 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge3D Human Pose Lifting with Grid Convolution
Feb 17, 2023Existing lifting networks for regressing 3D human poses from 2D single-view poses are typically constructed with linear layers based on graph-structured representation learning. In sharp contrast to them, this paper presents Grid Convolution (GridConv), mimicking the wisdom of regular convolution operations in image space. GridConv is based on a novel Semantic Grid Transformation (SGT) which leverages a binary assignment matrix to map the irregular graph-structured human pose onto a regular weave-like grid pose representation joint by joint, enabling layer-wise feature learning with GridConv operations. We provide two ways to implement SGT, including handcrafted and learnable designs. Surprisingly, both designs turn out to achieve promising results and the learnable one is better, demonstrating the great potential of this new lifting representation learning formulation. To improve the ability of GridConv to encode contextual cues, we introduce an attention module over the convolutional kernel, making grid convolution operations input-dependent, spatial-aware and grid-specific. We show that our fully convolutional grid lifting network outperforms state-of-the-art methods with noticeable margins under (1) conventional evaluation on Human3.6M and (2) cross-evaluation on MPI-INF-3DHP. Code is available at https://github.com/OSVAI/GridConv
Redistribution of Weights and Activations for AdderNet Quantization
Dec 20, 2022



Adder Neural Network (AdderNet) provides a new way for developing energy-efficient neural networks by replacing the expensive multiplications in convolution with cheaper additions (i.e.l1-norm). To achieve higher hardware efficiency, it is necessary to further study the low-bit quantization of AdderNet. Due to the limitation that the commutative law in multiplication does not hold in l1-norm, the well-established quantization methods on convolutional networks cannot be applied on AdderNets. Thus, the existing AdderNet quantization techniques propose to use only one shared scale to quantize both the weights and activations simultaneously. Admittedly, such an approach can keep the commutative law in the l1-norm quantization process, while the accuracy drop after low-bit quantization cannot be ignored. To this end, we first thoroughly analyze the difference on distributions of weights and activations in AdderNet and then propose a new quantization algorithm by redistributing the weights and the activations. Specifically, the pre-trained full-precision weights in different kernels are clustered into different groups, then the intra-group sharing and inter-group independent scales can be adopted. To further compensate the accuracy drop caused by the distribution difference, we then develop a lossless range clamp scheme for weights and a simple yet effective outliers clamp strategy for activations. Thus, the functionality of full-precision weights and the representation ability of full-precision activations can be fully preserved. The effectiveness of the proposed quantization method for AdderNet is well verified on several benchmarks, e.g., our 4-bit post-training quantized adder ResNet-18 achieves an 66.5% top-1 accuracy on the ImageNet with comparable energy efficiency, which is about 8.5% higher than that of the previous AdderNet quantization methods.
