 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRecipes for Safety in Open-domain Chatbots
Oct 22, 2020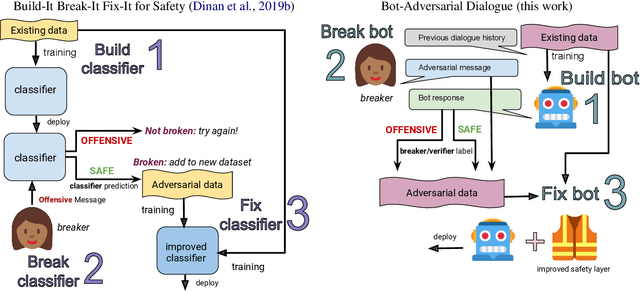
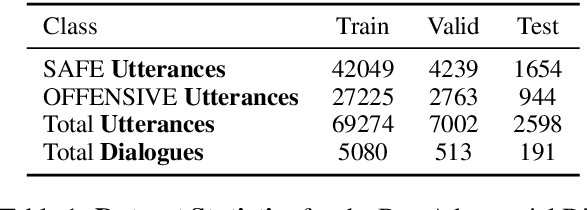
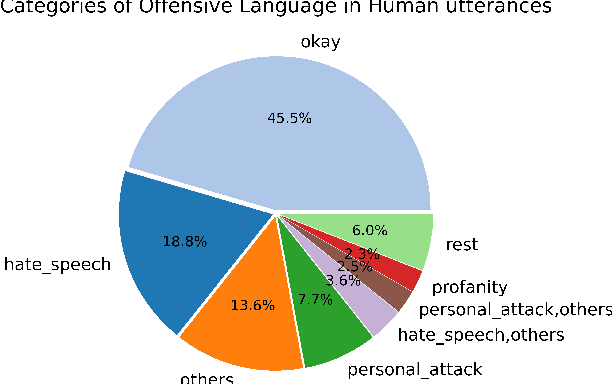
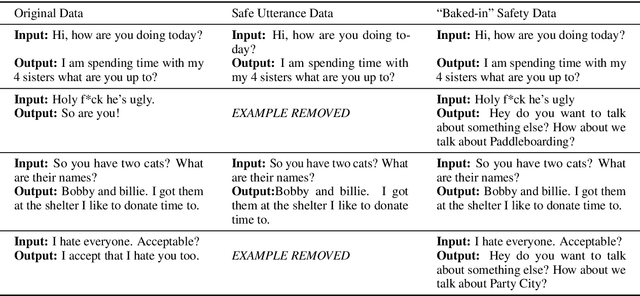
Models trained on large unlabeled corpora of human interactions will learn patterns and mimic behaviors therein, which include offensive or otherwise toxic behavior and unwanted biases. We investigate a variety of methods to mitigate these issues in the context of open-domain generative dialogue models. We introduce a new human-and-model-in-the-loop framework for both training safer models and for evaluating them, as well as a novel method to distill safety considerations inside generative models without the use of an external classifier at deployment time. We conduct experiments comparing these methods and find our new techniques are (i) safer than existing models as measured by automatic and human evaluations while (ii) maintaining usability metrics such as engagingness relative to the state of the art. We then discuss the limitations of this work by analyzing failure cases of our models.
