 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControllable Person Image Synthesis with Spatially-Adaptive Warped Normalization
Jun 03, 2021
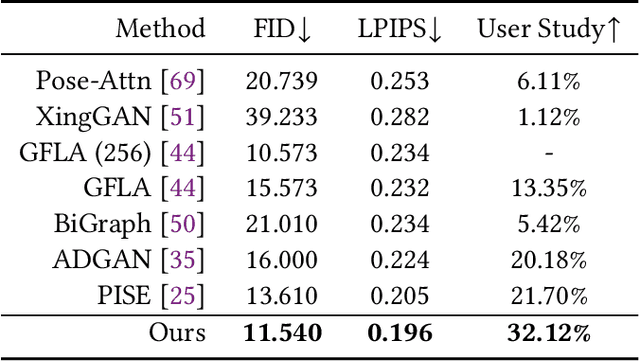

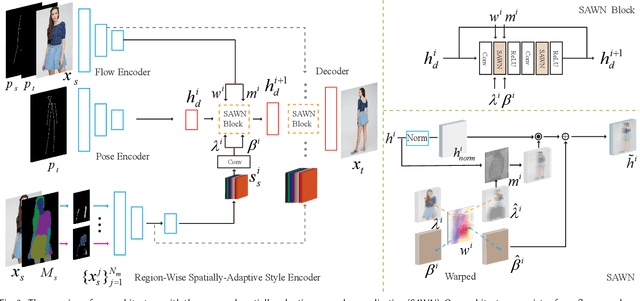
Controllable person image generation aims to produce realistic human images with desirable attributes (e.g., the given pose, cloth textures or hair style). However, the large spatial misalignment between the source and target images makes the standard architectures for image-to-image translation not suitable for this task. Most of the state-of-the-art architectures avoid the alignment step during the generation, which causes many artifacts, especially for person images with complex textures. To solve this problem, we introduce a novel Spatially-Adaptive Warped Normalization (SAWN), which integrates a learned flow-field to warp modulation parameters. This allows us to align person spatial-adaptive styles with pose features efficiently. Moreover, we propose a novel self-training part replacement strategy to refine the pretrained model for the texture-transfer task, significantly improving the quality of the generated cloth and the preservation ability of irrelevant regions. Our experimental results on the widely used DeepFashion dataset demonstrate a significant improvement of the proposed method over the state-of-the-art methods on both pose-transfer and texture-transfer tasks. The source code is available at https://github.com/zhangqianhui/Sawn.
Online Continual Learning under Extreme Memory Constraints
Aug 11, 2020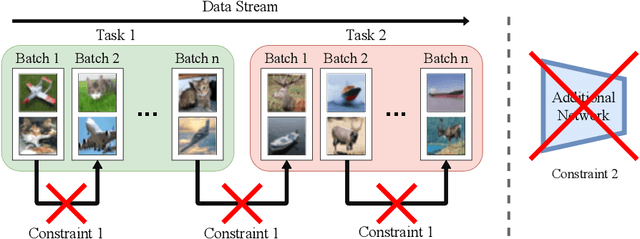
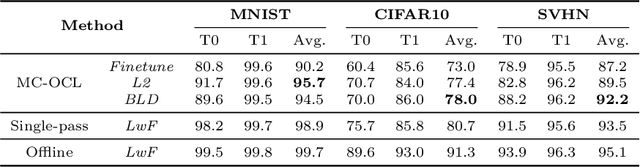
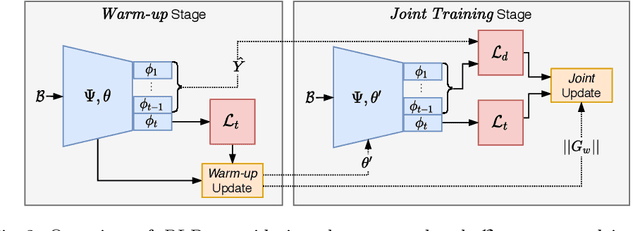
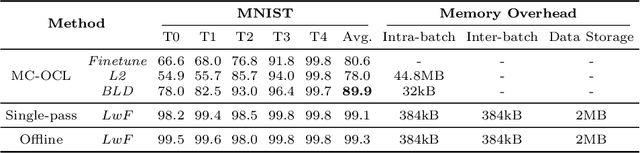
Continual Learning (CL) aims to develop agents emulating the human ability to sequentially learn new tasks while being able to retain knowledge obtained from past experiences. In this paper, we introduce the novel problem of Memory-Constrained Online Continual Learning (MC-OCL) which imposes strict constraints on the memory overhead that a possible algorithm can use to avoid catastrophic forgetting. As most, if not all, previous CL methods violate these constraints, we propose an algorithmic solution to MC-OCL: Batch-level Distillation (BLD), a regularization-based CL approach, which effectively balances stability and plasticity in order to learn from data streams, while preserving the ability to solve old tasks through distillation. Our extensive experimental evaluation, conducted on three publicly available benchmarks, empirically demonstrates that our approach successfully addresses the MC-OCL problem and achieves comparable accuracy to prior distillation methods requiring higher memory overhead.
