 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnsupervised Domain Adaptation for Video Transformers in Action Recognition
Jul 26, 2022
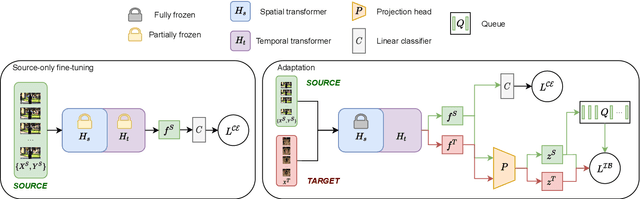
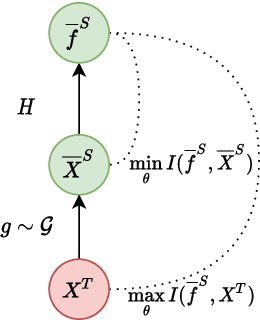
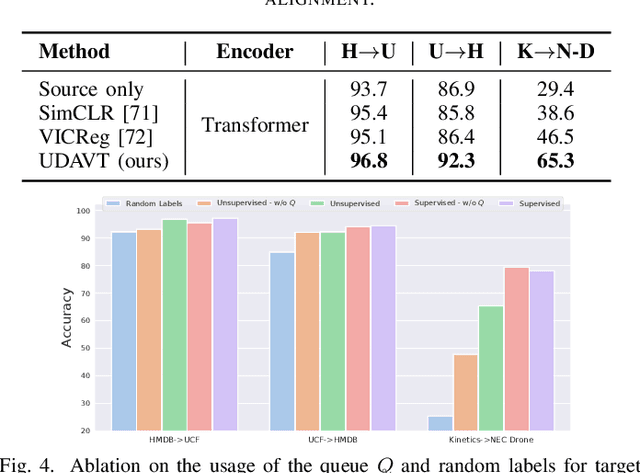
Over the last few years, Unsupervised Domain Adaptation (UDA) techniques have acquired remarkable importance and popularity in computer vision. However, when compared to the extensive literature available for images, the field of videos is still relatively unexplored. On the other hand, the performance of a model in action recognition is heavily affected by domain shift. In this paper, we propose a simple and novel UDA approach for video action recognition. Our approach leverages recent advances on spatio-temporal transformers to build a robust source model that better generalises to the target domain. Furthermore, our architecture learns domain invariant features thanks to the introduction of a novel alignment loss term derived from the Information Bottleneck principle. We report results on two video action recognition benchmarks for UDA, showing state-of-the-art performance on HMDB$\leftrightarrow$UCF, as well as on Kinetics$\rightarrow$NEC-Drone, which is more challenging. This demonstrates the effectiveness of our method in handling different levels of domain shift. The source code is available at https://github.com/vturrisi/UDAVT.