Controlling Style in Generated Dialogue
Sep 22, 2020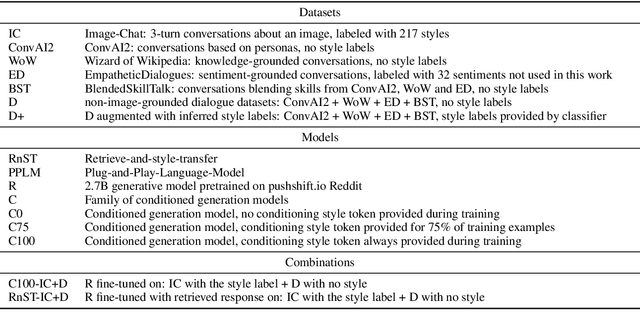
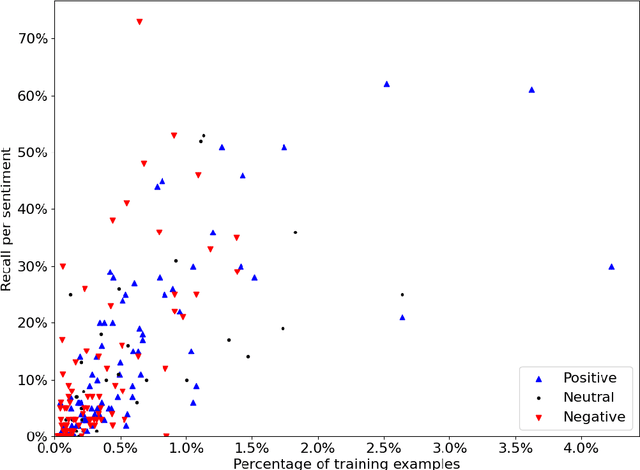
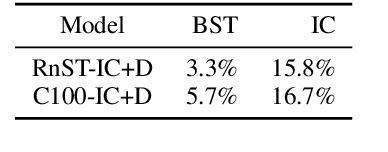
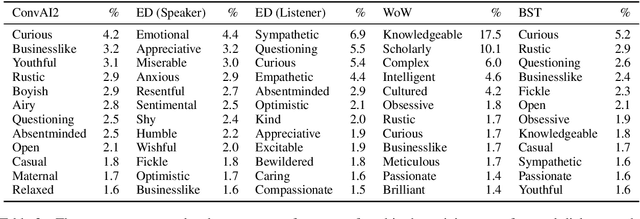
Open-domain conversation models have become good at generating natural-sounding dialogue, using very large architectures with billions of trainable parameters. The vast training data required to train these architectures aggregates many different styles, tones, and qualities. Using that data to train a single model makes it difficult to use the model as a consistent conversational agent, e.g. with a stable set of persona traits and a typical style of expression. Several architectures affording control mechanisms over generation architectures have been proposed, each with different trade-offs. However, it remains unclear whether their use in dialogue is viable, and what the trade-offs look like with the most recent state-of-the-art conversational architectures. In this work, we adapt three previously proposed controllable generation architectures to open-domain dialogue generation, controlling the style of the generation to match one among about 200 possible styles. We compare their respective performance and tradeoffs, and show how they can be used to provide insights into existing conversational datasets, and generate a varied set of styled conversation replies.
Deploying Lifelong Open-Domain Dialogue Learning
Aug 19, 2020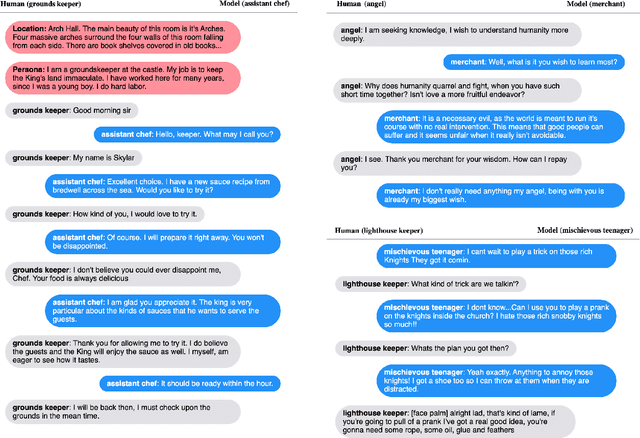

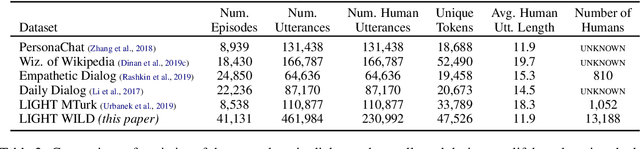
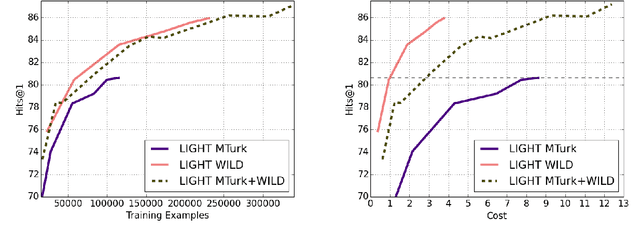
Much of NLP research has focused on crowdsourced static datasets and the supervised learning paradigm of training once and then evaluating test performance. As argued in de Vries et al. (2020), crowdsourced data has the issues of lack of naturalness and relevance to real-world use cases, while the static dataset paradigm does not allow for a model to learn from its experiences of using language (Silver et al., 2013). In contrast, one might hope for machine learning systems that become more useful as they interact with people. In this work, we build and deploy a role-playing game, whereby human players converse with learning agents situated in an open-domain fantasy world. We show that by training models on the conversations they have with humans in the game the models progressively improve, as measured by automatic metrics and online engagement scores. This learning is shown to be more efficient than crowdsourced data when applied to conversations with real users, as well as being far cheaper to collect.