Rethinking skip connection model as a learnable Markov chain
Sep 30, 2022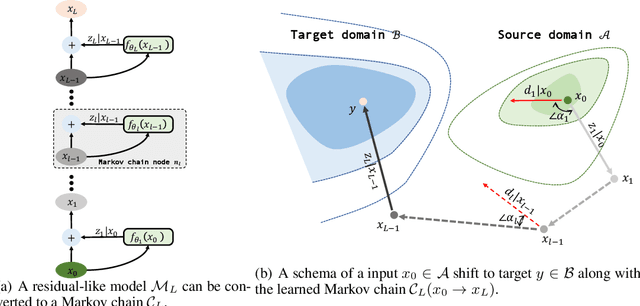

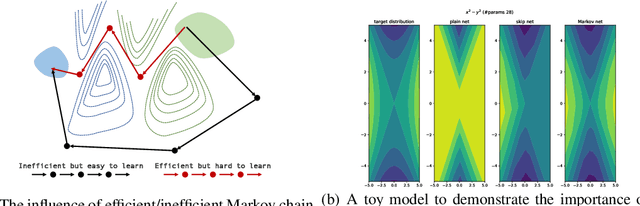
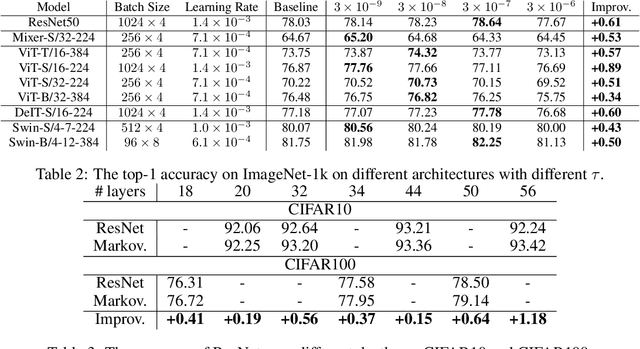
Over past few years afterward the birth of ResNet, skip connection has become the defacto standard for the design of modern architectures due to its widespread adoption, easy optimization and proven performance. Prior work has explained the effectiveness of the skip connection mechanism from different perspectives. In this work, we deep dive into the model's behaviors with skip connections which can be formulated as a learnable Markov chain. An efficient Markov chain is preferred as it always maps the input data to the target domain in a better way. However, while a model is explained as a Markov chain, it is not guaranteed to be optimized following an efficient Markov chain by existing SGD-based optimizers which are prone to get trapped in local optimal points. In order to towards a more efficient Markov chain, we propose a simple routine of penal connection to make any residual-like model become a learnable Markov chain. Aside from that, the penal connection can also be viewed as a particular model regularization and can be easily implemented with one line of code in the most popular deep learning frameworks~\footnote{Source code: \url{https://github.com/densechen/penal-connection}}. The encouraging experimental results in multi-modal translation and image recognition empirically confirm our conjecture of the learnable Markov chain view and demonstrate the superiority of the proposed penal connection.
Vision GNN: An Image is Worth Graph of Nodes
Jun 01, 2022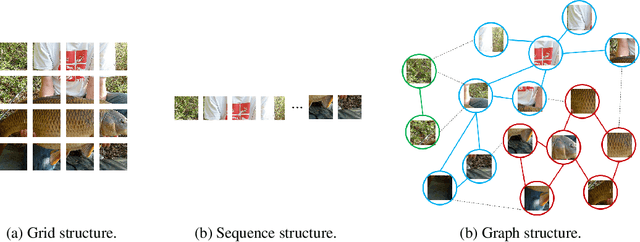
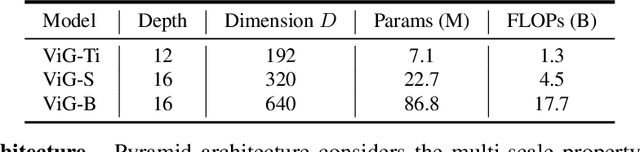
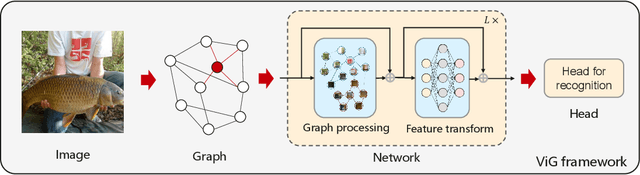
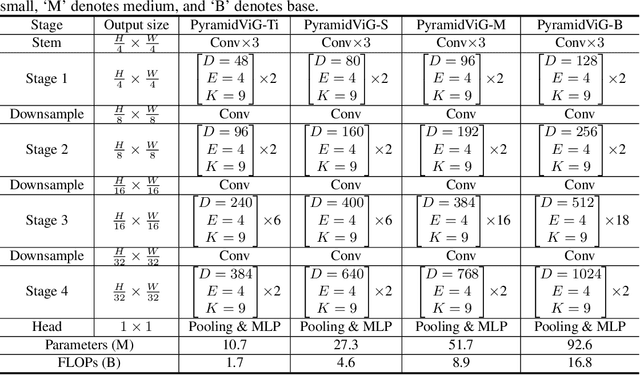
Network architecture plays a key role in the deep learning-based computer vision system. The widely-used convolutional neural network and transformer treat the image as a grid or sequence structure, which is not flexible to capture irregular and complex objects. In this paper, we propose to represent the image as a graph structure and introduce a new Vision GNN (ViG) architecture to extract graph-level feature for visual tasks. We first split the image to a number of patches which are viewed as nodes, and construct a graph by connecting the nearest neighbors. Based on the graph representation of images, we build our ViG model to transform and exchange information among all the nodes. ViG consists of two basic modules: Grapher module with graph convolution for aggregating and updating graph information, and FFN module with two linear layers for node feature transformation. Both isotropic and pyramid architectures of ViG are built with different model sizes. Extensive experiments on image recognition and object detection tasks demonstrate the superiority of our ViG architecture. We hope this pioneering study of GNN on general visual tasks will provide useful inspiration and experience for future research. The PyTroch code will be available at https://github.com/huawei-noah/CV-Backbones and the MindSpore code will be avaiable at https://gitee.com/mindspore/models.
