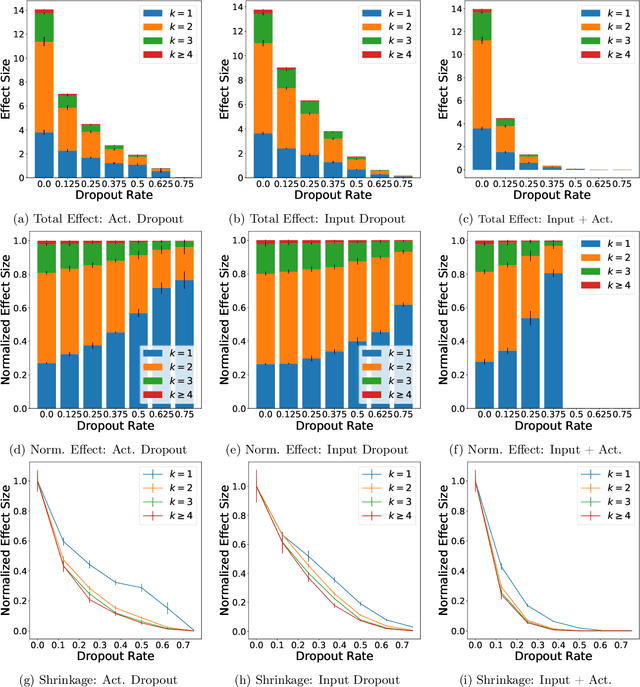
We examine Dropout through the perspective of interactions: learned effects that combine multiple input variables. Given $N$ variables, there are $O(N^2)$ possible pairwise interactions, $O(N^3)$ possible 3-way interactions, etc. We show that Dropout implicitly sets a learning rate for interaction effects that decays exponentially with the size of the interaction, corresponding to a regularizer that balances against the hypothesis space which grows exponentially with number of variables in the interaction. This understanding of Dropout has implications for the optimal Dropout rate: higher Dropout rates should be used when we need stronger regularization against spurious high-order interactions. This perspective also issues caution against using Dropout to measure term saliency because Dropout regularizes against terms for high-order interactions. Finally, this view of Dropout as a regularizer of interaction effects provides insight into the varying effectiveness of Dropout for different architectures and data sets. We also compare Dropout to regularization via weight decay and early stopping and find that it is difficult to obtain the same regularization effect for high-order interactions with these methods.
Improving GAN Training with Probability Ratio Clipping and Sample Reweighting
Jun 30, 2020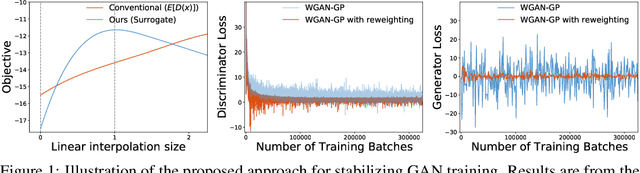


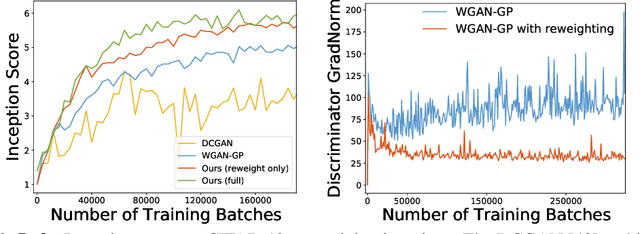
Despite success on a wide range of problems related to vision, generative adversarial networks (GANs) can suffer from inferior performance due to unstable training, especially for text generation. We propose a new variational GAN training framework which enjoys superior training stability. Our approach is inspired by a connection of GANs and reinforcement learning under a variational perspective. The connection leads to (1) probability ratio clipping that regularizes generator training to prevent excessively large updates, and (2) a sample re-weighting mechanism that stabilizes discriminator training by downplaying bad-quality fake samples. We provide theoretical analysis on the convergence of our approach. By plugging the training approach in diverse state-of-the-art GAN architectures, we obtain significantly improved performance over a range of tasks, including text generation, text style transfer, and image generation.
