 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNo Token Left Behind: Reliable KV Cache Compression via Importance-Aware Mixed Precision Quantization
Feb 28, 2024



Key-Value (KV) Caching has become an essential technique for accelerating the inference speed and throughput of generative Large Language Models~(LLMs). However, the memory footprint of the KV cache poses a critical bottleneck in LLM deployment as the cache size grows with batch size and sequence length, often surpassing even the size of the model itself. Although recent methods were proposed to select and evict unimportant KV pairs from the cache to reduce memory consumption, the potential ramifications of eviction on the generative process are yet to be thoroughly examined. In this paper, we examine the detrimental impact of cache eviction and observe that unforeseen risks arise as the information contained in the KV pairs is exhaustively discarded, resulting in safety breaches, hallucinations, and context loss. Surprisingly, we find that preserving even a small amount of information contained in the evicted KV pairs via reduced precision quantization substantially recovers the incurred degradation. On the other hand, we observe that the important KV pairs must be kept at a relatively higher precision to safeguard the generation quality. Motivated by these observations, we propose \textit{Mixed-precision KV cache}~(MiKV), a reliable cache compression method that simultaneously preserves the context details by retaining the evicted KV pairs in low-precision and ensure generation quality by keeping the important KV pairs in high-precision. Experiments on diverse benchmarks and LLM backbones show that our proposed method offers a state-of-the-art trade-off between compression ratio and performance, compared to other baselines.
DropBP: Accelerating Fine-Tuning of Large Language Models by Dropping Backward Propagation
Feb 27, 2024



Training deep neural networks typically involves substantial computational costs during both forward and backward propagation. The conventional layer dropping techniques drop certain layers during training for reducing the computations burden. However, dropping layers during forward propagation adversely affects the training process by degrading accuracy. In this paper, we propose Dropping Backward Propagation (DropBP), a novel approach designed to reduce computational costs while maintaining accuracy. DropBP randomly drops layers during the backward propagation, which does not deviate forward propagation. Moreover, DropBP calculates the sensitivity of each layer to assign appropriate drop rate, thereby stabilizing the training process. DropBP is designed to enhance the efficiency of the training process with backpropagation, thereby enabling the acceleration of both full fine-tuning and parameter-efficient fine-tuning using backpropagation. Specifically, utilizing DropBP in QLoRA reduces training time by 44%, increases the convergence speed to the identical loss level by 1.5$\times$, and enables training with a 6.2$\times$ larger sequence length on a single NVIDIA-A100 80GiB GPU in LLaMA2-70B. The code is available at https://github.com/WooSunghyeon/dropbp.
Rethinking Channel Dimensions to Isolate Outliers for Low-bit Weight Quantization of Large Language Models
Sep 27, 2023Large Language Models (LLMs) have recently demonstrated a remarkable success across various tasks. However, efficiently serving LLMs has been a challenge due to its large memory bottleneck, specifically in small batch inference settings (e.g. mobile devices). Weight-only quantization can be a promising approach, but sub-4 bit quantization remains a challenge due to large-magnitude activation outliers. To mitigate the undesirable outlier effect, we first propose per-IC quantization, a simple yet effective method that creates quantization groups within each input channel (IC) rather than the conventional per-output channel (OC). Our method is motivated by the observation that activation outliers affect the input dimension of the weight matrix, so similarly grouping the weights in the IC direction can isolate outliers to be within a group. We also find that activation outliers do not dictate quantization difficulty, and inherent weight sensitivities also exist. With per-IC quantization as a new outlier-friendly scheme, we then propose Adaptive Dimensions (AdaDim), a versatile quantization framework that can adapt to various weight sensitivity patterns. We demonstrate the effectiveness of AdaDim by augmenting prior methods such as Round-To-Nearest and GPTQ, showing significant improvements across various language modeling benchmarks for both base (up to +4.7% on MMLU) and instruction-tuned (up to +10% on HumanEval) LLMs.
