 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Dataset of Peer Reviews : Collection, Insights and NLP Applications
Apr 25, 2018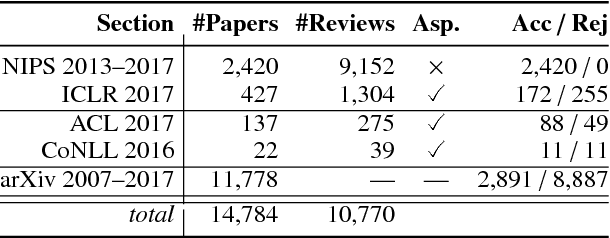
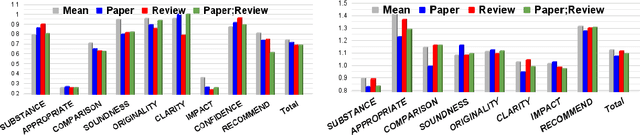
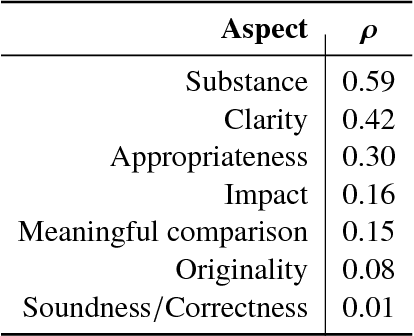
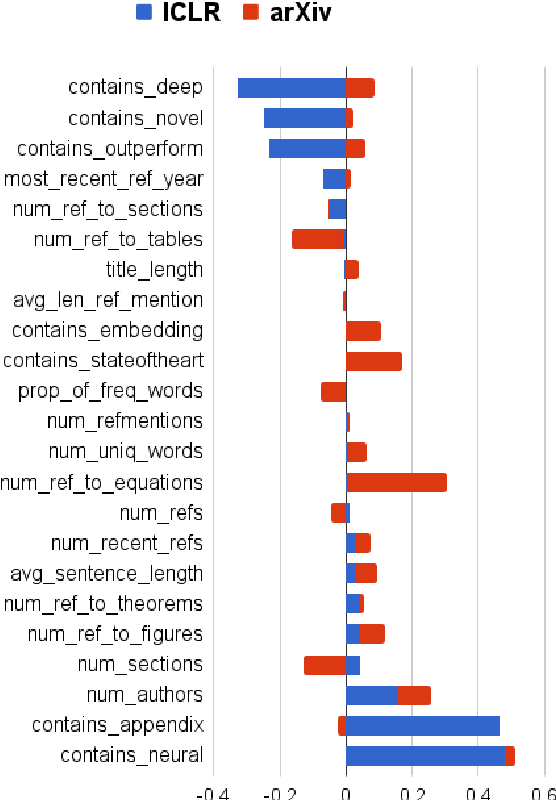
Peer reviewing is a central component in the scientific publishing process. We present the first public dataset of scientific peer reviews available for research purposes (PeerRead v1) providing an opportunity to study this important artifact. The dataset consists of 14.7K paper drafts and the corresponding accept/reject decisions in top-tier venues including ACL, NIPS and ICLR. The dataset also includes 10.7K textual peer reviews written by experts for a subset of the papers. We describe the data collection process and report interesting observed phenomena in the peer reviews. We also propose two novel NLP tasks based on this dataset and provide simple baseline models. In the first task, we show that simple models can predict whether a paper is accepted with up to 21% error reduction compared to the majority baseline. In the second task, we predict the numerical scores of review aspects and show that simple models can outperform the mean baseline for aspects with high variance such as 'originality' and 'impact'.
