 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFast yet Safe: Early-Exiting with Risk Control
May 31, 2024



Scaling machine learning models significantly improves their performance. However, such gains come at the cost of inference being slow and resource-intensive. Early-exit neural networks (EENNs) offer a promising solution: they accelerate inference by allowing intermediate layers to exit and produce a prediction early. Yet a fundamental issue with EENNs is how to determine when to exit without severely degrading performance. In other words, when is it 'safe' for an EENN to go 'fast'? To address this issue, we investigate how to adapt frameworks of risk control to EENNs. Risk control offers a distribution-free, post-hoc solution that tunes the EENN's exiting mechanism so that exits only occur when the output is of sufficient quality. We empirically validate our insights on a range of vision and language tasks, demonstrating that risk control can produce substantial computational savings, all the while preserving user-specified performance goals.
Uncertainty Aware Tropical Cyclone Wind Speed Estimation from Satellite Data
Apr 12, 2024



Deep neural networks (DNNs) have been successfully applied to earth observation (EO) data and opened new research avenues. Despite the theoretical and practical advances of these techniques, DNNs are still considered black box tools and by default are designed to give point predictions. However, the majority of EO applications demand reliable uncertainty estimates that can support practitioners in critical decision making tasks. This work provides a theoretical and quantitative comparison of existing uncertainty quantification methods for DNNs applied to the task of wind speed estimation in satellite imagery of tropical cyclones. We provide a detailed evaluation of predictive uncertainty estimates from state-of-the-art uncertainty quantification (UQ) methods for DNNs. We find that predictive uncertainties can be utilized to further improve accuracy and analyze the predictive uncertainties of different methods across storm categories.
Adaptive Bounding Box Uncertainties via Two-Step Conformal Prediction
Mar 12, 2024



Quantifying a model's predictive uncertainty is essential for safety-critical applications such as autonomous driving. We consider quantifying such uncertainty for multi-object detection. In particular, we leverage conformal prediction to obtain uncertainty intervals with guaranteed coverage for object bounding boxes. One challenge in doing so is that bounding box predictions are conditioned on the object's class label. Thus, we develop a novel two-step conformal approach that propagates uncertainty in predicted class labels into the uncertainty intervals for the bounding boxes. This broadens the validity of our conformal coverage guarantees to include incorrectly classified objects, ensuring their usefulness when maximal safety assurances are required. Moreover, we investigate novel ensemble and quantile regression formulations to ensure the bounding box intervals are adaptive to object size, leading to a more balanced coverage across sizes. Validating our two-step approach on real-world datasets for 2D bounding box localization, we find that desired coverage levels are satisfied with actionably tight predictive uncertainty intervals.
Learning to Defer to a Population: A Meta-Learning Approach
Mar 05, 2024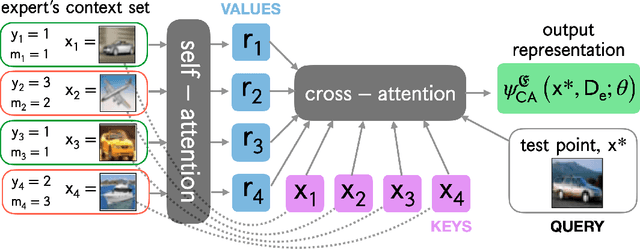



