 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlind Room Parameter Estimation Using Multiple-Multichannel Speech Recordings
Jul 29, 2021
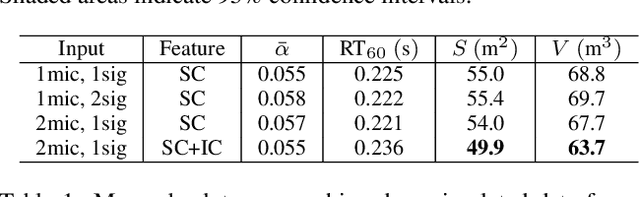
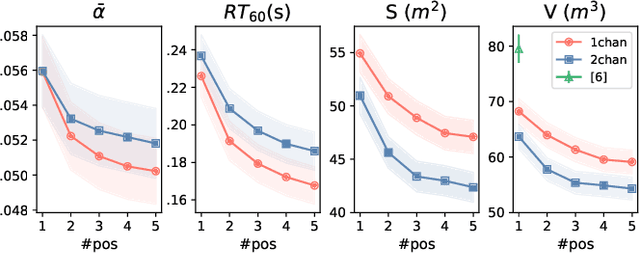
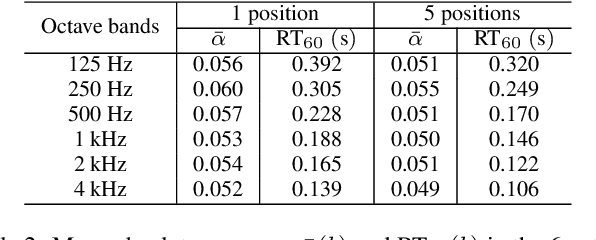
Knowing the geometrical and acoustical parameters of a room may benefit applications such as audio augmented reality, speech dereverberation or audio forensics. In this paper, we study the problem of jointly estimating the total surface area, the volume, as well as the frequency-dependent reverberation time and mean surface absorption of a room in a blind fashion, based on two-channel noisy speech recordings from multiple, unknown source-receiver positions. A novel convolutional neural network architecture leveraging both single- and inter-channel cues is proposed and trained on a large, realistic simulated dataset. Results on both simulated and real data show that using multiple observations in one room significantly reduces estimation errors and variances on all target quantities, and that using two channels helps the estimation of surface and volume. The proposed model outperforms a recently proposed blind volume estimation method on the considered datasets.
UIAI System for Short-Duration Speaker Verification Challenge 2020
Jul 26, 2020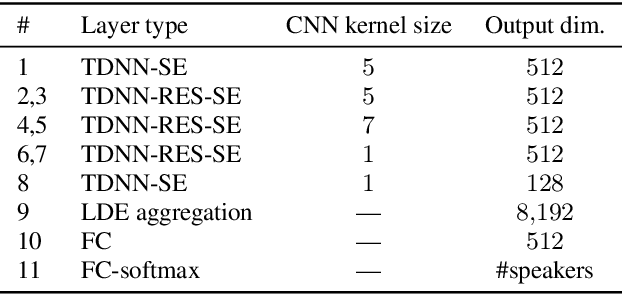
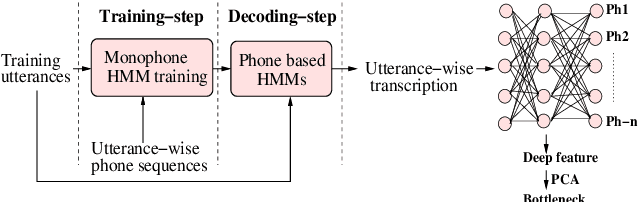
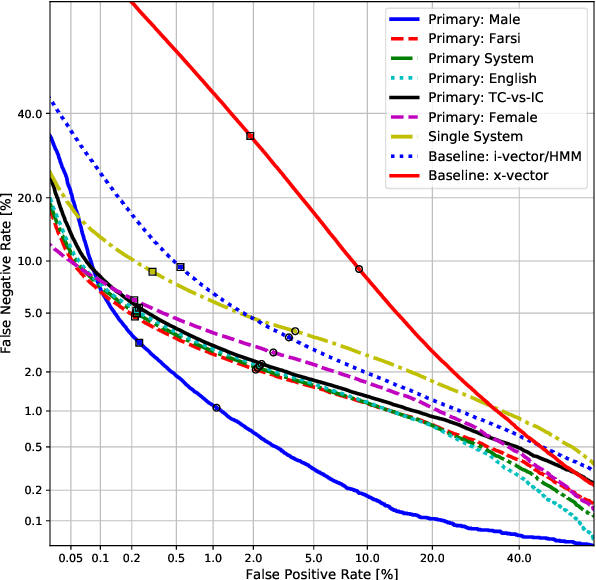