Controllable Invariance through Adversarial Feature Learning
Jan 29, 2018

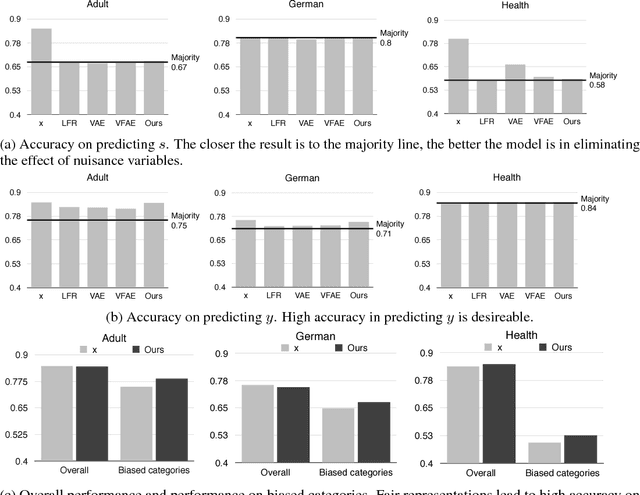

Learning meaningful representations that maintain the content necessary for a particular task while filtering away detrimental variations is a problem of great interest in machine learning. In this paper, we tackle the problem of learning representations invariant to a specific factor or trait of data. The representation learning process is formulated as an adversarial minimax game. We analyze the optimal equilibrium of such a game and find that it amounts to maximizing the uncertainty of inferring the detrimental factor given the representation while maximizing the certainty of making task-specific predictions. On three benchmark tasks, namely fair and bias-free classification, language-independent generation, and lighting-independent image classification, we show that the proposed framework induces an invariant representation, and leads to better generalization evidenced by the improved performance.
SPINE: SParse Interpretable Neural Embeddings
Nov 23, 2017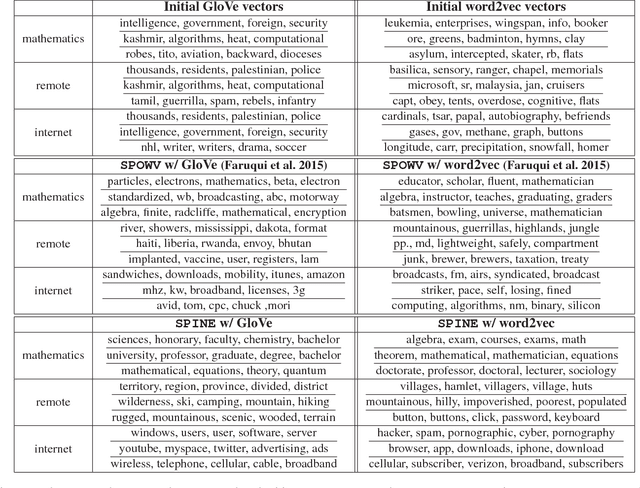
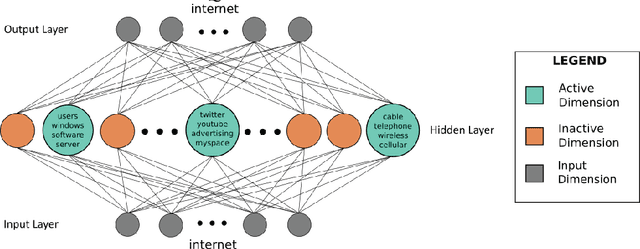


Prediction without justification has limited utility. Much of the success of neural models can be attributed to their ability to learn rich, dense and expressive representations. While these representations capture the underlying complexity and latent trends in the data, they are far from being interpretable. We propose a novel variant of denoising k-sparse autoencoders that generates highly efficient and interpretable distributed word representations (word embeddings), beginning with existing word representations from state-of-the-art methods like GloVe and word2vec. Through large scale human evaluation, we report that our resulting word embedddings are much more interpretable than the original GloVe and word2vec embeddings. Moreover, our embeddings outperform existing popular word embeddings on a diverse suite of benchmark downstream tasks.