Progressive Generation of Long Text
Jun 28, 2020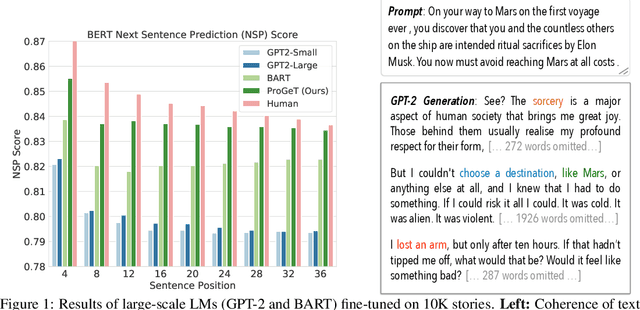
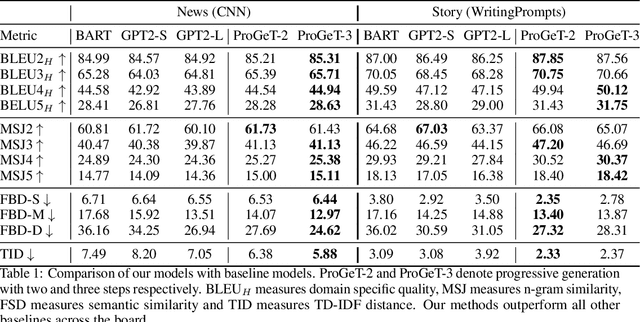
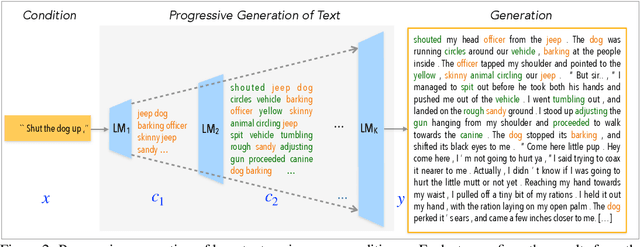
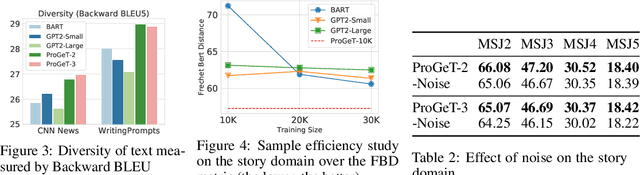
Large-scale language models pretrained on massive corpora of text, such as GPT-2, are powerful open-domain text generators. However, as our systematic examination reveals, it is still challenging for such models to generate coherent long passages of text ($>$1000 tokens), especially when the models are fine-tuned to the target domain on a small corpus. To overcome the limitation, we propose a simple but effective method of generating text in a progressive manner, inspired by generating images from low to high resolution. Our method first produces domain-specific content keywords and then progressively refines them into complete passages in multiple stages. The simple design allows our approach to take advantage of pretrained language models at each stage and effectively adapt to any target domain given only a small set of examples. We conduct a comprehensive empirical study with a broad set of evaluation metrics, and show that our approach significantly improves upon the fine-tuned GPT-2 in terms of domain-specific quality and sample efficiency. The coarse-to-fine nature of progressive generation also allows for a higher degree of control over the generated content.
