 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeControlling Style in Generated Dialogue
Paper and Code
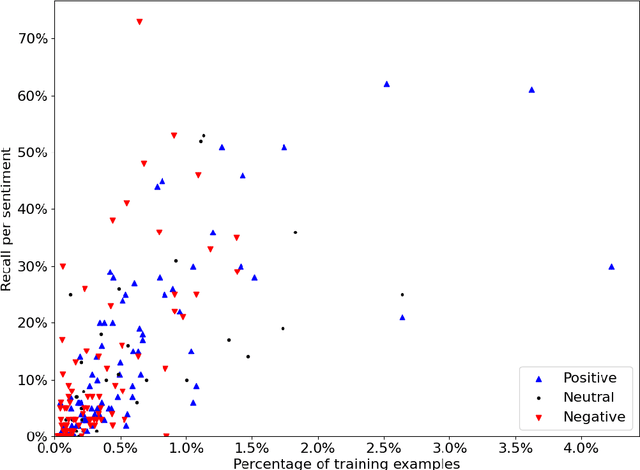
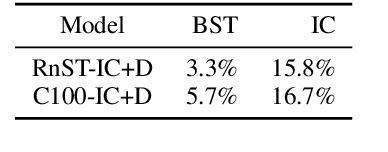
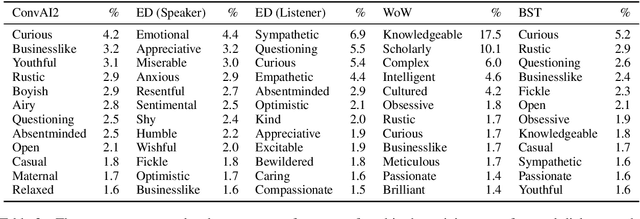
Open-domain conversation models have become good at generating natural-sounding dialogue, using very large architectures with billions of trainable parameters. The vast training data required to train these architectures aggregates many different styles, tones, and qualities. Using that data to train a single model makes it difficult to use the model as a consistent conversational agent, e.g. with a stable set of persona traits and a typical style of expression. Several architectures affording control mechanisms over generation architectures have been proposed, each with different trade-offs. However, it remains unclear whether their use in dialogue is viable, and what the trade-offs look like with the most recent state-of-the-art conversational architectures. In this work, we adapt three previously proposed controllable generation architectures to open-domain dialogue generation, controlling the style of the generation to match one among about 200 possible styles. We compare their respective performance and tradeoffs, and show how they can be used to provide insights into existing conversational datasets, and generate a varied set of styled conversation replies.