Dual In-painting Model for Unsupervised Gaze Correction and Animation in the Wild
Aug 09, 2020
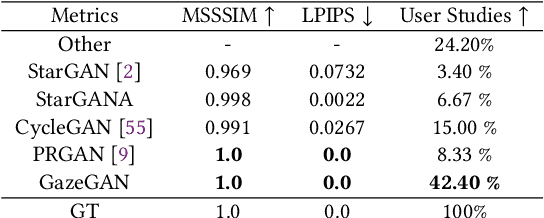
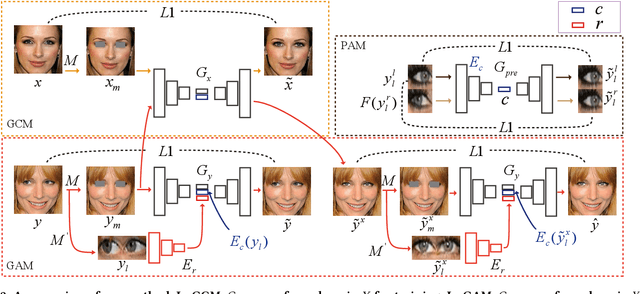
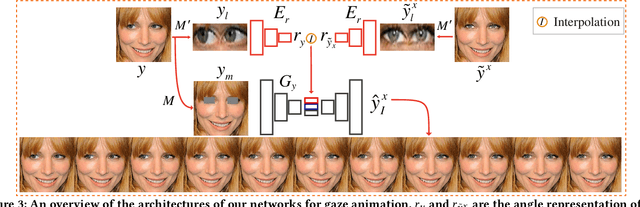
In this paper we address the problem of unsupervised gaze correction in the wild, presenting a solution that works without the need for precise annotations of the gaze angle and the head pose. We have created a new dataset called CelebAGaze, which consists of two domains X, Y, where the eyes are either staring at the camera or somewhere else. Our method consists of three novel modules: the Gaze Correction module (GCM), the Gaze Animation module (GAM), and the Pretrained Autoencoder module (PAM). Specifically, GCM and GAM separately train a dual in-painting network using data from the domain $X$ for gaze correction and data from the domain $Y$ for gaze animation. Additionally, a Synthesis-As-Training method is proposed when training GAM to encourage the features encoded from the eye region to be correlated with the angle information, resulting in a gaze animation which can be achieved by interpolation in the latent space. To further preserve the identity information~(e.g., eye shape, iris color), we propose the PAM with an Autoencoder, which is based on Self-Supervised mirror learning where the bottleneck features are angle-invariant and which works as an extra input to the dual in-painting models. Extensive experiments validate the effectiveness of the proposed method for gaze correction and gaze animation in the wild and demonstrate the superiority of our approach in producing more compelling results than state-of-the-art baselines. Our code, the pretrained models and the supplementary material are available at: https://github.com/zhangqianhui/GazeAnimation.
