 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAligning Recommendations with User Popularity Preferences
Apr 01, 2026Popularity bias is a pervasive problem in recommender systems, where recommendations disproportionately favor popular items. This not only results in "rich-get-richer" dynamics and a homogenization of visible content, but can also lead to misalignment of recommendations with individual users' preferences for popular or niche content. This work studies popularity bias through the lens of user-recommender alignment. To this end, we introduce Popularity Quantile Calibration, a measurement framework that quantifies misalignment between a user's historical popularity preference and the popularity of their recommendations. Building on this notion of popularity alignment, we propose SPREE, an inference-time mitigation method for sequential recommenders based on activation steering. SPREE identifies a popularity direction in representation space and adaptively steers model activations based on an estimate of each user's personal popularity bias, allowing both the direction and magnitude of steering to vary across users. Unlike global debiasing approaches, SPREE explicitly targets alignment rather than uniformly reducing popularity. Experiments across multiple datasets show that SPREE consistently improves user-level popularity alignment while preserving recommendation quality.
Between Rules and Reality: On the Context Sensitivity of LLM Moral Judgment
Mar 24, 2026A human's moral decision depends heavily on the context. Yet research on LLM morality has largely studied fixed scenarios. We address this gap by introducing Contextual MoralChoice, a dataset of moral dilemmas with systematic contextual variations known from moral psychology to shift human judgment: consequentialist, emotional, and relational. Evaluating 22 LLMs, we find that nearly all models are context-sensitive, shifting their judgments toward rule-violating behavior. Comparing with a human survey, we find that models and humans are most triggered by different contextual variations, and that a model aligned with human judgments in the base case is not necessarily aligned in its contextual sensitivity. This raises the question of controlling contextual sensitivity, which we address with an activation steering approach that can reliably increase or decrease a model's contextual sensitivity.
Test-Time Adaptation with State-Space Models
Jul 17, 2024



Distribution shifts between training and test data are all but inevitable over the lifecycle of a deployed model and lead to performance decay. Adapting the model can hopefully mitigate this drop in performance. Yet, adaptation is challenging since it must be unsupervised: we usually do not have access to any labeled data at test time. In this paper, we propose a probabilistic state-space model that can adapt a deployed model subjected to distribution drift. Our model learns the dynamics induced by distribution shifts on the last set of hidden features. Without requiring labels, we infer time-evolving class prototypes that serve as a dynamic classification head. Moreover, our approach is lightweight, modifying only the model's last linear layer. In experiments on real-world distribution shifts and synthetic corruptions, we demonstrate that our approach performs competitively with methods that require back-propagation and access to the model backbone. Our model especially excels in the case of small test batches - the most difficult setting.
Beyond Top-Class Agreement: Using Divergences to Forecast Performance under Distribution Shift
Dec 13, 2023Knowing if a model will generalize to data 'in the wild' is crucial for safe deployment. To this end, we study model disagreement notions that consider the full predictive distribution - specifically disagreement based on Hellinger distance, Jensen-Shannon and Kullback-Leibler divergence. We find that divergence-based scores provide better test error estimates and detection rates on out-of-distribution data compared to their top-1 counterparts. Experiments involve standard vision and foundation models.
Modeling Irregular Time Series with Continuous Recurrent Units
Nov 22, 2021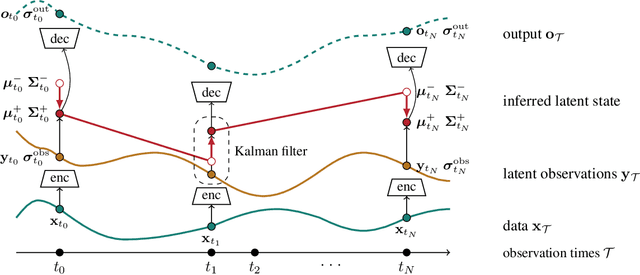
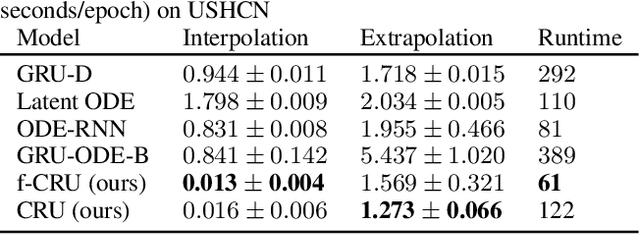

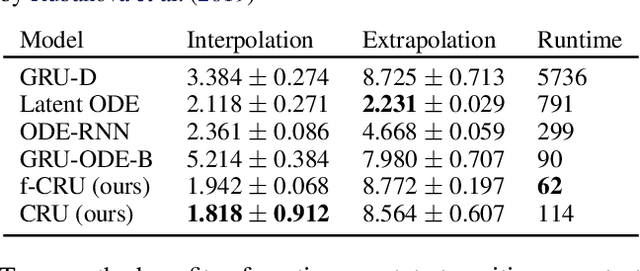
Recurrent neural networks (RNNs) like long short-term memory networks (LSTMs) and gated recurrent units (GRUs) are a popular choice for modeling sequential data. Their gating mechanism permits weighting previous history encoded in a hidden state with new information from incoming observations. In many applications, such as medical records, observations times are irregular and carry important information. However, LSTMs and GRUs assume constant time intervals between observations. To address this challenge, we propose continuous recurrent units (CRUs) -a neural architecture that can naturally handle irregular time intervals between observations. The gating mechanism of the CRU employs the continuous formulation of a Kalman filter and alternates between (1) continuous latent state propagation according to a linear stochastic differential equation (SDE) and (2) latent state updates whenever a new observation comes in. In an empirical study, we show that the CRU can better interpolate irregular time series than neural ordinary differential equation (neural ODE)-based models. We also show that our model can infer dynamics from im-ages and that the Kalman gain efficiently singles out candidates for valuable state updates from noisy observations.