Softmax Q-Distribution Estimation for Structured Prediction: A Theoretical Interpretation for RAML
Oct 27, 2017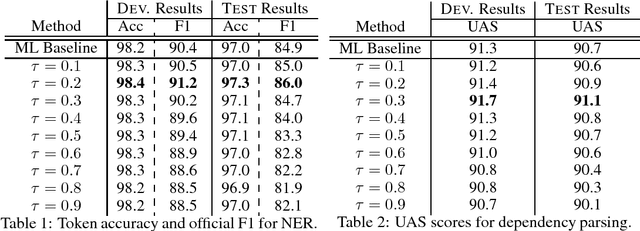
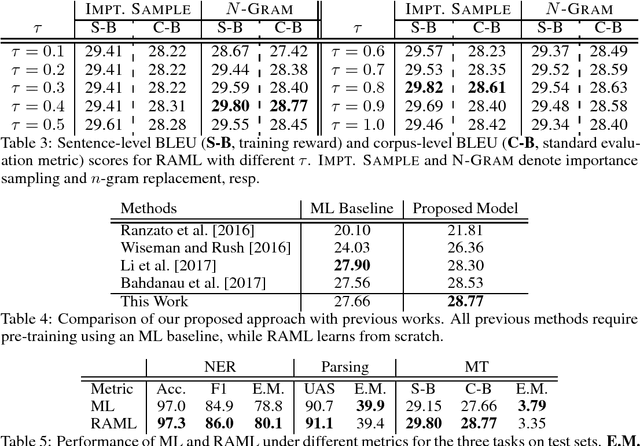
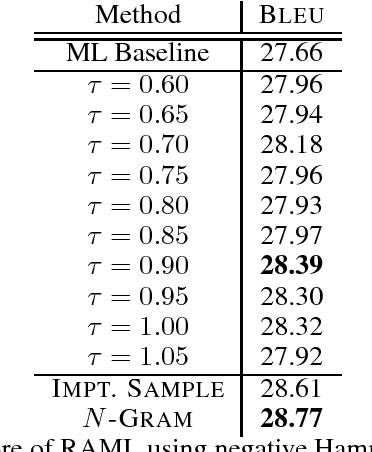
Reward augmented maximum likelihood (RAML), a simple and effective learning framework to directly optimize towards the reward function in structured prediction tasks, has led to a number of impressive empirical successes. RAML incorporates task-specific reward by performing maximum-likelihood updates on candidate outputs sampled according to an exponentiated payoff distribution, which gives higher probabilities to candidates that are close to the reference output. While RAML is notable for its simplicity, efficiency, and its impressive empirical successes, the theoretical properties of RAML, especially the behavior of the exponentiated payoff distribution, has not been examined thoroughly. In this work, we introduce softmax Q-distribution estimation, a novel theoretical interpretation of RAML, which reveals the relation between RAML and Bayesian decision theory. The softmax Q-distribution can be regarded as a smooth approximation of the Bayes decision boundary, and the Bayes decision rule is achieved by decoding with this Q-distribution. We further show that RAML is equivalent to approximately estimating the softmax Q-distribution, with the temperature $\tau$ controlling approximation error. We perform two experiments, one on synthetic data of multi-class classification and one on real data of image captioning, to demonstrate the relationship between RAML and the proposed softmax Q-distribution estimation method, verifying our theoretical analysis. Additional experiments on three structured prediction tasks with rewards defined on sequential (named entity recognition), tree-based (dependency parsing) and irregular (machine translation) structures show notable improvements over maximum likelihood baselines.
Neural Probabilistic Model for Non-projective MST Parsing
Sep 03, 2017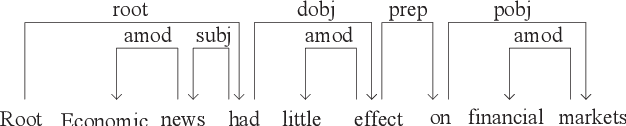
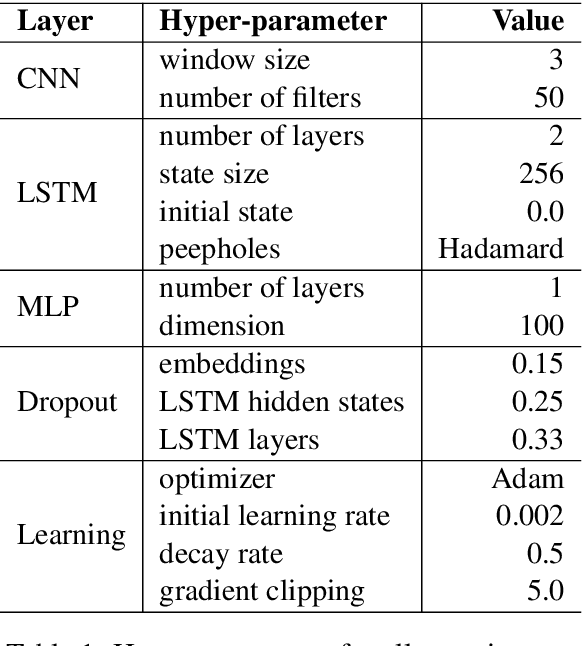
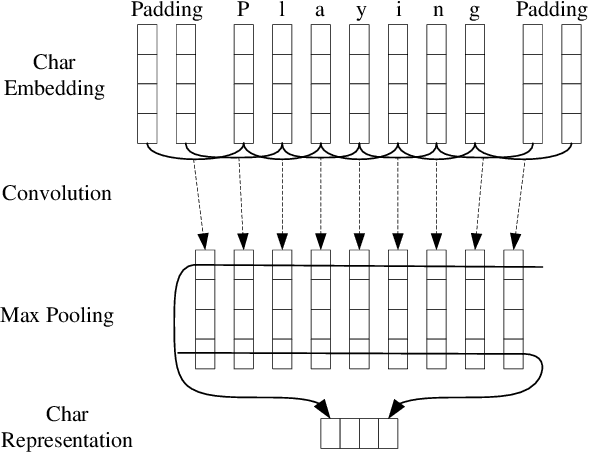