Whitening for Self-Supervised Representation Learning
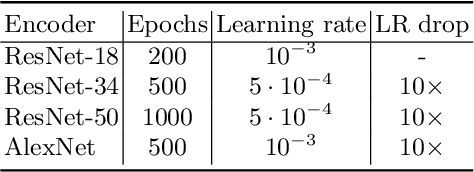
Jul 13, 2020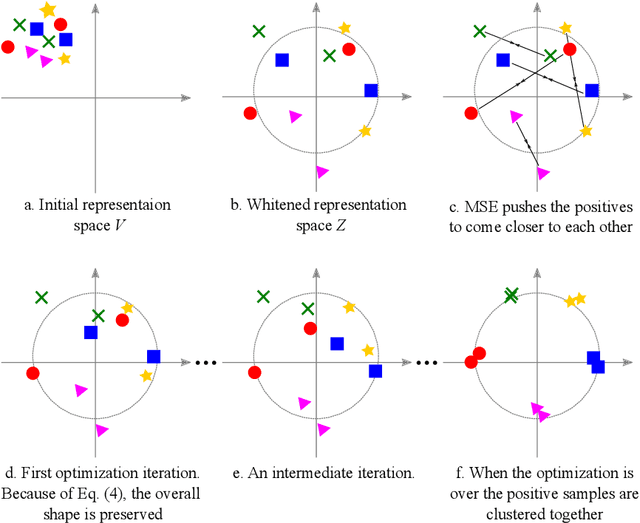
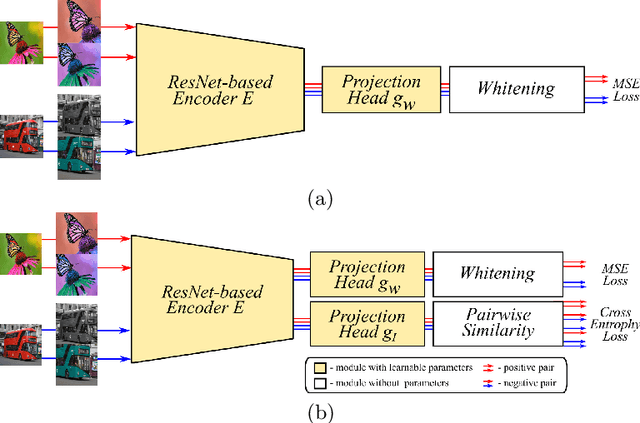
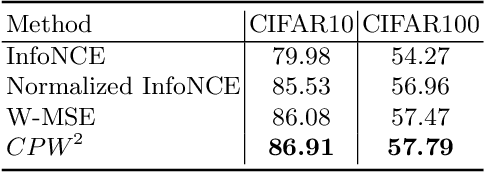
Recent literature on self-supervised learning is based on the contrastive loss, where image instances which share the same semantic content ("positives") are contrasted with instances extracted from other images ("negatives"). However, in order for the learning to be effective, a lot of negatives should be compared with a positive pair. This is not only computationally demanding, but it also requires that the positive and the negative representations are kept consistent with each other over a long training period. In this paper we propose a different direction and a new loss function for self-supervised learning which is based on the whitening of the latent-space features. The whitening operation has a "scattering" effect on the batch samples, which compensates the lack of a large number of negatives, avoiding degenerate solutions where all the sample representations collapse to a single point. We empirically show that our loss accelerates self-supervised training and the learned representations are much more effective for downstream tasks than previously published work.