GhostNets on Heterogeneous Devices via Cheap Operations
Jan 10, 2022
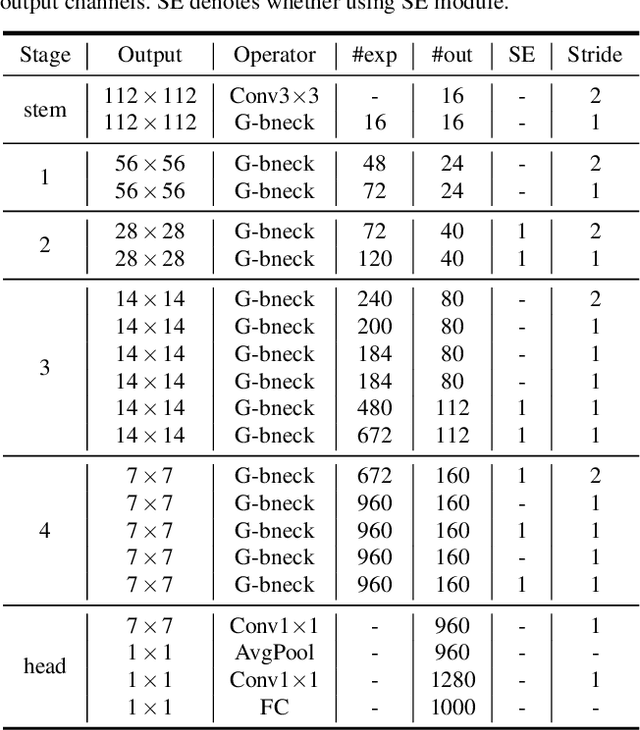
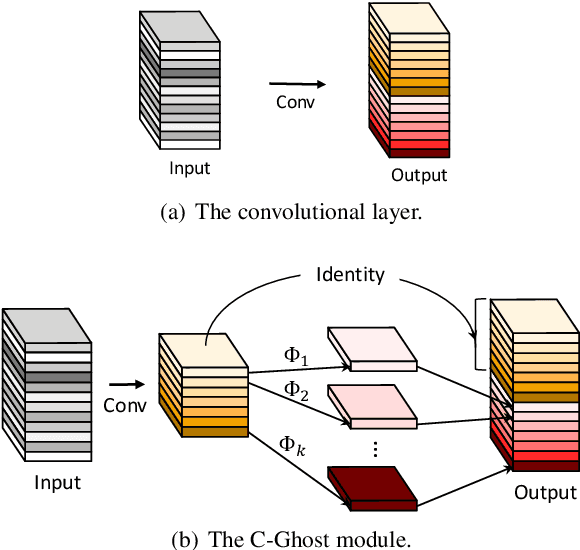
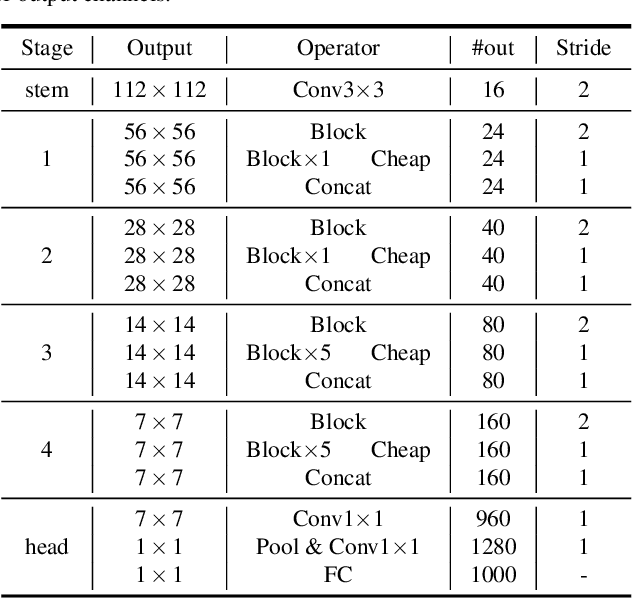
Deploying convolutional neural networks (CNNs) on mobile devices is difficult due to the limited memory and computation resources. We aim to design efficient neural networks for heterogeneous devices including CPU and GPU, by exploiting the redundancy in feature maps, which has rarely been investigated in neural architecture design. For CPU-like devices, we propose a novel CPU-efficient Ghost (C-Ghost) module to generate more feature maps from cheap operations. Based on a set of intrinsic feature maps, we apply a series of linear transformations with cheap cost to generate many ghost feature maps that could fully reveal information underlying intrinsic features. The proposed C-Ghost module can be taken as a plug-and-play component to upgrade existing convolutional neural networks. C-Ghost bottlenecks are designed to stack C-Ghost modules, and then the lightweight C-GhostNet can be easily established. We further consider the efficient networks for GPU devices. Without involving too many GPU-inefficient operations (e.g.,, depth-wise convolution) in a building stage, we propose to utilize the stage-wise feature redundancy to formulate GPU-efficient Ghost (G-Ghost) stage structure. The features in a stage are split into two parts where the first part is processed using the original block with fewer output channels for generating intrinsic features, and the other are generated using cheap operations by exploiting stage-wise redundancy. Experiments conducted on benchmarks demonstrate the effectiveness of the proposed C-Ghost module and the G-Ghost stage. C-GhostNet and G-GhostNet can achieve the optimal trade-off of accuracy and latency for CPU and GPU, respectively. Code is available at https://github.com/huawei-noah/CV-Backbones.