Multimodal Emotion Recognition with Modality-Pairwise Unsupervised Contrastive Loss
Jul 23, 2022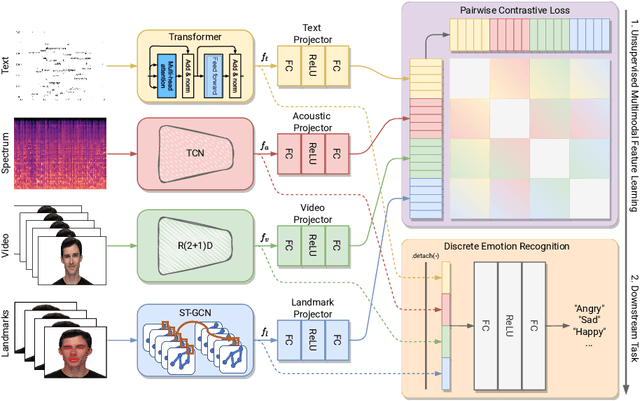
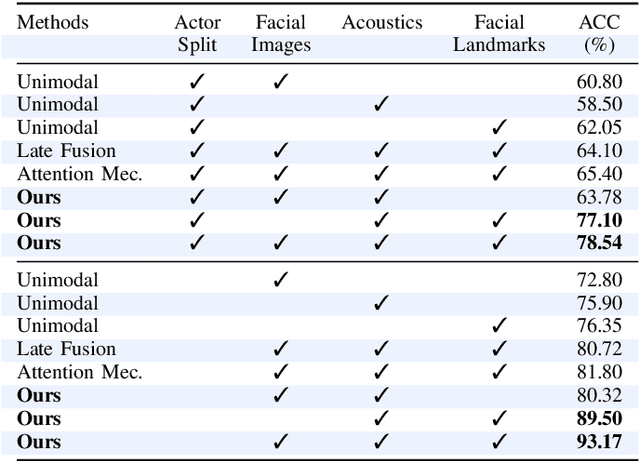

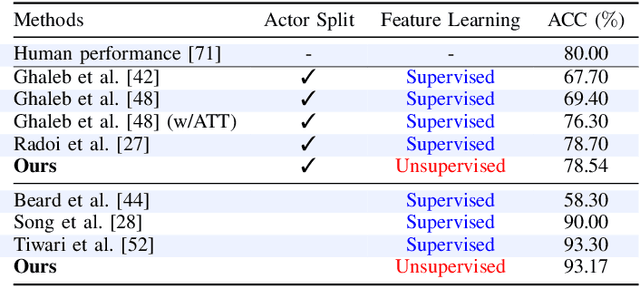
Emotion recognition is involved in several real-world applications. With an increase in available modalities, automatic understanding of emotions is being performed more accurately. The success in Multimodal Emotion Recognition (MER), primarily relies on the supervised learning paradigm. However, data annotation is expensive, time-consuming, and as emotion expression and perception depends on several factors (e.g., age, gender, culture) obtaining labels with a high reliability is hard. Motivated by these, we focus on unsupervised feature learning for MER. We consider discrete emotions, and as modalities text, audio and vision are used. Our method, as being based on contrastive loss between pairwise modalities, is the first attempt in MER literature. Our end-to-end feature learning approach has several differences (and advantages) compared to existing MER methods: i) it is unsupervised, so the learning is lack of data labelling cost; ii) it does not require data spatial augmentation, modality alignment, large number of batch size or epochs; iii) it applies data fusion only at inference; and iv) it does not require backbones pre-trained on emotion recognition task. The experiments on benchmark datasets show that our method outperforms several baseline approaches and unsupervised learning methods applied in MER. Particularly, it even surpasses a few supervised MER state-of-the-art.
CoSMix: Compositional Semantic Mix for Domain Adaptation in 3D LiDAR Segmentation
Jul 20, 20223D LiDAR semantic segmentation is fundamental for autonomous driving. Several Unsupervised Domain Adaptation (UDA) methods for point cloud data have been recently proposed to improve model generalization for different sensors and environments. Researchers working on UDA problems in the image domain have shown that sample mixing can mitigate domain shift. We propose a new approach of sample mixing for point cloud UDA, namely Compositional Semantic Mix (CoSMix), the first UDA approach for point cloud segmentation based on sample mixing. CoSMix consists of a two-branch symmetric network that can process labelled synthetic data (source) and real-world unlabelled point clouds (target) concurrently. Each branch operates on one domain by mixing selected pieces of data from the other one, and by using the semantic information derived from source labels and target pseudo-labels. We evaluate CoSMix on two large-scale datasets, showing that it outperforms state-of-the-art methods by a large margin. Our code is available at https://github.com/saltoricristiano/cosmix-uda.