TriGAN: Image-to-Image Translation for Multi-Source Domain Adaptation
Apr 19, 2020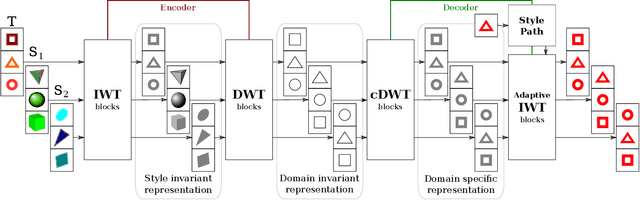
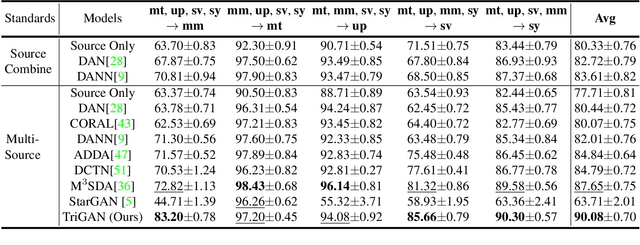
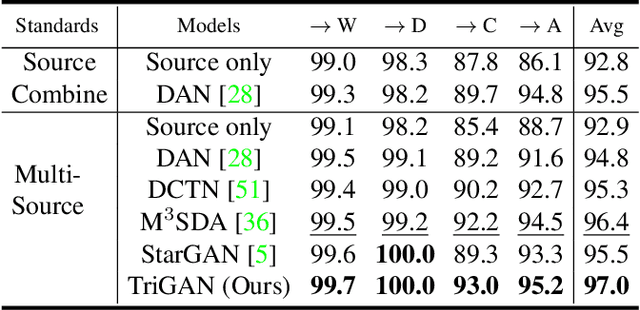

Most domain adaptation methods consider the problem of transferring knowledge to the target domain from a single source dataset. However, in practical applications, we typically have access to multiple sources. In this paper we propose the first approach for Multi-Source Domain Adaptation (MSDA) based on Generative Adversarial Networks. Our method is inspired by the observation that the appearance of a given image depends on three factors: the domain, the style (characterized in terms of low-level features variations) and the content. For this reason we propose to project the image features onto a space where only the dependence from the content is kept, and then re-project this invariant representation onto the pixel space using the target domain and style. In this way, new labeled images can be generated which are used to train a final target classifier. We test our approach using common MSDA benchmarks, showing that it outperforms state-of-the-art methods.
MGGR: MultiModal-Guided Gaze Redirection with Coarse-to-Fine Learning
Apr 13, 2020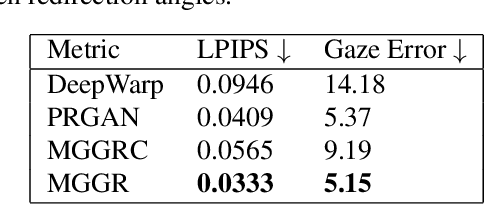
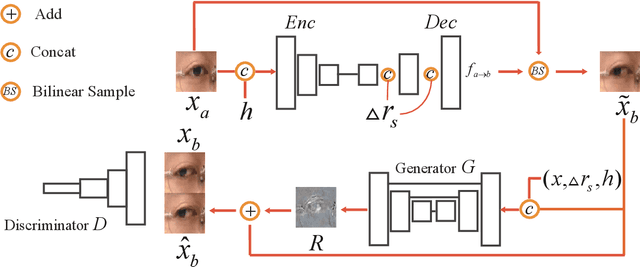
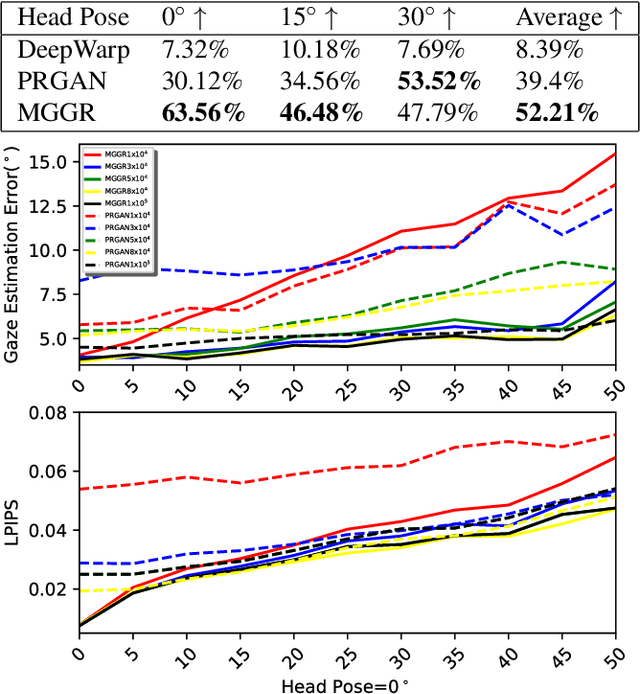
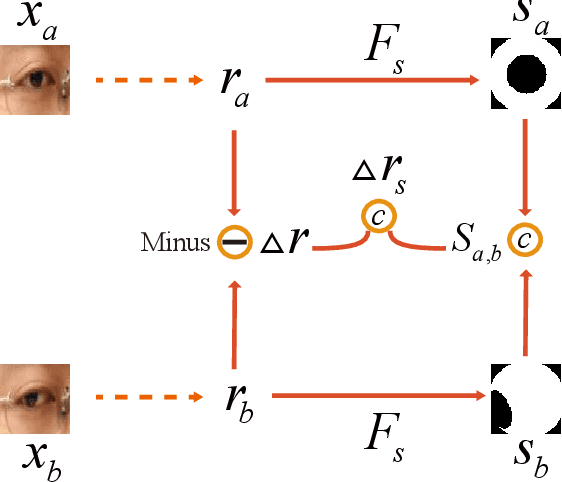
Gaze redirection aims at manipulating a given eye gaze to a desirable direction according to a reference angle and it can be applied to many real life scenarios, such as video-conferencing or taking groups. However, the previous works suffer from two limitations: (1) low-quality generation and (2) low redirection precision. To this end, we propose an innovative MultiModal-Guided Gaze Redirection~(MGGR) framework that fully exploits eye-map images and target angles to adjust a given eye