 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic-Aligned Matching for Enhanced DETR Convergence and Multi-Scale Feature Fusion
Jul 28, 2022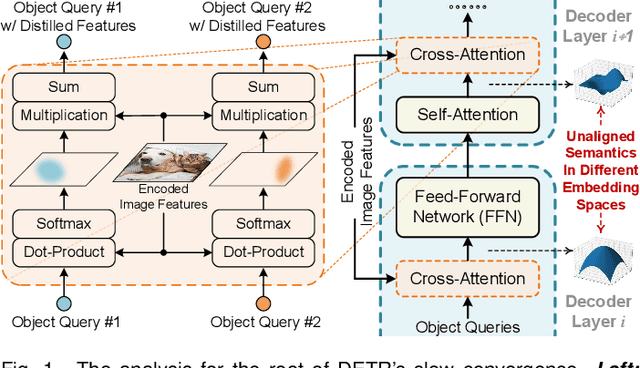
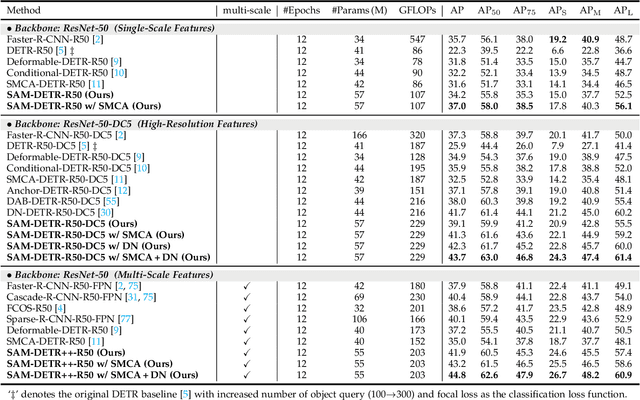
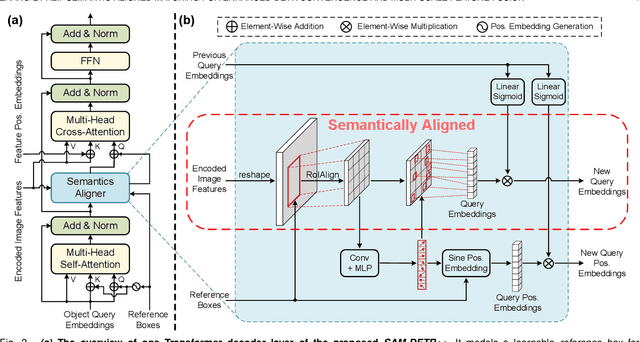
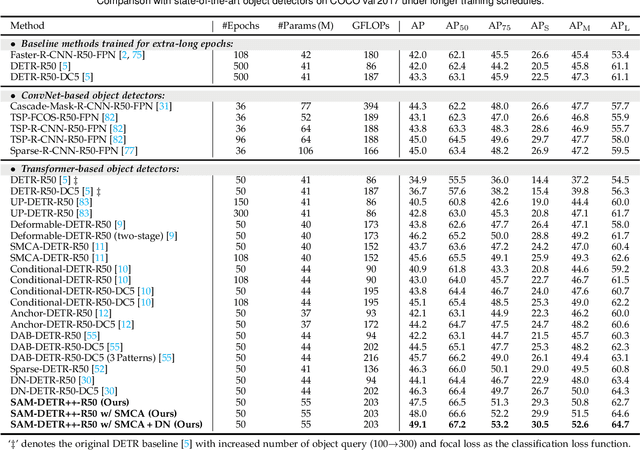
The recently proposed DEtection TRansformer (DETR) has established a fully end-to-end paradigm for object detection. However, DETR suffers from slow training convergence, which hinders its applicability to various detection tasks. We observe that DETR's slow convergence is largely attributed to the difficulty in matching object queries to relevant regions due to the unaligned semantics between object queries and encoded image features. With this observation, we design Semantic-Aligned-Matching DETR++ (SAM-DETR++) to accelerate DETR's convergence and improve detection performance. The core of SAM-DETR++ is a plug-and-play module that projects object queries and encoded image features into the same feature embedding space, where each object query can be easily matched to relevant regions with similar semantics. Besides, SAM-DETR++ searches for multiple representative keypoints and exploits their features for semantic-aligned matching with enhanced representation capacity. Furthermore, SAM-DETR++ can effectively fuse multi-scale features in a coarse-to-fine manner on the basis of the designed semantic-aligned matching. Extensive experiments show that the proposed SAM-DETR++ achieves superior convergence speed and competitive detection accuracy. Additionally, as a plug-and-play method, SAM-DETR++ can complement existing DETR convergence solutions with even better performance, achieving 44.8% AP with merely 12 training epochs and 49.1% AP with 50 training epochs on COCO val2017 with ResNet-50. Codes are available at https://github.com/ZhangGongjie/SAM-DETR .