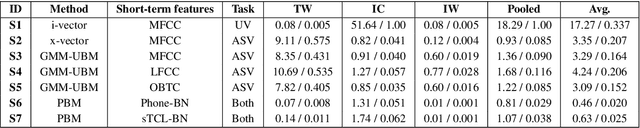
In this work, we present the system description of the UIAI entry for the short-duration speaker verification (SdSV) challenge 2020. Our focus is on Task 1 dedicated to text-dependent speaker verification. We investigate different feature extraction and modeling approaches for automatic speaker verification (ASV) and utterance verification (UV). We have also studied different fusion strategies for combining UV and ASV modules. Our primary submission to the challenge is the fusion of seven subsystems which yields a normalized minimum detection cost function (minDCF) of 0.072 and an equal error rate (EER) of 2.14% on the evaluation set. The single system consisting of a pass-phrase identification based model with phone-discriminative bottleneck features gives a normalized minDCF of 0.118 and achieves 19% relative improvement over the state-of-the-art challenge baseline.
Design Choices for X-vector Based Speaker Anonymization
May 18, 2020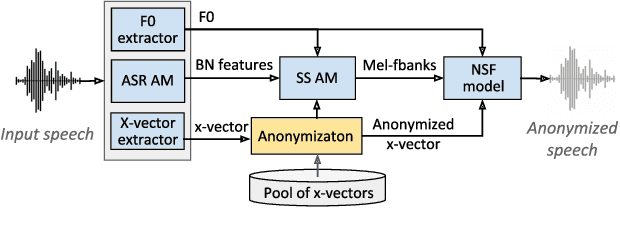
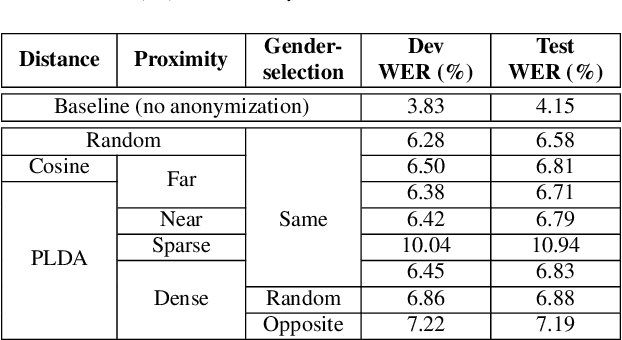
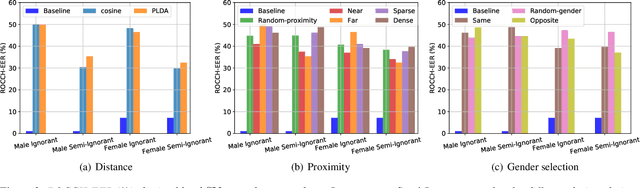
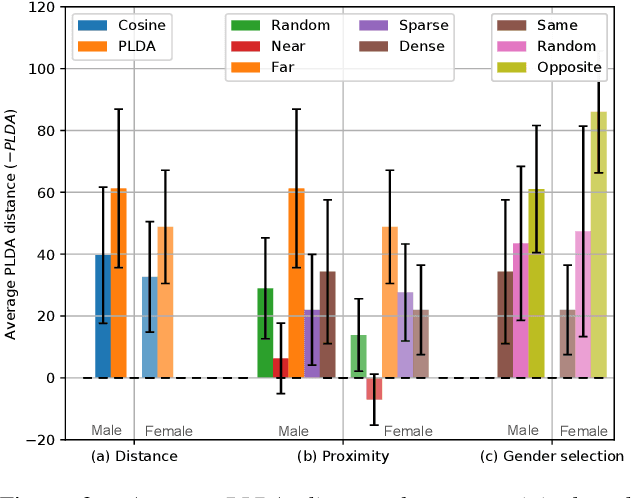
The recently proposed x-vector based anonymization scheme converts any input voice into that of a random pseudo-speaker. In this paper, we present a flexible pseudo-speaker selection technique as a baseline for the first VoicePrivacy Challenge. We explore several design choices for the distance metric