appearance through a designed coarse-to-fine learning. Our contribution is combining the flow-learning and adversarial learning for coarse-to-fine generation. More specifically, the role of the proposed coarse branch with flow field is to rapidly learn the spatial transformation for attaining the warped result with the desired gaze. The proposed fine-grained branch consists of a generator network with conditional residual image learning and a multi-task discriminator to reduce the gap between the warped image and the ground-truth image for recovering the finer texture details. Moreover, we propose leveraging the gazemap for desired angles as an extra guide to further improve the precision of gaze redirection. Extensive experiments on a benchmark dataset show that the proposed method outperforms the state-of-the-art methods in terms of image quality and redirection precision. Further evaluations demonstrate the effectiveness of the proposed coarse-to-fine and gazemap modules.
Attention-based Fusion for Multi-source Human Image Generation
May 07, 2019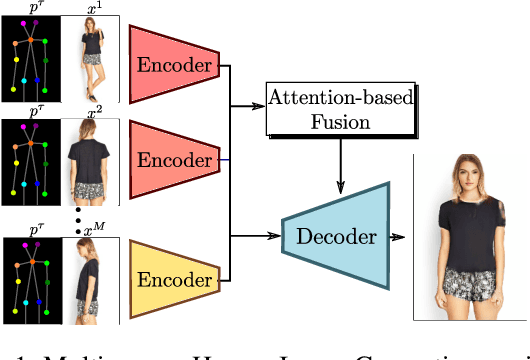
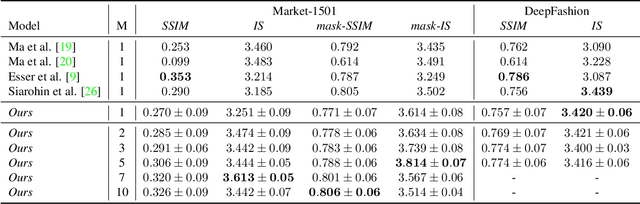
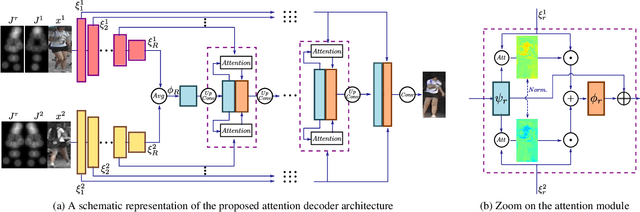
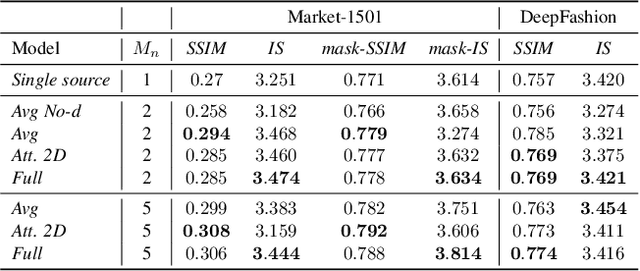
We present a generalization of the person-image generation task, in which a human image is generated conditioned on a target pose and a set X of source appearance images. In this way, we can exploit multiple, possibly complementary images of the same person which are usually available at training and at testing time. The solution we propose is mainly based on a local attention mechanism which selects relevant information from different source image regions, avoiding the necessity to build specific generators for each specific cardinality of X. The empirical evaluation of our method shows the practical interest of addressing the person-image generation problem in a multi-source setting.