FlexRound: Learnable Rounding based on Element-wise Division for Post-Training Quantization
Jun 01, 2023



Post-training quantization (PTQ) has been gaining popularity for the deployment of deep neural networks on resource-limited devices since unlike quantization-aware training, neither a full training dataset nor end-to-end training is required at all. As PTQ schemes based on reconstructing each layer or block output turn out to be effective to enhance quantized model performance, recent works have developed algorithms to devise and learn a new weight-rounding scheme so as to better reconstruct each layer or block output. In this work, we propose a simple yet effective new weight-rounding mechanism for PTQ, coined FlexRound, based on element-wise division instead of typical element-wise addition such that FlexRound enables jointly learning a common quantization grid size as well as a different scale for each pre-trained weight. Thanks to the reciprocal rule of derivatives induced by element-wise division, FlexRound is inherently able to exploit pre-trained weights when updating their corresponding scales, and thus, flexibly quantize pre-trained weights depending on their magnitudes. We empirically validate the efficacy of FlexRound on a wide range of models and tasks. To the best of our knowledge, our work is the first to carry out comprehensive experiments on not only image classification and natural language understanding but also natural language generation, assuming a per-tensor uniform PTQ setting. Moreover, we demonstrate, for the first time, that large language models can be efficiently quantized, with only a negligible impact on performance compared to half-precision baselines, achieved by reconstructing the output in a block-by-block manner.
Memory-Efficient Fine-Tuning of Compressed Large Language Models via sub-4-bit Integer Quantization
May 23, 2023



Parameter-efficient fine-tuning (PEFT) methods have emerged to mitigate the prohibitive cost of full fine-tuning large language models (LLMs). Nonetheless, the enormous size of LLMs impedes routine deployment. To address the issue, we present Parameter-Efficient and Quantization-aware Adaptation (PEQA), a novel quantization-aware PEFT technique that facilitates model compression and accelerates inference. PEQA operates through a dual-stage process: initially, the parameter matrix of each