Robustar: Interactive Toolbox Supporting Precise Data Annotation for Robust Vision Learning
Jul 18, 2022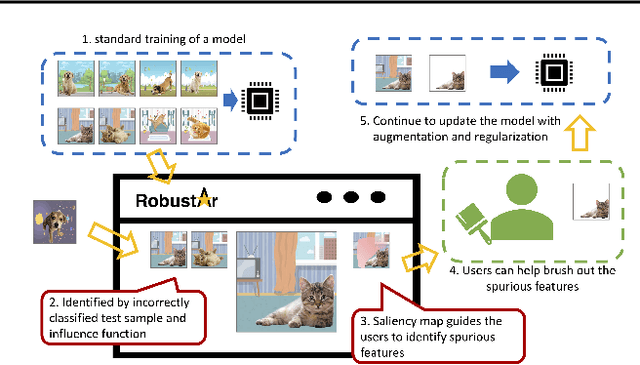
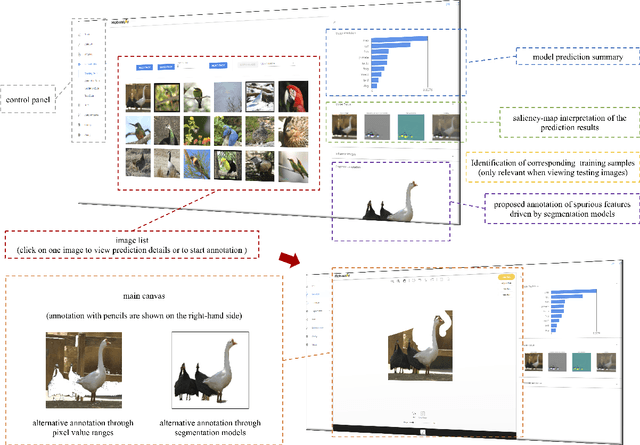
We introduce the initial release of our software Robustar, which aims to improve the robustness of vision classification machine learning models through a data-driven perspective. Building upon the recent understanding that the lack of machine learning model's robustness is the tendency of the model's learning of spurious features, we aim to solve this problem from its root at the data perspective by removing the spurious features from the data before training. In particular, we introduce a software that helps the users to better prepare the data for training image classification models by allowing the users to annotate the spurious features at the pixel level of images. To facilitate this process, our software also leverages recent advances to help identify potential images and pixels worthy of attention and to continue the training with newly annotated data. Our software is hosted at the GitHub Repository https://github.com/HaohanWang/Robustar.
MRCLens: an MRC Dataset Bias Detection Toolkit
Jul 18, 2022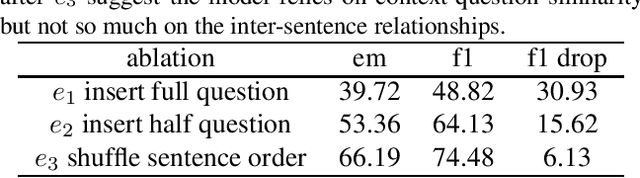

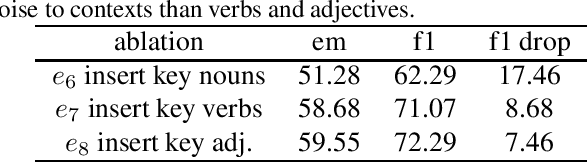
Many recent neural models have shown remarkable empirical results in Machine Reading Comprehension, but evidence suggests sometimes the models take advantage of dataset biases to predict and fail to generalize on out-of-sample data. While many other approaches have been proposed to address this issue from the computation perspective such as new architectures or training procedures, we believe a method that allows researchers to discover biases, and adjust the data or the models in an earlier stage will be beneficial. Thus, we introduce MRCLens, a toolkit that detects whether biases exist before users train the full model. For the convenience of introducing the toolkit, we also provide a categorization of common biases in MRC.