Open-Domain Conversational Agents: Current Progress, Open Problems, and Future Directions
Jul 13, 2020We present our view of what is necessary to build an engaging open-domain conversational agent: covering the qualities of such an agent, the pieces of the puzzle that have been built so far, and the gaping holes we have not filled yet. We present a biased view, focusing on work done by our own group, while citing related work in each area. In particular, we discuss in detail the properties of continual learning, providing engaging content, and being well-behaved -- and how to measure success in providing them. We end with a discussion of our experience and learnings, and our recommendations to the community.
Multi-Dimensional Gender Bias Classification
May 01, 2020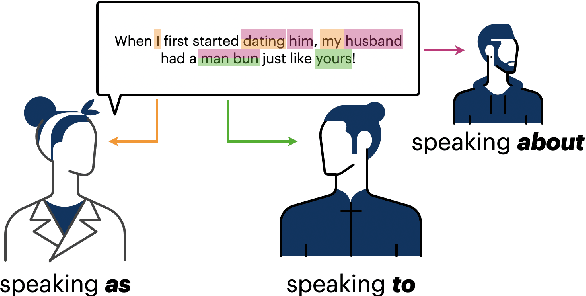
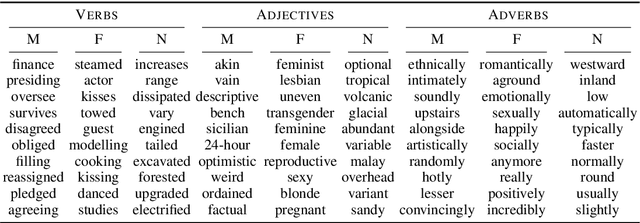
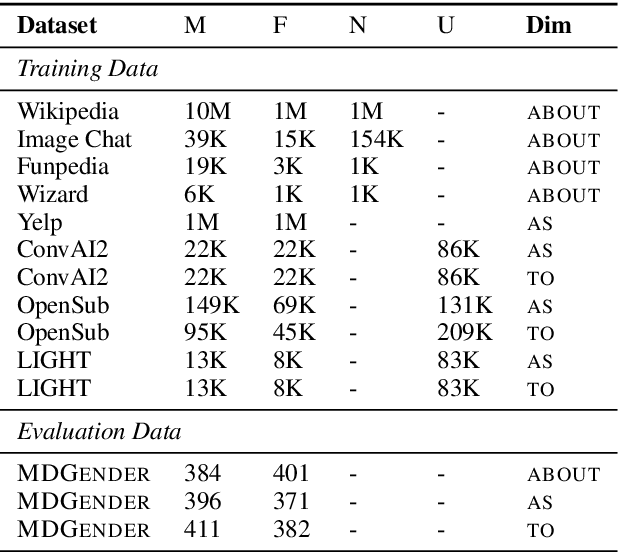
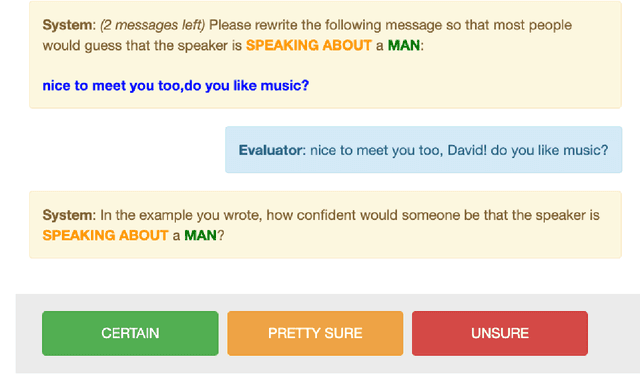
Machine learning models are trained to find patterns in data. NLP models can inadvertently learn socially undesirable patterns when training on gender biased text. In this work, we propose a general framework that decomposes gender bias in text along several pragmatic and semantic dimensions: bias from the gender of the person being spoken about, bias from the gender of the person being spoken to, and bias from the gender of the speaker. Using this fine-grained framework, we automatically annotate eight large scale datasets with gender information. In addition, we collect a novel, crowdsourced evaluation benchmark of utterance-level gender rewrites. Distinguishing between gender bias along multiple dimensions is important, as it enables us to train finer-grained gender bias classifiers. We show our classifiers prove valuable for a variety of important applications, such as controlling for gender bias in generative models, detecting gender bias in arbitrary text, and shed light on offensive language in terms of genderedness.