between speakers, the region of x-vector space where the pseudo-speaker is picked, and gender selection. To assess the strength of anonymization achieved, we consider attackers using an x-vector based speaker verification system who may use original or anonymized speech for enrollment, depending on their knowledge of the anonymization scheme. The Equal Error Rate (EER) achieved by the attackers and the decoding Word Error Rate (WER) over anonymized data are reported as the measures of privacy and utility. Experiments are performed using datasets derived from LibriSpeech to find the optimal combination of design choices in terms of privacy and utility.
Introducing the VoicePrivacy Initiative
May 13, 2020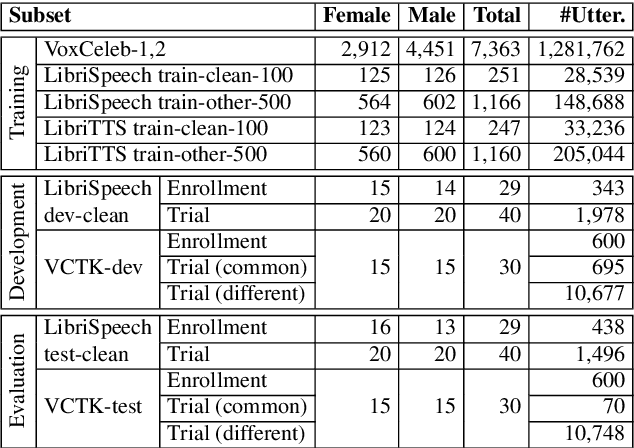
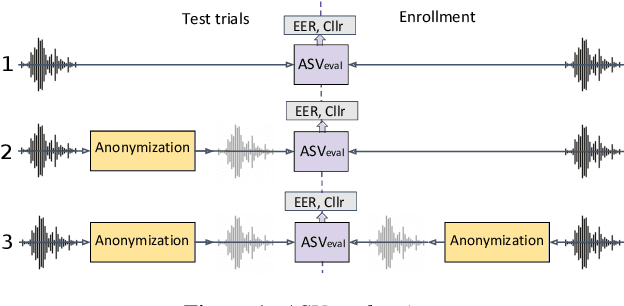
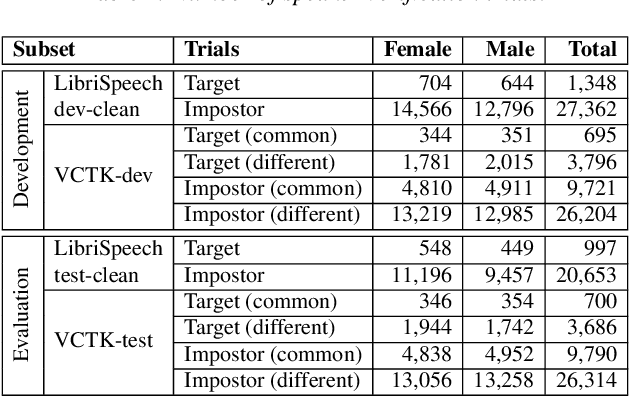
The VoicePrivacy initiative aims to promote the development of privacy preservation tools for speech technology by gathering a new community to define the tasks of interest and the evaluation methodology, and benchmarking solutions through a series of challenges. In this paper, we formulate the voice anonymization task selected for the VoicePrivacy 2020 Challenge and describe the datasets used for system development and evaluation. We also present the attack models and the associated objective and subjective evaluation metrics. We introduce two anonymization baselines and report objective evaluation results.