Toward Learning Robust and Invariant Representations with Alignment Regularization and Data Augmentation
Jun 04, 2022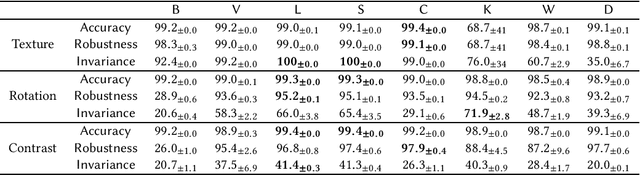
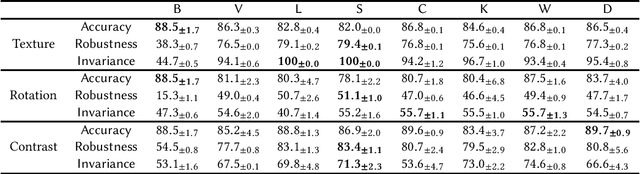

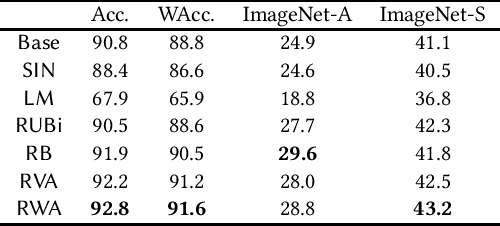
Data augmentation has been proven to be an effective technique for developing machine learning models that are robust to known classes of distributional shifts (e.g., rotations of images), and alignment regularization is a technique often used together with data augmentation to further help the model learn representations invariant to the shifts used to augment the data. In this paper, motivated by a proliferation of options of alignment regularizations, we seek to evaluate the performances of several popular design choices along the dimensions of robustness and invariance, for which we introduce a new test procedure. Our synthetic experiment results speak to the benefits of squared l2 norm regularization. Further, we also formally analyze the behavior of alignment regularization to complement our empirical study under assumptions we consider realistic. Finally, we test this simple technique we identify (worst-case data augmentation with squared l2 norm alignment regularization) and show that the benefits of this method outrun those of the specially designed methods. We also release a software package in both TensorFlow and PyTorch for users to use the method with a couple of lines at https://github.com/jyanln/AlignReg.
RLPrompt: Optimizing Discrete Text Prompts With Reinforcement Learning
May 25, 2022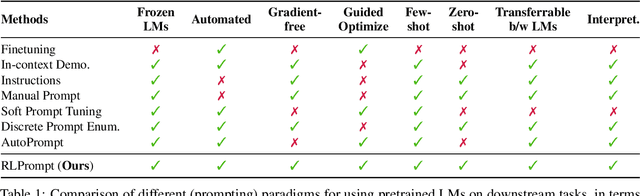
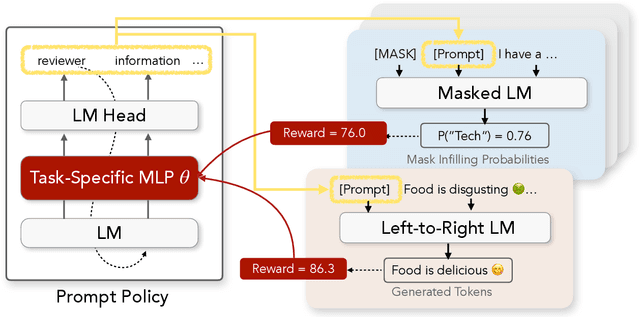
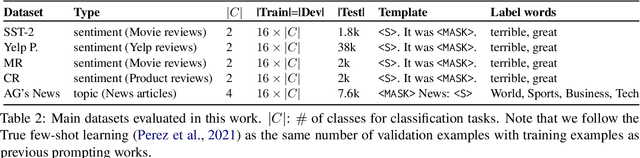
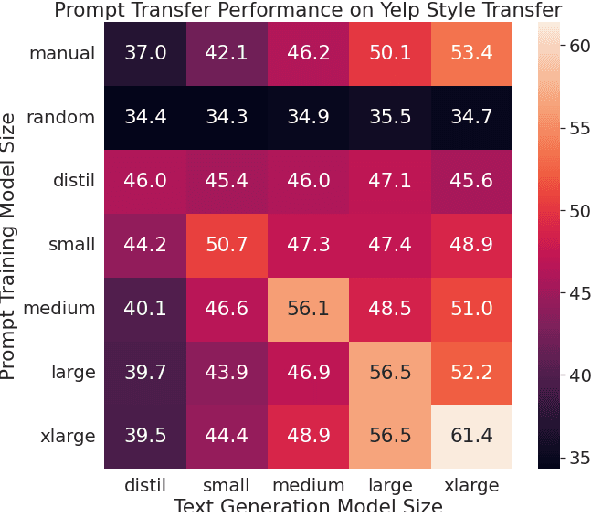
Prompting has shown impressive success in enabling large pretrained language models (LMs) to perform diverse NLP tasks, especially when only few downstream data are available. Automatically finding the optimal prompt for each task, however, is challenging. Most existing work resorts to tuning soft prompt (e.g., embeddings) which falls short of interpretability, reusability across LMs, and applicability when gradients are not accessible. Discrete prompt, on the other hand, is difficult to optimize, and is