Elastic-Link for Binarized Neural Network
Dec 19, 2021
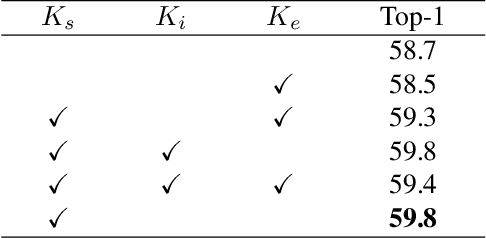
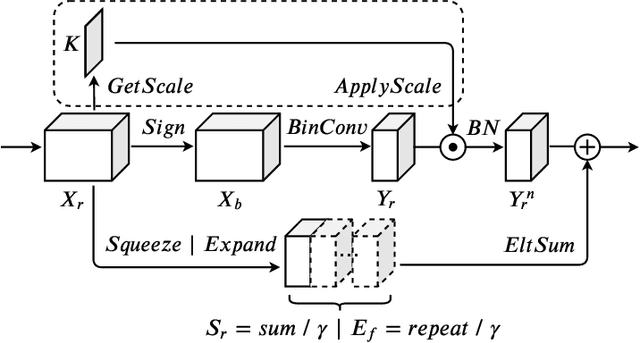
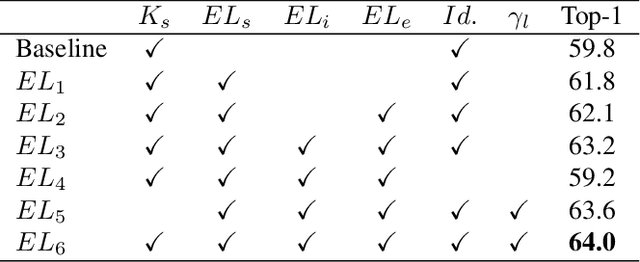
Recent work has shown that Binarized Neural Networks (BNNs) are able to greatly reduce computational costs and memory footprints, facilitating model deployment on resource-constrained devices. However, in comparison to their full-precision counterparts, BNNs suffer from severe accuracy degradation. Research aiming to reduce this accuracy gap has thus far largely focused on specific network architectures with few or no 1x1 convolutional layers, for which standard binarization methods do not work well. Because 1x1 convolutions are common in the design of modern architectures (e.g. GoogleNet, ResNet, DenseNet), it is crucial to develop a method to binarize them effectively for BNNs to be more widely adopted. In this work, we propose an "Elastic-Link" (EL) module to enrich information flow within a BNN by adaptively adding real-valued input features to the subsequent convolutional output features. The proposed EL module is easily implemented and can be used in conjunction with other methods for BNNs. We demonstrate that adding EL to BNNs produces a significant improvement on the challenging large-scale ImageNet dataset. For example, we raise the top-1 accuracy of binarized ResNet26 from 57.9% to 64.0%. EL also aids convergence in the training of binarized MobileNet, for which a top-1 accuracy of 56.4% is achieved. Finally, with the integration of ReActNet, it yields a new state-of-the-art result of 71.9% top-1 accuracy.