Foreground-Background Ambient Sound Scene Separation
May 11, 2020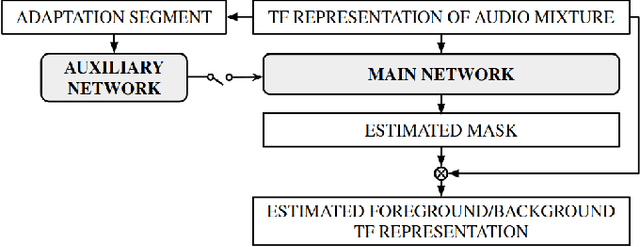
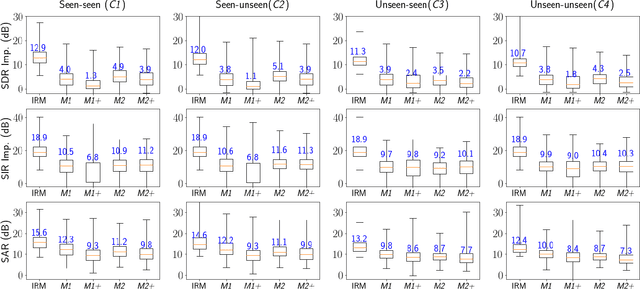
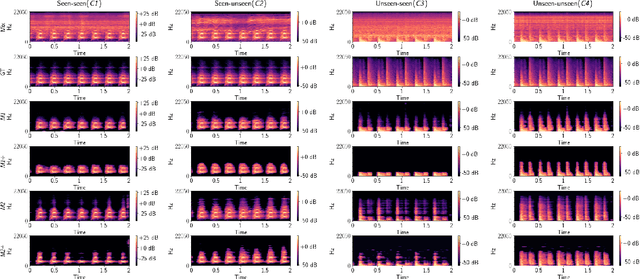
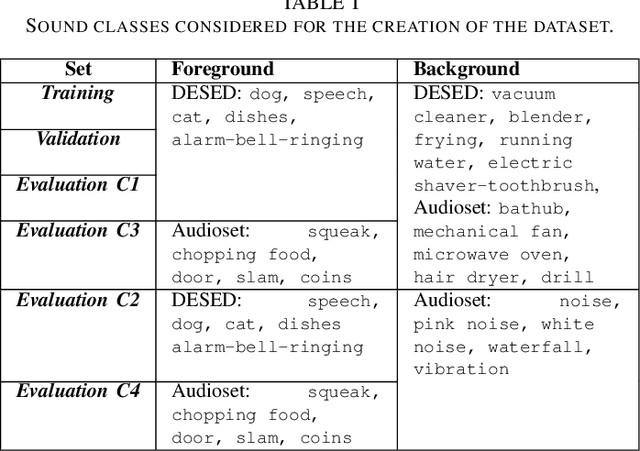
Ambient sound scenes typically comprise multiple short events occurring on top of a somewhat stationary background. We consider the task of separating these events from the background, which we call foreground-background ambient sound scene separation. We propose a deep learning-based separation framework with a suitable feature normaliza-tion scheme and an optional auxiliary network capturing the background statistics, and we investigate its ability to handle the great variety of sound classes encountered in ambient sound scenes, which have often not been seen in training. To do so, we create single-channel foreground-background mixtures using isolated sounds from the DESED and Audioset datasets, and we conduct extensive experiments with mixtures of seen or unseen sound classes at various signal-to-noise ratios. Our experimental findings demonstrate the generalization ability of the proposed approach.