often created by "enumeration (e.g., paraphrasing)-then-selection" heuristics that do not explore the prompt space systematically. This paper proposes RLPrompt, an efficient discrete prompt optimization approach with reinforcement learning (RL). RLPrompt formulates a parameter-efficient policy network that generates the desired discrete prompt after training with reward. To overcome the complexity and stochasticity of reward signals by the large LM environment, we incorporate effective reward stabilization that substantially enhances the training efficiency. RLPrompt is flexibly applicable to different types of LMs, such as masked (e.g., BERT) and left-to-right models (e.g., GPTs), for both classification and generation tasks. Experiments on few-shot classification and unsupervised text style transfer show superior performance over a wide range of existing finetuning or prompting methods. Interestingly, the resulting optimized prompts are often ungrammatical gibberish text; and surprisingly, those gibberish prompts are transferrable between different LMs to retain significant performance, indicating LM prompting may not follow human language patterns.
The Two Dimensions of Worst-case Training and the Integrated Effect for Out-of-domain Generalization
Apr 09, 2022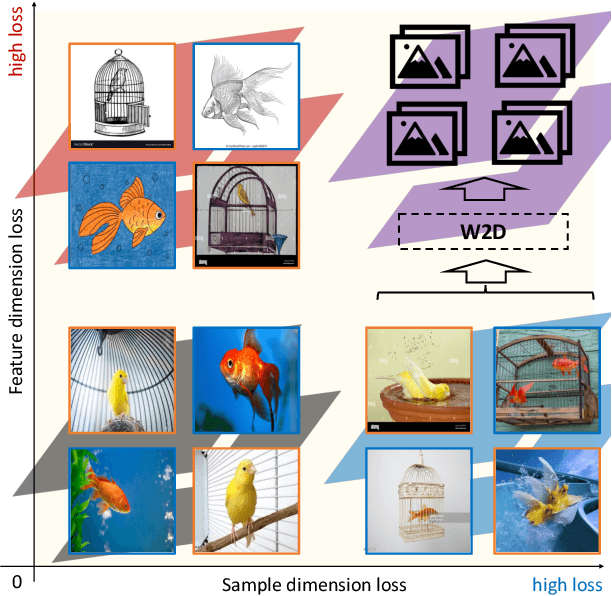

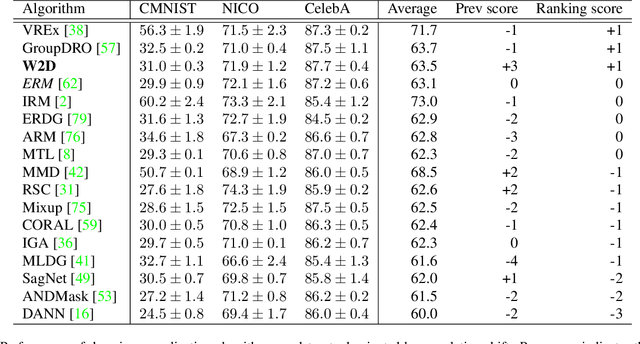
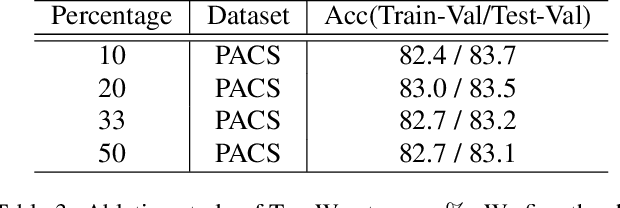
Training with an emphasis on "hard-to-learn" components of the data has been proven as an effective method to improve the generalization of machine learning models, especially in the settings where robustness (e.g., generalization across distributions) is valued. Existing literature discussing this "hard-to-learn" concept are mainly expanded either along the dimension of the samples or the dimension of the features. In this paper, we aim to introduce a simple view merging these two dimensions, leading to a new, simple yet effective, heuristic to train machine learning models by emphasizing the worst-cases on both the sample and the feature dimensions. We name our method W2D following the concept of "Worst-case along Two Dimensions". We validate the idea and demonstrate its empirical strength over standard benchmarks.