In this paper, we propose a probabilistic parsing model, which defines a proper conditional probability distribution over non-projective dependency trees for a given sentence, using neural representations as inputs. The neural network architecture is based on bi-directional LSTM-CNNs which benefits from both word- and character-level representations automatically, by using combination of bidirectional LSTM and CNN. On top of the neural network, we introduce a probabilistic structured layer, defining a conditional log-linear model over non-projective trees. We evaluate our model on 17 different datasets, across 14 different languages. By exploiting Kirchhoff's Matrix-Tree Theorem (Tutte, 1984), the partition functions and marginals can be computed efficiently, leading to a straight-forward end-to-end model training procedure via back-propagation. Our parser achieves state-of-the-art parsing performance on nine datasets.
Detecting and Explaining Causes From Text For a Time Series Event
Jul 27, 2017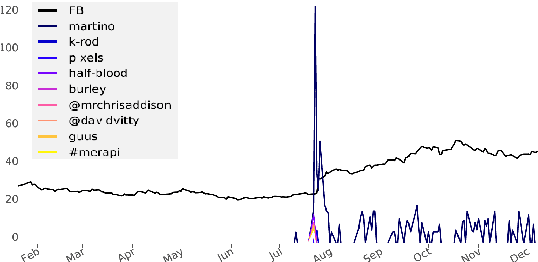
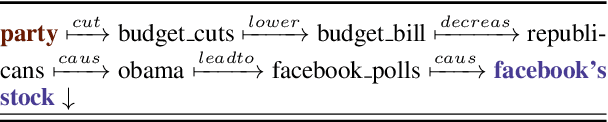
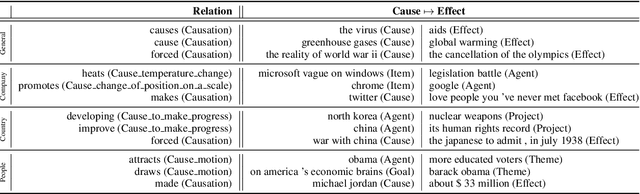
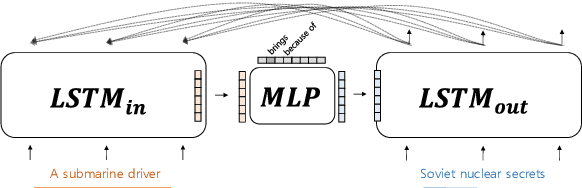
Explaining underlying causes or effects about events is a challenging but valuable task. We define a novel problem of generating explanations of a time series event by (1) searching cause and effect relationships of the time series with textual data and (2) constructing a connecting chain between them to generate an explanation. To detect causal features from text, we propose a novel method based on the Granger causality of time series between features extracted from text such as N-grams, topics, sentiments, and their composition. The generation of the sequence of causal entities requires a commonsense causative knowledge base with efficient reasoning. To ensure good interpretability and appropriate lexical usage we combine symbolic and neural representations, using a neural reasoning algorithm trained on commonsense causal tuples to predict the next cause step. Our quantitative and human analysis show empirical evidence that our method successfully extracts meaningful causality relationships between time series with textual features and generates appropriate explanation between them.
