 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIn-Context Learning for Text Classification with Many Labels
Sep 19, 2023



In-context learning (ICL) using large language models for tasks with many labels is challenging due to the limited context window, which makes it difficult to fit a sufficient number of examples in the prompt. In this paper, we use a pre-trained dense retrieval model to bypass this limitation, giving the model only a partial view of the full label space for each inference call. Testing with recent open-source LLMs (OPT, LLaMA), we set new state of the art performance in few-shot settings for three common intent classification datasets, with no finetuning. We also surpass fine-tuned performance on fine-grained sentiment classification in certain cases. We analyze the performance across number of in-context examples and different model scales, showing that larger models are necessary to effectively and consistently make use of larger context lengths for ICL. By running several ablations, we analyze the model's use of: a) the similarity of the in-context examples to the current input, b) the semantic content of the class names, and c) the correct correspondence between examples and labels. We demonstrate that all three are needed to varying degrees depending on the domain, contrary to certain recent works.
RepoFusion: Training Code Models to Understand Your Repository
Jun 19, 2023



Despite the huge success of Large Language Models (LLMs) in coding assistants like GitHub Copilot, these models struggle to understand the context present in the repository (e.g., imports, parent classes, files with similar names, etc.), thereby producing inaccurate code completions. This effect is more pronounced when using these assistants for repositories that the model has not seen during training, such as proprietary software or work-in-progress code projects. Recent work has shown the promise of using context from the repository during inference. In this work, we extend this idea and propose RepoFusion, a framework to train models to incorporate relevant repository context. Experiments on single-line code completion show that our models trained with repository context significantly outperform much larger code models as CodeGen-16B-multi ($\sim73\times$ larger) and closely match the performance of the $\sim 70\times$ larger StarCoderBase model that was trained with the Fill-in-the-Middle objective. We find these results to be a novel and compelling demonstration of the gains that training with repository context can bring. We carry out extensive ablation studies to investigate the impact of design choices such as context type, number of contexts, context length, and initialization within our framework. Lastly, we release Stack-Repo, a dataset of 200 Java repositories with permissive licenses and near-deduplicated files that are augmented with three types of repository contexts. Additionally, we are making available the code and trained checkpoints for our work. Our released resources can be found at \url{https://huggingface.co/RepoFusion}.
StarCoder: may the source be with you!
May 09, 2023



The BigCode community, an open-scientific collaboration working on the responsible development of Large Language Models for Code (Code LLMs), introduces StarCoder and StarCoderBase: 15.5B parameter models with 8K context length, infilling capabilities and fast large-batch inference enabled by multi-query attention. StarCoderBase is trained on 1 trillion tokens sourced from The Stack, a large collection of permissively licensed GitHub repositories with inspection tools and an opt-out process. We fine-tuned StarCoderBase on 35B Python tokens, resulting in the creation of StarCoder. We perform the most comprehensive evaluation of Code LLMs to date and show that StarCoderBase outperforms every open Code LLM that supports multiple programming languages and matches or outperforms the OpenAI code-cushman-001 model. Furthermore, StarCoder outperforms every model that is fine-tuned on Python, can be prompted to achieve 40\% pass@1 on HumanEval, and still retains its performance on other programming languages. We take several important steps towards a safe open-access model release, including an improved PII redaction pipeline and a novel attribution tracing tool, and make the StarCoder models publicly available under a more commercially viable version of the Open Responsible AI Model license.
SantaCoder: don't reach for the stars!
Jan 09, 2023



The BigCode project is an open-scientific collaboration working on the responsible development of large language models for code. This tech report describes the progress of the collaboration until December 2022, outlining the current state of the Personally Identifiable Information (PII) redaction pipeline, the experiments conducted to de-risk the model architecture, and the experiments investigating better preprocessing methods for the training data. We train 1.1B parameter models on the Java, JavaScript, and Python subsets of The Stack and evaluate them on the MultiPL-E text-to-code benchmark. We find that more aggressive filtering of near-duplicates can further boost performance and, surprisingly, that selecting files from repositories with 5+ GitHub stars deteriorates performance significantly. Our best model outperforms previous open-source multilingual code generation models (InCoder-6.7B and CodeGen-Multi-2.7B) in both left-to-right generation and infilling on the Java, JavaScript, and Python portions of MultiPL-E, despite being a substantially smaller model. All models are released under an OpenRAIL license at https://hf.co/bigcode.