Can Transformers be Strong Treatment Effect Estimators?
Feb 14, 2022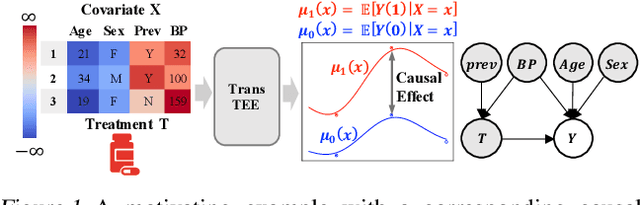

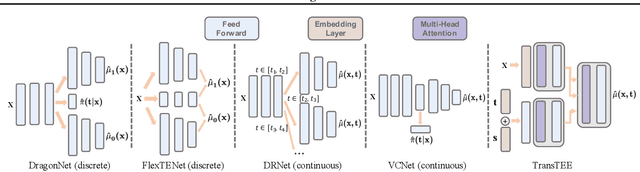
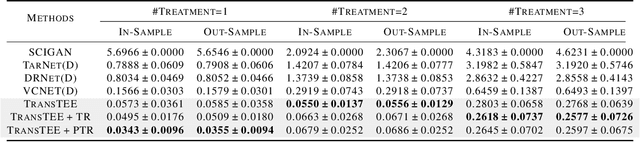
In this paper, we develop a general framework based on the Transformer architecture to address a variety of challenging treatment effect estimation (TEE) problems. Our methods are applicable both when covariates are tabular and when they consist of sequences (e.g., in text), and can handle discrete, continuous, structured, or dosage-associated treatments. While Transformers have already emerged as dominant methods for diverse domains, including natural language and computer vision, our experiments with Transformers as Treatment Effect Estimators (TransTEE) demonstrate that these inductive biases are also effective on the sorts of estimation problems and datasets that arise in research aimed at estimating causal effects. Moreover, we propose a propensity score network that is trained with TransTEE in an adversarial manner to promote independence between covariates and treatments to further address selection bias. Through extensive experiments, we show that TransTEE significantly outperforms competitive baselines with greater parameter efficiency over a wide range of benchmarks and settings.