CharManteau: Character Embedding Models For Portmanteau Creation
Jul 24, 2017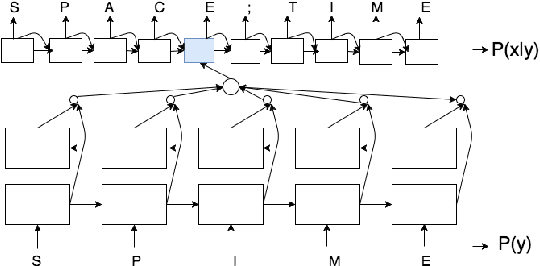
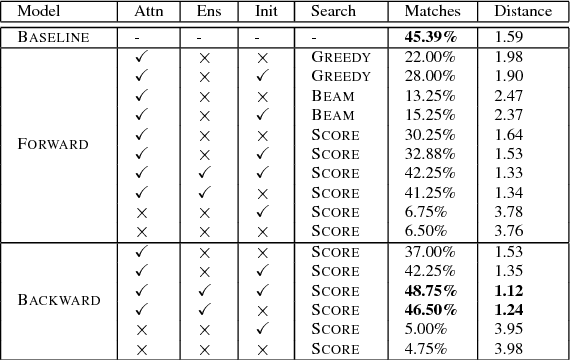

Portmanteaus are a word formation phenomenon where two words are combined to form a new word. We propose character-level neural sequence-to-sequence (S2S) methods for the task of portmanteau generation that are end-to-end-trainable, language independent, and do not explicitly use additional phonetic information. We propose a noisy-channel-style model, which allows for the incorporation of unsupervised word lists, improving performance over a standard source-to-target model. This model is made possible by an exhaustive candidate generation strategy specifically enabled by the features of the portmanteau task. Experiments find our approach superior to a state-of-the-art FST-based baseline with respect to ground truth accuracy and human evaluation.
Shakespearizing Modern Language Using Copy-Enriched Sequence-to-Sequence Models
Jul 20, 2017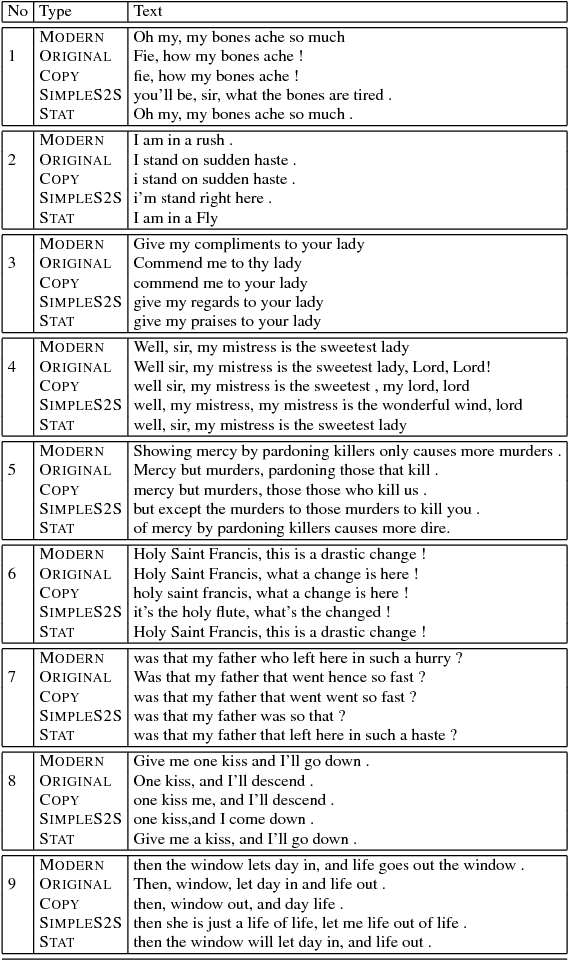
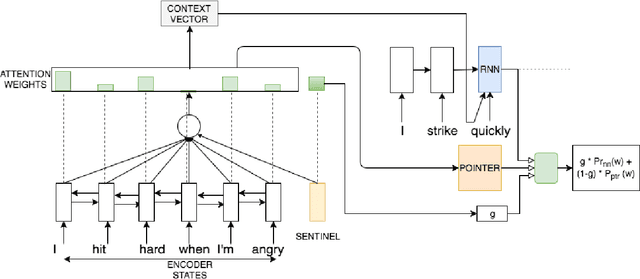
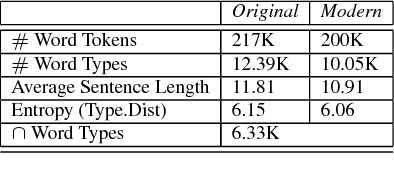
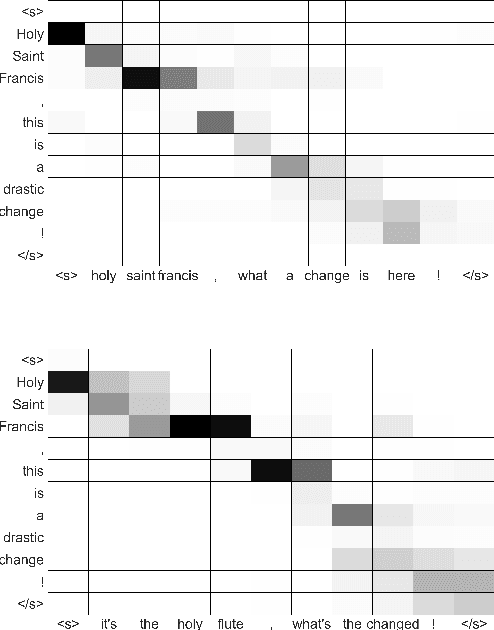
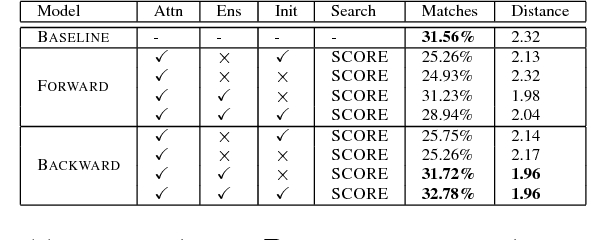