The Stack: 3 TB of permissively licensed source code
Nov 20, 2022



Large Language Models (LLMs) play an ever-increasing role in the field of Artificial Intelligence (AI)--not only for natural language processing but also for code understanding and generation. To stimulate open and responsible research on LLMs for code, we introduce The Stack, a 3.1 TB dataset consisting of permissively licensed source code in 30 programming languages. We describe how we collect the full dataset, construct a permissively licensed subset, present a data governance plan, discuss limitations, and show promising results on text2code benchmarks by training 350M-parameter decoders on different Python subsets. We find that (1) near-deduplicating the data significantly boosts performance across all experiments, and (2) it is possible to match previously reported HumanEval and MBPP performance using only permissively licensed data. We make the dataset available at https://hf.co/BigCode, provide a tool called "Am I in The Stack" (https://hf.co/spaces/bigcode/in-the-stack) for developers to search The Stack for copies of their code, and provide a process for code to be removed from the dataset by following the instructions at https://www.bigcode-project.org/docs/about/the-stack/.
On the Compositional Generalization Gap of In-Context Learning
Nov 15, 2022Pretrained large generative language models have shown great performance on many tasks, but exhibit low compositional generalization abilities. Scaling such models has been shown to improve their performance on various NLP tasks even just by conditioning them on a few examples to solve the task without any fine-tuning (also known as in-context learning). In this work, we look at the gap between the in-distribution (ID) and out-of-distribution (OOD) performance of such models in semantic parsing tasks with in-context learning. In the ID settings, the demonstrations are from the same split (test or train) that the model is being evaluated on, and in the OOD settings, they are from the other split. We look at how the relative generalization gap of in-context learning evolves as models are scaled up. We evaluate four model families, OPT, BLOOM, CodeGen and Codex on three semantic parsing datasets, CFQ, SCAN and GeoQuery with different number of exemplars, and observe a trend of decreasing relative generalization gap as models are scaled up.
LAGr: Label Aligned Graphs for Better Systematic Generalization in Semantic Parsing
Jun 01, 2022
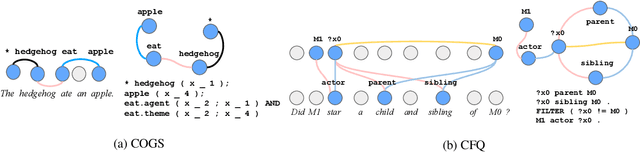
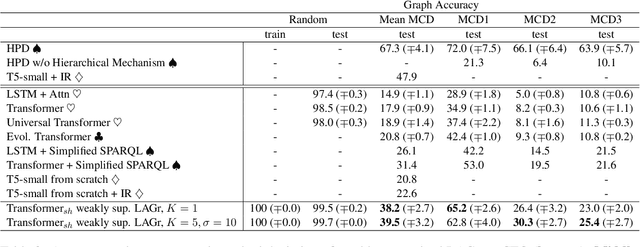
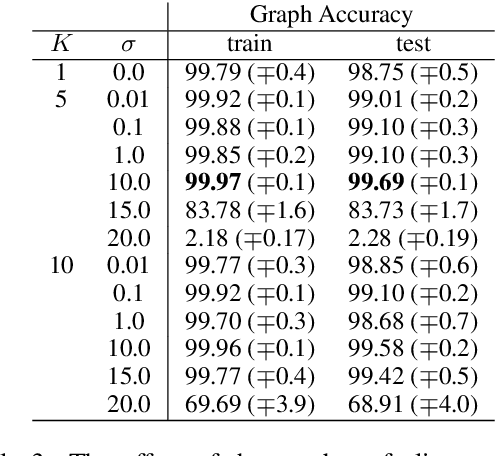
Semantic parsing is the task of producing structured meaning representations for natural language sentences. Recent research has pointed out that the commonly-used sequence-to-sequence (seq2seq) semantic parsers struggle to generalize systematically, i.e. to handle examples that require recombining known knowledge in novel settings. In this work, we show that better systematic generalization can be achieved by producing the meaning representation directly as a graph and not as a sequence. To this end we propose LAGr (Label Aligned Graphs), a general framework to produce semantic parses by independently predicting node and edge labels for a complete multi-layer input-aligned graph. The strongly-supervised LAGr algorithm requires aligned graphs as inputs, whereas weakly-supervised LAGr infers alignments for originally unaligned target graphs using approximate maximum-a-posteriori inference. Experiments demonstrate that LAGr achieves significant improvements in systematic generalization upon the baseline seq2seq parsers in both strongly- and weakly-supervised settings.