CHiME-6 Challenge:Tackling Multispeaker Speech Recognition for Unsegmented Recordings
May 02, 2020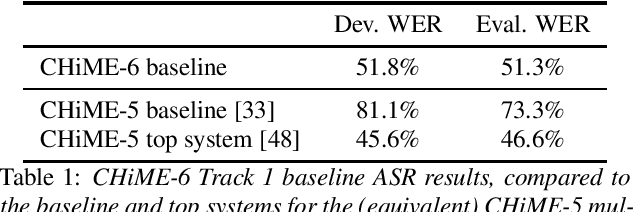

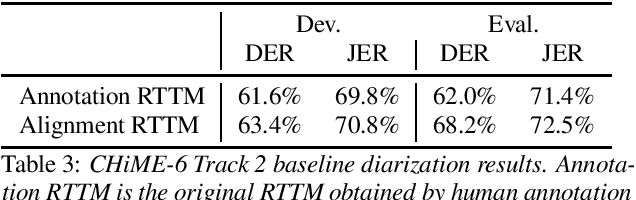

Following the success of the 1st, 2nd, 3rd, 4th and 5th CHiME challenges we organize the 6th CHiME Speech Separation and Recognition Challenge (CHiME-6). The new challenge revisits the previous CHiME-5 challenge and further considers the problem of distant multi-microphone conversational speech diarization and recognition in everyday home environments. Speech material is the same as the previous CHiME-5 recordings except for accurate array synchronization. The material was elicited using a dinner party scenario with efforts taken to capture data that is representative of natural conversational speech. This paper provides a baseline description of the CHiME-6 challenge for both segmented multispeaker speech recognition (Track 1) and unsegmented multispeaker speech recognition (Track 2). Of note, Track 2 is the first challenge activity in the community to tackle an unsegmented multispeaker speech recognition scenario with a complete set of reproducible open source baselines providing speech enhancement, speaker diarization, and speech recognition modules.