Variations in writing styles are commonly used to adapt the content to a specific context, audience, or purpose. However, applying stylistic variations is still by and large a manual process, and there have been little efforts towards automating it. In this paper we explore automated methods to transform text from modern English to Shakespearean English using an end to end trainable neural model with pointers to enable copy action. To tackle limited amount of parallel data, we pre-train embeddings of words by leveraging external dictionaries mapping Shakespearean words to modern English words as well as additional text. Our methods are able to get a BLEU score of 31+, an improvement of ~6 points above the strongest baseline. We publicly release our code to foster further research in this area.
Ontology-Aware Token Embeddings for Prepositional Phrase Attachment
May 08, 2017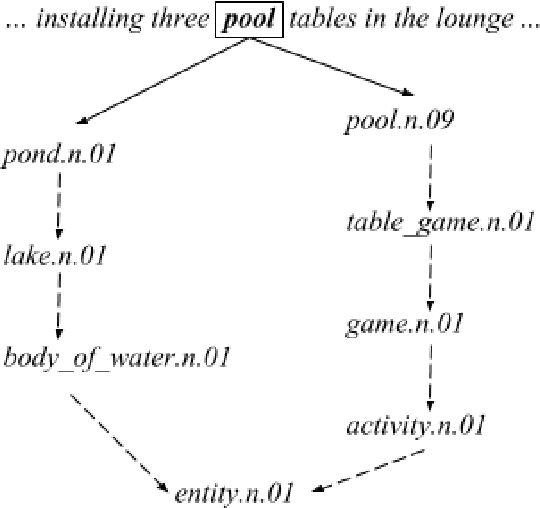

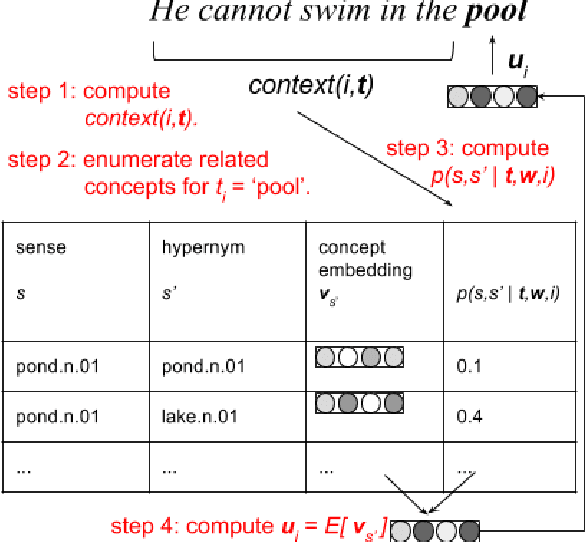
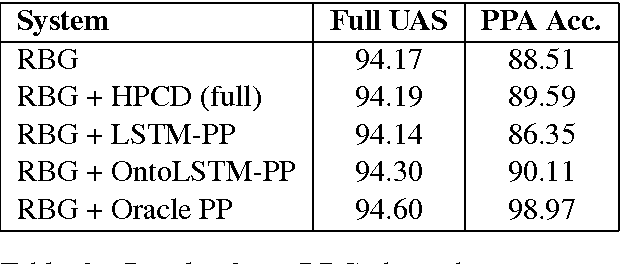
Type-level word embeddings use the same set of parameters to represent all instances of a word regardless of its context, ignoring the inherent lexical ambiguity in language. Instead, we embed semantic concepts (or synsets) as defined in WordNet and represent a word token in a particular context by estimating a distribution over relevant semantic concepts. We use the new, context-sensitive