GIPSO: Geometrically Informed Propagation for Online Adaptation in 3D LiDAR Segmentation
Jul 20, 2022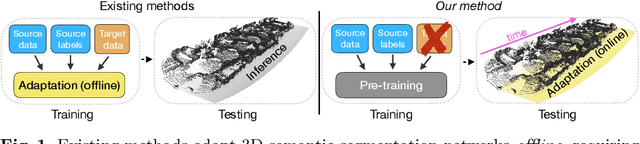
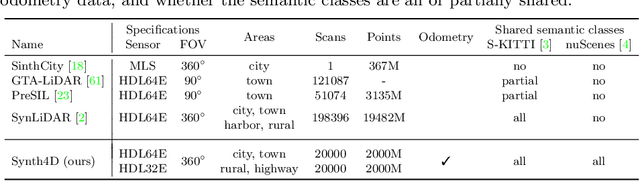
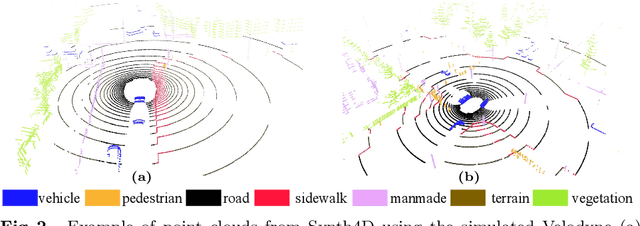
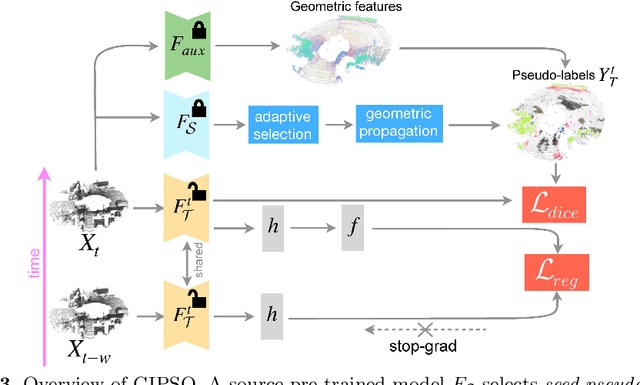
3D point cloud semantic segmentation is fundamental for autonomous driving. Most approaches in the literature neglect an important aspect, i.e., how to deal with domain shift when handling dynamic scenes. This can significantly hinder the navigation capabilities of self-driving vehicles. This paper advances the state of the art in this research field. Our first contribution consists in analysing a new unexplored scenario in point cloud segmentation, namely Source-Free Online Unsupervised Domain Adaptation (SF-OUDA). We experimentally show that state-of-the-art methods have a rather limited ability to adapt pre-trained deep network models to unseen domains in an online manner. Our second contribution is an approach that relies on adaptive self-training and geometric-feature propagation to adapt a pre-trained source model online without requiring either source data or target labels. Our third contribution is to study SF-OUDA in a challenging setup where source data is synthetic and target data is point clouds captured in the real world. We use the recent SynLiDAR dataset as a synthetic source and introduce two new synthetic (source) datasets, which can stimulate future synthetic-to-real autonomous driving research. Our experiments show the effectiveness of our segmentation approach on thousands of real-world point clouds. Code and synthetic datasets are available at https://github.com/saltoricristiano/gipso-sfouda.