Learning Versatile Convolution Filters for Efficient Visual Recognition
Sep 20, 2021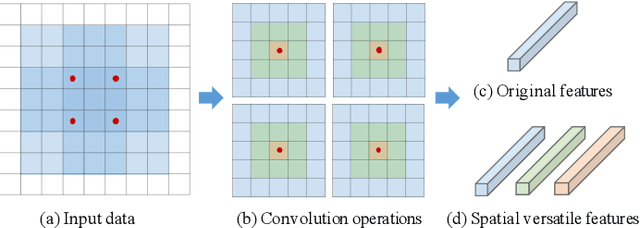
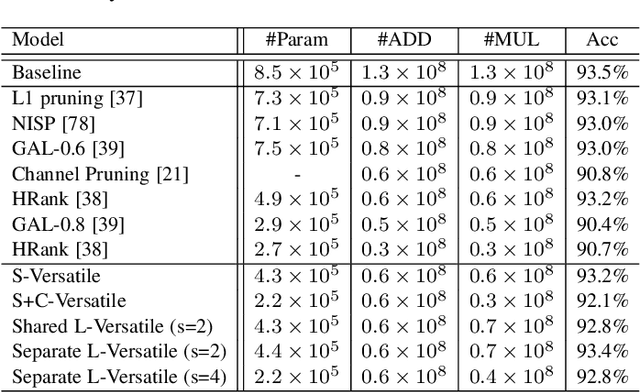
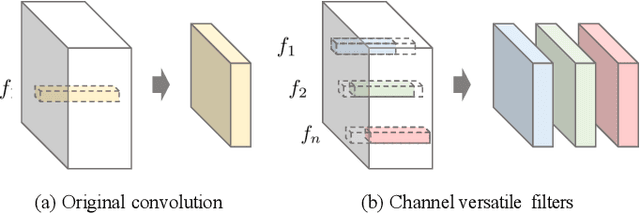
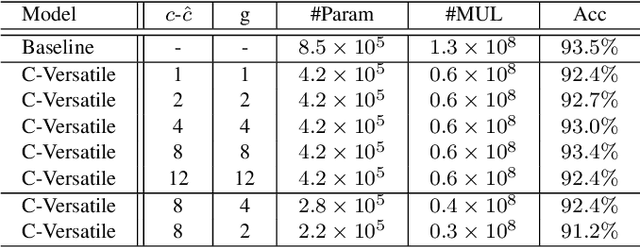
This paper introduces versatile filters to construct efficient convolutional neural networks that are widely used in various visual recognition tasks. Considering the demands of efficient deep learning techniques running on cost-effective hardware, a number of methods have been developed to learn compact neural networks. Most of these works aim to slim down filters in different ways, \eg,~investigating small, sparse or quantized filters. In contrast, we treat filters from an additive perspective. A series of secondary filters can be derived from a primary filter with the help of binary masks. These secondary filters all inherit in the primary filter without occupying more storage, but once been unfolded in computation they could significantly enhance the capability of the filter by integrating information extracted from different receptive fields. Besides spatial versatile filters, we additionally investigate versatile filters from the channel perspective. Binary masks can be further customized for different primary filters under orthogonal constraints. We conduct theoretical analysis on network complexity and an efficient convolution scheme is introduced. Experimental results on benchmark datasets and neural networks demonstrate that our versatile filters are able to achieve comparable accuracy as that of original filters, but require less memory and computation cost.