fully-connected layer undergoes quantization into a matrix of low-bit integers and a scalar vector; subsequently, fine-tuning occurs on the scalar vector for each downstream task. Such a strategy compresses the size of the model considerably, leading to a lower inference latency upon deployment and a reduction in the overall memory required. At the same time, fast fine-tuning and efficient task switching becomes possible. In this way, PEQA offers the benefits of quantization, while inheriting the advantages of PEFT. We compare PEQA with competitive baselines in comprehensive experiments ranging from natural language understanding to generation benchmarks. This is done using large language models of up to $65$ billion parameters, demonstrating PEQA's scalability, task-specific adaptation performance, and ability to follow instructions, even in extremely low-bit settings.
AlphaTuning: Quantization-Aware Parameter-Efficient Adaptation of Large-Scale Pre-Trained Language Models
Oct 08, 2022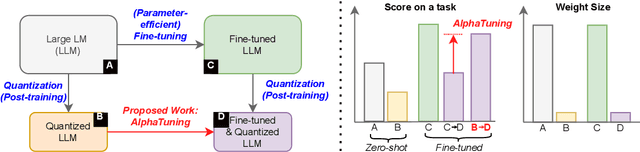

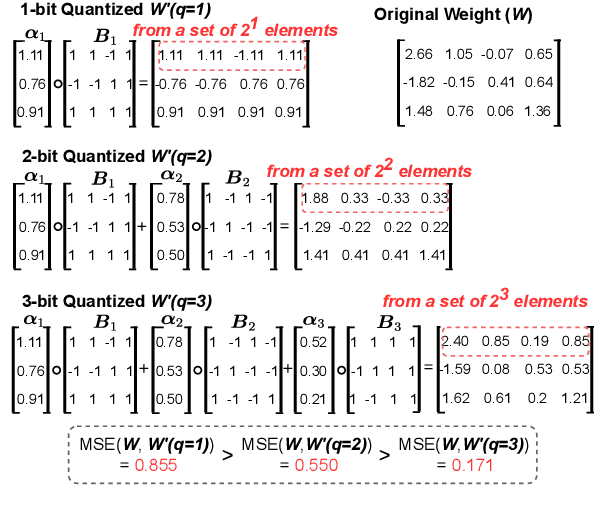
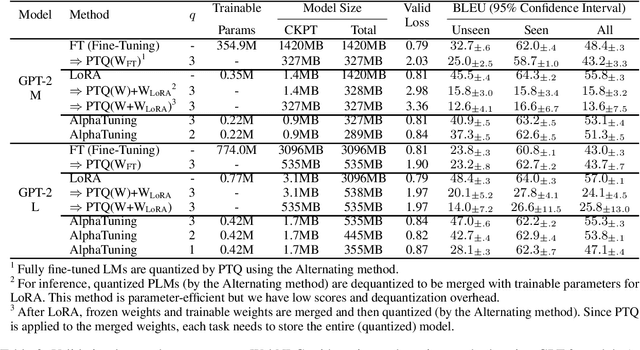
There are growing interests in adapting large-scale language models using parameter-efficient fine-tuning methods. However, accelerating the model itself and achieving better inference efficiency through model compression has not been thoroughly explored yet. Model compression could provide the benefits of reducing memory footprints, enabling low-precision computations, and ultimately achieving cost-effective inference. To combine parameter-efficient adaptation and model compression, we propose AlphaTuning consisting of post-training quantization of the pre-trained language model and fine-tuning only some parts of quantized parameters for a target task. Specifically, AlphaTuning works by employing binary-coding quantization, which factorizes the full-precision parameters into binary parameters and a separate set of scaling factors. During the adaptation phase, the binary values are frozen for all tasks, while the scaling factors are fine-tuned for the downstream task. We demonstrate that AlphaTuning, when applied to GPT-2 and OPT, performs competitively with full fine-tuning on a variety of downstream tasks while achieving >10x compression ratio under 4-bit quantization and >1,000x reduction in the number of trainable parameters.