Towards Principled Disentanglement for Domain Generalization
Nov 27, 2021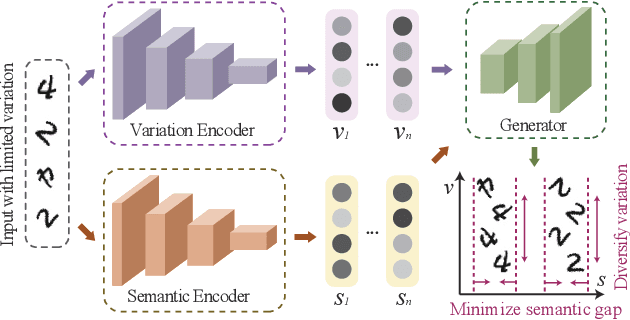
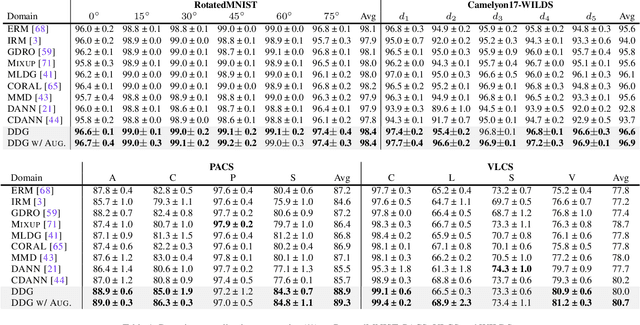
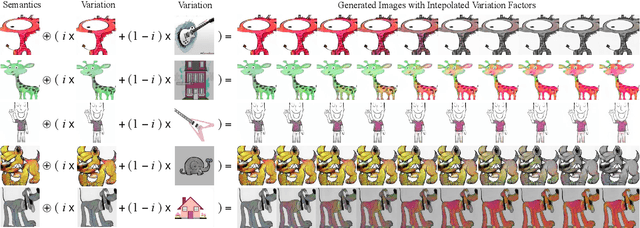
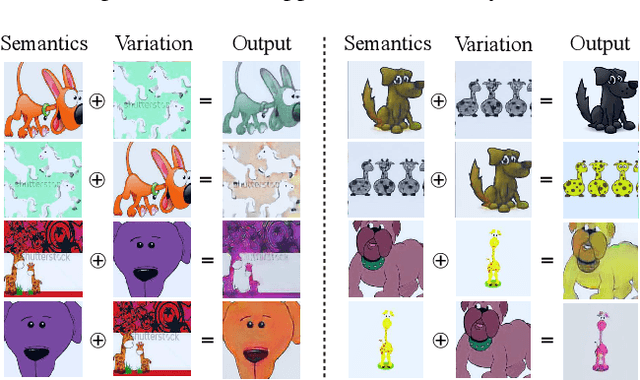
A fundamental challenge for machine learning models is generalizing to out-of-distribution (OOD) data, in part due to spurious correlations. To tackle this challenge, we first formalize the OOD generalization problem as constrained optimization, called Disentanglement-constrained Domain Generalization (DDG). We relax this non-trivial constrained optimization to a tractable form with finite-dimensional parameterization and empirical approximation. Then a theoretical analysis of the extent to which the above transformations deviates from the original problem is provided. Based on the transformation, we propose a primal-dual algorithm for joint representation disentanglement and domain generalization. In contrast to traditional approaches based on domain adversarial training and domain labels, DDG jointly learns semantic and variation encoders for disentanglement, enabling flexible manipulation and augmentation on training data. DDG aims to learn intrinsic representations of semantic concepts that are invariant to nuisance factors and generalizable across different domains. Comprehensive experiments on popular benchmarks show that DDG can achieve competitive OOD performance and uncover interpretable salient structures within data.
NOTMAD: Estimating Bayesian Networks with Sample-Specific Structures and Parameters
Nov 01, 2021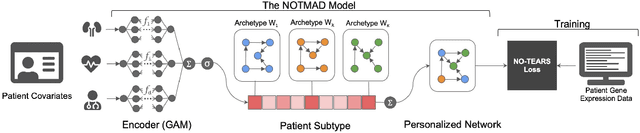


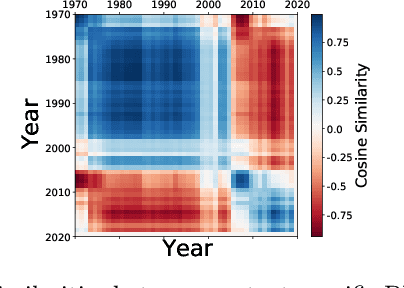
Context-specific Bayesian networks (i.e. directed acyclic graphs, DAGs) identify context-dependent relationships between variables, but the non-convexity induced by the acyclicity requirement makes it difficult to share information between context-specific estimators (e.g. with graph generator functions). For this reason, existing methods for inferring context-specific Bayesian networks have favored breaking datasets into subsamples, limiting statistical power and resolution, and preventing the use of multidimensional and latent contexts. To overcome this challenge, we propose NOTEARS-optimized Mixtures of Archetypal DAGs (NOTMAD). NOTMAD models context-specific Bayesian networks as the output of a function which learns to mix archetypal networks according to sample context. The archetypal networks are estimated jointly with the context-specific networks and do not require any prior knowledge. We encode the acyclicity constraint as a smooth regularization loss which is back-propagated to the mixing function; in this way, NOTMAD shares information between context-specific acyclic graphs, enabling the estimation of Bayesian network structures and parameters at even single-sample resolution. We demonstrate the utility of NOTMAD and sample-specific network inference through analysis and experiments, including patient-specific gene expression networks which correspond to morphological variation in cancer.