The learning to defer (L2D) framework allows autonomous systems to be safe and robust by allocating difficult decisions to a human expert. All existing work on L2D assumes that each expert is well-identified, and if any expert were to change, the system should be re-trained. In this work, we alleviate this constraint, formulating an L2D system that can cope with never-before-seen experts at test-time. We accomplish this by using meta-learning, considering both optimization- and model-based variants. Given a small context set to characterize the currently available expert, our framework can quickly adapt its deferral policy. For the model-based approach, we employ an attention mechanism that is able to look for points in the context set that are similar to a given test point, leading to an even more precise assessment of the expert's abilities. In the experiments, we validate our methods on image recognition, traffic sign detection, and skin lesion diagnosis benchmarks.
A Generative Model of Symmetry Transformations
Mar 04, 2024Correctly capturing the symmetry transformations of data can lead to efficient models with strong generalization capabilities, though methods incorporating symmetries often require prior knowledge. While recent advancements have been made in learning those symmetries directly from the dataset, most of this work has focused on the discriminative setting. In this paper, we construct a generative model that explicitly aims to capture symmetries in the data, resulting in a model that learns which symmetries are present in an interpretable way. We provide a simple algorithm for efficiently learning our generative model and demonstrate its ability to capture symmetries under affine and color transformations. Combining our symmetry model with existing generative models results in higher marginal test-log-likelihoods and robustness to data sparsification.
On the Challenges and Opportunities in Generative AI
Feb 28, 2024The field of deep generative modeling has grown rapidly and consistently over the years. With the availability of massive amounts of training data coupled with advances in scalable unsupervised learning paradigms, recent large-scale generative models show tremendous promise in synthesizing high-resolution images and text, as well as structured data such as videos and molecules. However, we argue that current large-scale generative AI models do not sufficiently address several fundamental issues that hinder their widespread adoption across domains. In this work, we aim to identify key unresolved challenges in modern generative AI paradigms that should be tackled to further enhance their capabilities, versatility, and reliability. By identifying these challenges, we aim to provide researchers with valuable insights for exploring fruitful research directions, thereby fostering the development of more robust and accessible generative AI solutions.
Beyond Top-Class Agreement: Using Divergences to Forecast Performance under Distribution Shift
Dec 13, 2023Knowing if a model will generalize to data 'in the wild' is crucial for safe deployment. To this end, we study model disagreement notions that consider the full predictive distribution - specifically disagreement based on Hellinger distance, Jensen-Shannon and Kullback-Leibler divergence. We find that divergence-based scores provide better test error estimates and detection rates on out-of-distribution data compared to their top-1 counterparts. Experiments involve standard vision and foundation models.
One Strike, You're Out: Detecting Markush Structures in Low Signal-to-Noise Ratio Images
Nov 24, 2023



Modern research increasingly relies on automated methods to assist researchers. An example of this is Optical Chemical Structure Recognition (OCSR), which aids chemists in retrieving information about chemicals from large amounts of documents. Markush structures are chemical structures that cannot be parsed correctly by OCSR and cause errors. The focus of this research was to propose and test a novel method for classifying Markush structures. Within this method, a comparison was made between fixed-feature extraction and end-to-end learning (CNN). The end-to-end method performed significantly better than the fixed-feature method, achieving 0.928 (0.035 SD) Macro F1 compared to the fixed-feature method's 0.701 (0.052 SD). Because of the nature of the experiment, these figures are a lower bound and can be improved further. These results suggest that Markush structures can be filtered out effectively and accurately using the proposed method. When implemented into OCSR pipelines, this method can improve their performance and use to other researchers.
A powerful rank-based correction to multiple testing under positive dependency
Nov 17, 2023We develop a novel multiple hypothesis testing correction with family-wise error rate (FWER) control that efficiently exploits positive dependencies between potentially correlated statistical hypothesis tests. Our proposed algorithm $\texttt{max-rank}$ is conceptually straight-forward, relying on the use of a $\max$-operator in the rank domain of computed test statistics. We compare our approach to the frequently employed Bonferroni correction, theoretically and empirically demonstrating its superiority over Bonferroni in the case of existing positive dependency, and its equivalence otherwise. Our advantage over Bonferroni increases as the number of tests rises, and we maintain high statistical power whilst ensuring FWER control. We specifically frame our algorithm in the context of parallel permutation testing, a scenario that arises in our primary application of conformal prediction, a recently popularized approach for quantifying uncertainty in complex predictive settings.
Anytime-Valid Confidence Sequences for Consistent Uncertainty Estimation in Early-Exit Neural Networks
Nov 10, 2023Early-exit neural networks (EENNs) facilitate adaptive inference by producing predictions at multiple stages of the forward pass. In safety-critical applications, these predictions are only meaningful when complemented with reliable uncertainty estimates. Yet, due to their sequential structure, an EENN's uncertainty estimates should also be consistent: labels that are deemed improbable at one exit should not reappear within the confidence interval / set of later exits. We show that standard uncertainty quantification techniques, like Bayesian methods or conformal prediction, can lead to inconsistency across exits. We address this problem by applying anytime-valid confidence sequences (AVCSs) to the exits of EENNs. By design, AVCSs maintain consistency across exits. We examine the theoretical and practical challenges of applying AVCSs to EENNs and empirically validate our approach on both regression and classification tasks.