Limitations of weak labels for embedding and tagging
Feb 13, 2020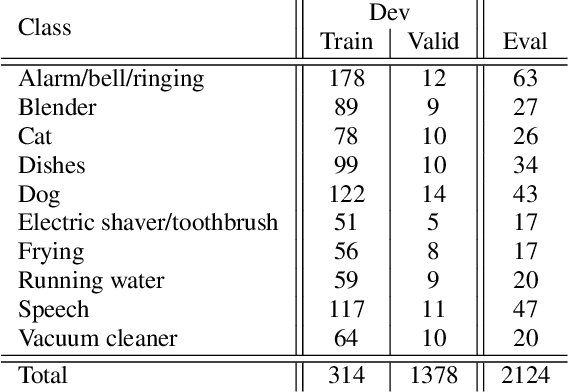
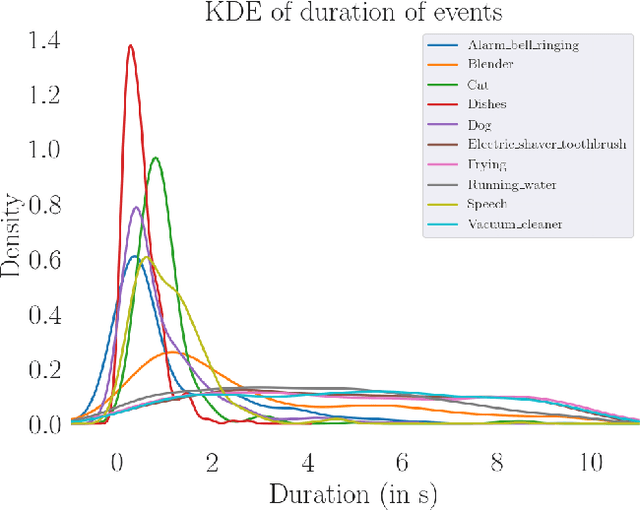
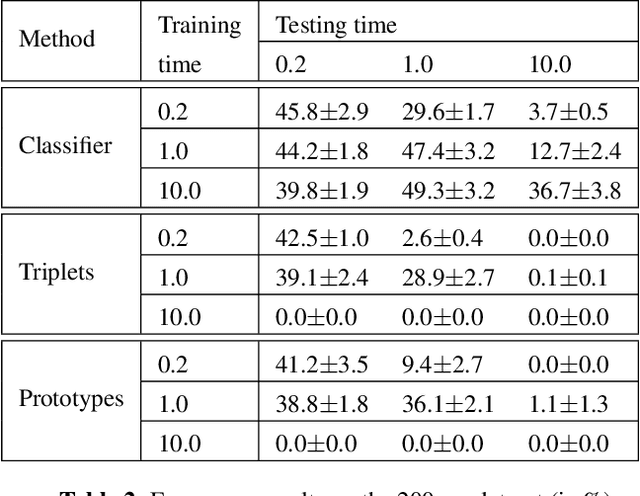
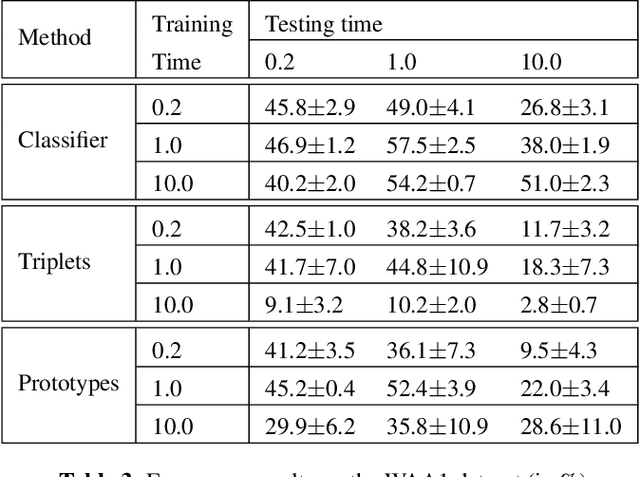
While many datasets and approaches in ambient sound analysis use weakly labeled data, the impact of weak labels on the performance in comparison to strong labels remains unclear. Indeed, weakly labeled data is usually used because it is too expensive to annotate every data with a strong label and for some use cases strong labels are not sure to give better results. Moreover, weak labels are usually mixed with various other challenges like multilabels, unbalanced classes, overlapping events. In this paper, we formulate a supervised problem which involves weak labels. We create a dataset that focuses on difference between strong and weak labels. We investigate the impact of weak labels when training an embedding or an end-to-end classi-fier. Different experimental scenarios are discussed to give insights into which type of applications are most sensitive to weakly labeled data.