Class-incremental Novel Class Discovery
Jul 18, 2022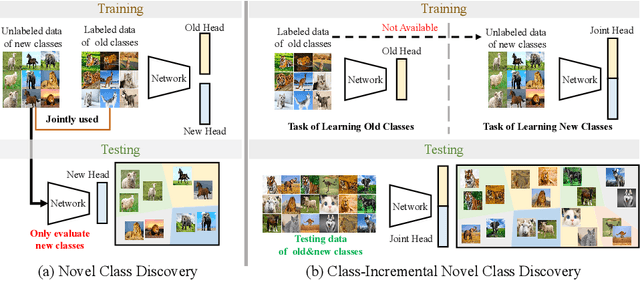
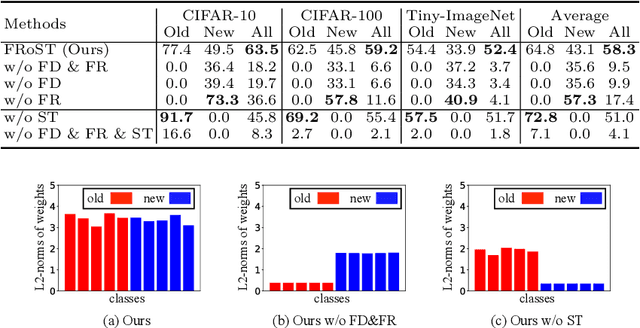
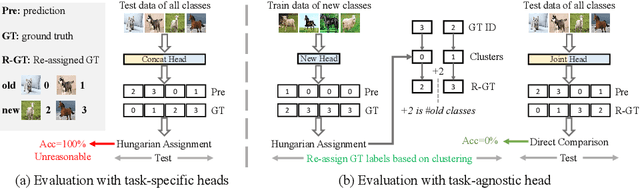

We study the new task of class-incremental Novel Class Discovery (class-iNCD), which refers to the problem of discovering novel categories in an unlabelled data set by leveraging a pre-trained model that has been trained on a labelled data set containing disjoint yet related categories. Apart from discovering novel classes, we also aim at preserving the ability of the model to recognize previously seen base categories. Inspired by rehearsal-based incremental learning methods, in this paper we propose a novel approach for class-iNCD which prevents forgetting of past information about the base classes by jointly exploiting base class feature prototypes and feature-level knowledge distillation. We also propose a self-training clustering strategy that simultaneously clusters novel categories and trains a joint classifier for both the base and novel classes. This makes our method able to operate in a class-incremental setting. Our experiments, conducted on three common benchmarks, demonstrate that our method significantly outperforms state-of-the-art approaches. Code is available at https://github.com/OatmealLiu/class-iNCD
Uncertainty-aware Contrastive Distillation for Incremental Semantic Segmentation
Mar 26, 2022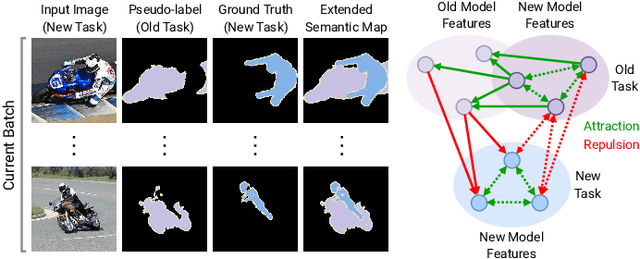
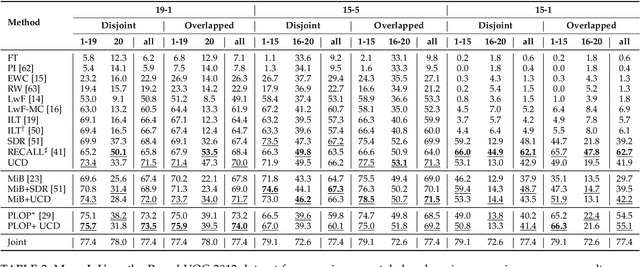
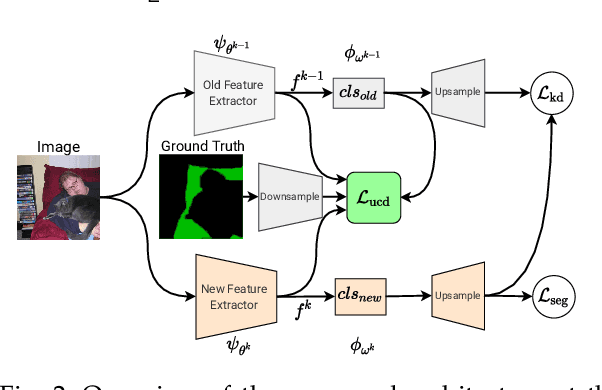
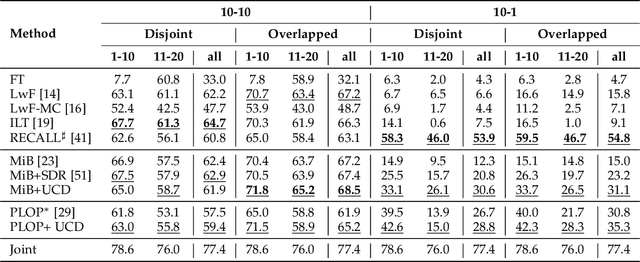
A fundamental and challenging problem in deep learning is catastrophic forgetting, i.e. the tendency of neural networks to fail to preserve the knowledge acquired from old tasks when learning new tasks. This problem has been widely investigated in the research community and several Incremental Learning (IL) approaches have been proposed in the past years. While earlier works in computer vision have mostly focused on image classification and object detection, more recently some IL approaches for semantic segmentation have been introduced. These previous works showed that, despite its simplicity, knowledge distillation can be effectively employed to alleviate catastrophic forgetting. In this paper, we follow this research direction and, inspired by recent literature on contrastive learning, we propose a novel distillation framework, Uncertainty-aware Contrastive Distillation (\method). In a nutshell, \method~is operated by introducing a novel distillation loss that takes into account all the images in a mini-batch, enforcing similarity between features associated to all the pixels from the same classes, and