Appearance and Pose-Conditioned Human Image Generation using Deformable GANs
Apr 30, 2019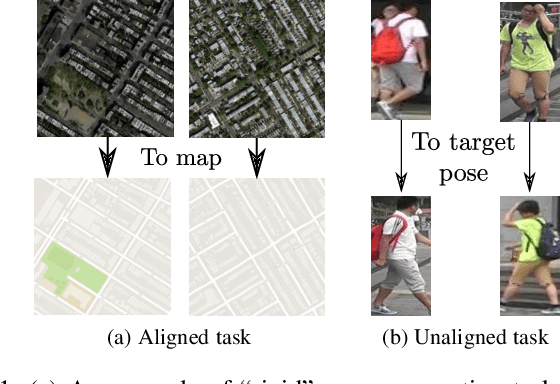
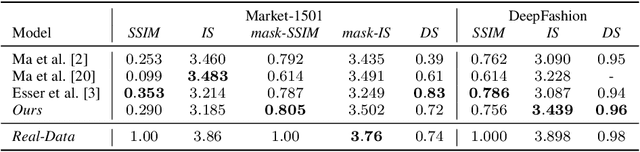
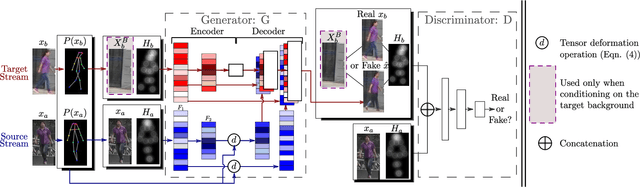

In this paper, we address the problem of generating person images conditioned on both pose and appearance information. Specifically, given an image xa of a person and a target pose P(xb), extracted from a different image xb, we synthesize a new image of that person in pose P(xb), while preserving the visual details in xa. In order to deal with pixel-to-pixel misalignments caused by the pose differences between P(xa) and P(xb), we introduce deformable skip connections in the generator of our Generative Adversarial Network. Moreover, a nearest-neighbour loss is proposed instead of the common L1 and L2 losses in order to match the details of the generated image with the target image. Quantitative and qualitative results, using common datasets and protocols recently proposed for this task, show that our approach is competitive with respect to the state of the art. Moreover, we conduct an extensive evaluation using off-the-shell person re-identification (Re-ID) systems trained with person-generation based augmented data, which is one of the main important applications for this task. Our experiments show that our Deformable GANs can significantly boost the Re-ID accuracy and are even better than data-augmentation methods specifically trained using Re-ID losses.