Data Augmentation for Intent Classification with Off-the-shelf Large Language Models
Apr 05, 2022
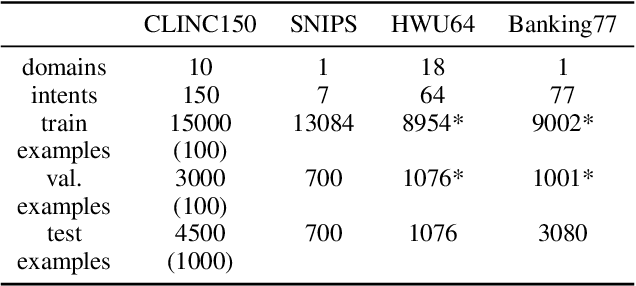
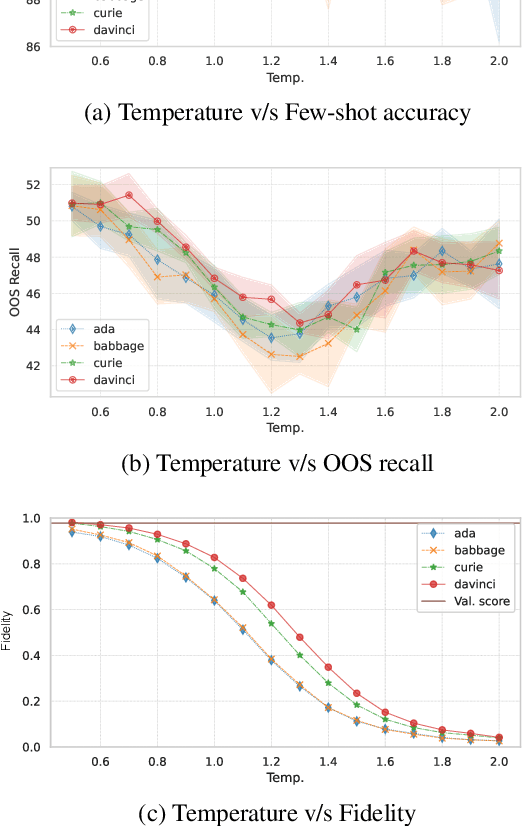
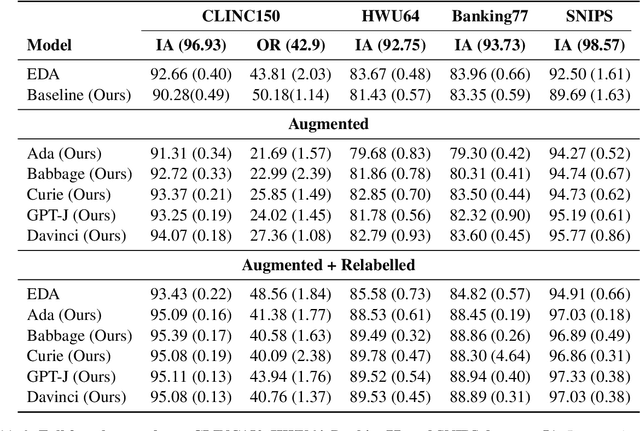
Data augmentation is a widely employed technique to alleviate the problem of data scarcity. In this work, we propose a prompting-based approach to generate labelled training data for intent classification with off-the-shelf language models (LMs) such as GPT-3. An advantage of this method is that no task-specific LM-fine-tuning for data generation is required; hence the method requires no hyper-parameter tuning and is applicable even when the available training data is very scarce. We evaluate the proposed method in a few-shot setting on four diverse intent classification tasks. We find that GPT-generated data significantly boosts the performance of intent classifiers when intents in consideration are sufficiently distinct from each other. In tasks with semantically close intents, we observe that the generated data is less helpful. Our analysis shows that this is because GPT often generates utterances that belong to a closely-related intent instead of the desired one. We present preliminary evidence that a prompting-based GPT classifier could be helpful in filtering the generated data to enhance its quality.