Cooperative Multi-Agent Actor-Critic for Privacy-Preserving Load Scheduling in a Residential Microgrid
Oct 06, 2021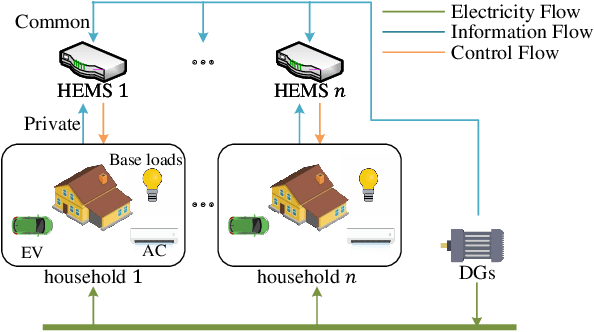
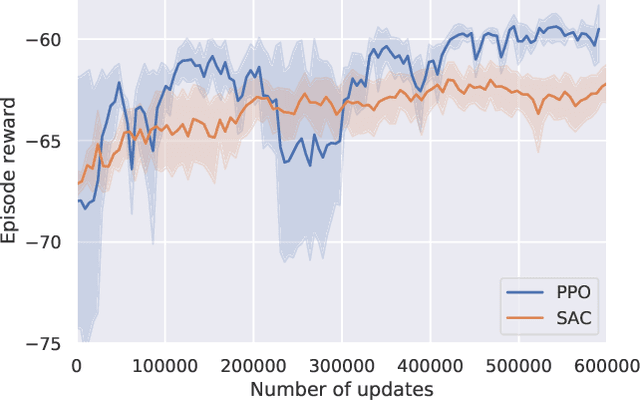
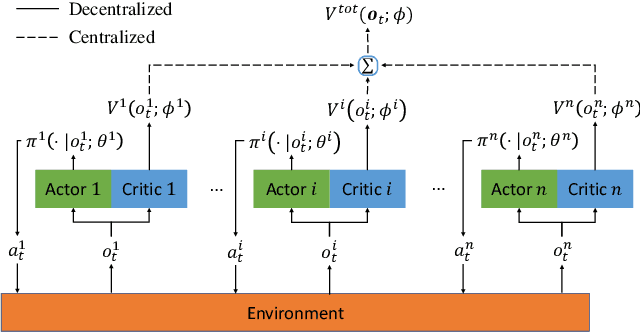
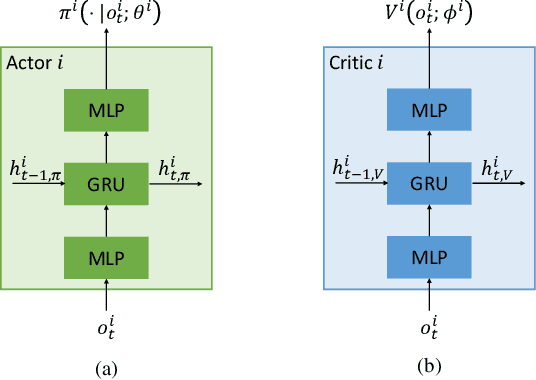
As a scalable data-driven approach, multi-agent reinforcement learning (MARL) has made remarkable advances in solving the cooperative residential load scheduling problems. However, the common centralized training strategy of MARL algorithms raises privacy risks for involved households. In this work, we propose a privacy-preserving multi-agent actor-critic framework where the decentralized actors are trained with distributed critics, such that both the decentralized execution and the distributed training do not require the global state information. The proposed framework can preserve the privacy of the households while simultaneously learn the multi-agent credit assignment mechanism implicitly. The simulation experiments demonstrate that the proposed framework significantly outperforms the existing privacy-preserving actor-critic framework, and can achieve comparable performance to the state-of-the-art actor-critic framework without privacy constraints.