pulling apart those corresponding to pixels from different classes. In order to mitigate catastrophic forgetting, we contrast features of the new model with features extracted by a frozen model learned at the previous incremental step. Our experimental results demonstrate the advantage of the proposed distillation technique, which can be used in synergy with previous IL approaches, and leads to state-of-art performance on three commonly adopted benchmarks for incremental semantic segmentation. The code is available at \url{https://github.com/ygjwd12345/UCD}.
Quantum Motion Segmentation
Mar 24, 2022
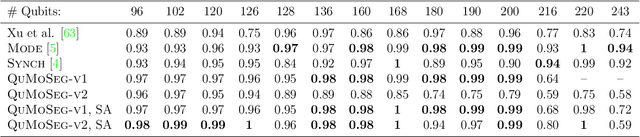


Motion segmentation is a challenging problem that seeks to identify independent motions in two or several input images. This paper introduces the first algorithm for motion segmentation that relies on adiabatic quantum optimization of the objective function. The proposed method achieves on-par performance with the state of the art on problem instances which can be mapped to modern quantum annealers.
Playable Environments: Video Manipulation in Space and Time
Mar 15, 2022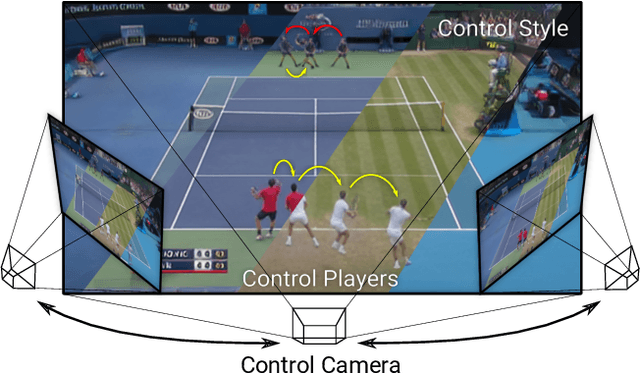

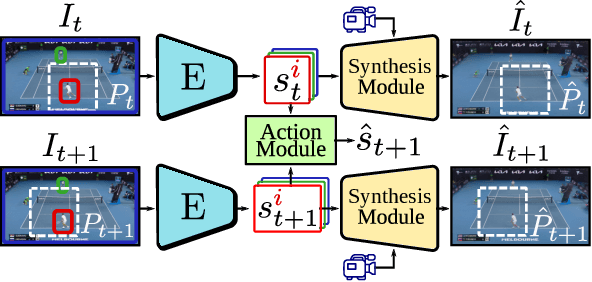
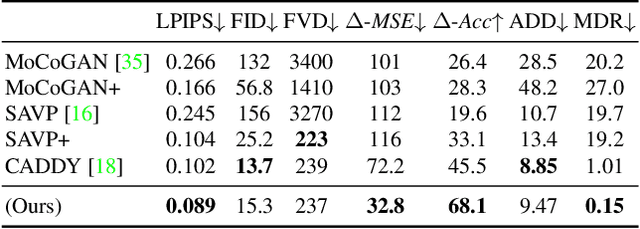
We present Playable Environments - a new representation for interactive video generation and manipulation in space and time. With a single image at inference time, our novel framework allows the user to move objects in 3D while generating a video by providing a sequence of desired actions. The actions are learnt in an unsupervised manner. The camera can be controlled to get the desired viewpoint. Our method builds an environment state for each frame, which can be manipulated by our proposed action module and decoded back to the image space with volumetric rendering. To support diverse appearances of objects, we extend neural radiance fields with style-based modulation. Our method trains on a collection of various monocular videos requiring only the estimated camera parameters and 2D object locations. To set a challenging benchmark, we introduce two large scale video datasets with significant camera movements. As evidenced by our experiments, playable environments enable several creative applications not attainable by prior video synthesis works, including playable 3D video generation, stylization and manipulation. Further details, code and examples are available at https://willi-menapace.github.io/playable-environments-website
3D Object Detection from Images for Autonomous Driving: A Survey
Feb 12, 2022