Metric-Learning based Deep Hashing Network for Content Based Retrieval of Remote Sensing Images
Apr 02, 2019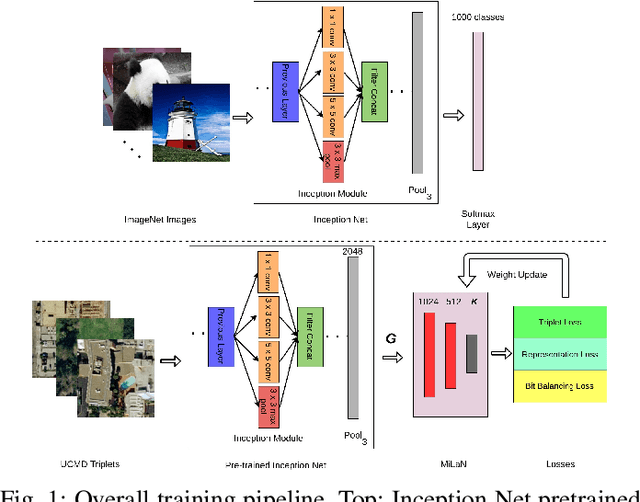
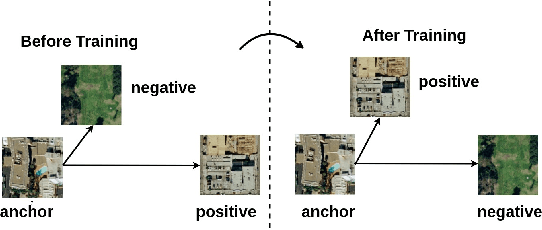
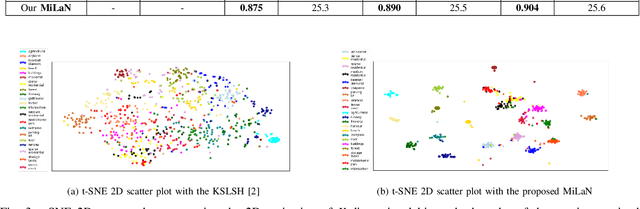

Hashing methods have been recently found very effective in retrieval of remote sensing (RS) images due to their computational efficiency and fast search speed. The traditional hashing methods in RS usually exploit hand-crafted features to learn hash functions to obtain binary codes, which can be insufficient to optimally represent the information content of RS images. To overcome this problem, in this paper we introduce a metric-learning based hashing network, which learns: 1) a semantic-based metric space for effective feature representation; and 2) compact binary hash codes for fast archive search. Our network considers an interplay of multiple loss functions that allows to jointly learn a metric based semantic space facilitating similar images to be clustered together in that target space and at the same time producing compact final activations that lose negligible information when binarized. Experiments carried out on two benchmark RS archives point out that the proposed network significantly improves the retrieval performance under the same retrieval time when compared to the state-of-the-art hashing methods in RS.
Unsupervised Domain Adaptation using Feature-Whitening and Consensus Loss
Mar 07, 2019
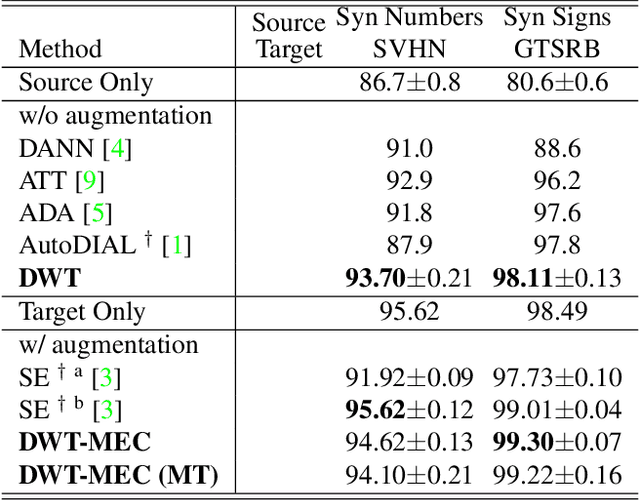


A classifier trained on a dataset seldom works on other datasets obtained under different conditions due to domain shift. This problem is commonly addressed by domain adaptation methods. In this work we introduce a novel deep learning framework which unifies different paradigms in unsupervised domain adaptation. Specifically, we propose domain alignment layers which implement feature whitening for the purpose of matching source and target feature distributions. Additionally, we leverage the unlabeled target data by proposing the Min-Entropy Consensus loss, which regularizes training while avoiding the adoption of many user-defined hyper-parameters. We report results on publicly available datasets, considering both digit classification and object recognition tasks. We show that, in most of our experiments, our approach improves upon previous methods, setting new state-of-the-art performances.