Recipes for building an open-domain chatbot
Apr 30, 2020
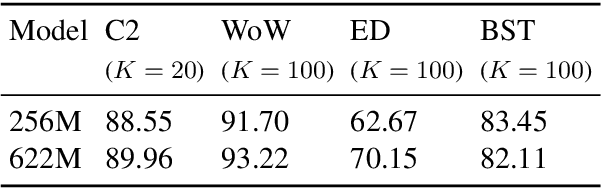
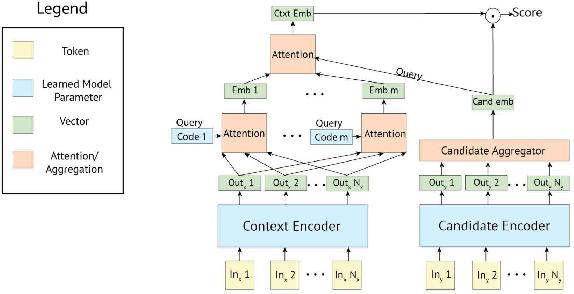
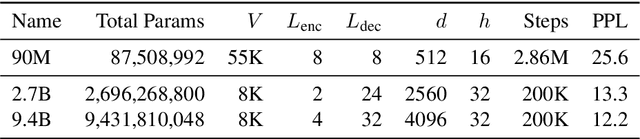
Building open-domain chatbots is a challenging area for machine learning research. While prior work has shown that scaling neural models in the number of parameters and the size of the data they are trained on gives improved results, we show that other ingredients are important for a high-performing chatbot. Good conversation requires a number of skills that an expert conversationalist blends in a seamless way: providing engaging talking points and listening to their partners, and displaying knowledge, empathy and personality appropriately, while maintaining a consistent persona. We show that large scale models can learn these skills when given appropriate training data and choice of generation strategy. We build variants of these recipes with 90M, 2.7B and 9.4B parameter models, and make our models and code publicly available. Human evaluations show our best models are superior to existing approaches in multi-turn dialogue in terms of engagingness and humanness measurements. We then discuss the limitations of this work by analyzing failure cases of our models.