3D object detection from images, one of the fundamental and challenging problems in autonomous driving, has received increasing attention from both industry and academia in recent years. Benefiting from the rapid development of deep learning technologies, image-based 3D detection has achieved remarkable progress. Particularly, more than 200 works have studied this problem from 2015 to 2021, encompassing a broad spectrum of theories, algorithms, and applications. However, to date no recent survey exists to collect and organize this knowledge. In this paper, we fill this gap in the literature and provide the first comprehensive survey of this novel and continuously growing research field, summarizing the most commonly used pipelines for image-based 3D detection and deeply analyzing each of their components. Additionally, we also propose two new taxonomies to organize the state-of-the-art methods into different categories, with the intent of providing a more systematic review of existing methods and facilitating fair comparisons with future works. In retrospect of what has been achieved so far, we also analyze the current challenges in the field and discuss future directions for image-based 3D detection research.
Continual Attentive Fusion for Incremental Learning in Semantic Segmentation
Feb 01, 2022


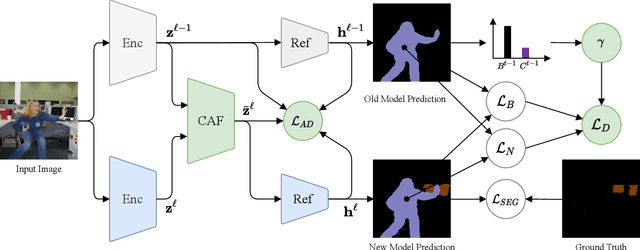
Over the past years, semantic segmentation, as many other tasks in computer vision, benefited from the progress in deep neural networks, resulting in significantly improved performance. However, deep architectures trained with gradient-based techniques suffer from catastrophic forgetting, which is the tendency to forget previously learned knowledge while learning new tasks. Aiming at devising strategies to counteract this effect, incremental learning approaches have gained popularity over the past years. However, the first incremental learning methods for semantic segmentation appeared only recently. While effective, these approaches do not account for a crucial aspect in pixel-level dense prediction problems, i.e. the role of attention mechanisms. To fill this gap, in this paper we introduce a novel attentive feature distillation approach to mitigate catastrophic forgetting while accounting for semantic spatial- and channel-level dependencies. Furthermore, we propose a {continual attentive fusion} structure, which takes advantage of the attention learned from the new and the old tasks while learning features for the new task. Finally, we also introduce a novel strategy to account for the background class in the distillation loss, thus preventing biased predictions. We demonstrate the effectiveness of our approach with an extensive evaluation on Pascal-VOC 2012 and ADE20K, setting a new state of the art.