Overfitting the Data: Compact Neural Video Delivery via Content-aware Feature Modulation
Aug 18, 2021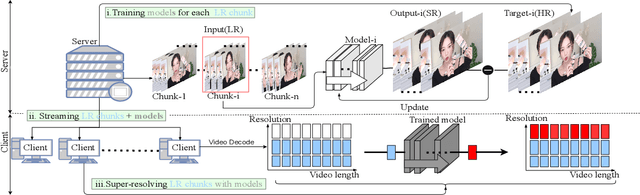
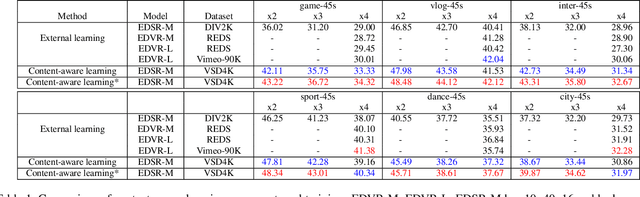

Internet video delivery has undergone a tremendous explosion of growth over the past few years. However, the quality of video delivery system greatly depends on the Internet bandwidth. Deep Neural Networks (DNNs) are utilized to improve the quality of video delivery recently. These methods divide a video into chunks, and stream LR video chunks and corresponding content-aware models to the client. The client runs the inference of models to super-resolve the LR chunks. Consequently, a large number of models are streamed in order to deliver a video. In this paper, we first carefully study the relation between models of different chunks, then we tactfully design a joint training framework along with the Content-aware Feature Modulation (CaFM) layer to compress these models for neural video delivery. {\bf With our method, each video chunk only requires less than $1\% $ of original parameters to be streamed, achieving even better SR performance.} We conduct extensive experiments across various SR backbones, video time length, and scaling factors to demonstrate the advantages of our method. Besides, our method can be also viewed as a new approach of video coding. Our primary experiments achieve better video quality compared with the commercial H.264 and H.265 standard under the same storage cost, showing the great potential of the proposed method. Code is available at:\url{https://github.com/Neural-video-delivery/CaFM-Pytorch-ICCV2021}
Dynamic Resolution Network
Jun 05, 2021
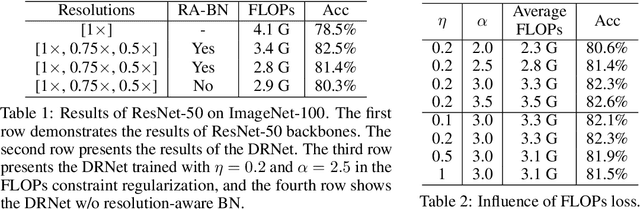
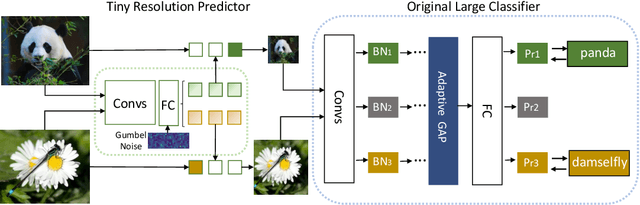
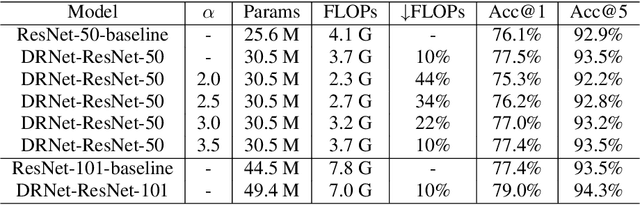
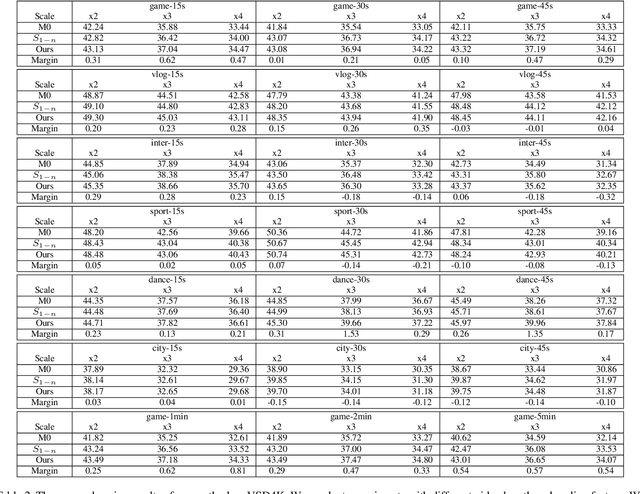
Deep convolutional neural networks (CNNs) are often of sophisticated design with numerous convolutional layers and learnable parameters for the accuracy reason. To alleviate the expensive costs of deploying them on mobile devices, recent works have made huge efforts for excavating redundancy in pre-defined architectures. Nevertheless, the redundancy on the input resolution of modern CNNs has not been fully investigated, i.e., the resolution of input image is fixed. In this paper, we observe that the smallest resolution for accurately