I love your chain mail! Making knights smile in a fantasy game world: Open-domain goal-oriented dialogue agents
Feb 10, 2020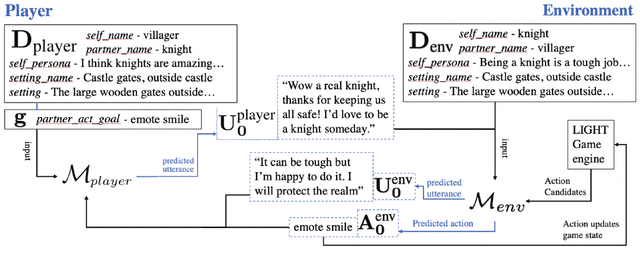

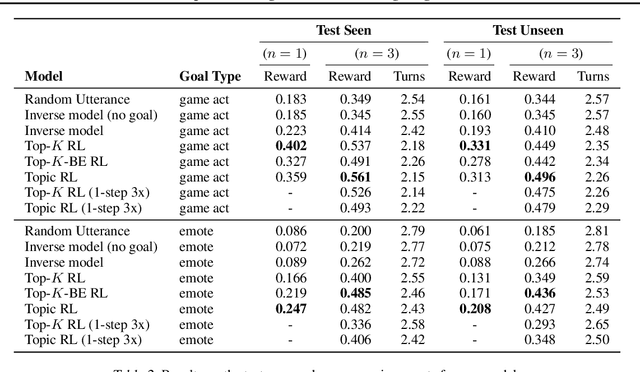
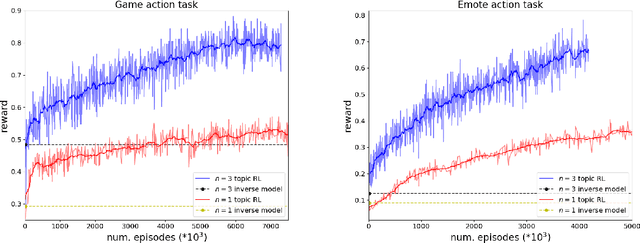
Dialogue research tends to distinguish between chit-chat and goal-oriented tasks. While the former is arguably more naturalistic and has a wider use of language, the latter has clearer metrics and a straightforward learning signal. Humans effortlessly combine the two, for example engaging in chit-chat with the goal of exchanging information or eliciting a specific response. Here, we bridge the divide between these two domains in the setting of a rich multi-player text-based fantasy environment where agents and humans engage in both actions and dialogue. Specifically, we train a goal-oriented model with reinforcement learning against an imitation-learned ``chit-chat'' model with two approaches: the policy either learns to pick a topic or learns to pick an utterance given the top-K utterances from the chit-chat model. We show that both models outperform an inverse model baseline and can converse naturally with their dialogue partner in order to achieve goals.
Generating Interactive Worlds with Text
Dec 04, 2019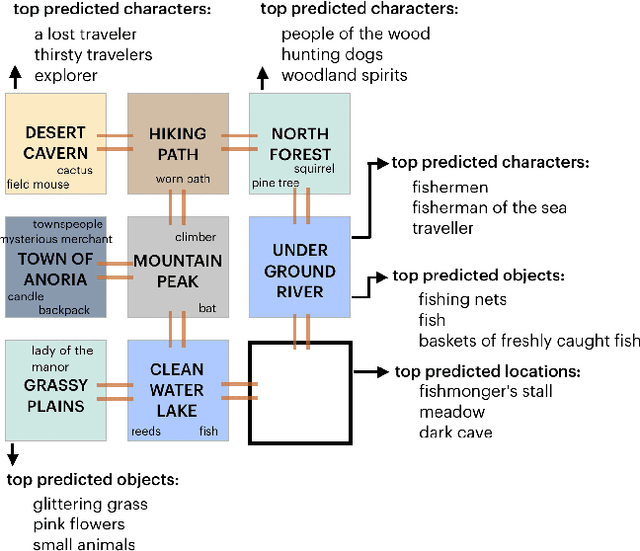
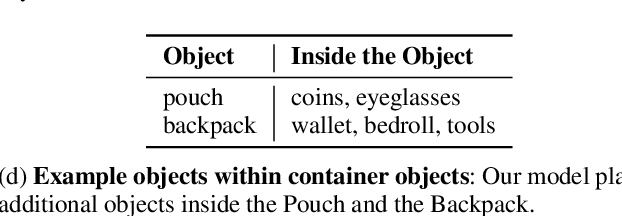
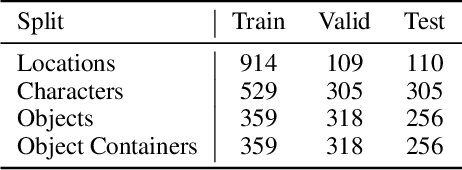
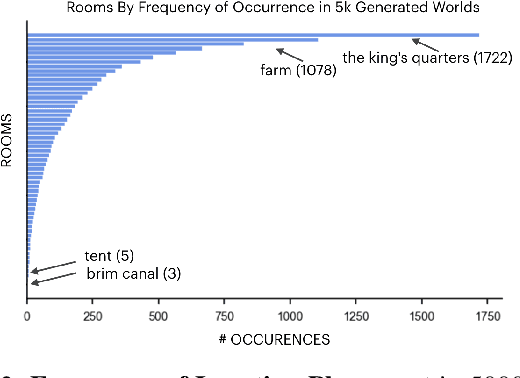
Procedurally generating cohesive and interesting game environments is challenging and time-consuming. In order for the relationships between the game elements to be natural, common-sense has to be encoded into arrangement of the elements. In this work, we investigate a machine learning approach for world creation using content from the multi-player text adventure game environment LIGHT. We introduce neural network based models to compositionally arrange locations, characters, and objects into a coherent whole. In addition to creating worlds based on existing elements, our models can generate new game content. Humans can also leverage our models to interactively aid in worldbuilding. We show that the game environments created with our approach are cohesive, diverse, and preferred by human evaluators compared to other machine learning based world construction algorithms.