embeddings in a model for predicting prepositional phrase(PP) attachments and jointly learn the concept embeddings and model parameters. We show that using context-sensitive embeddings improves the accuracy of the PP attachment model by 5.4% absolute points, which amounts to a 34.4% relative reduction in errors.
An Interpretable Knowledge Transfer Model for Knowledge Base Completion
May 03, 2017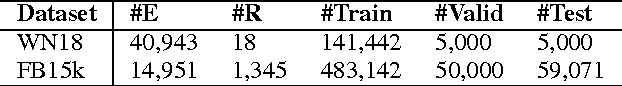
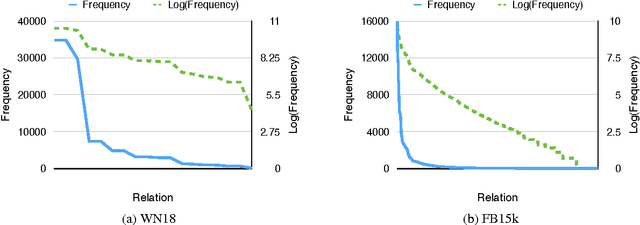
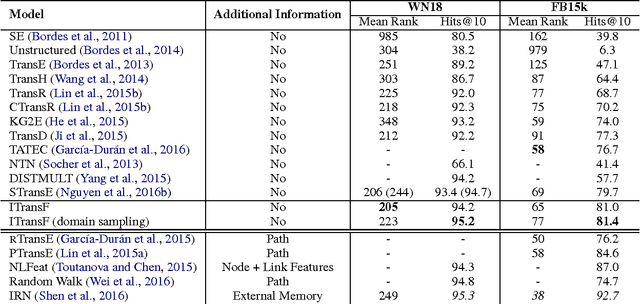
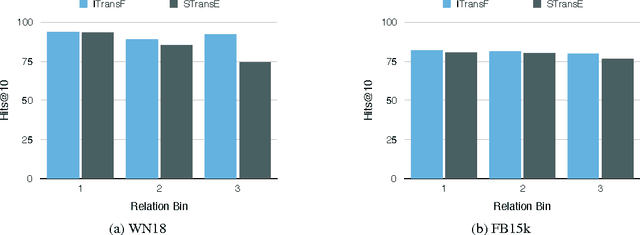
Knowledge bases are important resources for a variety of natural language processing tasks but suffer from incompleteness. We propose a novel embedding model, \emph{ITransF}, to perform knowledge base completion. Equipped with a sparse attention mechanism, ITransF discovers hidden concepts of relations and transfer statistical strength through the sharing of concepts. Moreover, the learned associations between relations and concepts, which are represented by sparse attention vectors, can be interpreted easily. We evaluate ITransF on two benchmark datasets---WN18 and FB15k for knowledge base completion and obtains improvements on both the mean rank and Hits@10 metrics, over all baselines that do not use additional information.