predicting the given image is different using the same neural network. To this end, we propose a novel dynamic-resolution network (DRNet) in which the resolution is determined dynamically based on each input sample. Thus, a resolution predictor with negligible computational costs is explored and optimized jointly with the desired network. In practice, the predictor learns the smallest resolution that can retain and even exceed the original recognition accuracy for each image. During the inference, each input image will be resized to its predicted resolution for minimizing the overall computation burden. We then conduct extensive experiments on several benchmark networks and datasets. The results show that our DRNet can be embedded in any off-the-shelf network architecture to obtain a considerable reduction in computational complexity. For instance, DRNet achieves similar performance with an about 34% computation reduction, while gains 1.4% accuracy increase with 10% computation reduction compared to the original ResNet-50 on ImageNet.
Transformer in Transformer
Feb 27, 2021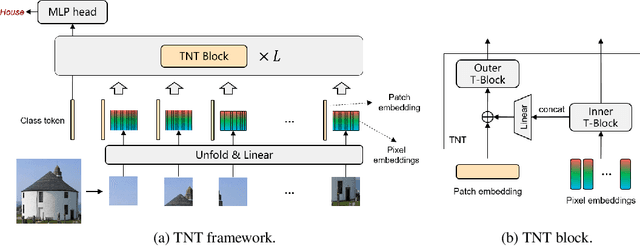

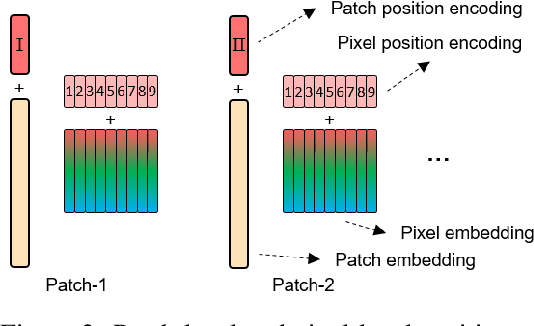
Transformer is a type of self-attention-based neural networks originally applied for NLP tasks. Recently, pure transformer-based models are proposed to solve computer vision problems. These visual transformers usually view an image as a sequence of patches while they ignore the intrinsic structure information inside each patch. In this paper, we propose a novel Transformer-iN-Transformer (TNT) model for modeling both patch-level and pixel-level representation. In each TNT block, an outer transformer block is utilized to process patch embeddings, and an inner transformer block extracts local features from pixel embeddings. The pixel-level feature is projected to the space of patch embedding by a linear transformation layer and then added into the patch. By stacking the TNT blocks, we build the TNT model for image recognition. Experiments on ImageNet benchmark and downstream tasks demonstrate the superiority and efficiency of the proposed TNT architecture. For example, our TNT achieves $81.3\%$ top-1 accuracy on ImageNet which is $1.5\%$ higher than that of DeiT with similar computational cost. The code will be available at https://github.com/huawei-noah/noah-research/tree/master/TNT.