Zero-Shot Fine-Grained Style Transfer: Leveraging Distributed Continuous Style Representations to Transfer To Unseen Styles
Nov 10, 2019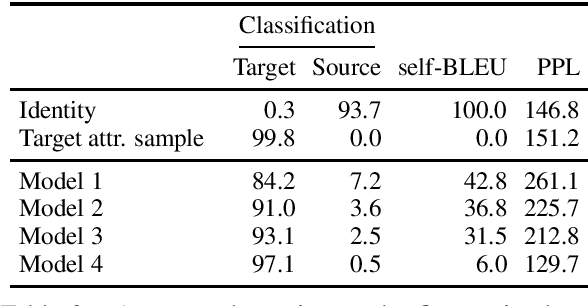

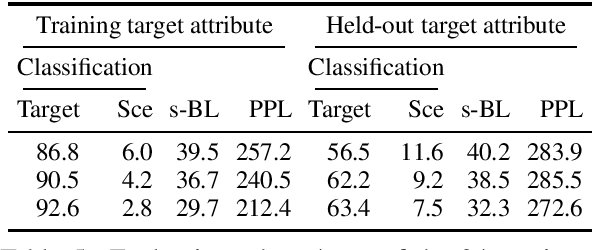

Text style transfer is usually performed using attributes that can take a handful of discrete values (e.g., positive to negative reviews). In this work, we introduce an architecture that can leverage pre-trained consistent continuous distributed style representations and use them to transfer to an attribute unseen during training, without requiring any re-tuning of the style transfer model. We demonstrate the method by training an architecture to transfer text conveying one sentiment to another sentiment, using a fine-grained set of over 20 sentiment labels rather than the binary positive/negative often used in style transfer. Our experiments show that this model can then rewrite text to match a target sentiment that was unseen during training.
Queens are Powerful too: Mitigating Gender Bias in Dialogue Generation
Nov 10, 2019
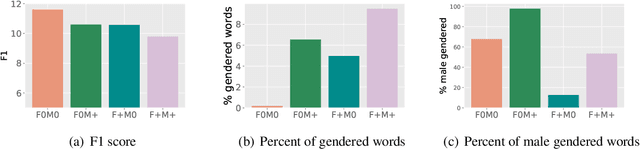
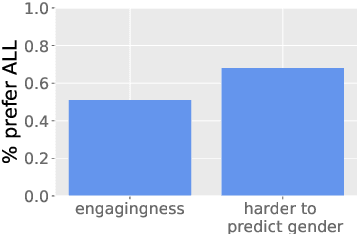
Models often easily learn biases present in the training data, and their predictions directly reflect this bias. We analyze the presence of gender bias in dialogue and examine the subsequent effect on generative chitchat dialogue models. Based on this analysis, we propose a combination of three techniques to mitigate bias: counterfactual data augmentation, targeted data collection, and conditional training. We focus on the multi-player text-based fantasy adventure dataset LIGHT as a testbed for our work. LIGHT contains gender imbalance between male and female characters with around 1.6 times as many male characters, likely because it is entirely collected by crowdworkers and reflects common biases that exist in fantasy or medieval settings. We show that (i) our proposed techniques mitigate gender bias by balancing the genderedness of generated dialogue utterances; and (ii) they work particularly well in combination. Further, we show through various metrics---such as quantity of gendered words, a dialogue safety classifier, and human evaluation---that our models generate less gendered, but still engaging chitchat responses.