Joint DNN-Based Multichannel Reduction of Acoustic Echo, Reverberation and Noise
Dec 20, 2019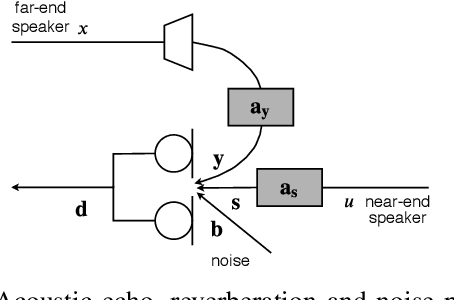
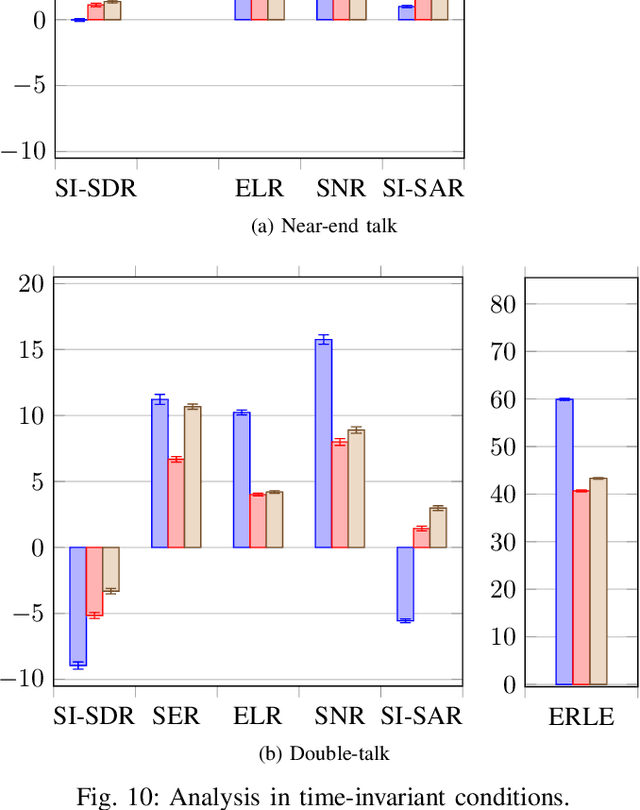
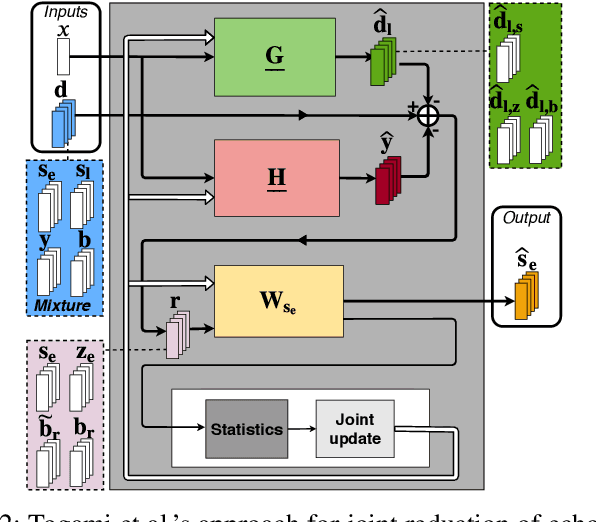
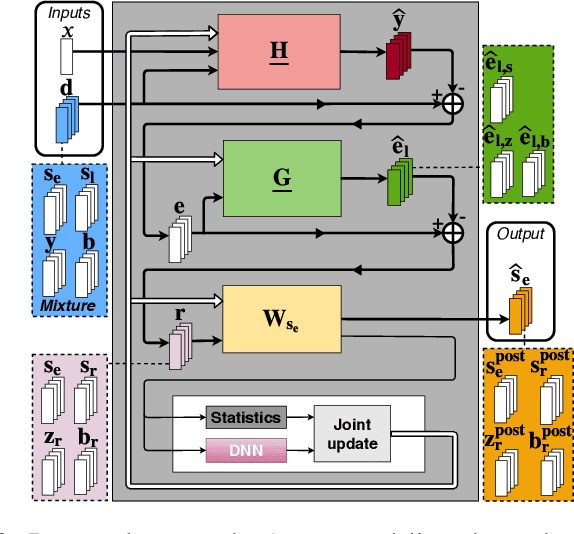
We consider the problem of simultaneous reduction of acoustic echo, reverberation and noise. In real scenarios, these distortion sources may occur simultaneously and reducing them implies combining the corresponding distortion-specific filters. As these filters interact with each other, they must be jointly optimized. We propose to model the target and residual signals after linear echo cancellation and dereverberation using a multichannel Gaussian modeling framework and to jointly represent their spectra by means of a neural network. We develop an iterative block-coordinate ascent algorithm to update all the filters. We evaluate our system on real recordings of acoustic echo, reverberation and noise acquired with a smart speaker in various situations. The proposed approach outperforms in terms of overall distortion a cascade of the individual approaches and a joint reduction approach which does not rely on a spectral model of the target and residual signals.