Distributed, partially collapsed MCMC for Bayesian Nonparametrics
Jan 15, 2020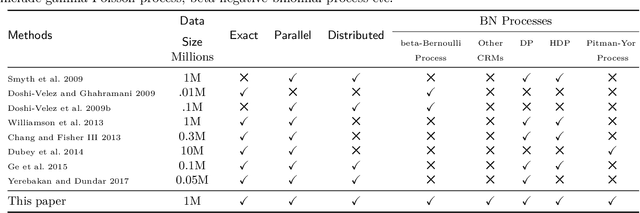
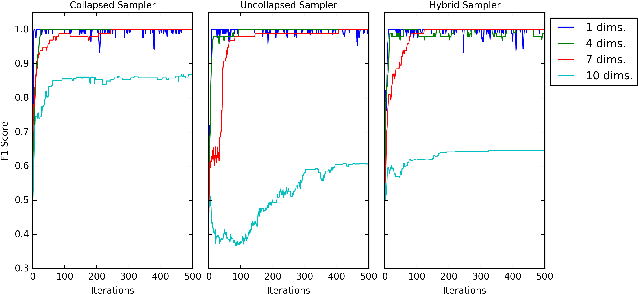

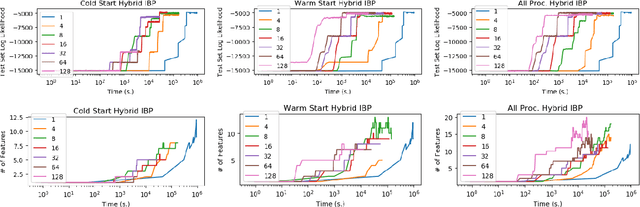
Bayesian nonparametric (BNP) models provide elegant methods for discovering underlying latent features within a data set, but inference in such models can be slow. We exploit the fact that completely random measures, which commonly used models like the Dirichlet process and the beta-Bernoulli process can be expressed as, are decomposable into independent sub-measures. We use this decomposition to partition the latent measure into a finite measure containing only instantiated components, and an infinite measure containing all other components. We then select different inference algorithms for the two components: uncollapsed samplers mix well on the finite measure, while collapsed samplers mix well on the infinite, sparsely occupied tail. The resulting hybrid algorithm can be applied to a wide class of models, and can be easily distributed to allow scalable inference without sacrificing asymptotic convergence guarantees.
Learning Data Manipulation for Augmentation and Weighting
Oct 28, 2019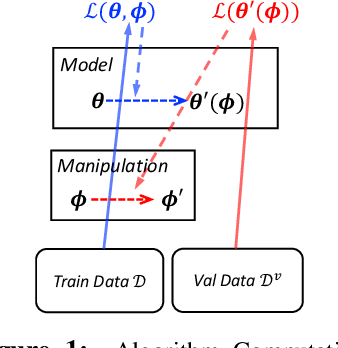
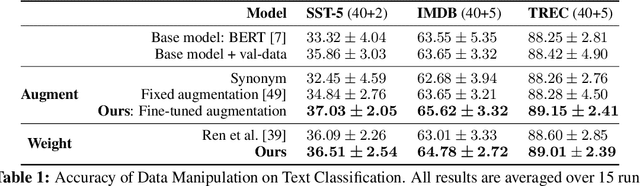
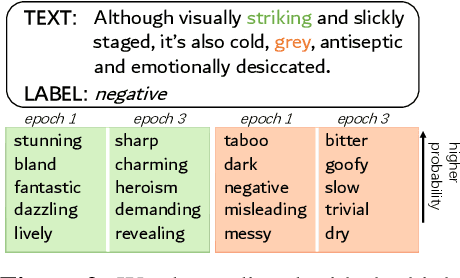
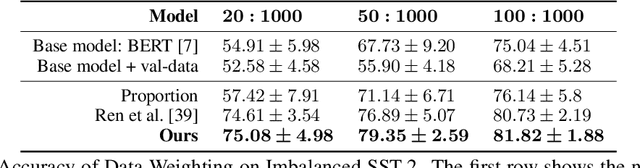
Manipulating data, such as weighting data examples or augmenting with new instances, has been increasingly used to improve model training. Previous work has studied various rule- or learning-based approaches designed for specific types of data manipulation. In this work, we propose a new method that supports learning different manipulation schemes with the same gradient-based algorithm. Our approach builds upon a recent connection of supervised learning and reinforcement learning (RL), and adapts an off-the-shelf reward learning algorithm from RL for joint data manipulation learning and model training. Different parameterization of the "data reward" function instantiates different manipulation schemes. We showcase data augmentation that learns a text transformation network, and data weighting that dynamically adapts the data sample importance. Experiments show the resulting algorithms significantly improve the image and text classification performance in low data regime and class-imbalance problems.