DFX: A Low-latency Multi-FPGA Appliance for Accelerating Transformer-based Text Generation
Sep 22, 2022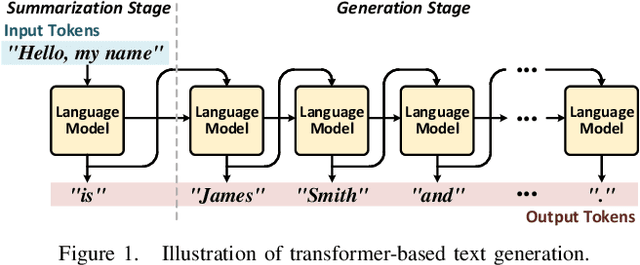
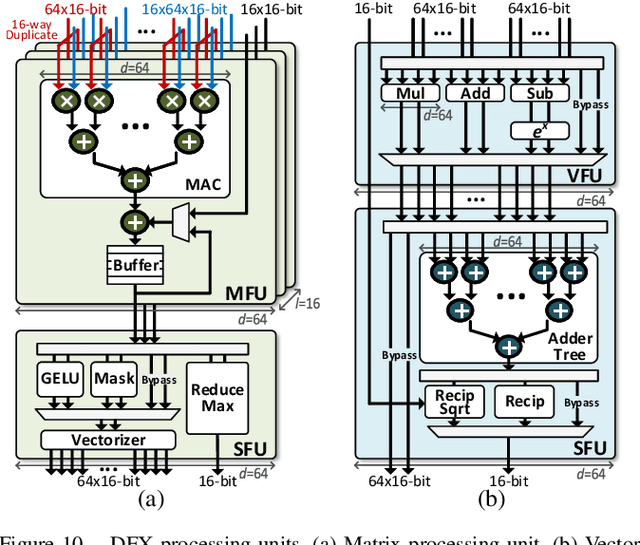
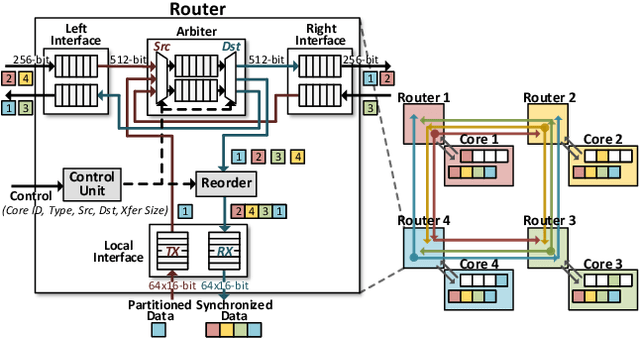
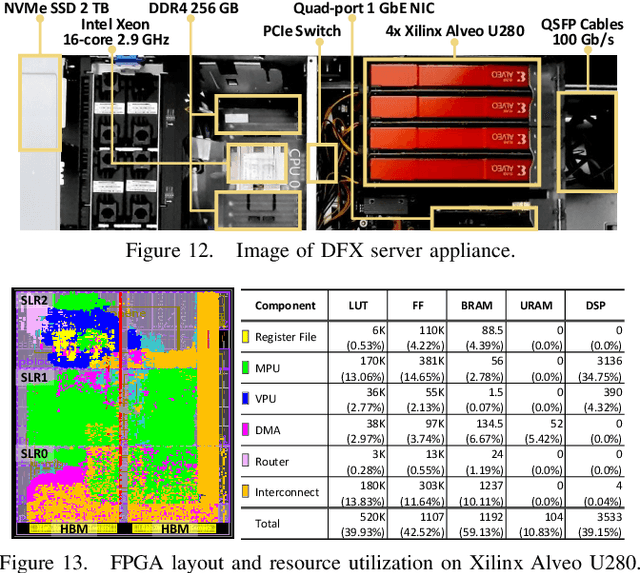
Transformer is a deep learning language model widely used for natural language processing (NLP) services in datacenters. Among transformer models, Generative Pre-trained Transformer (GPT) has achieved remarkable performance in text generation, or natural language generation (NLG), which needs the processing of a large input context in the summarization stage, followed by the generation stage that produces a single word at a time. The conventional platforms such as GPU are specialized for the parallel processing of large inputs in the summarization stage, but their performance significantly degrades in the generation stage due to its sequential characteristic. Therefore, an efficient hardware platform is required to address the high latency caused by the sequential characteristic of text generation. In this paper, we present DFX, a multi-FPGA acceleration appliance that executes GPT-2 model inference end-to-end with low latency and high throughput in both summarization and generation stages. DFX uses model parallelism and optimized dataflow that is model-and-hardware-aware for fast simultaneous workload execution among devices. Its compute cores operate on custom instructions and provide GPT-2 operations end-to-end. We implement the proposed hardware architecture on four Xilinx Alveo U280 FPGAs and utilize all of the channels of the high bandwidth memory (HBM) and the maximum number of compute resources for high hardware efficiency. DFX achieves 5.58x speedup and 3.99x energy efficiency over four NVIDIA V100 GPUs on the modern GPT-2 model. DFX is also 8.21x more cost-effective than the GPU appliance, suggesting that it is a promising solution for text generation workloads in cloud datacenters.
nuQmm: Quantized MatMul for Efficient Inference of Large-Scale Generative Language Models
Jun 20, 2022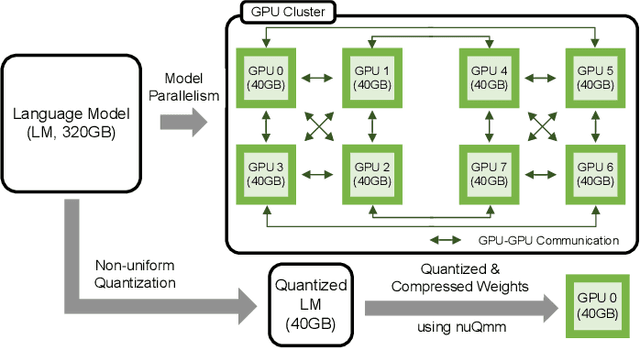
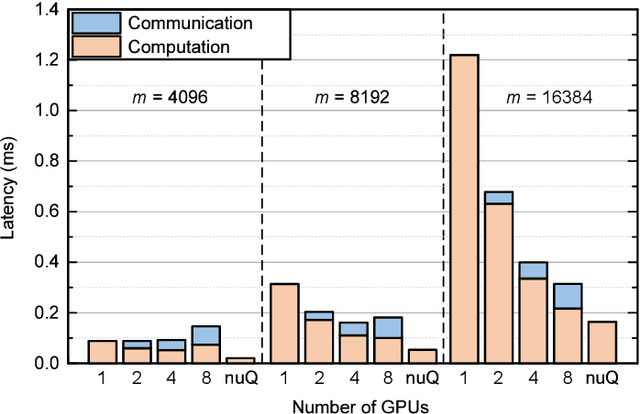
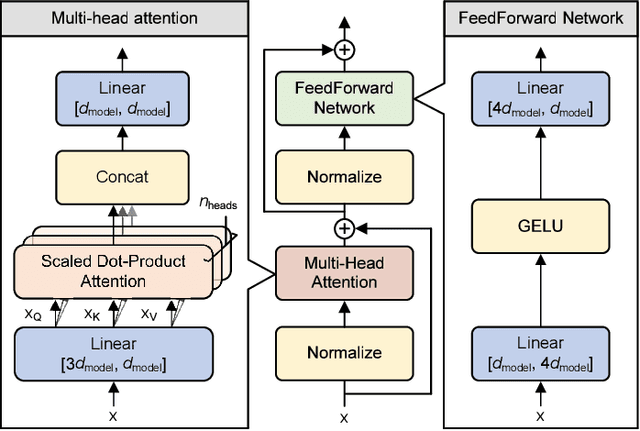