Privacy-Preserving Adversarial Representation Learning in ASR: Reality or Illusion?
Nov 12, 2019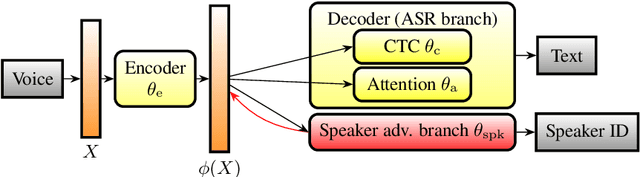
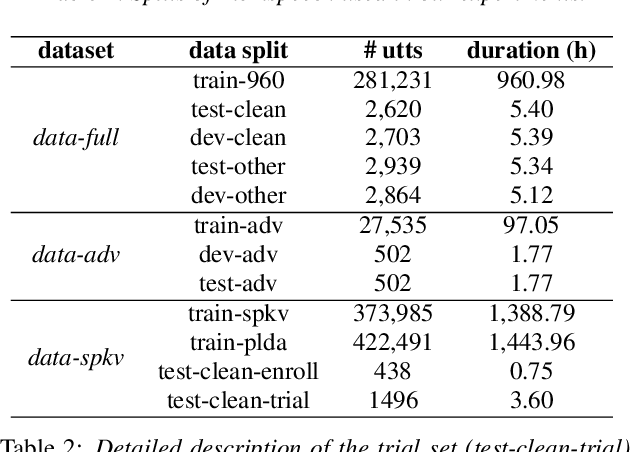
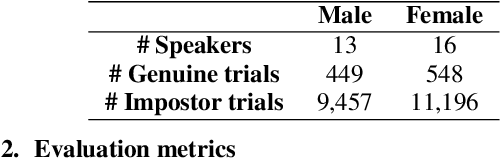
Automatic speech recognition (ASR) is a key technology in many services and applications. This typically requires user devices to send their speech data to the cloud for ASR decoding. As the speech signal carries a lot of information about the speaker, this raises serious privacy concerns. As a solution, an encoder may reside on each user device which performs local computations to anonymize the representation. In this paper, we focus on the protection of speaker identity and study the extent to which users can be recognized based on the encoded representation of their speech as obtained by a deep encoder-decoder architecture trained for ASR. Through speaker identification and verification experiments on the Librispeech corpus with open and closed sets of speakers, we show that the representations obtained from a standard architecture still carry a lot of information about speaker identity. We then propose to use adversarial training to learn representations that perform well in ASR while hiding speaker identity. Our results demonstrate that adversarial training dramatically reduces the closed-set classification accuracy, but this does not translate into increased open-set verification error hence into increased protection of the speaker identity in practice. We suggest several possible reasons behind this negative result.
Evaluating Voice Conversion-based Privacy Protection against Informed Attackers
Nov 10, 2019
Speech signals are a rich source of speaker-related information including sensitive attributes like identity or accent. With a small amount of found speech data, such attributes can be extracted and modeled for malicious purposes like voice cloning, spoofing, etc. In this paper, we investigate speaker anonymization strategies based on voice conversion. In contrast to prior evaluations, we argue that different types of attackers can be defined depending on the extent of their knowledge about the conversion scheme. We compare two frequency warping-based conversion methods and a deep learning based method in three attack scenarios. The utility of the converted speech is measured through the word error rate achieved by automatic speech recognition, while privacy protection is assessed by state-of-the-art speaker verification techniques (i-vectors and x-vectors). Our results show that voice conversion schemes are unable to effectively protect against an attacker that has extensive knowledge of the type of conversion and how it has been applied, but may provide some protection against less knowledgeable attackers.