Evaluating the Text-to-SQL Capabilities of Large Language Models
Mar 15, 2022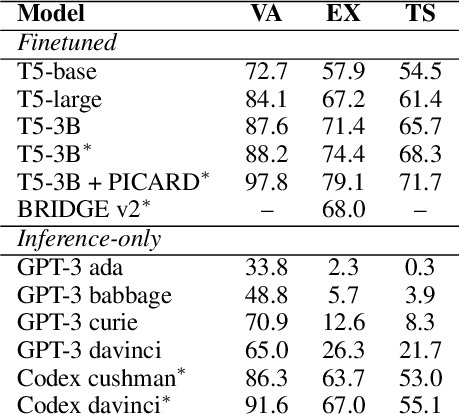

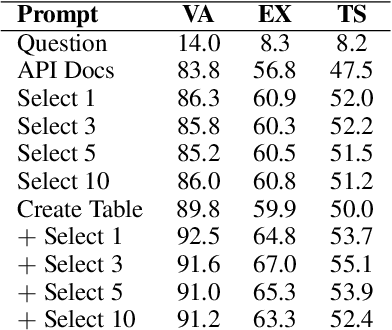
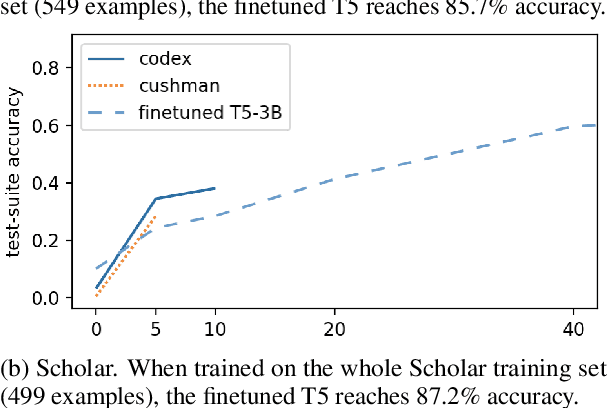
We perform an empirical evaluation of Text-to-SQL capabilities of the Codex language model. We find that, without any finetuning, Codex is a strong baseline on the Spider benchmark; we also analyze the failure modes of Codex in this setting. Furthermore, we demonstrate on the GeoQuery and Scholar benchmarks that a small number of in-domain examples provided in the prompt enables Codex to perform better than state-of-the-art models finetuned on such few-shot examples.
Systematic Generalization with Edge Transformers
Dec 01, 2021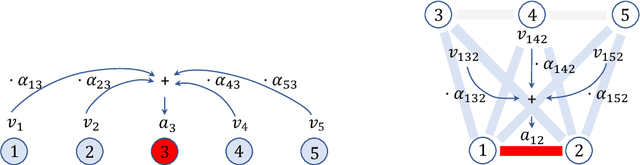
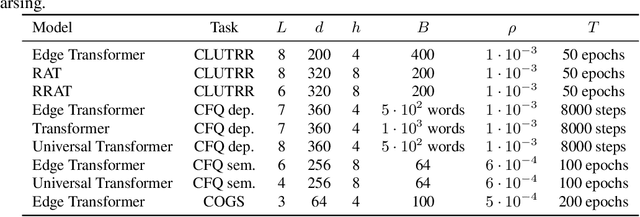
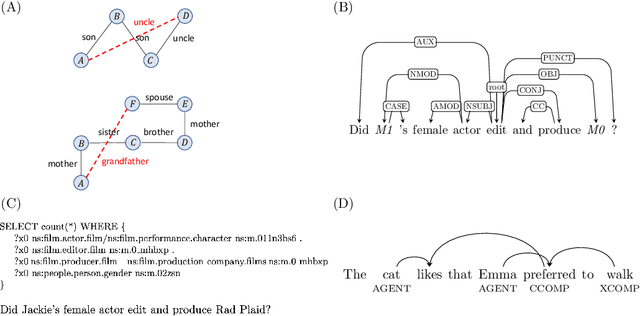
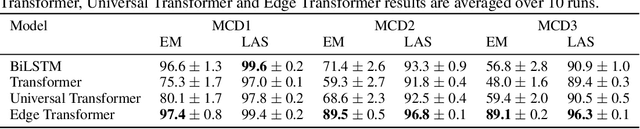
Recent research suggests that systematic generalization in natural language understanding remains a challenge for state-of-the-art neural models such as Transformers and Graph Neural Networks. To tackle this challenge, we propose Edge Transformer, a new model that combines inspiration from Transformers and rule-based symbolic AI. The first key idea in Edge Transformers is to associate vector states with every edge, that is, with every pair of input nodes -- as opposed to just every node, as it is done in the Transformer model. The second major innovation is a triangular attention mechanism that updates edge representations in a way that is inspired by unification from logic programming. We evaluate Edge Transformer on compositional generalization benchmarks in relational reasoning, semantic parsing, and dependency parsing. In all three settings, the Edge Transformer outperforms Relation-aware, Universal and classical Transformer baselines.