The recent advance of self-supervised learning associated with the Transformer architecture enables natural language processing (NLP) to exhibit extremely low perplexity. Such powerful models demand ever-increasing model size, and thus, large amounts of computations and memory footprints. In this paper, we propose an efficient inference framework for large-scale generative language models. As the key to reducing model size, we quantize weights by a non-uniform quantization method. Then, quantized matrix multiplications are accelerated by our proposed kernel, called nuQmm, which allows a wide trade-off between compression ratio and accuracy. Our proposed nuQmm reduces the latency of not only each GPU but also the entire inference of large LMs because a high compression ratio (by low-bit quantization) mitigates the minimum required number of GPUs. We demonstrate that nuQmm can accelerate the inference speed of the GPT-3 (175B) model by about 14.4 times and save energy consumption by 93%.
Maximum Likelihood Training of Implicit Nonlinear Diffusion Models
May 27, 2022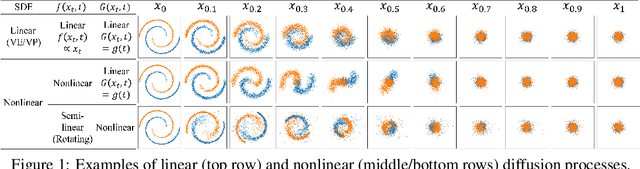

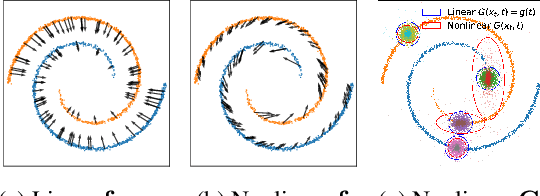
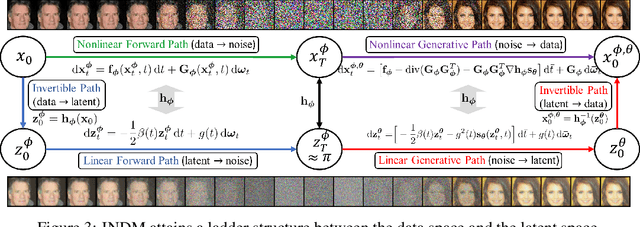
Whereas diverse variations of diffusion models exist, expanding the linear diffusion into a nonlinear diffusion process is investigated only by a few works. The nonlinearity effect has been hardly understood, but intuitively, there would be more promising diffusion patterns to optimally train the generative distribution towards the data distribution. This paper introduces such a data-adaptive and nonlinear diffusion process for score-based diffusion models. The proposed Implicit Nonlinear Diffusion Model (INDM) learns the nonlinear diffusion process by combining a normalizing flow and a diffusion process. Specifically, INDM implicitly constructs a nonlinear diffusion on the \textit{data space} by leveraging a linear diffusion on the \textit{latent space} through a flow network. This flow network is the key to forming a nonlinear diffusion as the nonlinearity fully depends on the flow network. This flexible nonlinearity is what improves the learning curve of INDM to nearly MLE training, compared against the non-MLE training of DDPM++, which turns out to be a special case of INDM with the identity flow. Also, training the nonlinear diffusion empirically yields a sampling-friendly latent diffusion that the sample trajectory of INDM is closer to an optimal transport than the trajectories of previous research. In experiments, INDM achieves the state-of-the-art FID on CelebA.
Modulating Regularization Frequency for Efficient Compression-Aware Model Training
May 05, 2021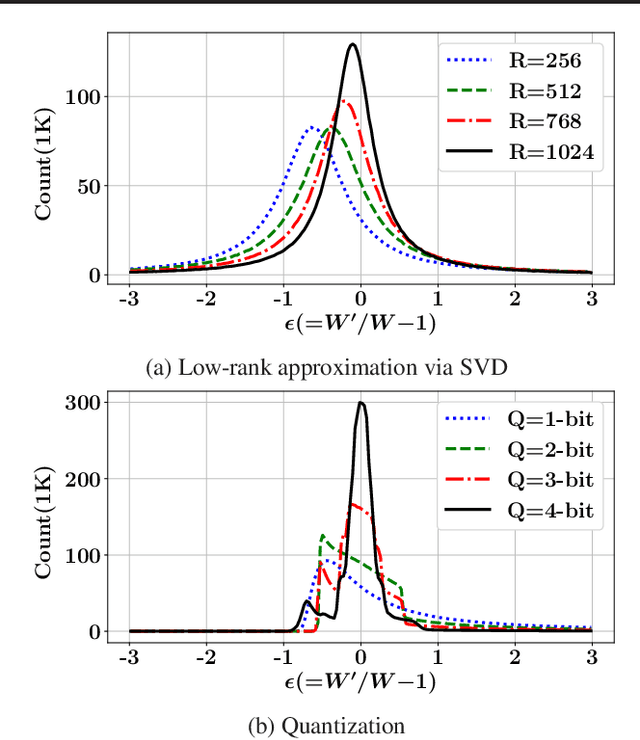
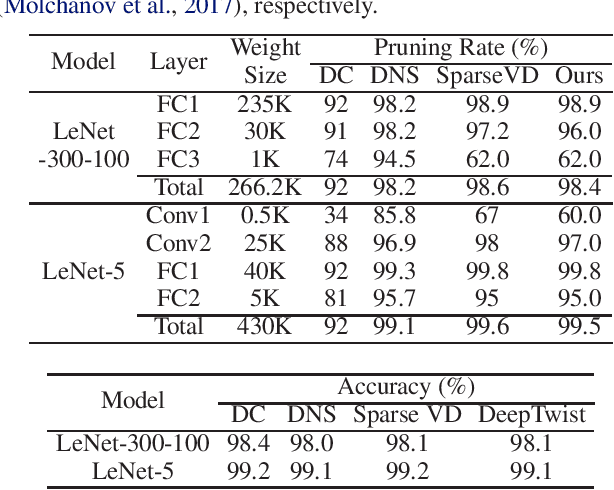
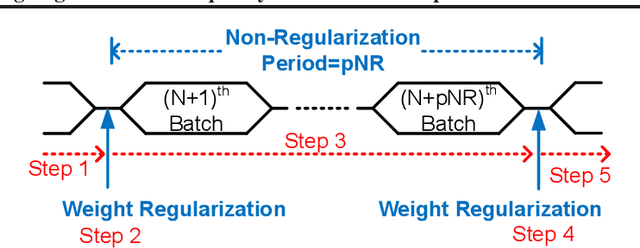

While model compression is increasingly important because of large neural network size, compression-aware training is challenging as it needs sophisticated model modifications and longer training time.In this paper, we introduce regularization frequency (i.e., how often compression is performed during training) as a new regularization technique for a practical and efficient compression-aware training method. For various regularization techniques, such as weight decay and dropout, optimizing the regularization strength is crucial to improve generalization in Deep Neural Networks (DNNs). While model compression also demands the right amount of regularization, the regularization strength incurred by model compression has been controlled only by compression ratio. Throughout various experiments, we show that regularization frequency critically affects the regularization strength of model compression. Combining regularization frequency and compression ratio, the amount of weight updates by model compression per mini-batch can be optimized to achieve the best model accuracy. Modulating regularization frequency is implemented by occasional model compression while conventional compression-aware training is usually performed for every mini-batch.